4层小模型吊打BERT-large?亚马逊最新瘦身秘籍

最近一年多,BERT的瘦身方法层出不穷,主要围绕着三个方向:蒸馏、剪枝、量化。也有不少同学直接砍掉BERT的一些层再精调也能达到不错的效果。我就是“懒惰”的砍层一族,不过在实践中发现,取不同的层得到的效果差异很大,最多能差出7个点。于是最近也在思考,怎样可以在不穷举的情况下抽出效果最好的子模型?
老天就是这么眷顾爱思考的孩子,让我刷到了一个亚马逊新鲜出炉的论文:Optimal Subarchitecture Extraction For BERT。论文的摘要中写道:参数量只有large模型的16%,通过1.2%的时间预训练后,对比BERT-large有0.3%到31%的提升! 不能更exciting了有木有!

再跳到GLUE实验结果,简直是工业界福音:
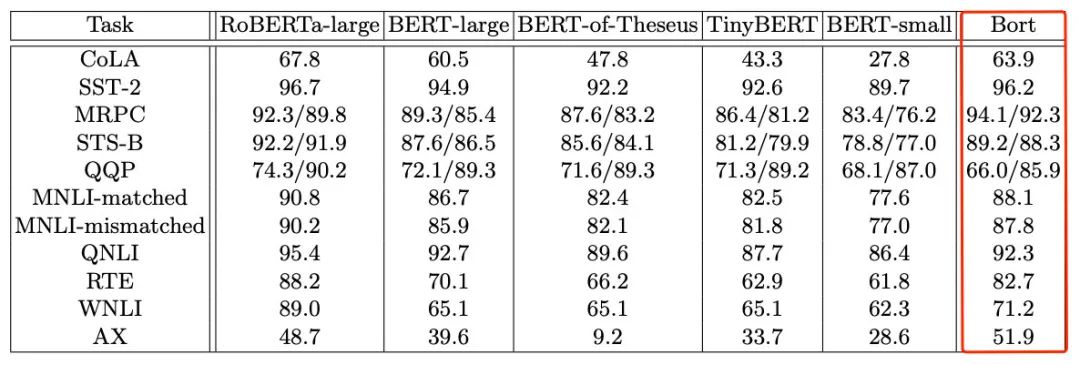
但。。是。。
在我快速(也没有快速,原理部分真的很煎熬)过了一遍论文后,发现文章的缺点和优点一样多。虽然作者给出了新的方法和一些有用的结论,但实验存在着两个主要问题:
-
对比不公平:BERT-large只在Wiki语料上进行训练,而作者预训练Bort的预料是原始BERT的十倍。同时BERT-of-Theseus、TinyBERT也是在分别基于原始BERT或者用Wiki语料训练的。无法证明是作者的方法好,还是用了更多的语料训练让效果更好。 -
没有消融实验:虽然文章主打“Optimal Subarchitecture Extraction”,但实际上作者也用了蒸馏预训练、以及一种名为Agora的蒸馏方法来精调,如果不做消融实验,怎么知道到底是子结构抽的好、还是蒸馏预训练好、还是Agora精调好?
不过从另一方面来说,作者确实通过各种方法,得到了一个效果很好的小模型Bort,其中使用的抽取、快速预训练、精调等流程也有值得借鉴的地方。
Good or not good?我进退两难。

接下来介绍一下作者训练模型的主要流程,同学们可以酌情在实践中参考。
论文题目:Optimal Subarchitecture Extraction For BERT
论文地址:https://arxiv.org/abs/2010.10499
源码地址:https://github.com/alexa/bort
论文中有引用作者的两个其他工作,大礼包请在公众号「李rumor」回复“bort”下载。
最优子结构的选取
作者在今年早些时候的论文“An Approximation Algorithm for Optimal Subarchitecture Extraction”中对OSE(Optimal Subarchitecture Extraction)问题进行了研究。先证明对于BERT这类模型来说OSE是可解的,然后提出了一个近似求解的算法,并证明了算法的复杂度(多项式时间)和近似边界。
作者的证明和讨论长达15页多,感兴趣的同学可以仔细看看,这里只说一下选取最优子结构的算法思想:
输入:模型结构,数据,参数,子结构搜索空间(层数/注意力头数/隐藏维度/Intermediate层维度),模型超参,最大训练步数s,loss,最优模型
输出:最优结果,包括参数、层数/注意力头数/隐藏维度/Intermediate层维度
流程:
1. 计算最优模型的参数量、推理时间
2. 根据最优模型的参数量对搜索空间中的候选排序
3. 对于每一组超参数:
4. 对于每一组子结构:
5. 将子结构训练s步
6. 根据子结构的参数量、推理时间,计算分数W(参数量越小、推理时间越小、和最优模型T最后一层的交叉熵越小则分数越高)
7. 选取分数W最高的作为最优子结构
P.S. 解读如有错误,欢迎在评论区指出
作者在论文中给出了Top3结果,可以发现4层是性价比较高的子结构:

预训练
得到了最优子结构后,作者用小模型对Roberta-large进行蒸馏,并得到了两个结论:
-
用小模型对Roberta-large蒸馏相比MLM收敛更快 -
只蒸馏最后一层的效果比每层都蒸馏要更好
在蒸馏预训练的设定下,小模型的训练效率更高,只是原始Roberta-large预训练时间(GPU hours)的1.2%:
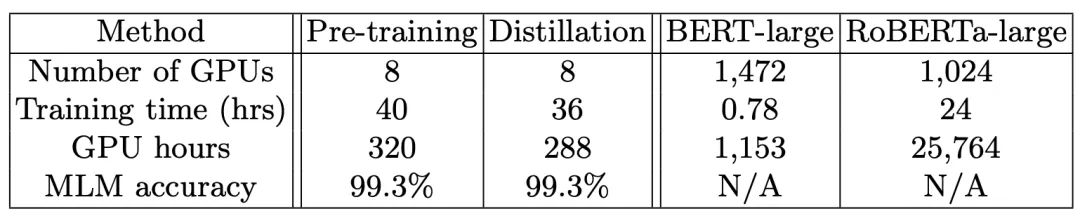
不过小模型本来就是Roberta抽出来的,收敛得快肯定也有这部分原因。
精调
在精调过程中,作者又引用了自己今年另一篇论文的算法Agora。该算法混合了数据增强和蒸馏,当二分类的数据很少或者存在数据不一致时,可以让student在大部分情况下逼近teacher模型的表现。
数学力Max的作者又给自己的算法配了10+页的证明,这里主要提一下作者数据增强的核心思想:
-
先根据超参数训练多个学生模型,选择acc最高的 -
用最好的学生模型对dev集打分,选出预测错的 -
让老师模型对上述数据重新预测,再将数据加入训练集
总结
作者的子结构和精调方法都略微复杂,需要不少计算量,最终得到的模型虽然比BERT-large和其他蒸馏模型好上很多,但相比它的teacher模型还是有不少差距。同时作者还提到,利用Agora精调很重要,说不定没用Agora效果就不如BERT-large了?
令人愉悦的是,作者已经把代码和模型都挂到github上了,但用的是亚马逊选型的Mxnet框架,给大家的复现之路加了一点阻力。

这个作者哥哥让我今天像坐过山车,经历了无数情绪转折,从兴奋到失落到无奈到疑惑,所以最后我去google了他:

居然有些帅???真是数学又好编程又好的有才小哥哥 =。=
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




