![]()
来源:腾讯
【新智元导读】腾讯首个AI开源项目Angel完成3.0版本迭代,近日从AI领域的顶级基金会LF AI基金会毕业了。Angel 3.0致力于打造一个全栈的机器学习平台,功能特性涵盖了机器学习的各个阶段,尤其在图机器学习方面功能强大。戳右边链接上 新智元小程序 了解更多!
腾讯开源项目Angel 近日从LF AI基金会毕业,也是中国首个从LF AI基金会毕业的开源项目。
LF AI基金会(Linux Foundation Artificial Intelligence Foundation)是Linux基金会旗下面向AI领域的顶级基金会,
这意味着,Angel得到全球技术专家的认可,成为世界最顶级的AI开源项目之一。
LF AI基金会执行总监Ibrahim Haddad表示:“在Angel从孵化到毕业的过程中,我们能看到Angel在新功能完善和应用场景落地方面惊人的速度。随着3.0版本的发布,Angel在功能、适用性和对社区的贡献等都有了非常优秀的表现。这也是整个AI开源社区在走向成熟并具备工业级生产能力的方向上迈出了一大步。”
Angel是腾讯的首个AI开源项目,于 2016 年底推出、2017年开源。
作为面向机器学习的第三代高性能计算平台,Angel致力于
解决稀疏数据大模型训练以及大规模图数据分析问题。腾讯在2018年成为LF AI基金会的创始白金会员之一,并于同年向基金会贡献了开源项目Angel。
腾讯云副总裁、腾讯数据平台部总经理蒋杰表示:“毕业是Angel新的开始,未来我们将进一步开放Angel在
图计算和联邦学习
领域的核心能力。”
据LF AI 基金会董事、腾讯AI专家肖涵介绍,LF AI基金会对开源项目的毕业流程有非常严格的规定,基于项目的技术含量、开源生态、社区互动等维度,严格评估项目的成熟度,最终由董事会投票决定能否准予毕业。能够从LF AI毕业,意味着项目已经得到全球技术专家的认可,成为最顶级的AI开源项目。
Angel在基金会的孵化过程中获得了快速发展,并完成了从2.0版本到3.0版本的跨越,从一个单纯的模型训练系统进化成包含从自动特征工程到模型服务的全栈机器学习平台。
LFAI & Angel
腾讯首个AI开源项目Angel:重点研发图机器学习
Angel的特征工程模块基于Spark开发,增强了Spark的特征选择功能,同时使用特征交叉和重索引实现了自动特征生成。这些组件可以无缝地整合进Spark的流水线。为了让整个系统更加的智能,Angel 3.0新增了超参数调节的功能。
在模型服务方面,Angel 3.0提供了一个跨平台的组件Angel Serving,不仅可以满足Angel自身的需求,还可以为其他平台提供模型服务。在生态方面,Angel也尝试将参数服务器(PS)能力共享给其他的计算平台,目前已经完成了Spark On Angel和PyTorch On Angel两个平台的建设。
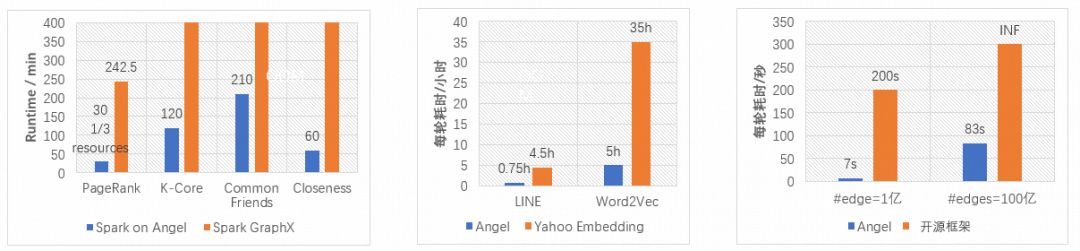
在3.0版本中,Angel重点研发了图机器学习功能,包括图表示和图神经网络学习模型,同时提供预处理、图挖掘等端到端数据处理能力,具有丰富的算法库,提供了同构图、异构图多种图计算范式和不同种类的图算法。经过腾讯内部业务的大规模实践,Angel在图算法性能上同样表现出众,例如十亿节点、千亿边规模的图结构,运行算法时能以Spark GraphX三分之一的计算资源,达到十倍处理性能。
除了技术功能上的完善,Angel在社区生态上也日趋成熟。据了解,在全行业Angel拥有超过 100家公司和机构用户,其中包括微博、华为、微众银行、小米、滴滴等大型互联网企业。基于Angel构建的一站式机器学习应用平台智能钛TI,支持了包括微信支付、腾讯广告、微视等在内的诸多腾讯内部产品,同时也通过腾讯云对外开放为更多行业企业提供服务。
截止目前,Angel在GitHub上已经获得了5500 Star,1400 Fork,在技术、应用、生态等方面的优秀表现均得到了开源社区的认可。此前在腾讯2019 Techo开发者大会上,蒋杰还宣布了资源管理平台核心TKE和分布式数据库TBase的正式开源。腾讯正在成为大数据领域开源最全面的公司。
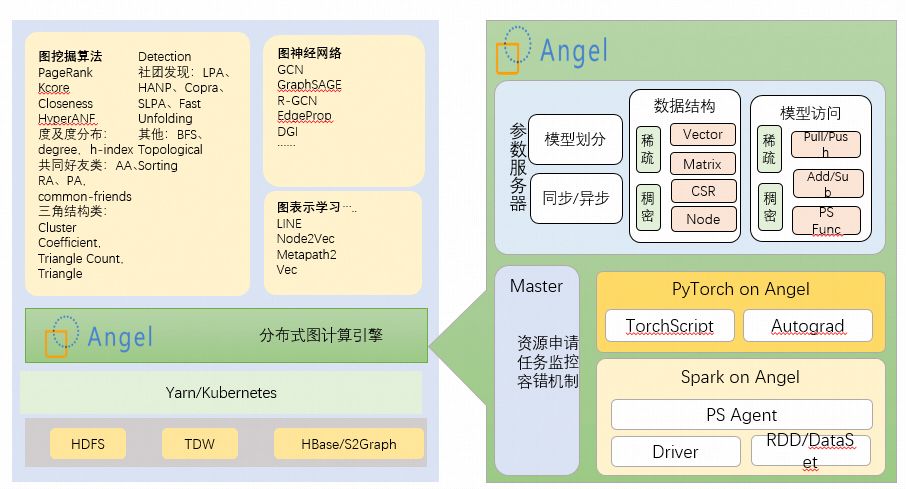
Angel是腾讯开源的大规模分布式机器学习平台,专注于稀疏数据高维模型的训练。目前Angel是Linux深度学习基金会孵化项目,相比于TensorFlow,PyTorch和Spark等业界同类平台,她有如下特点:
Angel是一个基于Parameter Server(PS)理念开发的高性能分布式机器学习平台,它具有灵活的可定制函数PS Function(PSF),可以将部分计算下推至PS端。PS架构良好的横向扩展能力让Angel能高效处理千亿级别的模型。
Angel具有专门为处理高维稀疏特征特别优化的数学库,性能可达breeze数学库的10倍以上。Angel的PS和内置的算法内核均构建在该数学库之上。
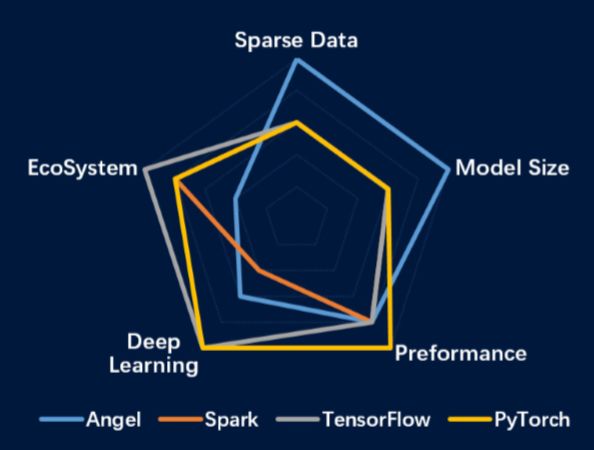
Angel擅长推荐模型和图网络模型相关领域(如社交网络分析)。图1是Angel和几个业界主流平台在稀疏数据,模型维度,性能表现,深度模型和生态建设几个维度的对比。Tensorflow和PyTouch在深度学习领域和生态建设方面优势明显,但在稀疏数据和高维模型方面的处理能力相对不足,而Angel正好与它们形成互补,3.0版本推出的PyTorch On Angel尝试将PyTorch和Angel的优势结合在一起。
Angel系统架构
Angel自研的高性能数学库是整个系统的基础,Angel的PS功能和内置的算法内核均是在这个数学库基础之上实现的。
Angel PS提供了高效,稳定和灵活的参数存储和交换服务。在3.0版本中,我们对Angel PS功能进行了扩展,使得它可以存储任意类型的对象,一个典型的例子是在图算法的实现过程中,我们使用Angel PS来存储了大量复杂的对象。
MLcore是Angel自研的一套算法内核,它支持自动求导,可以使用JSON配置文件定义和运行算法。除此之外,在3.0版本中,Angel还集成了PyTorch作为计算引擎。在计算引擎层之上是计算框架,它们可以看作计算引擎的容器,目前支持3种计算框架:原生的Angel,Spark On Angel(SONA)和PyTorch On Angel(PyTONA),这些计算框架可以使得Spark和PyTorch用户可以无缝切换到Angel平台。最上层是两个公共组件:AutoML和模型服务。
图5 GitHub上Angel的统计信息以及Angel发表的论文
从2017年6月开源以来,Angel受到了较多的关注,目前在GitHub上Star数超过4200,Fork数超过1000。Angel项目目前总共有38为代码贡献者,其他包括8位committer,他们总共提交了超过2000个commit。
从1.0到3.0,Angel发生了巨大的变化,它从一个单一的模型训练平台发展到涵盖机器学习各个流程,包含自己生态的通用计算平台,代码量也超过了50万行。为了后续维护和使用的方便,Angel拆分成8个子项目,统一放在Angel-ML目录下(https://github.com/Angel-ML):angel,PyTorch On Angel,sona,serving,automl,mlcore,math2和format,这些子项目会在下文详细介绍。
Angel 3.0新特性
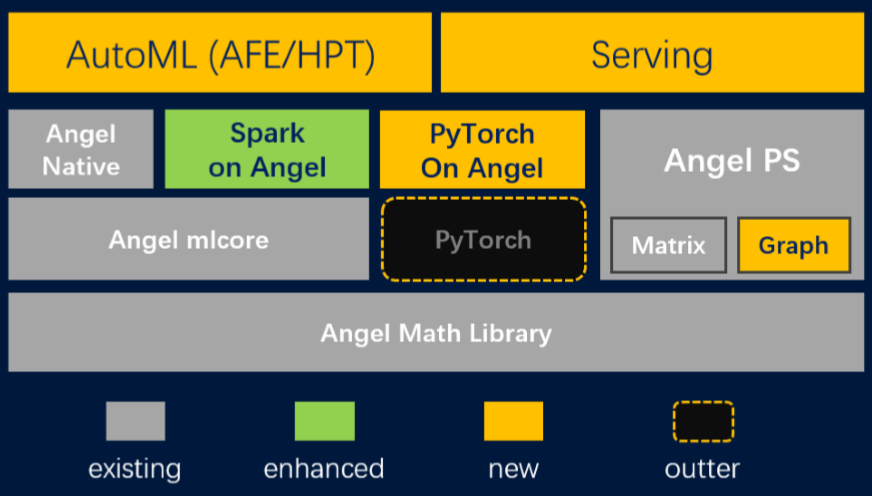
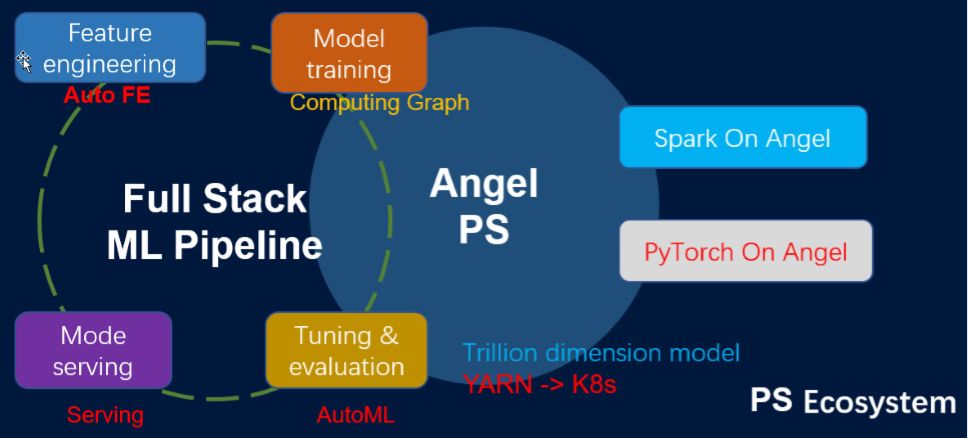
图6 Angel 3.0概览(红色的表示新增特性,白色的表示已有的但在持续改进的特性)
图6提供了一个Angel 3.0特性的整体视图。Angel 3.0试图打造一个
全栈的机器学习平台
,它的功能特性涵盖了机器学习的各个阶段:特征工程,模型训练,超参数调节和模型服务。
自动特征工程
特征工程,例如特征交叉和选择,对于工业界的机器学习应用具有重要意义。Spark提供了一些特征选择算子,但是仍有一些局限性。Angel基于Spark提供了更多的特征选择算子:
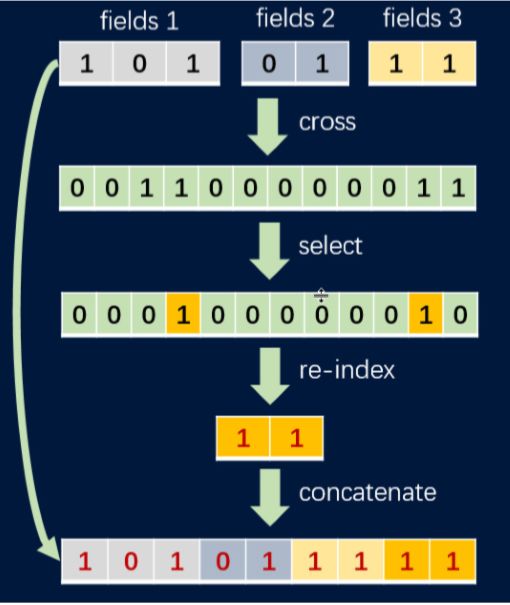
大多数在线推荐系统经常选择线性算法,例如逻辑回归作为机器学习模型,但逻辑回归需要复杂的特征工程才能实现较高的精度,这使得自动特征合成至关重要。但是,现有的自动化的高阶特征合成方法带来了维度灾难。为了解决这个问题,Angel实现了一种迭代生成高阶合成特征的方法。每次迭代由两个阶段组成:
扩增阶段:任意特征的笛卡尔积
缩约阶段:特征选择和特征重索引
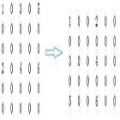
如图7所示,这种特征合成方法线性地增加特征数量,避免了维度灾难。在Higgs数据集上的实验表明合成的特征能有效地提高模型精度(如表1所示)。
Spark On Angel (SONA)
在Angel 3.0中,我们对Spark On Angel做了大幅度的优化,添加了下面这些新的特性:
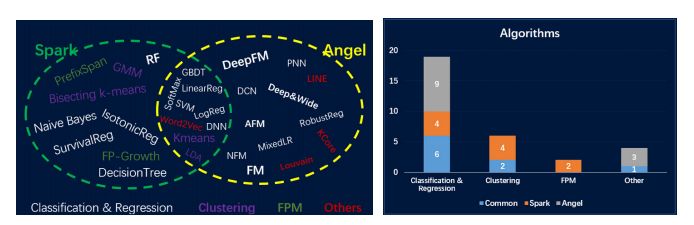
除了这些大的特征,我们也在持续完善Spark On Angel的算法库:添加了一些新的算法,如:Deep & Cross Network (DCN) 和 Attention Factorization Machines (AFM)等;同时对已有的算法做了大量的优化,例如对LINE和K-Core算法进行了重构,重构后的算法性能和稳定性都有大幅度提升。
从图9中可以看出,Spark On Angel中的算法与Spark中的算法存在显著的不同,如:基于Spark On Angel的算法主要是针对推荐和图领域,然而Spark中的算法更通用。
图9 Spark与Spark On Angel算法比较
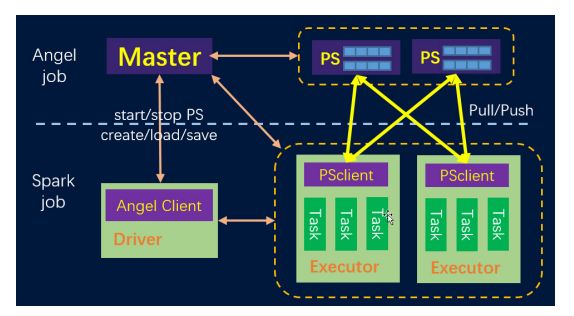
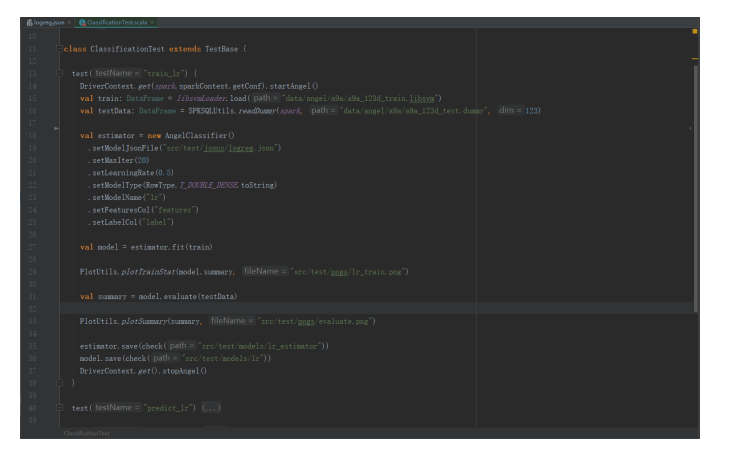
图10提供了一个基于Spark On Angel的分布式算法示例,主要包含以下步骤:
在程序开始时启动参数服务器,程序结束时关闭参数服务器
将训练集和测试集以Spark DataFrame形式加载
定义一个Angel模型并以Spark的参数设置方式为其设置参数。在这个示例中,算法是一个通过JSON定义的计算图
使用“fit”方法来训练模型
使用“evaluate”方法来评估已训练的模型
在训练完成后,Spark On Angel将会展示多种模型指标,如:准确率, ROC 曲线, AUC等。用户可以保存训练好的模型以便下次使用。
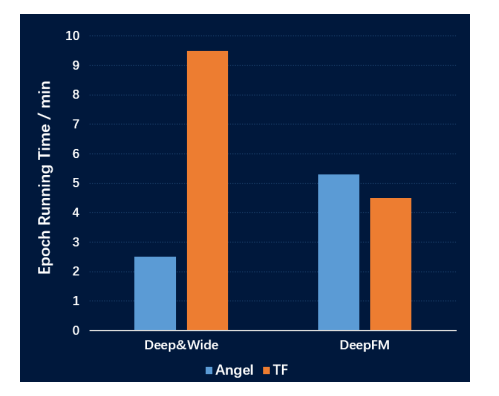
图11 Spark On Angel和TensorFlow性能比较
我们在两种流行的推荐算法Deep & Wide 和 DeepFM上使用了相同的资源和数据集比较了Spark On Angel和Tensorflow的性能。如图11所示,在Deep & Wide算法上Spark On Angel比Tensorflow快3倍,而在DeepFM算法上Tensorflow运行稍快一些。
PyTorch On Angel(PyTONA)
PyTorch On Angel是Angel 3.0新增的特性,它主要是为了解决大规模图表示学习和深度学习模型训练问题。
在过去几年时间,图卷积神经网络(GNN)快速发展,一系列的研究论文以及相关的算法问世:例如GCN,GraphSAGE和GAT等,研究和测试结果表明,它们能够比传统图表示学习更好的抽取图特征。腾讯拥有庞大的社交网络(QQ和微信),同时拥有大量对图数据进行分析的需求,而图表示学习正是这些分析的基础,因此腾讯内部对GNN有着强烈的需求,这也是我们开发PyTorch On Angel的主要原因之一。
大规模图的表示学习面临着两个主要的挑战:第一个挑战来自于超大规模图结构的存储以及访问,这要求系统不仅能存得下,还需要提供高效的访问接口,例如需要提供高效的访问任意节点的两跳邻居的接口;第二个挑战来自于GNN计算过程,它需要有高效的自动求导模块。
通过对Angel自身状况以及对业界已有系统的分析,我们得到如下结论:
为了将两者的优势结合起来,我们基于Angel PS开发了PyTorch On Angel平台,基本思路是使用Angel PS来存储大模型,使用Spark来作为PyTorch的分布式调度平台,也就是在在Spark的Executor中调用PyTorch来完成计算。
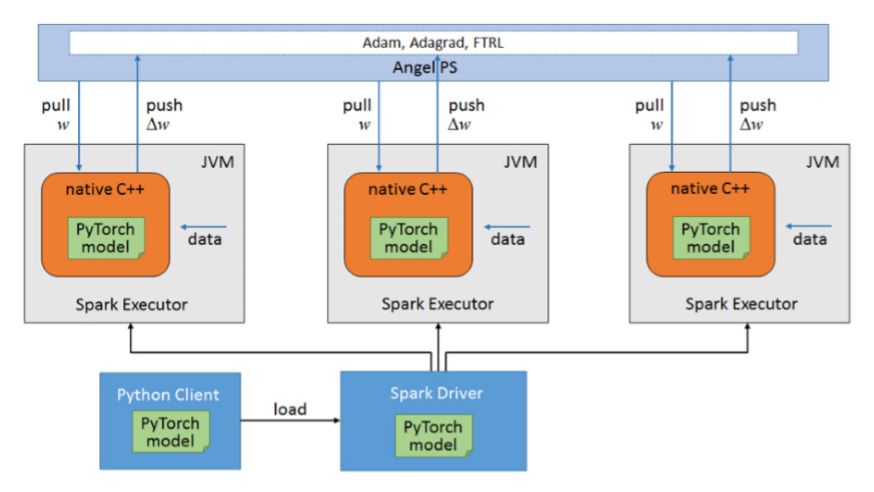
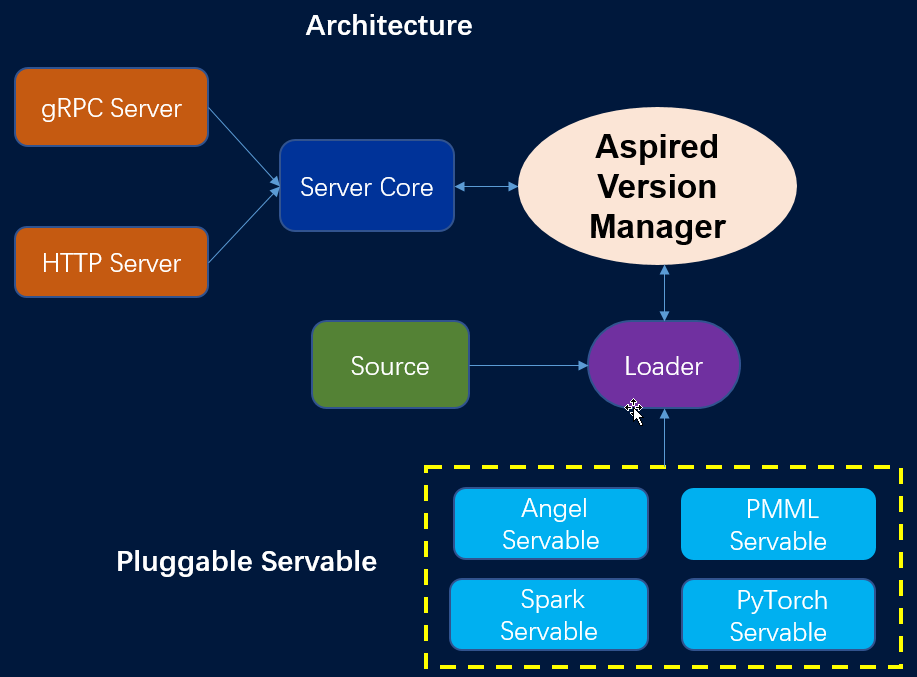
PyTorch On Angel的架构如图12所示:
PyTorch On Angel拥有3个主要的组件:
Angel PS:存储模型参数,图结构信息和节点特征等,并且提供模型参数和图相关数据结构的访问接口,例如需要提供两跳邻接访问接口
Spark Driver:中央控制节点,负责计算任务的调度和一些全局的控制功能,例如发起创建矩阵,初始化模型,保存模型,写checkpoint以及恢复模型命令
Spark Worker:读取计算数据,同时从PS上拉取模型参数和网络结构等信息,然后将这些训练数据参数和网络结构传给PyTorch,PyTorch负责具体的计算并且返回梯度,最后Spark Worker将梯度推送到PS更新模型
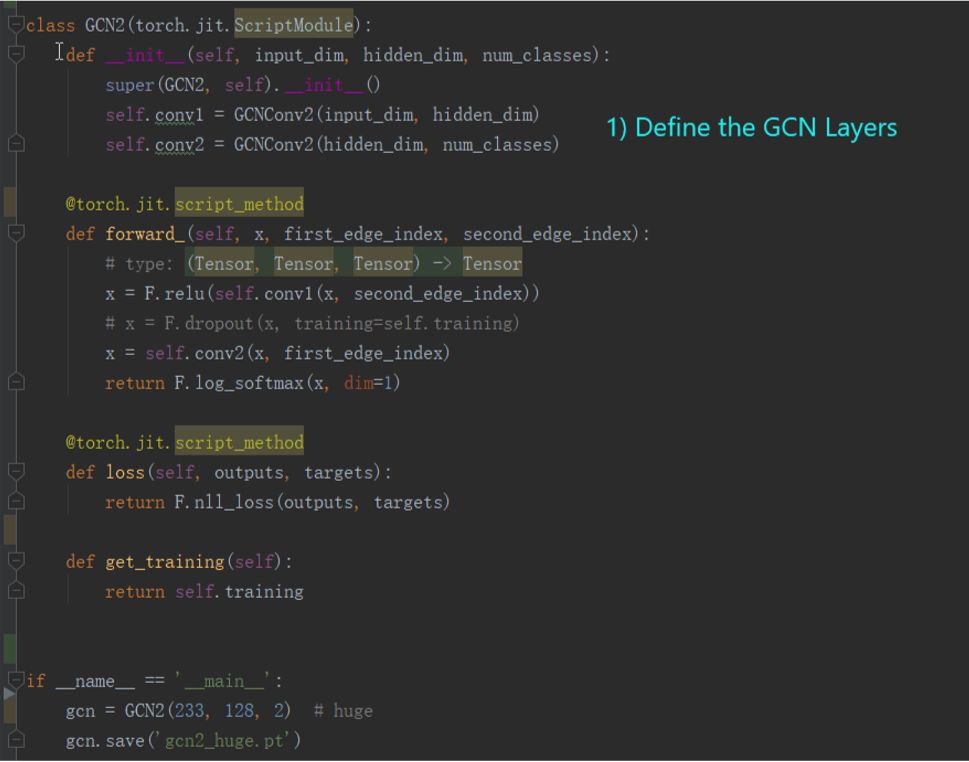
当然,这些细节都是封装好的,算法开发人员和用户并不需要了解。在PyTorch On Angel平台上开发新算法,只需要关注算法逻辑即可,与开发单机的PyTorch算法并没有太大区别。下面给出一个2层GCN算法的实现例子:
图13 在PyTorch On Angel上实现GCN的例子
算法开发完成后,将代码保存为pt文件,然后将pt文件提交给PyTorch On Angel平台就可以实现分布式训练了。
我们已经在PyTorch On Angel上实现了许多算法:包括推荐领域常见的算法(FM,DeepFM,Wide & Deep,xDeepFM,AttentionFM, DCN和PNN等)和GNN算法(GCN和GraphSAGE)。在后续的版本迭代中,我们将会进一步丰富PyTorch On Angel的算法库。
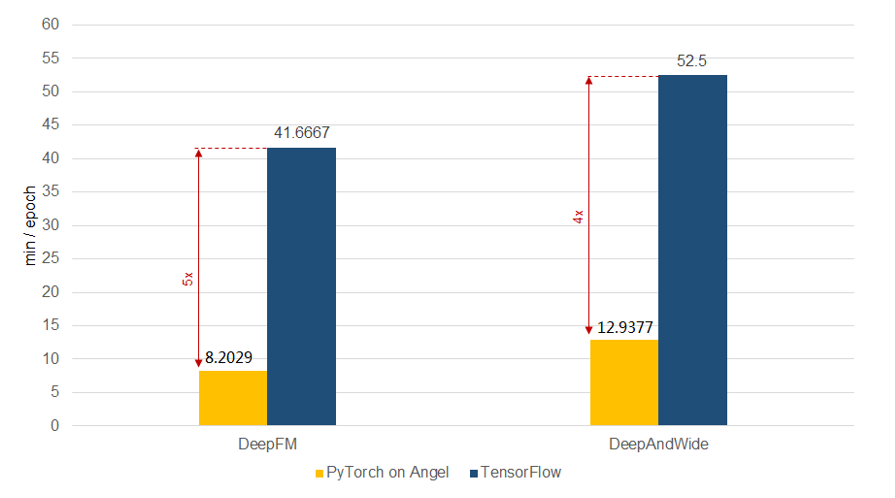
由于结合了PyTorch和Angel的优点,PyTorch On Angel在算法性能方面有很大的优势:对于推荐领域常见的深度学习算法,性能可以达到TensorFlow的4倍以上;对于GNN算法,性能也远好于目前业界开源的同类型平台(具体的性能数据会在开源社区陆续公开)。下图是在公开的数据集criteo kaggle2014(4500万训练样本,100w特征)上做的对比测试:
图14 PyTorch On Angel和TensorFlow性能对比测试
除了性能方面的优势,PyTorch On Angel还有一个比较大的优势就是易用性好。如图12所示:PyTorch运行在Spark的Executor中,可以实现Spark图数据预处理和PyTorch模型训练的无缝对接,在一个程序中完成整个计算过程。
自动超参数调节
贝叶斯优化与传统的无模型方法不同,使用计算成本较低的代理函数(surrogate function)来近似原始目标函数。在贝叶斯优化中,代理函数生成超参数组合的概率均值和方差。然后,效用函数(acquisition function)将评估超参数组合的预期损失或改进。这样的概率解释方法使贝叶斯优化能够使用少得多的开销找到目标函数的较优解。
Angel 3.0包括传统的两种方法和贝叶斯算法优化。对贝叶斯优化,Angel实现了以下的功能:
由于每次评估目标函数的计算开销可能较大,如果观察到候选的超参数组合在开始的若干轮迭代中表现不佳,可以提前停止这些候选超参数组合。Angel 3.0版本中实现了这种早停策略。
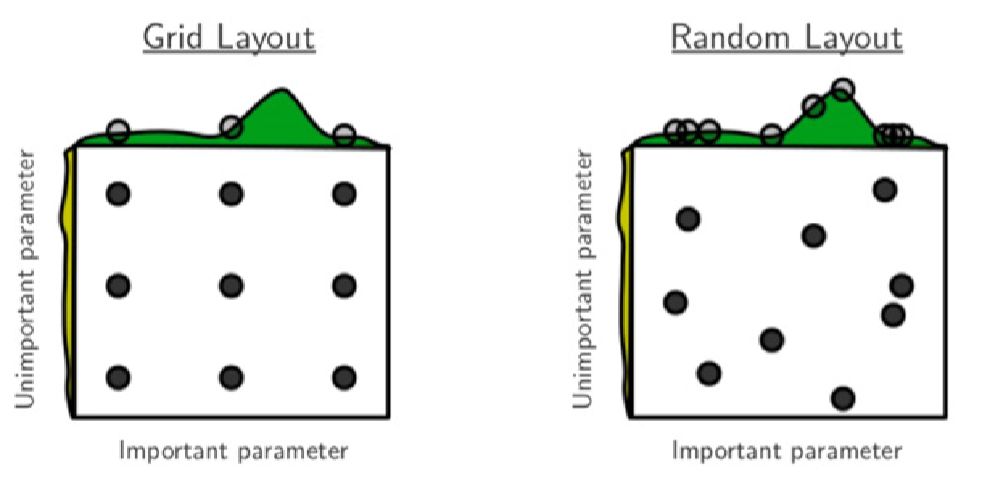
表2是在逻辑回归算法的实验,调节的超参数是学习速度和学习速度衰减率,结果显示贝叶斯优化的性能优于随机搜索和网格搜索,而随机搜索的结果略优于网格搜索
Angel Serving
为了满足在生产环境中高效地进行模型服务的需求,我们在Angel 3.0中实现了Angel Serving子系统,它是一个可拓展性强、高性能的机器学习模型服务系统,是全栈式机器学习平台Angel的上层服务入口,使Angel生态能够形成闭环。图16展示了Angel Serving的架构设计。
Angel Serving主要特征包括:1)支持多种类型的API访问服务,包括gRPC和Restful 接口;2)Angel Serving是一个通用的机器学习服务框架,可插拔机制设计使得来自其他第三方机器学习平台的模型可以很容易使用Angel Serving来服务,目前已经支持三种平台的模型:Angel,PyTorch和支持PMML模型格式的平台(Spark、XGBoost等);3)受TensorFlow Serving的启发,Angel Serving还提供细粒度版本控制策略:包括使用模型的最早,最新以及指定版本进行服务;4)Angel Serving还提供丰富的的模型服务监控指标,包括:
总的请求数以及成功请求总数
请求的响应时间分布
平均响应时间
表3 Angel Serving和Tensorflow Serving性能对比
表3展示了Angel Serving和TensorFlow Serving性能对比结果,我们使用具有100万个特征的DeepFM模型,向服务发送100,000个预测请求。Angel Serving和TensorFlow Serving的总耗时分别为56秒和59秒。两个服务系统的平均响应时间都为2毫秒。Angel Serving的QPS是1,900,而TensorFlow Serving的QPS是1,800。上述结果表明Angel Serving与TensorFlow Serving性能相当,甚至更好。
本文主要介绍了Angel在腾讯内外的使用情况和3.0版本的新特性。
SONA(加强):特征工程支持索引为Long类型的向量;所有的算法被封装成Spark风格的APIs;SONA上的算法可以作为Spark的补充
PyTONA(新):PyTONA作为图学习算法的引擎被引入,目前支持GCN和GraphSage,同时也支持推荐领域的算法。PyTONA采用Python作为交互,因此是用户友好的
自动机器学习:Angel3.0引入了3种超参数调节算法:网格搜索、随机搜索和贝叶斯优化
Angel模型服务:Angel提供一个跨平台的模型服务框架,支持Angel、PyTorch和Spark的模型,性能上与TensorFlow Serving相当
支持Kubernetes:Angel3.0支持Kubernetes,从而可以在云上运行
Angel开源项目地址:
https://github.com/Angel-ML/angel
![]()