加入极市专业CV交流群,与10000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
【极市导读】同行评审作为科学研究不可或缺的一部分已经持续有300年。但是即使在引入同行评审之前,论文的可复现性也一直作为科学方法中的一项重要组成部分。机器学习是否面临复制危机?作者重新研究了255篇最新论文,并分享了他对可重复研究的意义的见解。
同行评审作为科学研究不可或缺的一部分已经持续有300年。但是即使在引入同行评审之前,论文的可复现性也一直作为科学方法中的一项重要组成部分。Jabir Ibn Haiyan提出了最早的可复现实验。
在过去的几十年中,许多领域都遇到了不可复现的结果。例如,美国心理学会一直在努力与未能提供数据的作者进行斗争。
2011年的一项研究发现,只有6%的医学研究可以完全复现。2016年,对来自多个学科的研究人员进行的一项调查发现,大多数研究人员对于他们自己以前的文章,至少会有一篇无法复现结果。现在,我们听到警告,人工智能(AI)和机器学习(ML)也面临着研究结果复现性危机。
于是我们不由得要问:这是真的吗?似乎让人难以置信,因为ML不断介入我们的生活,甚至渗透到每个智能设备中。从关于如何礼貌写邮件时的提示,到埃隆·马斯克(Elon Musk)承诺在明年进行无人驾驶汽车的尝试。从这些方面来看,机器学习研究成果似乎的确是可复现的呀。
那么,最新的ML研究复现性如何?是否可以对复现性因素进行量化分析?这个问题驱动我撰写了NeurIPS 2019的论文。由于偏执和受虐倾向,我花了8年时间尝试从头开始实现各种ML算法,最后做了一个ML库,叫做JSAT。我对ML研究可复现性的调查还依赖于我自己记录的一些笔记。有了这些数据再加上本能的冲动,我便开始了量化和验证可重复性的不归路!我也很快认识到,我这是在研究科学本身,从事的是超自然科学。
什么是可复现的机器学习?
在深入研究之前,重要的是定义可复制性的含义。理想情况下,完全可重复性意味着仅阅读科学论文即可获得所需的全部信息,包括:1)建立相同的实验,2)采用相同的方法,然后3)获得相似的结果。
如果我们仅根据本文中提供的信息就可以进入第3步,则可以说其具有独立可重复性。我们的结果是可重复的,因为我们能够获得相同的结果,而我们的结果是独立的,因为我们这样做是完全独立于原始出版物。
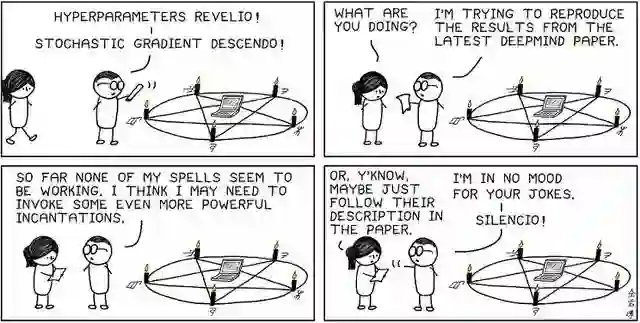
但是,正如我们上面漫画中的朋友可能告诉我们的那样,有些时候仅遵循论文的内容并不能复现相似结果。如果我们无法通过仅使用论文中的信息(或引用的先前工作)进入第3步,那么我们将确定该论文不可独立复现。
有人可能会奇怪,为什么要在可复现性和独立可复制性之间进行区分?几乎所有的AI和ML研究都基于计算机代码。我们不需要昂贵且费力的化学合成工作,而无需等待培养皿中的细菌成熟或那些讨厌的人体试验。对于计算机研究,我们可以简单地从作者那里获取代码,对相同的数据运行代码,并获得相同的结果应该很容易!
克里斯·德拉蒙德(Chris Drummond)将使用作者代码的方法描述为可复制性(replicability),并提出了一个非常突出的论点,即复制(replicability)是好的,但不足以实现形成好的科学。一篇论文被认为是对工作的科学精炼,代表了我们已经学到并且理解的能够实现这些新成果的文字内容。如果没有作者的代码我们就无法复现论文结果,则可能表明论文本身并未成功捕捉到重要的科学贡献。更不要说,代码中可能存在使结果受益的错误,或者代码与论文之间可能存在的许多其他差异。
去年来自ICML的另一个很好的例子表明,即使我们可以复制论文结果,稍微改变实验设置也可能会产生截然不同的结果。由于这些原因,我们不想考虑作者的代码,因为这可能会引起偏差。我们希望专注于可复现性问题,而不用纠缠于可复制性很多可操作的方面。
什么使ML论文具有再复现性?
我研读了2017年之前的每一篇论文,并尝试重现结果。我利用两个标准对论文进行了过滤:通过查看已发布的源代码是否会让结果有偏差,或者是否与作者有个人关系。
对于每篇论文,我都记录了尽可能多的信息,以创建一组可量化的特征。有的是完全客观的(论文上有多少位作者),而有的则是非常主观的(论文看起来有威慑力)?该分析的目的是尽可能多地获取有关可能影响论文可复现性的信息。通过这种方法,筛选出了255篇论文和162篇成功的可复现作品。每篇论文都被提炼出26种特征,并进行了统计测试以确定哪些因素是重要的。在右边的表格中,我已经列出了我认为最有趣和最重要的结果,以及我的最初反应。
有些结果并不让人很意外。例如,作者的数量对论文的可重复性没有显著的关系。调节超参数可以改变算法行为,但是算法本身无法学习如何调节超参数。取而代之的是,我们人类必须设定这些参数值(或设计一种巧妙的方式来选择它们)。一篇论文是否详细说明了所用的超参数很重要,因为如果您不告诉读者怎么设置,读者必须猜测。这需要额外的工作、时间并且容易出错!因此,我们的研究结果也证明了科研圈一直在追求的做法,我们需要使论文更具复现性。
我恳请您阅读本文以进行更深入的讨论,但是我认为还有一些其他结果特别有趣。要么是因为它们挑战了我们对"好论文"评价,要么是得出了一些令人惊讶的结论。
出现这种情况是因为可读性高的论文使用的方程式最少。出于多种原因,我们经常看到列出了许多方程和导数的论文。似乎,谨慎和聪明地使用方程式会使事情更容易阅读,这主要是因为您可以选择使用数学来更有效地进行交流。这项发现与发表论文所提倡的做法相冲突。审稿人不止一次要求我在论文中加入更多的数学知识。数学本身可能使论文更加科学,或者更客观,但是它与可重复性并不相容。这是科研圈需要解决的"文化"问题。
发现2:面向经验(实验)的论文比面向理论的论文更具可复现性
人们一直争论关于论文严谨程度的问题。注意力关注在给定的测试集上,如何得出最优的结果,并且理解背后的原理。人们普遍认为,详尽的数学证明可以确保对特定方法的更好理解,有趣的是,更高的数学上指导并不一定会使研究更容易复现。理论工作和形式证明虽不能包括"严谨"一词可能涵盖的所有方面。但普遍认为,详尽的数学证明可以确保对特定方法的更好理解。有趣的是,更高的数学规格并不一定会使研究更容易复现。这里的重点是,我发现:理论和经验并重的论文的总复现率与纯经验论文的复现率相同。
通过开源代码进行的复现与独立进行的复现是两码事。我的研究结果表明,开源代码充其量只是可重复性的一个弱指标。随着学术会议更加强烈地鼓励将代码审查作为论文评审的一部分,我也认为这是至关重要的一点。我们需要了解通过这些努力我们的目标是什么,以及我们实际上做到了哪里。如果我们曾经强制执行代码审查,并且我们给审稿人提供了评估此类代码的指导,则应再进一步仔细思考代码复现和独立复现的区别。
发现4:拥有详细的伪代码与没有伪代码的可复现概率一样
这个发现挑战了我对什么是"好论文"的评判标准的质疑,但细细想来又很有道理。在计算机研究中,我总是更喜欢使用一种称为伪代码的描述。基于伪代码的不同形式我将论文分为四类:None,Step-Code, Standard-Code 和Code-Like。让我感到震惊的是Standard-Code和Code-Like的复现率大致相等,并且发现所有的None都一样好!
写作和沟通技巧在对复现性也很重要。其中所谓的"Step-Code"往往会列出步骤的项目符号列表,每个步骤都引用了文章的另一部分。这让阅读和理解论文变得更加困难,因为读者现在必须在不同部分之间来回跳转,而不是遵循单个顺序流程。
这是另一个令人惊讶的结果。我一直很赞赏能够将一个复杂的想法转化为更简单、更易消化的形式的作者。我同样欣赏那些创建了"玩具问题(toy problem)"的论文。玩具问题易于可视化和实验实现,一定程度上也体现了某些属性。从主观上讲,简化的示例对于理解论文工作很有用。
复现玩具问题是创建可用于调试的较小测试用例的有用工具。从客观的角度来看,简化的示例似乎对论文的可复现性没有任何帮助。实际上,它们甚至无法使论文更具可读性!我仍然很难理解和解释这个结果。这正是为什么对我们这个研究圈子来说量化这些问题很重要。如果我们不进行量化工作,我们将永远不会知道我们的工作正在解决与当前科研最相关的问题。
我要讨论的最后一个结果是,回复问题对论文的可重复性有很大的影响。由于并非所有论文都对其方法进行了完美描述,因此可以得到相同结果。我向50位不同的作者发送了电子邮件,询问有关如何再现其结果的问题。在我没有得到回复的24个案例中,我只能复现其中一篇论文的结果(成功率为4%)。
对于得到作者回复的其余26个案例,我能够成功复现其中的22篇论文(成功率为85%)。我认为这个结果对于论文发布过程本身的含义最为有趣。如果我们允许已发表的论文可以更新,而又不成为某种"新"出版物呢?这样,作者就可以将常见的反馈和问题纳入原始论文中。这对于发布在arXiv上的论文已经成为可能。会议出版物也应如此。这么做是可以通过提高可复现性来潜在地推动科学发展的,但前提是我们允许它们发生。
从中可以学到什么?
这项工作受到了标题"人工智能面临可复现性危机"的启发。这是仅仅是标题党还是指向该领域的系统性问题呢?完成这项工作后,我倾向于有改进的空间,但是AI / ML领域的工作要比大多数学科做得更好。
62%的成功率高于其他科学领域的许多分析,而且我怀疑我得到的62%这个数字低于实际情况。其他比我更熟悉这些专业领域的研究者也许可以在我失败的地方获得成功。因此,我认为62%的估计是一个下限。
我想说的很清楚:这些结果中的任何一个都不应该作为"什么是可复现,什么是不可复现"的明确陈述。有大量可能影响这些结果的潜在误差因素。最明显的是,这255次的复现尝试都是由一个人完成的。
对于分析师之间的内部一致性还没有统一标准。我发现容易复现的内容可能对其他人来说很难,反之亦然。例如,我无法复现我尝试的任何基于贝叶斯或基于公平的论文,但我不认为这些领域是不可复现的。背景、教育、资源、兴趣等,都与我获得的结果密不可分。
也就是说,我认为这项工作为科研界的许多挑战提供了有力的证据,同时也验证了这个科研界中正在进行的许多可复现性工作。最大的因素是,我们不能接受关于所谓可复现ML的所有假设。这些假设需要进行检验,我希望这项工作能够激发其他人开始自己量化和收集这些数据。我们处于非常独特的位置,可以对自己进行"元科学"研究。复现的成本对我们而言比任何其他科学领域都低得多。我们在这里学到的东西也许可以从AI和ML领域扩展到计算机科学的其他子领域。
最重要的是,我认为这项工作让我们认识到了评估研究可复现性的难度。孤立地考虑每个特征是进行此分析的相当简单的方法。这项分析已经提供了许多潜在的见解,意想不到的结果和复杂性。但是,它并没有考虑基于作者论文之间的相关性,并没有将数据表示为图形,甚至仅仅只是查看当前特征的非线性相互作用!这就是为什么我试图将许多数据公开,以便其他人可以进行更深入的分析。
最后,已经有人指出,我可能创建了有史以来最不可重复的ML研究。但实际上,这项工作引发了许多关于我们如何进行"元科学"的科学、如何实施和评估研究的问题。因此,希望您能阅读我的论文以获取更多详细信息和讨论。随着新的AI和ML研究的雪崩式地增长,我们学习所有这些论文的能力将高度依赖于我们将繁杂知识精简为可消化形式的能力。同时,我们的流程和系统必须保证产生出可复现的工作,并且不会使我们误入歧途。我想在这个领域做更多的工作,希望您能加入我的行列。
Edward Raff博士是Booz Allen Hamilton的首席科学家,University of Maryland, Baltimore County (UMBC)的客座教授,并且是JSAT机器学习库的作者。Raff博士带领着Booz Allen机器学习研究团队,同时还为有高级ML需求的客户提供支持。他获得了普渡大学的计算机科学学士和硕士学位,以及UMBC的博士学位。读者可以在Twitter @EdwardRaffML上关注他。
https://thegradient.pub/independently-reproducible-machine-learning/
*延伸阅读
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()