计算语言顶会ACL 2018最佳论文公布!这些大学与研究员榜上有名
机器之心整理
机器之心编辑部
今日,ACL 2018 公布了 5 篇最佳论文,包括三篇最佳长论文和 2 篇最佳短论文。今年的 ACL 共收到 1544 份提交论文,其中 1018 份长论文接收了 258 篇,526 份短论文接收了 126 篇,总体接受率为 24.9%。
ACL 2018 获奖名单如下:
最佳长论文
1. Finding syntax in human encephalography with beam search(尚未公开)
作者:John Hale、Chris Dyer、Adhiguna Kuncoro、Jonathan Brennan
2. Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information
作者:Sudha Rao、Hal Daumé III 均来自于马里兰大学帕克分校。
3. Let’s do it “again”: A First Computational Approach to Detecting Adverbial Presupposition Triggers
作者:Andre Cianflone、Yulan Feng、Jad Kabbara、Jackie Chi Kit Cheung,来自于麦吉尔大学和 MILA。
最佳短论文
1. Know What You Don’t Know: Unanswerable Questions for SQuAD.(尚未公开)
作者:Pranav Rajpurkar、Robin Jia、Percy Liang
目前,该论文尚未公开,但三位研究员都来自斯坦福大学。
2. ‘Lighter’ Can Still Be Dark: Modeling Comparative Color Descriptions.(尚未公开)
作者:Olivia Winn、Smaranda Muresan
该获奖论文的两位作者来自于哥伦比亚大学。
在本文中,机器之心对两篇已公开的获奖论文进行了编译介绍,感兴趣的同学可以查看原论文:
论文 1: Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information

论文地址:https://arxiv.org/abs/1805.04655
摘要:询问对于交流而言是很基础的,然而机器无法与人类进行高效协作,除非它们可以学会问问题。在这项研究中,我们为给澄清性(clarification)提问排序的任务构建了一个神经网络模型。该模型受完美信息期望值的思想启发:一个问题好不好在于其期望的回答是否有用。我们使用了来自 StackExchange 的数据来研究这个问题,StackExchange 是一个丰富的在线资源,人们通常在帖子中询问澄清性问题,从而他们可以更好地为帖子楼主提供帮助。我们创建了一个由大约 77000 个澄清性问题帖子构成的数据集,其中每个帖子包含一个问答对,这些帖子来自 StackExchange 的三个领域:askubuntu、unix 和 superuser。我们在该数据集的 500 个样本上通过和人类专家判断对比对我们的模型进行了评估,并在受控基线上实现了显著的提高。
提问的核心目标是填补信息鸿沟,该过程通常通过澄清性问题进行。我们认同好的问题是其答案最可能有用的问题。考虑到图 1 中的信息交流,其中楼主(我们叫他 Terry)就配置环境变量提问。这个帖子不够细化,一个回复者(Parker)问了一个澄清性问题(如下 a),不过也可以问问题(b)或(c)。
(a)你使用的是哪个版本的 Ubuntu?
(b)你的无线网卡型号是什么?
(c)你是在 x86 64 架构上运行 Ubuntu 14.10 kernel 4.4.0-59- generic 吗?
Parker 不应该问(b)因为答案可能没什么用;也不应该问(c)因为这个问题太具体了,「No」或「I do not know」这样的答案也没什么用处。Parker 的问题(a)就好多了:答案有用的可能性高,且对于 Terry 来说是可以回答的。
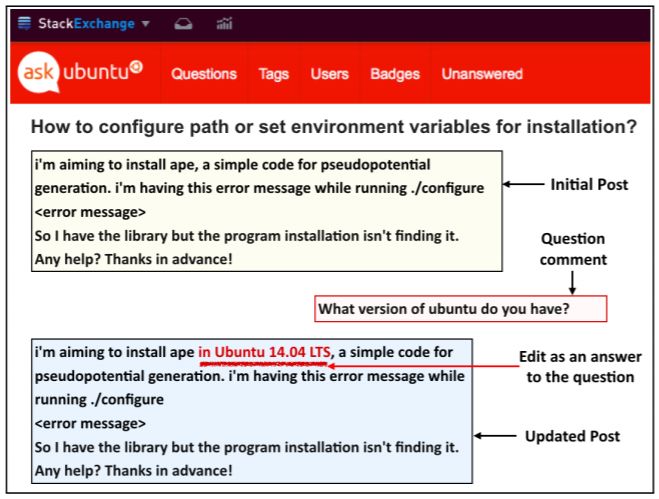
图 1:更新在线问答论坛「askubuntu.com」上的帖子来补充评论中缺失的信息。
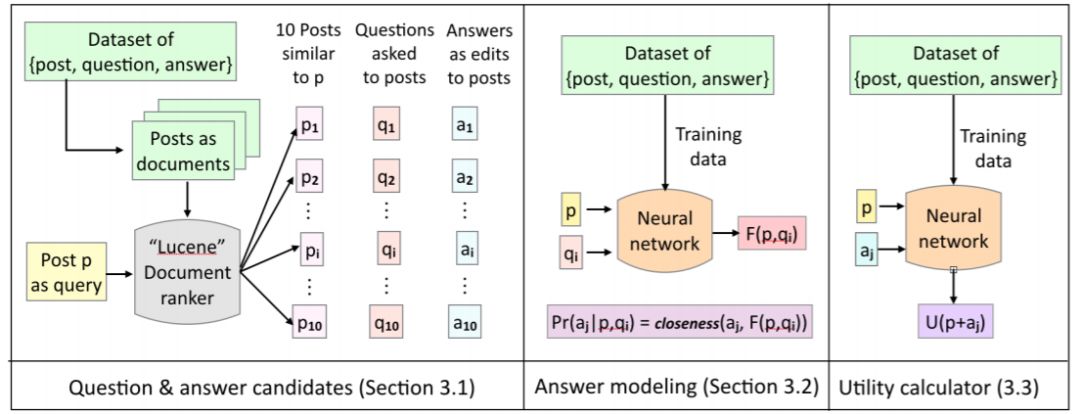
图 2:我们的模型在测试过程中的行为:给出帖子 p,我们使用 Lucene 检索出 10 个与 p 类似的帖子。对这 10 个帖子提问的问题是我们的候选问题 Q,对这些问题的答复是我们的候选答案 A。对于每个候选问题 q_i,我们生成答案表征 F(p, q_i),并计算候选答案 a_j 与答案表征 F(p, q_i) 之间的接近程度。然后我们计算帖子 p 的效用,并确定是否使用答案 a_j 对它进行更新。最后,我们根据公式 1,按照问题的期望效用对候选问题 Q 进行排序。
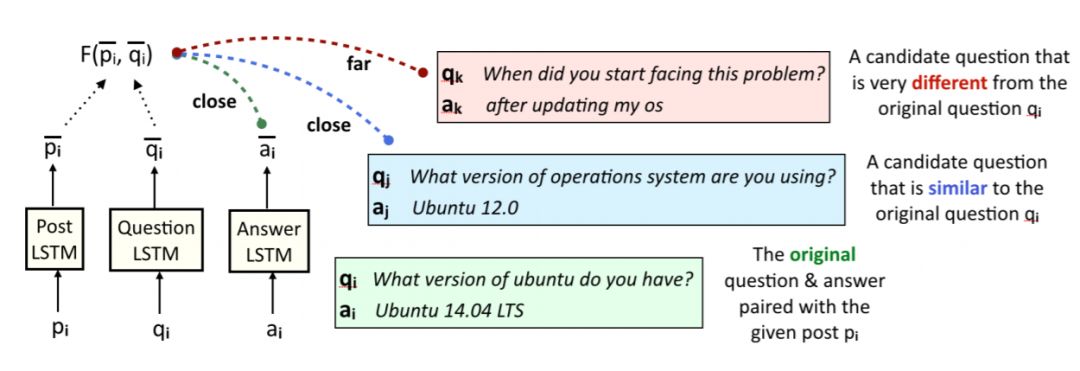
图 3:答案生成器的训练过程。给定一个帖子 p_i 和问题 q_i,我们生成答案表征,其不仅与原始答案 a_i 很接近,而且在候选问题 q_j 与原始问题 q_i 接近的情况下答案表征与候选答案 a_j 也很接近。
实验结果
我们在实验评估过程中使用的主要研究问题是:
1. 神经网络架构是否比非神经网络基线模型有所改善?
2. EVPI formalism 是否能影响有类似表征力的前馈网络?
3. 答案有助于识别正确的问题吗?
4. 在候选问题(不包括原始问题)上评估模型时,模型性能如何?
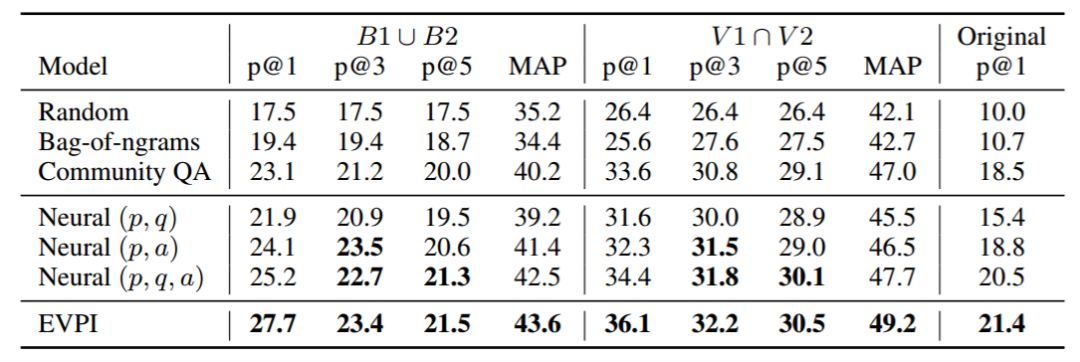
表 2:在 500 个样本上评估的模型性能,包括「最佳」标注的并集(B1 ∪ B2)、「有效」标注的交集(V1 ∩ V2),以及数据集中和帖子配对的原始问题。加粗和非加粗数字的区别在于统计显著性 p<0.05(使用自引导检验计算)。p@k 是模型排序最高的 k 个问题的精度,MAP 是模型预测排序的平均精度。
结论
我们为学习给澄清性问题排序构建了一个新的数据集,并为求解该任务提出了新的模型。该模型结合了著名的深度网络架构和完美信息期望值的经典概念,可以从提问者的角度为实用的选择有效地建模:如果我问了这个问题,我应该如何设想对方的回答。这种实用原则近期被证明在其它任务中也有用(Golland et al., 2010; Smith et al., 2013; Orita et al., 2015; Andreas and Klein, 2016)。人们可以自然地将我们的 EVPI 方法扩展到完全的强化学习方法,以处理多回合的对话。实验结果表明 EVPI 模型对于求解问题生成任务而言是有潜力的范式。
论文 2:Let’s do it “again”: A First Computational Approach to Detecting Adverbial Presupposition Triggers

论文地址:https://www.cs.mcgill.ca/~jkabba/acl2018paper.pdf
摘要:我们介绍了预测状语预设触发语(如 also、again)的任务。解决这样的任务需要检测语篇中的重复或类似事件,并且在自然语言生成任务中有应用,例如摘要和对话系统。我们为这项任务创建了两个新的数据集,分别来自宾州树库(Penn Treebank)和 Annotated English Gigaword 语料库,并为其定制了一个新的注意力机制。我们的注意力机制增强了基线循环神经网络,而不需要额外的可训练参数,从而使注意力机制的额外计算成本最小化。我们已证实,根据统计数据,该模型优于许多基线模型,包括基于 LSTM 的语言模型。
在本文中,我们的重点是如 again、also、still 这样的状语预设触发语。状语预设触发语指出了语篇中事件的重复、延续或终止,或者类似事件的存在。
本论文的主要贡献如下:
介绍了预测状语预设触发语的任务;
提出了用于检测状语预设触发语的新数据集,以及一种可应用于其它类似预处理任务的数据提取方法;
在 RNN 架构中使用一种新的注意力机制,可用于预测状语预设触发语任务。这种注意力机制无需引入额外的参数,但预测效果优于很多基线模型。
3 数据集
我们从两个语料库中提取了数据集,即宾州树库(PTB)语料库(Marcuset al.,1993)和第三版 English Gigaword 语料库(Graff et al.,2007)的子集(sections 000-760)。

图 1:我们的数据集中一个包含预设触发语的实例。
4 学习模型
本章介绍了我们基于注意力的模型。该模型计算每一时间步上隐藏状态之间的相关性,然后再在这些相关性上应用注意力机制,从而扩展双向 LSTM 模型。我们提出的加权池化(WP)神经网络架构如图 2 所示。
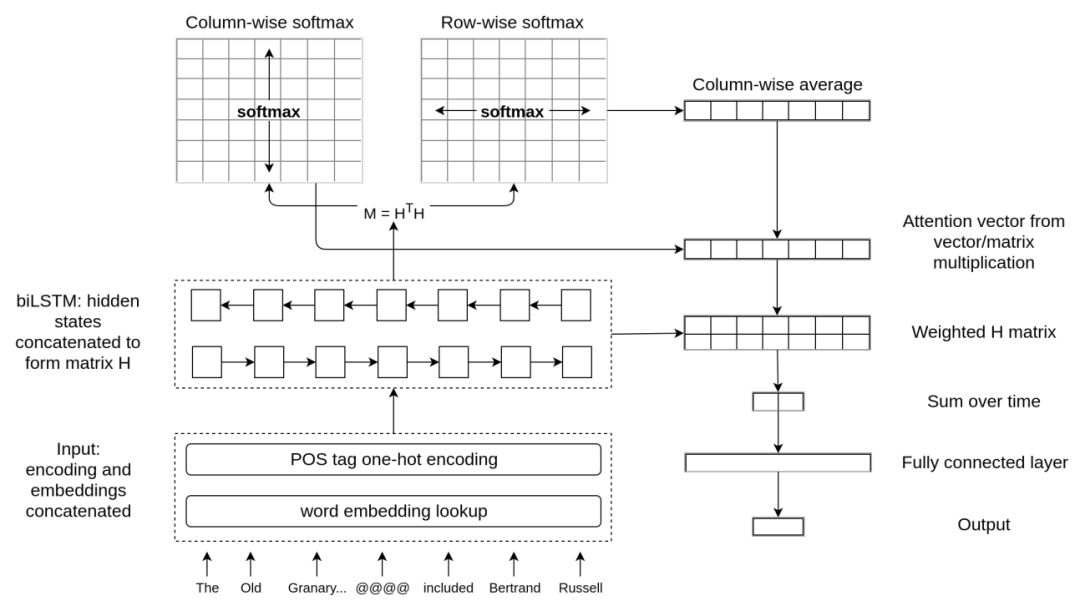
图 2:我们提出的加权池化神经网络架构(WP)。分词后的输入将嵌入到预训练词嵌入中,并可能与经过 one-hot 编码的 POS 标签相级联。输入序列随后会通过双向 LSTM 进行编码,并馈送到注意力机制内。计算得出的注意力权重随后可用于编码状态的加权平均运算,依次连接到全连接层以预测预设触发语。
6 结果
表 2 显示了具有 POS 标签和没有该标签的不同模型的表现。总体而言,在结合不同数据集以及是否使用 POS 标签的所有 14 个场景里,我们的注意力模型 WP 在 10 个场景中优于所有其它模型。重要的是,该模型在未引入额外参数的情况下,超越了常规 LSTM 模型,这突出了 WP 基于注意力的池化方法的优势。
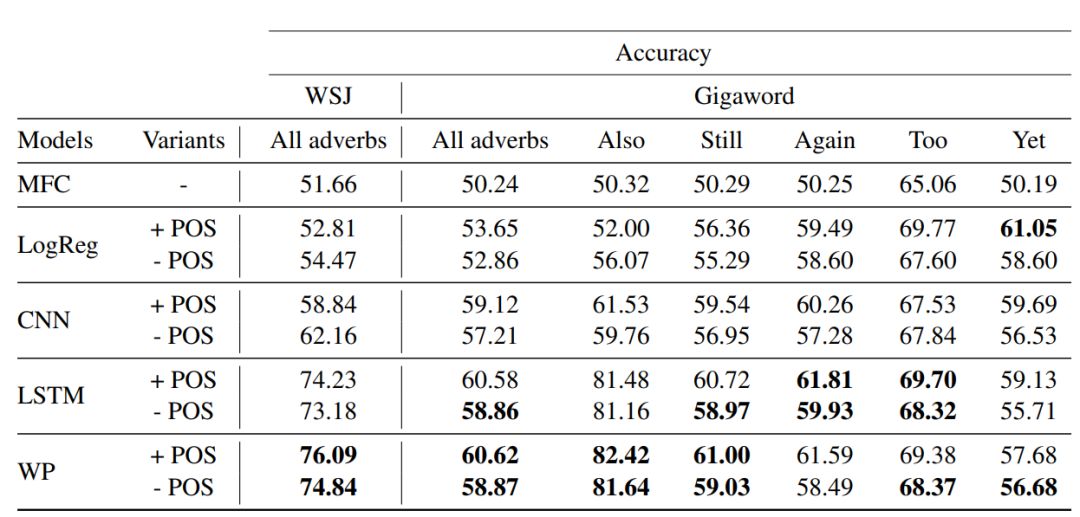
表 2:各种模型的性能,包括加权池化的 LSTM(WP)模型。MFC 指最常见的基线,LogReg 是 logistic 回归基线。LSTM 和 CNN 对应强大的神经网络基线模型。请注意,我们把每个「+ POS」案例和「- POS」案例中最佳模型的性能数字加粗显示了。
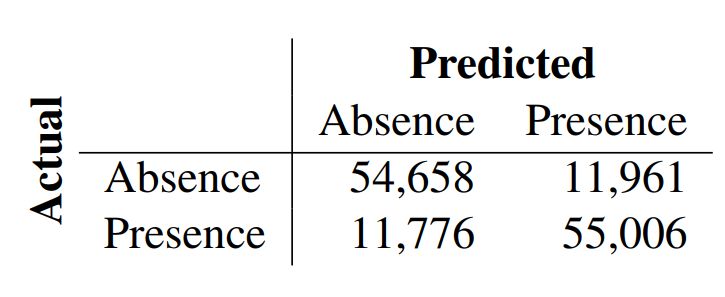
表 3:最佳模型的混淆矩阵,预测预设触发语是否存在。
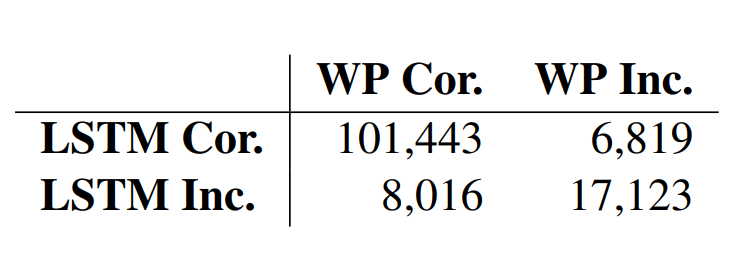
表 4:在 Giga_also 数据集上 LSTM 基线模型与注意力模型(WP)正确预测(cor.)和错误预测(inc.)的列联表。
参考内容:https://acl2018.org/2018/06/10/best-papers/
本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





