2022 年了,怎样才能做到真正的“永不宕机”?

互联网技术发展到了 2021 年,上云也更加普遍,但宕机事件却似乎没怎么减少。
这一年 10 月,拥有 30 亿用户的脸书 (Facebook) 遭遇大规模宕机,中断服务约 7 小时后大部分服务才重新上线。据说,这是 Facebook 创办以来最严重的一次网络访问事故,导致脸书一夜之间市值蒸发约 473 亿美元 (约合 3049 亿元人民币)。
而在更早些时候,国内某视频网站也因机房故障导致网站崩溃,大量用户“流浪”到其他网站,巨大的流量洪峰又让其他平台也连锁式瘫痪了。此外,拥有 15 万家客户的 Salesforce 在这一年也遭遇了一次长达 5 个小时的全球性质的宕机事故,在线游戏平台 Roblox 还曾发生过长达 73 小时的宕机事故......
互联网技术发展到现在,理论上来说是可以做到“永不宕机”的,但为什么还有这么多规模大、时间长的系统故障发生?如何减少宕机事故的发生?InfoQ 采访了阿里云全局高可用技术团队,谈谈如何保证复杂系统中的业务可持续性。
云计算的蓬勃发展,催生了越来越多的“国民级应用”,但传统的灾备架构已很难满足业务快速恢复的需要。
有统计数据表明,96% 的企业曾在过去三年中至少经历过一次系统中断。对于小型企业来说,一小时的宕机时间会平均造成 25,000 美元的损失。对于大型企业来说,平均成本可能高达 540,000 美元。如今,停机时间越长,这意味着产生永久性损失的可能性越大。
然而宕机事故又不可预测,因此它也被称为系统中的“黑天鹅”。阿里云全局高可用技术团队负责人周洋表示,当前大型互联网系统架构日趋复杂,稳定性风险也在升高,系统中一定会有一些没被发现的黑天鹅潜伏着。
虽然预测不了“黑天鹅”什么时候会出现,但是能从故障中去寻求一些分类,并有针对性地对一类问题进行防御。比如现在的容灾架构就是一种灾难防御手段,它主要针对的是机房级的故障场景。
机房级的故障场景,从 IDC 的维度上看,主要有机房入口网络故障、机房间网络故障以及机房掉电。如果精细化到应用层,又可以分为接入网关故障、业务应用故障以及数据库故障等,背后的故障原因可能是软件 BUG 或者部分硬件故障,比如机柜掉电、接入交换机故障等等。
容灾架构的目标是,在单机房出现任何故障的情况下,能够快速恢复业务,保障 RTO 和 RPO。
RTO(恢复时间目标)是指用户愿意为从灾难中恢复而花费的最长时间。一般来说,数据量越大,恢复所需的时间就越长。
RPO(恢复点目标)是指在发生灾难时用可以承受的最大数据丢失量。例如,如果用户可以承受 1 天的数据丢失,RPO 就是 24 小时。
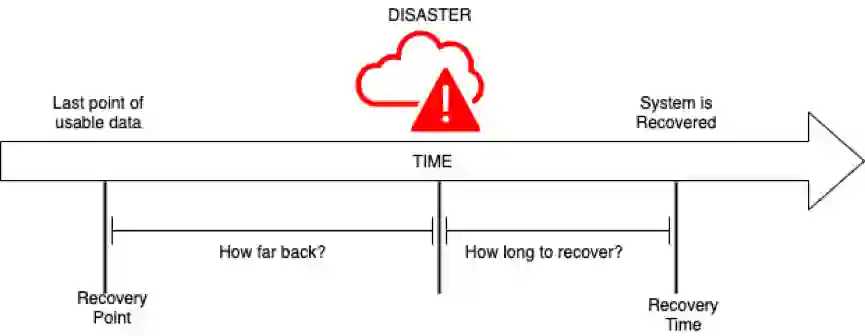
RTO 和 RPO
针对不同种类的故障,灾备行业有三种不同等级的防御方式:数据级、应用级、业务级。现在业内主流的容灾架构还是灾备容灾,属于数据级的容灾方案。由于灾备中心平时不工作,应用服务的完整性和运行状态未知,在发生故障的关键时刻会面临敢不敢切的问题。
有些企业会因为无法确定能否承载流量而不敢切,有些决定切换的企业也可能因为备用机房的应用状态不对而不能完全恢复业务,最终造成的影响就是 RTO 或者 RPO 较长,反应给外界就是大型“宕机”事件。
2021 年,国内外多家知名公司、云平台出现较严重服务中断、宕机事件,为企业敲响了警钟,越来越多的企业把容灾建设提上日程。在解决容灾问题的同时,为保持对成本的控制、支撑未来的多云架构演进和灾难容灾的确定性,许多企业选择尝试采用多活容灾的方式。
当灾难发生时,多活容灾可以实现分钟级的业务流量切换,用户甚至感受不到灾难发生。应用多活针对不同的部署场景有三大典型架构:在同城机房物理距离小于 100 公里的场景下建设同城应用多活,在异地机房物理距离大于 300 公里的场景下建设异地应用多活,在混合云多云融合的场景下建设混合云应用多活。在多活模式下,资源不闲置不浪费,而且能够突破单地域的机房容量限制,从而获得跨地域的容量扩展性。
多活容灾在阿里内部实践了多年。
早在 2007 年到 2010 年,阿里巴巴就采用同城多活架构支撑业务容量和可用性。
到了 2013 年,由于机房容量有限以及杭州机房有限电风险,阿里巴巴开始探索异地多活的架构方案,那就是后来大家都知道的所谓“单元化”。单元化架构在 2014 年完成了试点验证,2015 年正式在千里之外实现三地四中心,从而具备了生产级别的异地多活能力,2017 年完成了在双 11 凌晨切流。
2019 年,阿里巴巴系统全面上云,异地多活架构跟随上云的节奏孵化成阿里云云原生产品 AHAS-MSHA,服务阿里巴巴和云上客户,先后帮助数字政府、物流、能源、通信、互联网等十余家不同行业中的大型企业成功构建应用多活架构,包括菜鸟乡村同城应用多活、联通新客服异地应用多活、汇通达混合云应用多活等。
在采访阿里云全局高可用技术团队时,大家普遍的感受是,“业内对于多活没有统一的认知,并且重视度不够。”
首先,不同的人对于“多活”这个词会有不同的定义,人人都说自己是“多活”,可当故障来临的时候,才发现当前系统并不是真正的多活。其次,有些企业并不了解异地多活,有些了解的企业会认为异地多活的成本高、难落地。还有些企业在了解“多活”之后,下意识想要先在企业内部投入资源进行技术预研,抗拒云厂商的商业化产品输入。
“多活”的认知偏差会让使用者错用或者不用,从而享受不到“多活”带来的稳定性红利。
在阿里云全局高可用技术团队看来,应用多活将成为云原生容灾领域的趋势,与其等待趋势到来,不如通过开源来推动应用多活的发展。他们希望通过开源协同,形成一套应用多活的技术规范和标准,使得应用多活技术变得更易用、通用、稳定和可扩展。
2022 年 1 月 11 日,阿里云将 AHAS-MSHA 代码正式开源,命名为 AppActive。(项目地址:https://github.com/alibaba/Appactive)这也是开源领域首次提出“应用多活”概念。

阿里云也曾在 2019 年开源了自己的混沌工程项目 ChaosBlade(https://github.com/chaosblade-io/chaosblade),旨在通过混沌工程帮助企业解决云原生过程中的高可用问题。AppActive 更偏防御,ChaosBlade 更偏攻击,攻防结合,形成更加健全的落地安全生产机制。
AppActive 的设计目标是多站点生产系统同时对外提供服务。为了达到这一目标,技术实现上存在流量路由一致性、数据读写一致性、多活运维一致性等难点。
为应对以上挑战,阿里云全局高可用技术团队做了各类技术栈的抽象以及接口标准定义。
周洋介绍,他们将 AppActive 抽象为应用层、数据层和云平台 3 个部分:
应用层是业务流量链路的主路径,包含接入网关、微服务和消息组件,核心要解决的是全局流量路由一致性问题,通过层层路由纠错来保障流量路由的正确性。其中,接入网关,处于机房流量的入口,负责七层流量调度,通过识别流量中的业务属性并根据一定流量规则进行路由纠错。微服务和消息组件,以同步或异步调用的方式,通过路由纠错、流量保护、故障隔离等能力,保障流量进入正确的机房进行逻辑处理和数据读写。
数据层核心要解决的是数据一致性问题,通过数据一致性保护、数据同步、数据源切换能力来保障数据不脏写以及具备数据容灾恢复能力。
云平台是支撑业务应用运行的基石,由于用云形态可能包含自建 IDC、多云、混合云、异构芯片云等形态,云平台容灾需要进行多云集成和数据互通,在此基础来搭建和具备云平台、云服务 PaaS 层的容灾恢复能力。

应用多活应对的 6 大灾难故障
目前 AppActive 处于 v0.1 版本,开源内容包括上述应用层和数据层在数据平面上的所有标准接口定义,并基于 Nginx、Dubbo、MySQL 提供了基础实现。开发者可基于当前的能力,进行应用多活的基本功能运行和验证。
短期内,AppActive 的规划会对齐应用多活标准,提升 AppActive 的完整性,具体包括以下几点:
丰富接入层、服务层、数据层插件,支持更多技术组件到 AppActive 支持列表。
扩充应用多活的标准和实现,比如增加消息应用多活的标准和实现。
建立 AppActive 控制平面,提升 AppActive 应用多活实现的完整性。
遵循应用多活 LRA 标准扩展支持同城多活形态。
遵循应用多活 HCA 标准扩展支持混合云多活形态。
未来,阿里云将不断打磨 AppActive,努力使之成为应用多活标准下的最佳实践,以达到规模化生产可用的严格要求;也会顺应云的发展趋势,探索分布式云,实现跨云、跨平台、跨地理位置的应用多活全场景覆盖。
随着“无容灾不上云”共识的逐渐达成,阿里云希望帮助更多企业的应用系统构建应对灾难故障的逃逸能力,也希望能跟 GitHub 社区里的开发者共建应用多活容灾标准,
延展阅读:
阿里云《应用多活技术白皮书》:
https://developer.aliyun.com/topic/download?spm=a2c6h.12873639.0.0.5b222e55fukQsa&id=8266
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!

点个在看少个 bug 👇




