智能文档新成员:动态文档智能模型MarkupLM

编者按:自2019年以来,微软亚洲研究院在“智能文档”领域进行了诸多探索,提出了通用文档理解预训练模型 LayoutLM,以及多语言通用文档理解预训练模型 LayoutXLM。然而,除了诸多视觉效果固定不变的文档外,现实中还存在大量实时渲染的动态视觉富文本文档,直接套用过去如 LayoutLM 系列模型中采用的基于二维空间坐标的布局编码对动态文档进行建模是不现实的。为此,微软亚洲研究院的研究员们开发了一种全新模型 MarkupLM,可直接对动态文档的标记语言源代码进行处理,不需要任何额外的计算资源即可渲染生成动态文档的实际视觉效果。实验结果表明,MarkupLM 显著优于过去基于网页布局的方法,且具有高实用性。
视觉富文本文档(Visually Rich Document)因其包含大量的文本、布局、格式信息而成为人们日常工作生活中十分常用且重要的文件形式,然而处理这类文档(如提取信息,校对数据等)却需要耗费大量的人力与时间成本。因此,一类旨在使得机器理解并自动处理视觉富文本文档的需求便应运而生,被称为“文档智能(Document AI)“。自2019年以来,微软亚洲研究院的研究员们已对此进行了诸多探索,并开发出了基于多模态预训练的富文本文档理解模型 (Visually-rich Document Understanding, VrDU) LayoutLM、LayoutLMv2,及多语言通用文档理解预训练模型 LayoutXLM 等一系列相关模型,成功地在诸如表单、收据、发票、报告等视觉富文本文档数据集上取得了优良的表现。
然而,除了上述的诸多视觉效果固定不变的文档之外,还存在大量的实时渲染的动态视觉富文本文档,如基于 HTML 的网页,或基于 XML 的 Office 文件等。这些动态文档的特点是,它们并不包含一个硬编码的图像,而是以标记语言(Markup Language)代码的形式储存的。以图1为例,相同的网页在不同设备(如手机、平板、个人电脑等)上渲染得到的视觉效果会有所差异;此外,当需要处理大量的动态文档时,先统一进行渲染也会消耗巨额的计算资源。因此,直接套用过去如 LayoutLM 系列模型中采用的基于二维空间坐标的布局编码对动态文档进行建模是不现实的。
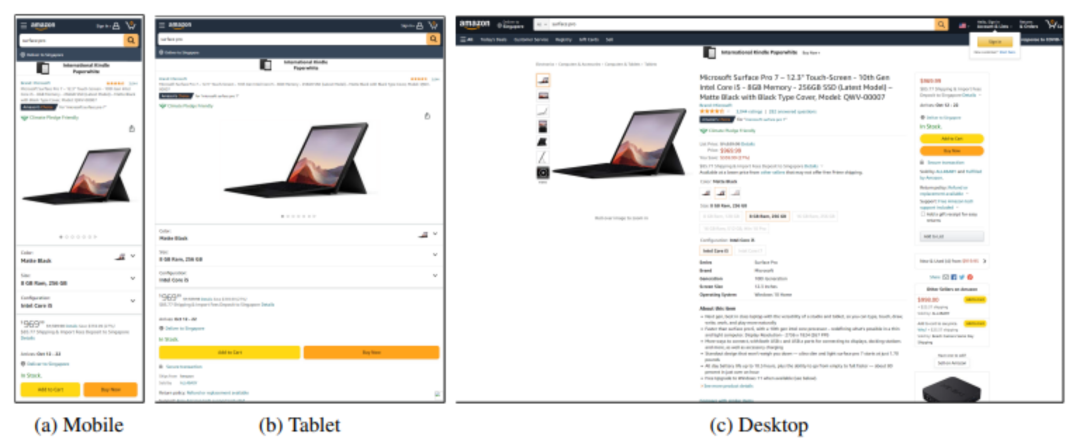
图1:同一网页在不同设备上的显示效果
(https: //amzn.to/2ZZoi5R)
根据动态视觉富文本文档的特点,微软亚洲研究院的研究员们开发出了一种全新的模型 MarkupLM。MarkupLM 直接对这些文档的标记语言源代码进行处理,不需要任何额外的计算资源即可渲染生成动态文档的实际视觉效果。通过从标记语言中提取树状结构的文档对象化模型(Document Object Model,DOM),并利用 DOM 对文档中的每个节点输出一个用于定位的 XPath(XML Path Language)表达式,MarkupLM 能够快速得到动态文档中每段文本在 DOM 树中的位置信息,并将其与对应的文本联合编码,从而极大地增强了模型对文档的建模能力。
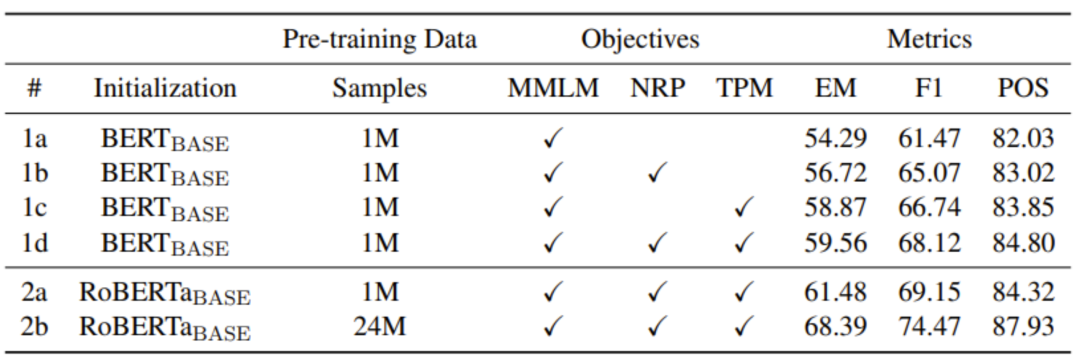
除了针对性设计的模型结构,研究员们也希望 MarkupLM 能自动地从大规模的无标注动态文档中学习可以广泛适用于相关下游任务的表征。作为最常见的动态文档,网页自然而然成为了 MarkupLM 的训练数据。研究员们采用了目前最大规模的网页数据集 CommonCrawl 作为训练集。除此之外,研究员们也从词、节点、文档三个层次构建了适应性的预训练任务,帮助 MarkupLM 从多维度理解与学习动态文档。

论文链接:
https://arxiv.org/abs/2110.08518
代码&模型链接:
https://aka.ms/markuplm
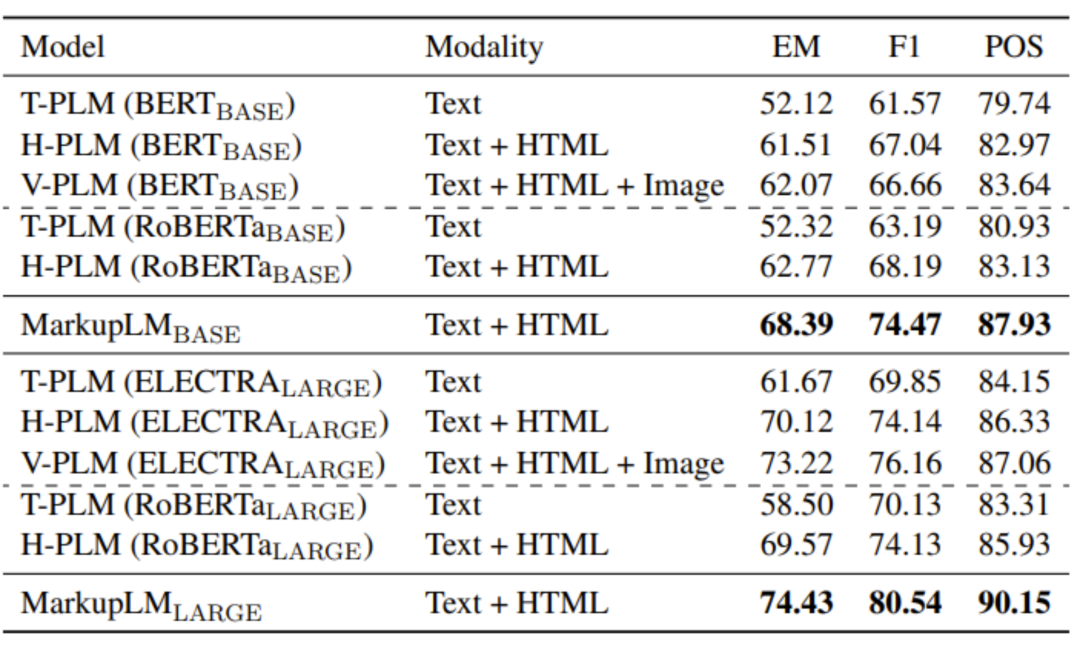
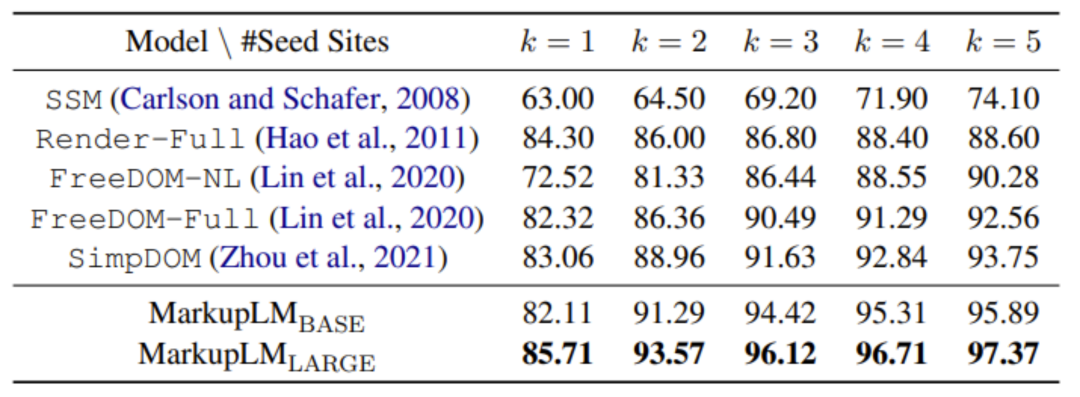
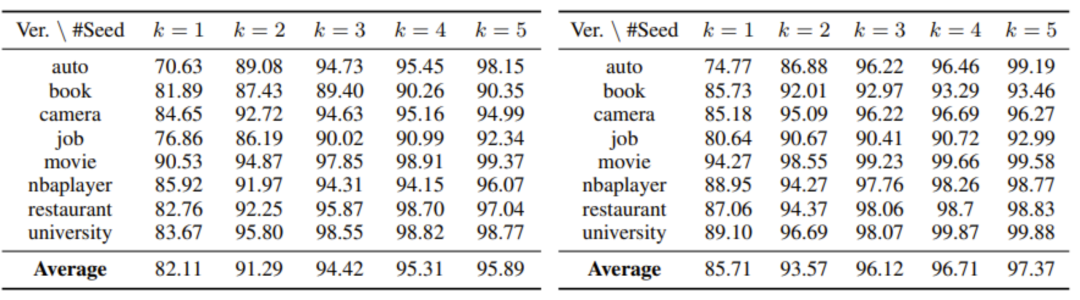
为了验证训练得到的 MarkupLM 的性能,研究员们在两种不同的下游任务上进行了实验,包括基于网页的阅读理解(WebSRC)与结构化网页信息提取(SWDE)。实验结果表明,MarkupLM 显著优于过去基于网页布局的方法,此外,在仅使用标记语言信息时 MarkupLM 取得了比采用渲染后图像联合编码的基线模型更好的性能,体现了它的高实用性。

与常见的预训练语言模型一样,MarkupLM 采用了与 BERT、RoBERTa 一致的 Transformers 架构。为了在模型中加入基于标记语言的布局信息,研究员们在 Embedding 层中额外加入了一个 XPath Embedding 模块,将每个词对应的 XPath 进行编码,并将该 Embedding 与原有的文本、位置,以及词类型 Embedding 相加,得到最终输入 Transformers Block 的词表征。图2展示了 MarkupLM 的总览结构,需要注意的是,由于用于参数初始化的 RoBERTa 模型中仅包含一种词类型 Embedding,因此在图中并未将其特别标出。
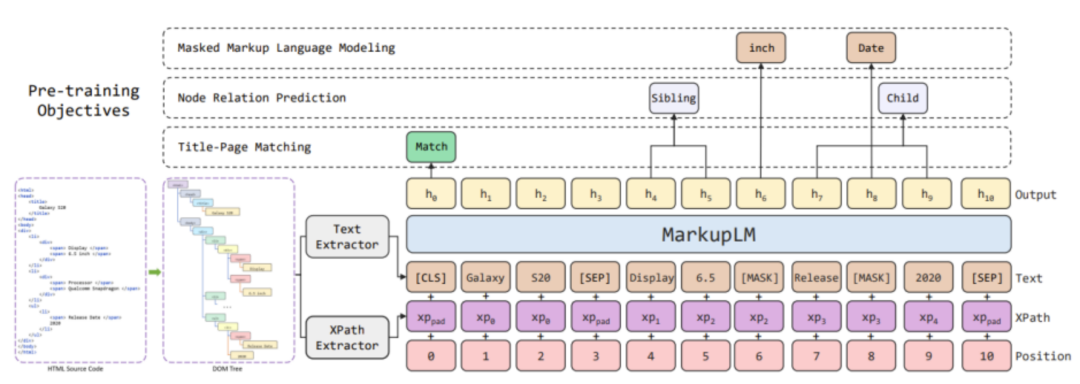
图2:MarkupLM 模型结构及相关预训练任务示意图
XPath Embedding编码
给定一个视觉富文本文档,模型首先将根据 DOM 树以深度优先遍历的方式抽取纯文本作为主要输入,同时也一并得到各个节点与 XPath 之间的对应关系。如图3所示,“6.5 inch” 对应的 XPath 表达式即为“/html/body/div/li[1]/div/span[2]”。
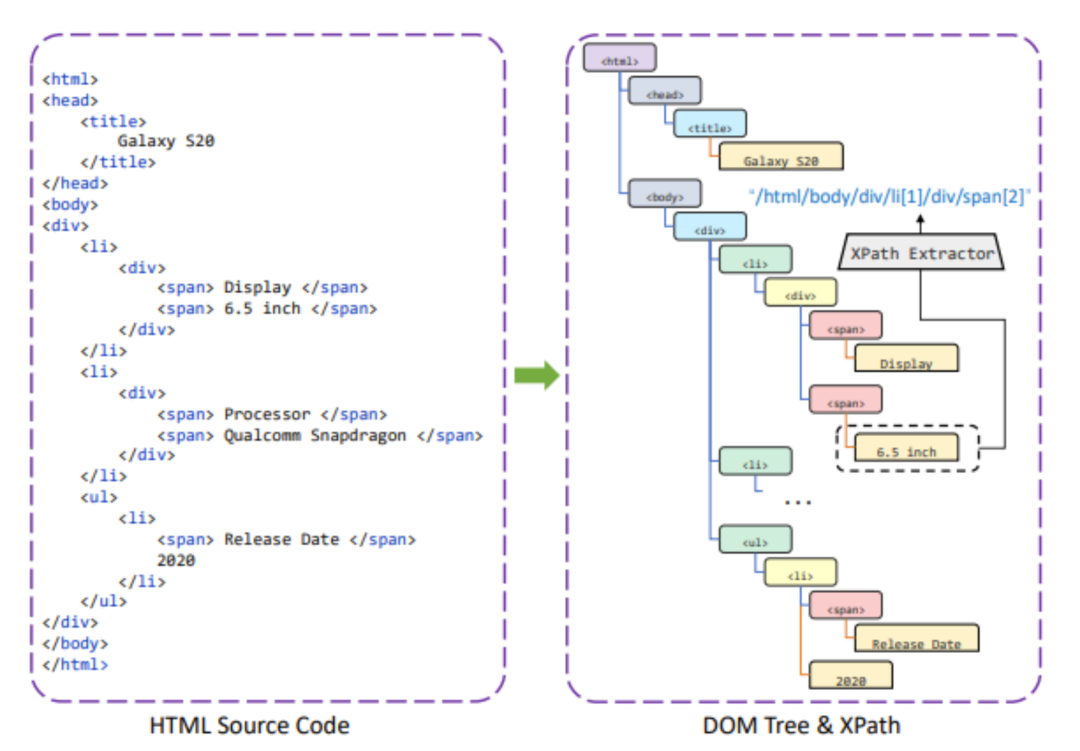
图3:抽取文本及 XPath 的示例
将 XPath 转换为 Embedding 向量的示例可参见图4。对于一个 XPath 表达式,模型首先将其按层级切分,得到不同深度上的 XPath 单元,而每个单元又包含了标签的名称及下标。对于无下标的单元,则统一将其下标设置为0。在每层深度上,XPath Embedding模块均含有一个独立的标签嵌入表与下标嵌入表。因此每个 XPath 单元均会产生两个向量,分别表示名称与下标,随后两个向量相加即可得到各 XPath 单元的表征。为了保留单元之间的层次信息,该模块随后会将所有单元的表示按原有位置进行拼接操作,得到整个 XPath 表达式的表示向量。最后,考虑到该表示向量与其他原有 Embedding 向量之间的维度不一致,模型采用了一个前馈神经网络(FFN)层将该向量的维度进行转换,从而保持统一,该过程中引入的非线性激活函数也进一步增强了模型的表达能力。
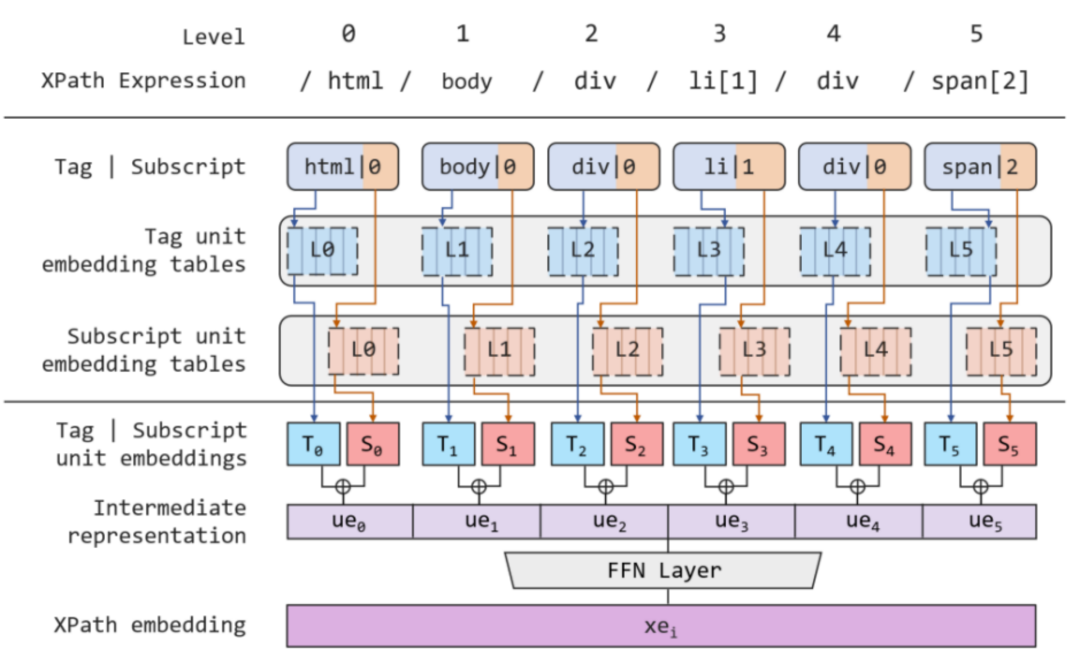
图4:将一 XPath 表达式编码为 Embedding 的示意图
在预训练任务的选择上,研究员们从多角度出发,分别构建了词级别的掩码标记语言模型、节点级别的节点关系预测,以及文档级别的标题页面匹配三大任务。
掩码标记语言模型(Masked Markup Language Model, MMLM)
在未来的研究中,微软亚洲研究院的研究员们还将对基于动态编码的 PDF 和使用 XML DOM 作为骨干的 Office 文档的 MarkupLM 预训练进行研究,发掘这一类文档的通用处理办法。另外,MarkupLM 和基于布局的模型(如 LayoutLM)之间的关系也十分值得探索,下一步研究员们将深入了解这两种模型是否可以在统一的多视图和多任务设置下进行预训练,以及这两种模型的知识是否可以相互转换,以更好地理解结构信息。
微软亚洲研究院自然语言计算组(Natural Language Computing Group)正在招聘研究员和实习生,欢迎对文档智能、图像和文本预训练等领域感兴趣的同学加入我们。
全职岗位详情:
https://careers.microsoft.com/students/us/en/job/1127939/Researcher-MSRA-Full-Time-opportunity-for-graduates
https://careers.microsoft.com/students/us/en/job/1127940/Research-Software-Development-Engineer-MSRA-Full-Time-opportunity-for-graduates
实习岗位详情:
https://www.msra.cn/zh-cn/jobs/interns/nlc-research-intern-20170522
简历投递邮箱:
lecu@microsoft.com









