赛尔笔记 | 事件模式归纳相关研究简述
作者:哈工大SCIR 徐焕琛
事件模式归纳(event schema induction)是从未标记的文本中学习复杂的事件以及其论元的高级表示的一项任务[1]。事件模式归纳最早可以起源于1992年,当时是由美国DARPA资助的MUC-4会议中提出的MUC-4 scenario template task任务中提出了事件模板提取任务(event template task),该任务主要是以管道模型的方式将事件模板提取分解为字段分割和基于事件的文本分割任务[2]。
最早的事件模式自动归纳方法(automatic event schema induction)源自于Chambers and Jurafsky在2009年发布的一篇对于叙事事件模式和其论元的无监督学习的研究[3],在这篇研究中首次提出了利用文本中的类型叙事链来对事件模式进行自动归纳的研究方法。
由于事件模式并没有一个统一的定义,因此存在着众多的事件模式定义方法以及其相关的归纳方法。但是从大体上来说可以将事件模式归纳分为两类:一种是原子事件模式归纳(Atomic Event Schema Induction),另外一种是叙事事件模式归纳(Narrative Event Schema Induction)[4]。
下面将分别按照两种不同的事件模式归纳方法分别对其典型的研究进行介绍,最后介绍一种事件模式归纳的新思路——事件图模式归纳。
1.原子事件模式归纳
1.1 原子事件模式归纳简介
原子事件模式归纳重点关注于单一原子事件的事件类型以及论元。一般的原子事件模式是多个相似事件的一个模板:其中包括一个事件类型(如Elections)以及一组论元(如Date/Winner.....)。这里需要注意不同的论文中对于事件类型与论元有着不同的描述,在本文中将其统称为事件类型和论元。一个原子事件模式的示例如图1[5]所示。

图1:一个选举(Elections)的事件模式。可以看到对于多个相似的事件(图1中的nominate、vote等),他们对应的均为事件类型为elections的事件模式,并且这些相似的事件都具有事件模式所有的五个论元(Date、Winner、Loser、Position和Vote)以及论元对应的类型。
语义角色(semantic role):谓语和论元之间不同的语义关系可以把论元分为若干个类型,这些类型一般称之为"语义角色",如施事、受事等。
句法关系(Syntactic Relations):指句法结构的组成成分间产生的关系意义,如主谓关系、偏正关系等。
1.2 典型研究
一个典型的原子事件类型归纳的研究是Nathanael Chambers和Dan Jurafsky在2013年发表的一篇关于如何在没有预设模板的情况下进行基于模板的事件模式归纳的方法[1]。这篇文章的开创性部分在于文章着重于在无监督的情况下学习一个事件类型的事件模式结构。
首先是通过计算事件单词之间的接近度来聚类训练集中的事件;
其次是针对第一步生成的每一个聚类从一个不相关的语料库中抽取文章来建立一个新的语料库;
最后采用第二步生成的新的语料库来归纳每一个事件模式的论元。
文章采用了MUC-4的恐怖主义语料库(terrorism corpus of MUC-4),选择该语料库的原因是语料库注释了包含事件与相关论元的模板,在最后的性能测试中可以将生成的事件模式的结构与语料库本身的模板结构进行比较。下面介绍作者的方法。
1.2.1 聚类训练集中的事件
首先需要对事件进行聚类。这里采用了两种聚类方法:LDA(隐含狄利克雷分布)和基于单词距离的层次聚类算法(agglomerative clustering based on word distance)。
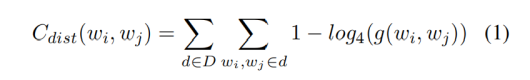
作者使用PMI分数(pointwise mutual information)对所有事件模式进行层次聚类。聚类合并的策略为两个事件聚类间所有新链接间的平均链接得分(average link score)。当聚类中事件个数超过40个以后停止聚类。
1.2.2 构建新的语料库
针对MUC-4没有提供足够的动词以及相关语义角色的情况,作者在一个更大的不相关语料库(美联社和《纽约时报》上的胃肠道语料库的一部分)上通过搜寻相关文章的方式针对每一个聚类分别来构建一个新的语料库。
具体搜寻方法如下:第一步中对每个聚类具有多个对应的事件词,在这里可以根据这些事件词在这个不相关语料库进行检索。通过聚类的事件词出现在文档中的次数以及文档中出现了几种聚类中的事件词进行筛选,最终得到了每一个聚类对应的语料库(IR-corpus)。
1.2.3 论元归纳
(1)聚类事件聚类对应的句法关系来表示论元:
在成功地聚类了事件词并检索了每个聚类的IR-corpus(指在第二步中生成的语料库)后,我们现在需要解决论元归纳的问题。
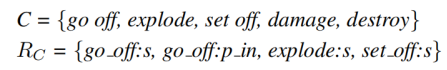
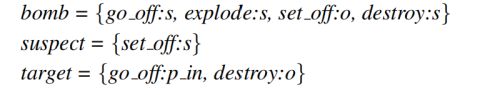
例如“他跑步和跳跃”,在这个例子中跑步和跳跃的主语均是“他”。所以“跑步”和“跳跃”很可能属于同一特定场景的语义角色。
比如go_off:s这个句法关系和plant:o, set off:o and injure:s具有相同的论元,则将go_off:s表示为这三个句法关系的向量,称其为共指向量表示(coref vector representation)。
比如对于go_off:s的选择偏好来说包含{bomb, device, charge, explosion}。
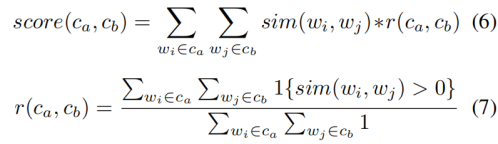
比 如sell的主语是seller,而宾语是good,二者的语义角色是不同的;
比如seller的实体类别是Person/Organization,good的实体类别是Physical Object。
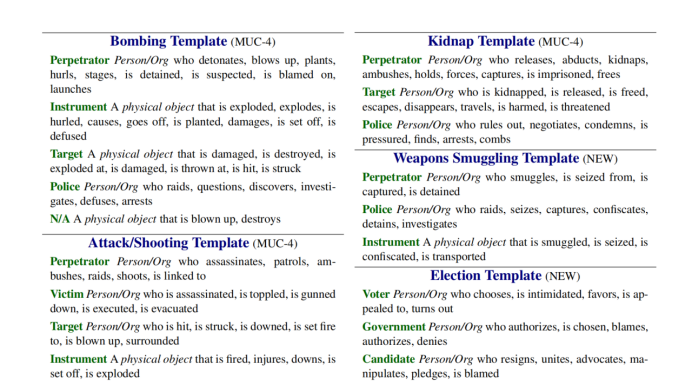
图2:根据算法生成的MUC-4恐怖主义语料库的部分事件模式,其中事件类型为蓝色,如Election Template,事件的论元为绿色,如Voter。
1.2.4 论元归纳对于事件模式归纳的测试
现在将我们学习到的模板与那些为MUC-4恐怖主义语料库手工创建的模板进行比较。MUC-4恐怖主义语料库共有6种事件模式,作者对于其中4种主要的事件模式进行了测评。图3是原先的MUC-4恐怖主义语料库包含的事件模式和论元,可以看到图3中包含了13种相关论元,本文的事件模式归纳算法寻找出了原先13种中的12种,并且寻找出了在Bombing/Kidnap/Arson中的一种新的论元Police or Authorities。对于论元的召回率92%,准确度是14/16。

图3:原先的MUC-4恐怖主义语料库包含的事件模式以及论元
2.叙事事件模式归纳
2.1 叙事事件模式归纳简介
叙事事件模式主要关注归纳叙事事件模式。一个叙事事件模式主要由一组相关事件(search/arrest/plead)、事件的时间顺序(search before arrest)以及特定的语义角色(Roles:Police/Suspect......)所构成[6]。图4是一个典型的叙事事件模式的示例[3]:

图4:一个典型的叙事事件模式。其中在左边的事件一列由一系列特定的语义角色(Police/Suspect/Plea/Jury)通过一系列相关的事件构成一个叙述(narrative)
最早的叙事事件模式自动归纳方法就是本文第一章中介绍的Chambers and Jurafsky在2009年发布的一篇对于叙事事件模式和其论元的无监督学习的论文[3]。下文将介绍这篇文章讲述的研究方法。
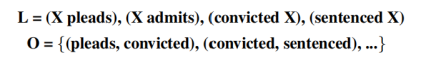
图5:叙事事件链的表示
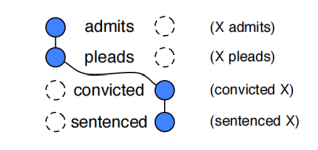
图6:叙事事件链的图示化表示
对于叙事事件链的生成来说,作者首先对文本进行分析和共指消解(parsing and resolving coreference in the text),随后对进行无监督的学习来生成叙事事件链:首先计算在文章中有多少个成对的动词具有共同的论元(即为图5中的X),随后计算这些动词-论元对之间的PMI分数,算法通过PMI分数进行聚类从而生成叙事事件链。这里的叙事事件链仅针对于事件链中事件共同的论元,这里的论元指的是参与者,即主角(protagonist,如图5中的X),而不是一种类型。
2.2.2 类型叙事链
在Chambers and Jurafsky 2009年的研究中扩展了叙事事件链并提出了类型叙事链(Typed Narrative Chains)这一概念,相较于原先的叙事事件链来说,类型叙事链中共同的论元被替换为一种类型(如person/government)。一个典型的类型叙事链由一个三元组(L,P,O)所构成,其中L和O的概念与叙事事件链的概念一致,而新增加的P是一组表示单个角色的论元类型,类型叙事链的示例图7所示:

图7:类型叙事链的一般表示

图8:一个具体的示例
比如在图8的示例中最突出的描述为workers,在这里这四个中心词则成为了共指集。在示例中如果任意成对的event slot具有相同的来自共指集的论元的话,则将其计算为workers。 在图8的示例中(X find),(X apply)具有相同类型的论元(workers,they)。因此在叙事事件链的归纳中((X find),(X apply))被计算,在论元归纳中((X find),(X apply),workers)被计算。

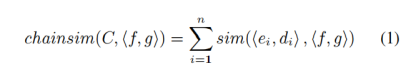
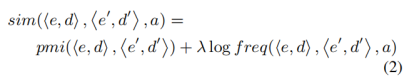
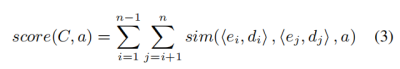
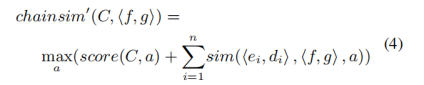
2.2.3 叙事事件模式
在完成类型叙事链的定义与构建后,下面来定义具体的叙事事件模式。如果说叙事事件链是由一系列的event slot构成,那么叙事事件模式则由一系列的类型叙事链所表示。叙事事件模式N由一个二元组N=(E,C)所组成,其中E是一系列事件(动词)的序列,C是一系列类型叙事链。一个典型的叙事事件模式如图10所示。
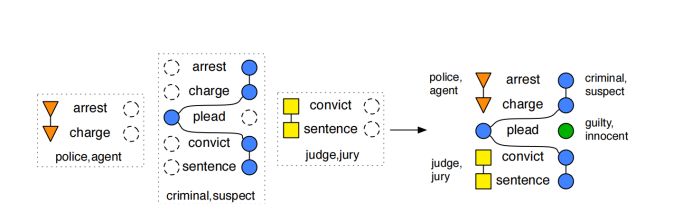
图10:一个典型的叙事事件模式,左侧是类型叙事链,第一个是警察的类型叙事链,第二个是罪犯的,第三个是法官的;右侧是生成的叙事事件模式。
比如对于图11中的例子来说,有可能(警察,pull over)的得分较高,但是(pull over,A)这个event slot并没有出现在其他的叙事链中; 假设有一个(警察,search)的event slot,同时也出现了(search,defendant)这个event slot,那么相较于pull over来说的话,search则更应该加入到叙事事件模式中。

图11:另一个叙事事件模式的示例
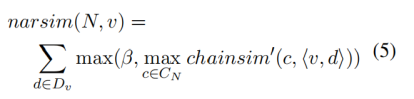

图12:算法生成的top 20个事件模式的其中几个实例,其中斜体字代表在FrameNet中被判别为错误,*号代表动词不在FrameNet中,而-号代表动词的词义不在FrameNet中
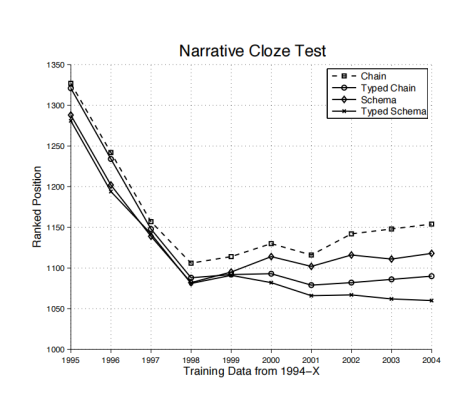
图13:叙事完型填空的实验结果
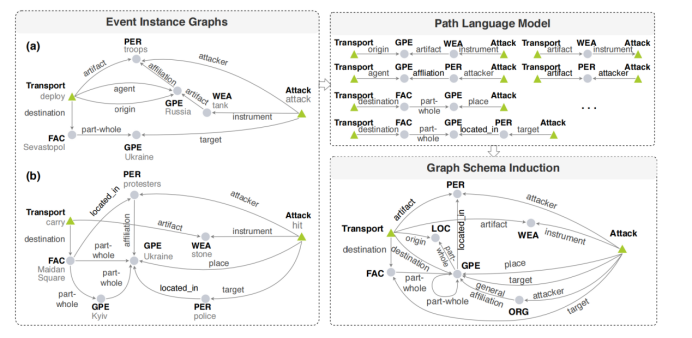
图14:事件图模式归纳的整体框架
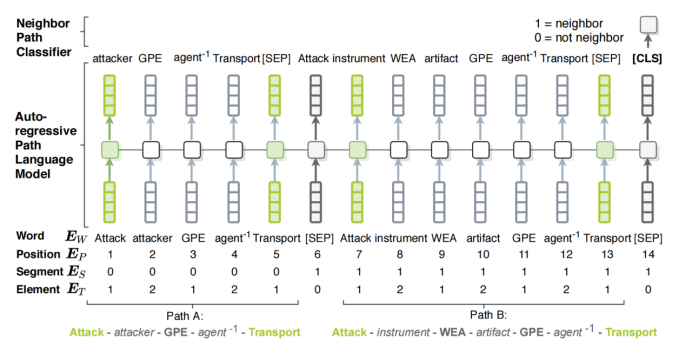
图15:自回归路径语言模型和邻居路径分类。其中是类型嵌入,1代表节点,2代表边,0代表其他字符,如[CLS];邻居路径分类中如果两个路径是邻居的话则为1,不是的话则为0
本文首先介绍了事件模式归纳的历史以及相关概念,介绍了原子事件模式归纳以及叙事事件模式归纳的典型研究,最后介绍了事件模式归纳的新思路——事件图模式归纳。随着深度学习技术的不断发展,相信事件模式归纳这一研究能够取得更大的创新与突破。
[1] Nathanael Chambers. 2013. Event schema induction with a probabilistic entity-driven model. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1797-1807,Seattle, Washington, USA. Association for Computational Linguistics.
[2] Event Schema Induction Based on Relational Co-occurrence over Multiple Documents.Tingsong Jiang, Lei Sha, and Zhifang Sui.
[3] Nathanael Chambers and Dan Jurafsky. 2009. Unsupervised learning of narrative schemas and their participants.In Proceedings of the Joint conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing (ACLIJCNLP2009).
[4] Manling Li, Qi Zeng, Ying Lin, Kyunghyun Cho, Heng Ji, Jonathan May, Nathanael Chambers, and Clare Voss. 2020. Connecting the dots: Event graph schema induction with path language modeling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),pages 684–695, Online. Association for Computational Linguistics.
[5] Katrin Erk and Sebastian Pado. 2008. A structured vector space model for word meaning in context. In Proceedings of the 2008 Conference on Empirical Methods on Natural Language Processing (EMNLP).
[6] Chambers, N., & Jurafsky, D. (2010, May). A database of narrative schemas. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10).
[7] Nasrin Mostafazadeh, Alyson Grealish, Nathanael Chambers, James Allen, and Lucy Vanderwende. 2016b. Caters: Causal and temporal relation scheme for semantic annotation of event structures. In Proceedings of the Fourth Workshop on Events, pages 51–61.
[8] Ashutosh Modi, Tatjana Anikina, Simon Ostermann, and Manfred Pinkal. 2017. Inscript: Narrative texts annotated with script information. arXiv preprint arXiv:1703.05260.
[9] Ying Lin, Heng Ji, Fei Huang, and Lingfei Wu. 2020. A joint end-to-end neural model for information extraction with global features. In Proceedings of the 2020 Annual Meeting of the Association for Computational Linguistics (ACL2020).
[10] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019. Xlnet: Generalized autoregressive pretraining forlanguage understanding. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, 8-14 December 2019, Vancouver, BC, Canada, pages 5754–5764.
[11] Li M, Li S, Wang Z, et al. The Future is not One-dimensional: Complex Event Schema Induction by Graph Modeling for Event Prediction[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 5203-5215.
本期责任编辑:赵森栋
理解语言,认知社会
以中文技术,助民族复兴
