跨语言的多模态、多任务检索模型MURAL解读

通常,从一种语言到另一种语言没有直接的一对一翻译。即使有这样的翻译,它们也不一定准确,对于非母语人士来说,不同的联想和内涵很容易丢失。但是,在这种情况下,如果是基于可视化的实例,其含义可能会更为清晰。
就拿“wedding”(婚礼)这个单词来说吧。在英语中,人们通常会联想到穿着白裙的新娘和穿着燕尾服的新郎,但是翻译成印地语(शादी)时,更恰当的联想可能是穿着鲜艳色彩的新娘和穿着高领长外套(印度男装 Sherwani)的新郎。
对于这个单词,每个人的联想可能有很大的不同,但是如果给他们一个想要表达的概念的图像,它的意义就会更清楚。

“婚礼”这个单词在英语和印地语中表现出不同的心理意象。
随着当前神经机器翻译和图像识别技术的发展,在翻译过程中可以通过提供一段文本和一幅支持图像来减少这种歧义。已有的研究已经在高资源语言(如英语)学习图像 - 文本联合表示方面取得了很大进展。
这些表示模型努力将图像和文本编码为共享嵌入空间的向量,使得图像和描述它的文本在这个空间中相互接近。ALIGN 和 CLIP 表明,当有足够的训练数据时,在图像 - 文本对上使用 对比学习损失 来训练双编码器模型(即通过两个独立的编码器训练的模型),效果非常好。
遗憾的是,对于大多数语言来说,这类图像 - 文本对数据的规模并不相同。实际上,90% 以上的这类网络数据属于资源丰富的前十种语言,比如英语和汉语,而资源不足的语言的数据则少得多。
要解决这一问题,我们可以试着为资源不足的语言手动收集图像 - 文本对数据,但是由于这项工作的规模,难度太大,或者我们可以设法利用现有的数据集(例如翻译对),这类数据集能够为多种语言提供必要的学习表示。
在 EMNLP 2021 提交的论文《MURAL:跨语言的多模态、多任务检索》(MURAL: Multimodal, Multitask Retrieval Across Languages)中,我们描述了一种用于图像 - 文本匹配的表示模型,该模型将多任务学习应用于图像 - 文本对,并与涵盖 100 多种语言的翻译对相结合。这项技术允许用户通过图像来表达那些不能直接翻译成目标语言的词语。
例如,“valiha”一词是指马尔加什人所演奏的一种 管状乐器,在大多数语言中不会有直接的翻译,但是可以通过图像轻松地描述出来。在实践中,MURAL 表现了比最先进的模型、其他基准和竞争基线全面持续改进。而且,MURAL 在它所测试的大多数资源不充足的语言中表现良好。此外,我们还发现了由 MURAL 表示学到的有趣的语言相关性。
MURAL 架构是基于 ALIGN,但以多任务的方式使用。ALIGN 使用双编码器架构将图像和相关文本描述的表示结合起来,而 MURAL 使用双编码器架构来实现同样的目标,并通过合并翻译对将其扩展到其他语言。图像 - 文本对的数据集与 ALIGN 所用的数据集相同,而翻译对则是用于 LaBSE 的数据集。
MURAL 解决了两个对比学习任务:
1)图像 - 文本匹配;
2)文本 - 文本(平行文本)匹配。
这两项任务共享文本编码器模块。该模型从图像 - 文本数据中学习图像和文本之间的联系,以及从翻译对中学习数百种不同语言的表示。其思想是,共享编码器将把从高资源语言中学到的图像 - 文本关联转移到低资源语言。
结果表明,最好的模型使用了 EfficientNet-B7 图像编码器和 BERT-large 文本编码器,这两者都是从头开始训练。所学到的表示可用于下游的视觉和视觉语言任务。
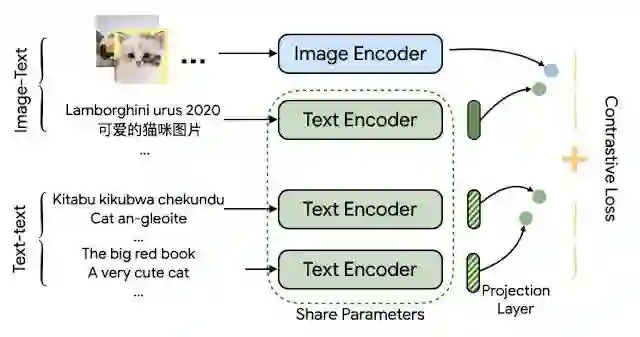
MURAL 架构描述了双编码器,两个任务之间有一个共享的文本编码器,使用对比学习损失进行训练。
为了展示 MURAL 的能力,我们选择了跨模态检索的任务(即基于文本检索相关的图像,反之亦然),并报告了在各种学术图像 - 文本数据集上的得分,这些数据集涵盖了资源丰富的语言,如 MS-COCO(及其日文变体 STAIR)、Flickr30K(英语)和 Multi30K(扩展到德语、法语、捷克语)、XTD(仅测试集,包含七种资源丰富的语言:意大利语、西班牙语、俄语、汉语、波兰语、土耳其语和韩语)。
除了资源丰富的语言外,我们还在最近发布的维基百科图像文本(Wikipedia Image–Text,WIT)数据集上对 MURAL 进行了评估,该数据集涵盖了 108 种语言,包括资源丰富(英语、法语、汉语等)和资源不足(斯瓦希里语、印地语等)的语言。
MURAL 在对资源丰富和资源不足的语言进行评估时,无论是在 零样本学习 设置还是 微调 设置方面,MURAL 总是优于先前 M3P、UC2 和 ALIGN 等最先进的模型。我们发现,相对于最先进的模型 ALIGN,资源不足的语言有着显著的性能提升。
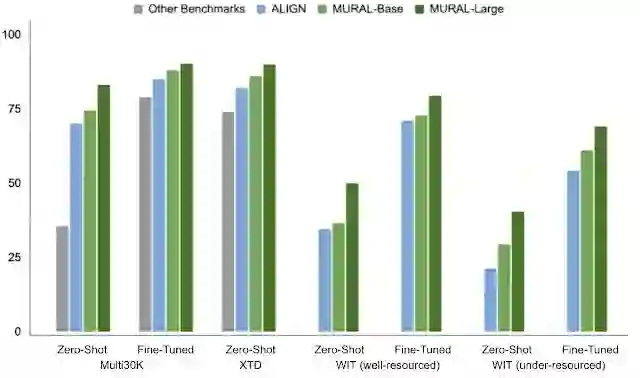
各种多语言图像 - 文本检索基准的平均召回率。
平均召回率是用于评估图像 - 文本数据集的跨模态检索性能的常用指标(越高越好)。它衡量的是六个测量值的平均值的 Recall@N(即基础真理图像出现在前 N 个检索图像中的概率):N=[1, 5, 10] 的图像→文本和文本→图像检索。请注意,XTD 的分数报告了文本→图像检索为 Recall@10。
我们还分析了 WIT 数据集 上的零样本检索实例,比较了 ALIGN 和 MURAL 对英语(en)和印地语(hi)的检索。MURAL 比 ALIGN 具有更好的检索性能,反映了对文本语义的较好把握,如印地语等资源不足的语言。

在 WIT 数据集的文本→图像检索任务中,用 ALIGN 和 MURAL 检索到的前 5 张图像的比较,以印地语文本为例。在 WIT 数据集的文本→图像检索任务中,ALIGN 和 MURAL 对印度语文本进行了比较,印度语文本是:“एकतश्तरी परबिना मसाले या सब्ज़ी के रखी ह सादी स्पगॅत्ती”,翻译成英文是“A bowl containing plain noodles without any spices or vegetables”(一碗没有任何香料或蔬菜的普通面条)。
甚至对于像法语这样资源丰富的语言中的图像→文本检索,MURAL 也显示出对某些单词有更好的理解。例如,MURAL 对 “cadran solaire”(法语,英文为“sundial”(日晷))的查询的结果比 ALIGN 要好,因为后者检索不到任何描述日晷的文本(如下图)。

同一张日晷图片上,ALIGN 和 MURAL 在图片→文本检索任务中的前 5 个文本结果的比较。
此前,研究人员已经表明,模型嵌入的可视化能够揭示语言之间的有趣联系——例如,由 神经机器翻译(neural machine translation,NMT)模型学习的表示已经被证明可以根据它们在某一 语言系属分类 中的成员身份来形成集群。
对于属于日耳曼语系、罗曼语系、斯拉夫语系、乌拉尔语系、芬兰语系、凯尔特语系和芬兰 - 乌戈尔语系(在欧洲和西亚广泛使用)的一个语言子集进行了类似的可视化处理。我们将 MURAL 的文本嵌入与 LaBSE 的文本嵌入进行比较,后者是一个纯文本的编码器。
LabSE 的嵌入图显示了受语言系属分类影响的不同语言集群。例如,罗曼语(紫色,下同)与斯拉夫语(棕色,下同)属于不同的区域。这一发现与 之前研究 由 NMT 系统学习的中间表示的研究结果相吻合。
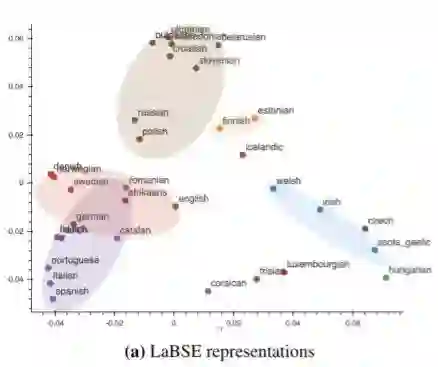
35 种语言的 LaBSE 文本表示的可视化。
语言根据其谱系关系用颜色编码。代表性的语言有:日耳曼语(红色)——德语、英语、荷兰语;乌拉尔语(橙色)——芬兰语、爱沙尼亚语;斯拉夫语(棕色)——波兰语、俄语;罗曼语(紫色)——意大利语、葡萄牙语、西班牙语;盖尔语(蓝色)——威尔士语、爱尔兰语。
相对于 LaBSE 的可视化,MURAL 的嵌入更注重多模态的学习,表现出一些符合 区域语言学(某一地理区域内的语言或方言共享元素)和 接触语言学(语言或 方言 相互影响)的集群。
值得一提的是,在 MURAL 嵌入空间中,罗马尼亚语(ro)比 LaBSE 更接近保加利亚语(bg)和马其顿语(mk)等斯拉夫语言,这符合 巴尔干语言联盟 的情况。另外一种可能的语言接触是芬兰语,爱沙尼亚语(et)和芬兰语(fi),它们更接近斯拉夫语言集群。
MURAL 以图像和翻译为轴心这一事实似乎为语言关联性增添了额外的观点,因为它是在深度表示中学习的,超越了在纯文本环境中观察到的语族集群。
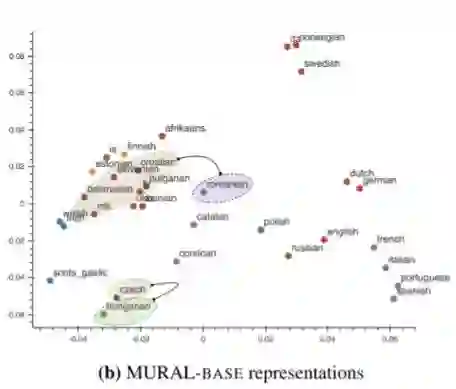
35 种语言的 MURAL 文本表示的可视化。颜色编码与上图相同。
我们的研究结果表明,使用翻译对进行联合训练可以有效地克服许多资源不足的语言中图像 - 文本对的稀缺性,并提高跨模态性能。此外,在使用多模态模型学习的文本表示中,观察区域语言学和接触语言学的提示也很有意思。因此,需要进一步探索通过多模态模型(如 MURAL)隐式学习到的各种联系。
最后,我们希望这项工作能促进多模态、多语言空间的深入研究,在这个空间里,模型学习语言的表示和语言之间的联系(通过图像和文本表示),而不仅仅是资源丰富的语言。
作者介绍:
Aashi Jain, 谷歌 AI Resident 成员。
Yinfei Yang,谷歌研究院研究科学家。
原文链接:
https://ai.googleblog.com/2021/11/mural-multimodal-multi-task-retrieval.html

你也「在看」吗?👇




