没有GPU也能发顶会?看看这篇CVPR 2020论文,给你答案!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

整理不易,希望点个在看或者转发,支持一下
前言
昨天整理并推送了1467篇CVPR 2020论文合集和270篇代码开源的CVPR 2020论文项目,大家反映内容很赞,里面不仅提供了"授之以鱼"的下载资源,还提供了"授之以渔"的检索方法。
所以后续Amusi 不会做细分方向的论文大盘点,因为懂得检索方法,直接就很容易查到了你所需要的论文,详见:270篇CVPR 2020代码开源的论文,全在这里了!
话题回到标题:没有GPU还能发顶会么?
Amusi 先说一下自己观察到的现状(背景):
1. 自从2012年AlexNet提出后,大多数CV方向的研究都被深度学习冲击了,特别是2014年开始,大量基于DL的论文呈井喷状态。这一点很好验证,看数十篇基于深度学习的CV综述,里面论文大多数都是从2014年开始的。
2. 基于DL的论文,注定亟需要显卡(GPU)。跑一些大模型、大数据集,你需要的卡自然是越多越好。这样硬件要求,国内大多数实验室一开始是无法满足的,即使到现在,Amusi 都觉得很多高校的实验室都是"缺卡状态"。
3. 顶会-名企/名校金字塔加剧。首先,要承认名企/名校的人才是超级强的,本身就具备发顶会的能力,所以起初就是金字塔模型;但Amusi想说的是在"深度学习"时代,一个"看卡"的时代,这个金字塔更陡峭了。
Amusi 很想吐槽一句:国内不少实验室里,一个人可能都分不到一块显卡(不提啥显卡了,提就是贫富差距),老板给的任务难度还那么大...
正文
吐槽完了,下面回到了本文要介绍的论文,一篇非深度学习的CV论文。这是CVPR 2020上图像拼接方向的一篇论文,据Amusi调查,这是CVPR 2020上唯一一篇图像拼接的论文。

作者团队:韩国蔚山科技大学(UNIST)
论文链接:
http://openaccess.thecvf.com/content_CVPR_2020/papers/Lee_Warping_Residual_Based_Image_Stitching_for_Large_Parallax_CVPR_2020_paper.pdf
图像拼接是一个至少有20年以上研究期的传统CV方向,主要步骤涉及:特征提取和描述、特征匹配、图像配准、图像融合等模块。其中各个模块都可以看成更基础性的CV方向,都可以单独发文章,比如特征提取和描述就是近年来很明显从传统方法到深度学习方法的见证,分别代表作:SIFT和D2-Net。
关于图像拼接更详细一点的流程图,可参考OpenCV中的stitching模块

OpenCV 图像拼接教程
可能因为图像拼接涉及的模块过多,而且还涉及"如何更好解决warping问题(偏几何)",Amusi 当前都没有看到一篇基于深度学习端到端的图像拼接论文。可能这个方向现在比较冷门了,没有大佬跟进了,但Amusi觉得难度还是超级大的。
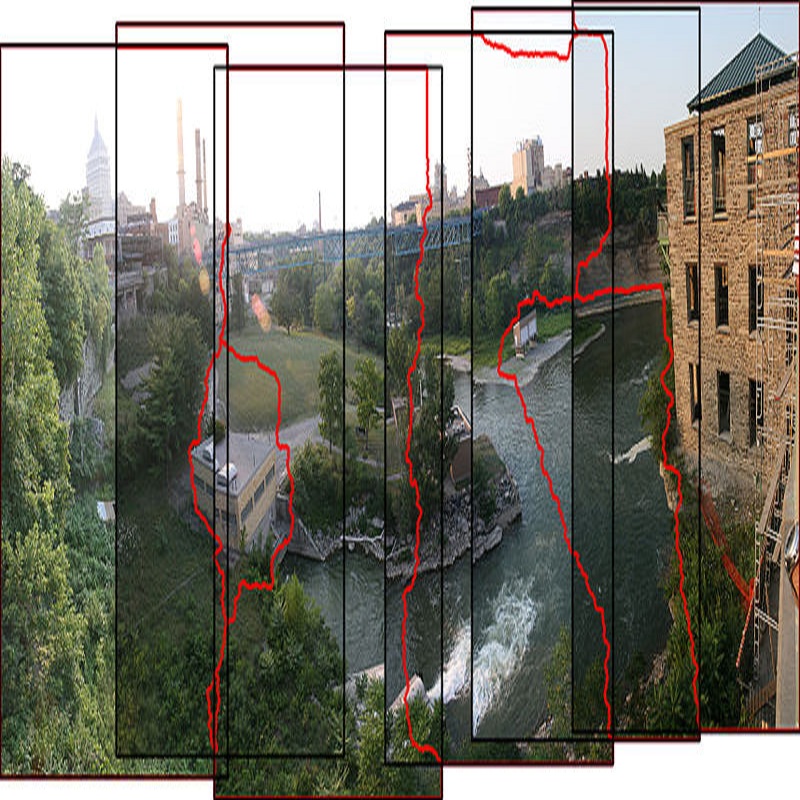
这篇CVPR 2020论文要解决的就是图像拼接非常非常棘手的问题:视差(Parallax)
视差问题其实很好理解,如下图所示,左图中的红色建筑在高建筑物的左侧;右图中的红色建筑在高建筑物的右侧。这样看起来是不是很难拼接?

本文基于Warping残差的新概念提出了一种对大视差具有鲁棒性的图像拼接算法。
首先估计多个单应性(homography),然后找到两个图像之间的内在特征匹配。然后,针对多个单应性评估每个特征匹配的Warping残差。

为了减轻视差伪影,将输入图像划分为多个超像素(superpixels),并根据最佳单应性自适应地warping每个超像素,该单应性是通过最小化由Warping残差加权的特征匹配误差来计算的。

实验结果表明,该算法可以为大视差图像提供准确的拼接效果,并且在质量和数量上均优于现有方法。


这里不对原文进行过多的介绍,因为需要你具有MDLT、SLIC等论文知识点的基础,有意思的是引入超像素(superpixels ),感兴趣的同学建议反复阅读原论文进行理解。
其实去年还推过一篇非深度学习的论文,CVPR2019 Oral | SWF:边窗滤波,一篇非深度学习的论文
侃侃
本文介绍了一篇CVPR 2020上的非深度学习CV论文,只是想告诉大家做传统图像处理还是有希望发顶会的。吐槽归吐槽,但考虑到就业找工作,Amusi 主观说一句,在"深度学习"时代大背景下,你如果入门还是用OpenCV等做一些传统图像处理的工作,我建议一定要同时学习好深度学习,现在绝大多数公司的计算机视觉岗位都是偏向深度学习的。
看到非深度学习的CV顶会,又激动又感慨...
论文下载
在CVer公众号后台回复:拼接01,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer一个在看!