「爱情就像脂肪,是点点滴滴的积累」,微软小冰造句天马行空,三大首席科学家万字解密背后技术原理

「爱情就像脂肪,是点点滴滴的积累」这是 18 岁少女微软小冰造出来的句子,咋一听来,倒是很能引起万千热恋中的少男少女的同理心: 「这可不就是恋爱后的幸福肥吗? 」
作者 | 丛末
编辑 | 唐里


一、更新到第七代,小冰实现了什么?

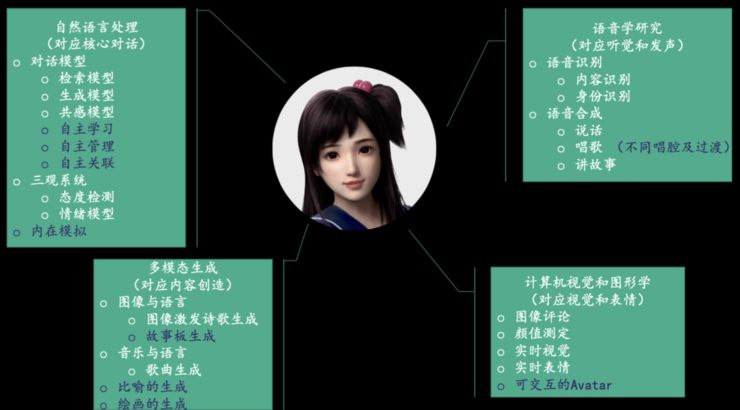
二、兼具学习+自我管理+知识联结能力,才能朝向自我完备
第一,学习能力。学习是人类发展进化并走向成熟的一个基本能力,对于对话机器人而言亦然如此。而对话机器人的学习能力有两个层次,一是能够从人类的对话中学习怎样去说话;二是当对话机器人发展得越来越成熟之后, 每个机器人可能都在各自专注的领域有很丰富的知识那是否有可能让这些机器人之间互相学习,从而实现信息共享和能力互补呢?
第二,自我管理能力。从初级层次来看,对话机器人能够管理好单轮对话的表达,从更高级的层次来看,它在管理好单轮表达后,还要能够把控好整个对话流程。
第三,知识联结能力,即对话机器人能够联结散落在世界上的各项多模态知识。

从单轮生成模型到多轮生成模型
从通用回复到有信息内容的生成
从无法接入外部知识到能够自然地引入外部知识
从单一模态的生成到涵盖声音、视觉和语言的多模态的生成
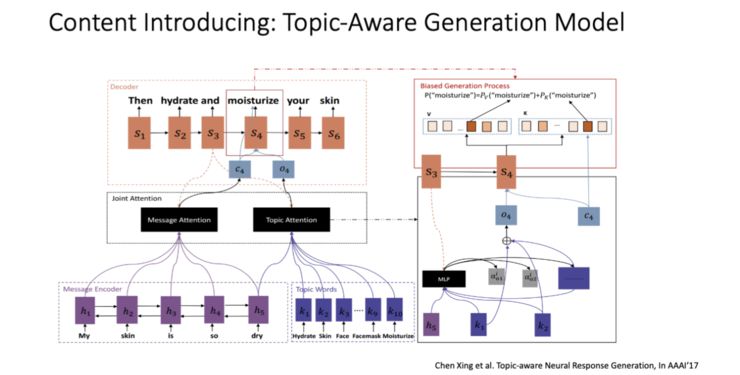
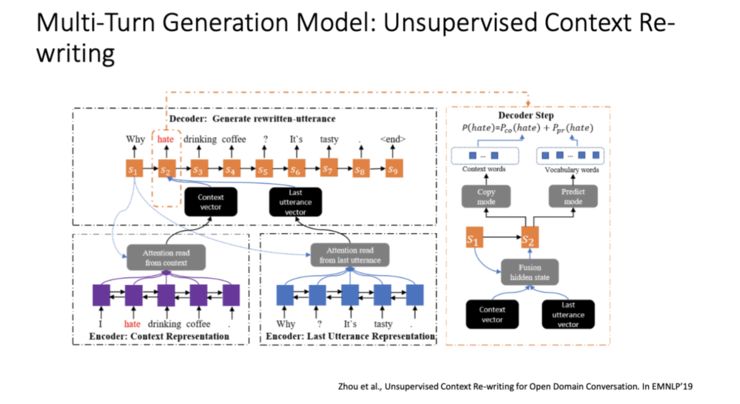
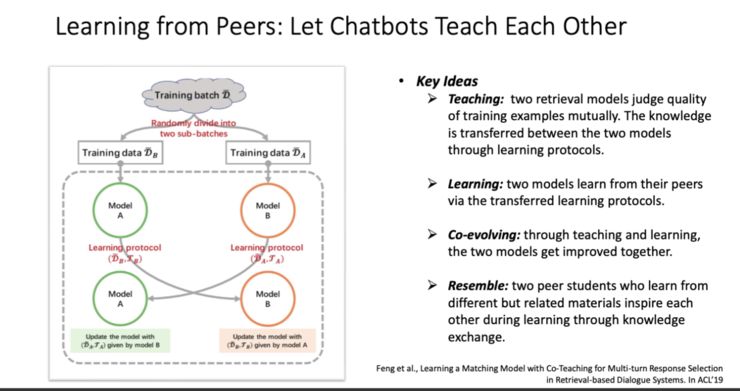
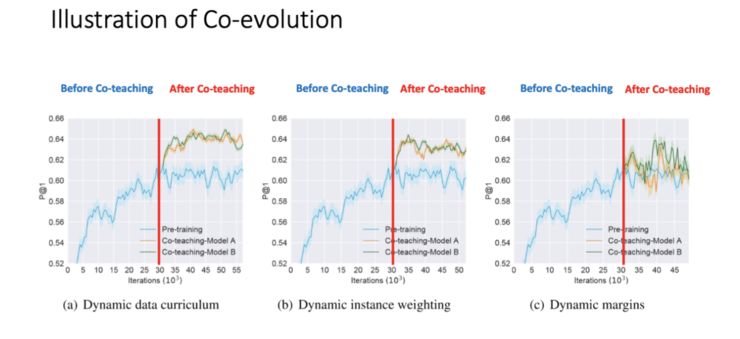
-
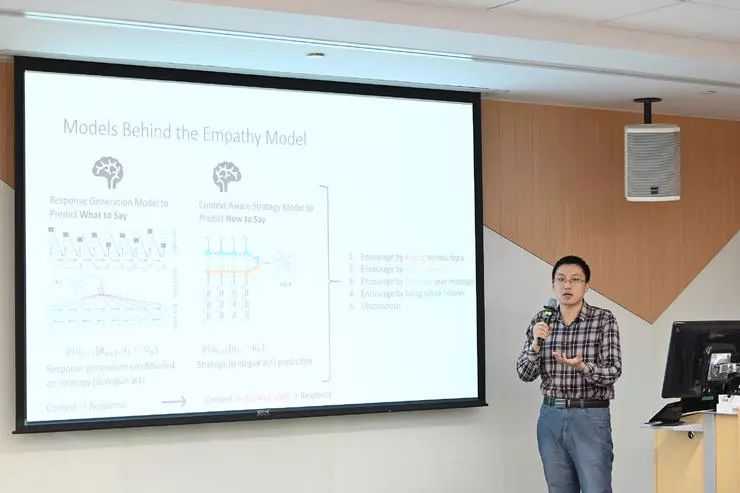
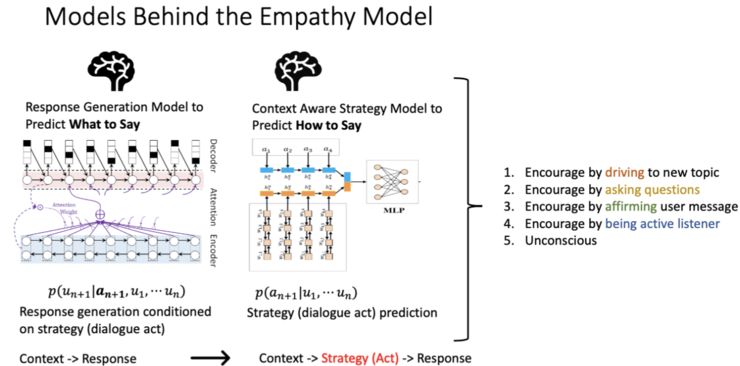
回复生成模型,决定的是机器人说什么。 -
策略决定模型,决定的是机器人要怎么去说。
-
问题一:给定一个策略,比如要表达的意图、情感、话题,模型能不能准确地生成把既定的策略表达出来的回复呢?与此同时,对话机器人不仅要表达这个策略,还要保证回复在上下文语境下是流畅的。 -
问题二:在有很多策略的时候,对话机器人怎么在一个对话流中组合这些策略呢?

-
第一,可解释性很强,让开发者和终端用户能在对话机器人生成回复之前都能知道可能会得到哪些回复; -
第二,可以把 Meta-Word 做成像一个接口一样,让工程师可以通过编辑这个接口来编辑 Meta-Word 中的属性,以及属性值去打造具有各种各样的风格、情感、话题、意图的各类对话机器人; -
第三,Meta-Word 也提供了一种一般的解决方案,像现在的一些前沿研究方向,包括基于话题的对话生成、情感的对话生成、个性化的对话生成,都可以在这个框架下找到一个解决方案,不仅如此,这个方案还具有很好的扩展性,工程师们通过简单地增加、减少或者修改 Meta-Word 里面的属性值,就可以调整整个生成模型的效果。
三、小冰为什么要唱歌以及如何唱歌?

-
第一, 唱歌的门槛比说话高。 普通人都会说话,但是不是所有人都会唱歌的,更不是所有人都能唱得好听,与此同时,唱歌还有三个要素,即除了发音之外,它还有其它要素的要求,所以它在技术上有难点。 -
第二, 唱歌在情感表达上更加丰富激烈一些。 古人说「幸甚至哉,歌以咏志」,说明人们在特别高兴的时候就想唱歌,《诗经》说「心之忧矣,我歌且谣」,说明人类在悲伤的时候也喜欢唱歌。现在流行歌曲里面有很多情歌都是和失恋相关的,不管因为什么原因失恋,都能找到一首与其心境很对应的情歌。而除了高兴和悲伤之外,在一些比较重要、有纪念意义的场合,比如说今年是建国 70 周年,大家在那段时间可能都会被《我和我的祖国》这首歌单曲循环,所以歌曲是一种喜闻乐见的形式。 -
第三, 唱歌是一种很重要的娱乐形式。 随着《快乐女生》、《我是歌手》、《中国好声音》类似的节目红遍大江南北,他们认为唱歌应该是很有市场前景的研究方向。
-
第一,发音,因为唱歌不是哼歌,不是用「啊」或者「嗯」把这首歌哼出来就好了,吐字发音一定要清晰,这和说话是一样的。 -
第二,节拍,它是通过一种节奏的变化来表现艺术的形式,像我们普通的说唱,比如「一人我饮酒醉」这种说唱的形式,可能没有其它的旋律,主要就是靠节拍的组合来表达,节拍是唱歌里面非常重要的要素。 -
第三,旋律,每个字的音高会不太一样,如果音高唱错了、跑调了,这首歌肯定就没法听了。
-
第一,如果有人唱过这首歌,那机器就可以通过这个人唱的歌学习这首歌应该是什么样子。 -
第二,通过曲谱的方式,可以是简谱也可以是五线谱,它们下面都有歌词,其中简谱则既有歌词,也有发音的元素以及节拍和音高。
-
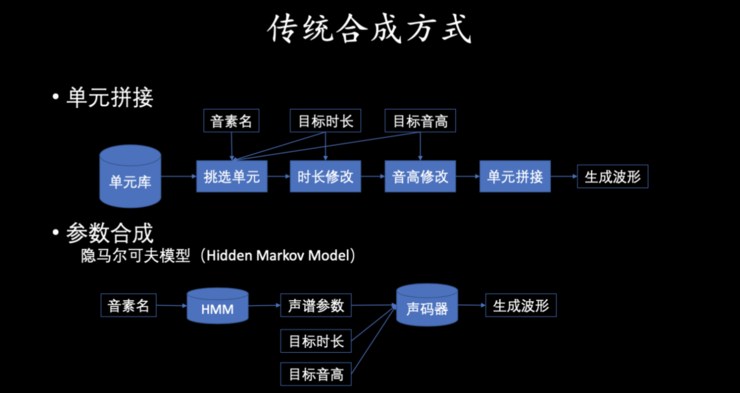
第一类: 单元拼接的方式。
-
第二类: 参数合成的方法。
-
第一,要把伴奏里人声部分的时间轴找到; -
第二,能够准确找到每个发音的起始和结束时间; -
第三,要把人声的音高轨迹提取出来。
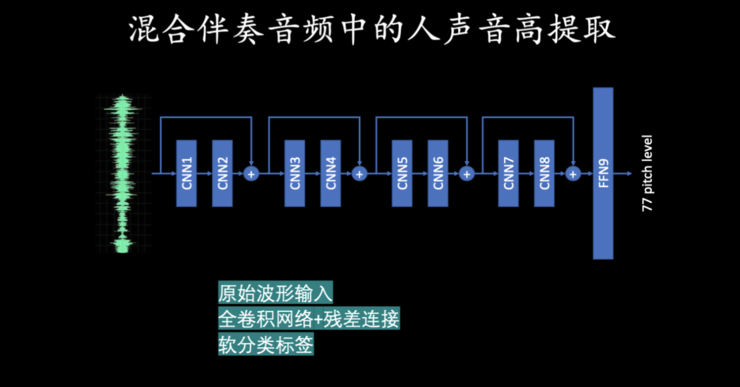
-
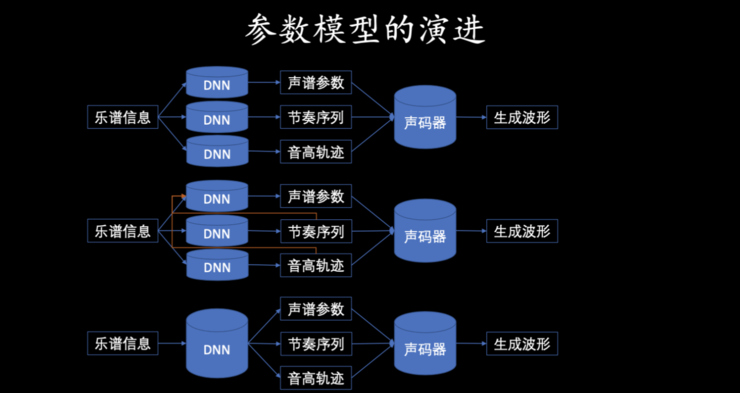
第一,模型的输入用的是原始波形,而不是常规的能量谱,这是因为提取音高时,模型主要是要检测周期性,所以它的相位信息是非常重要的,如果是能量谱的话,那这个相位就丢失了。 -
第二,模型采用全卷积网络+残差连接的网络结构,非常清晰、简洁; -
第三,软分类标签,即要准确判断每个时刻音高对应的是 77 个钢琴键里面的哪一个键,传统的方式可能是硬标签,比如说就是学习的时候标注这个时刻对应的中音八度的那个键,但是只有那个键会标「1」,其它的地方都标「0」,实际上这个方法会有一个问题,就是忽略了检测结果和标准结果偏差一个键值或者偏差 10 个键值之间错误的程度的差别是很大的。
四、小冰造出惊人比喻句的背后又做了哪些技术探索?


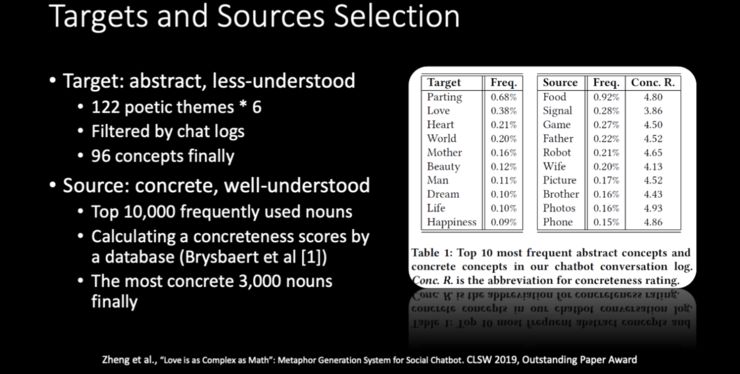
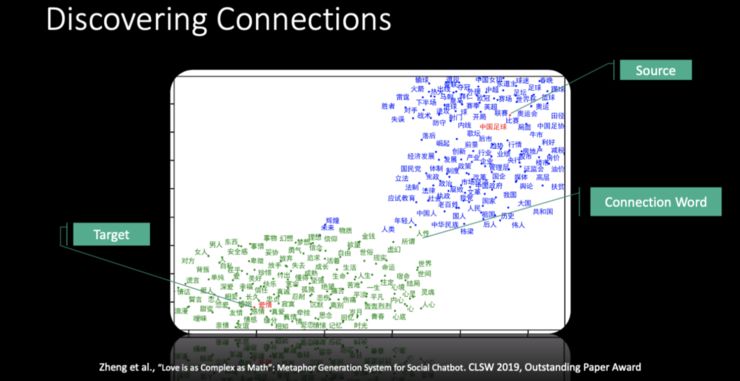
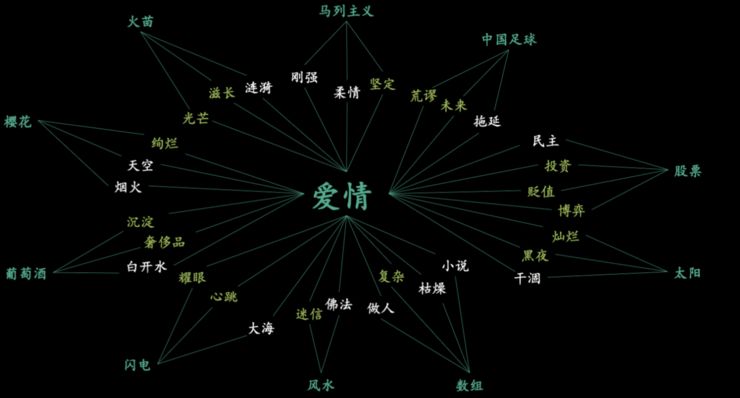

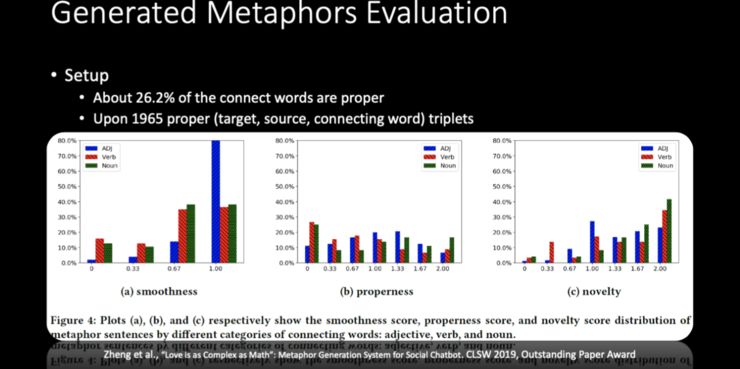
-
首先评价连接词是否合适,即让标注者去想像,如果「爱情」和「数学」用「复杂」来连接,是否能想像到一种联系,如果觉得可以,就可以打上标签「1」,如果不可以,就标成「0」。在这一步骤中,大概有 1/4 的连接词都是不错的。 -
接着,基于这些连接词,团队采用「分而治之」的方法造出了 1965 个比喻句,并从三个方面对这些句子进行了评价:第一,造出的这个比喻句是否通顺;第二,这个比喻是否恰当;第三,这个比喻是否新颖。

-
第一,不要用比喻,就用陈述句,比如说「心灵是闪光的」。 -
第二,用一轮的比喻说出去,比如说「心灵像钻石一样闪光」。 -
第三,把对话拆成两轮,第一轮卖一个关子说「我听说心灵像钻石,你知道为什么吗?」然后用户说「为什么呀?」或者其他的,小冰就会说「因为它们都是闪光的」。

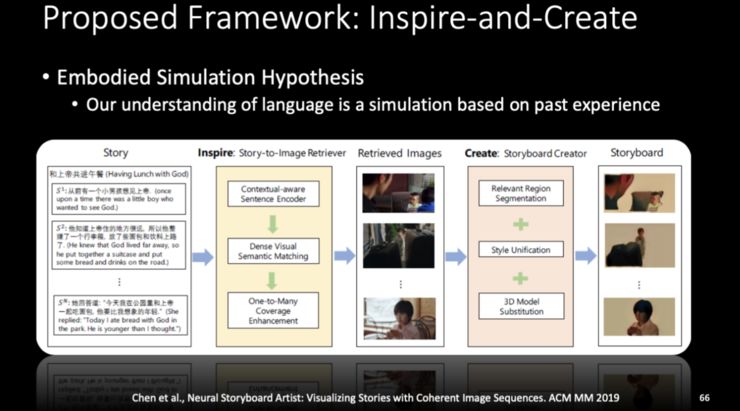
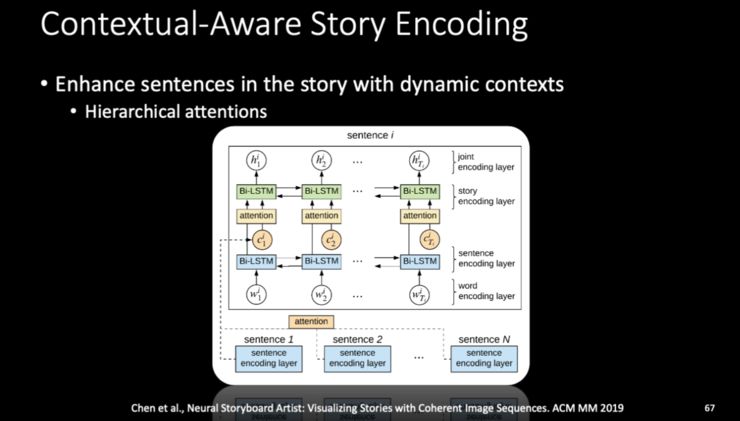
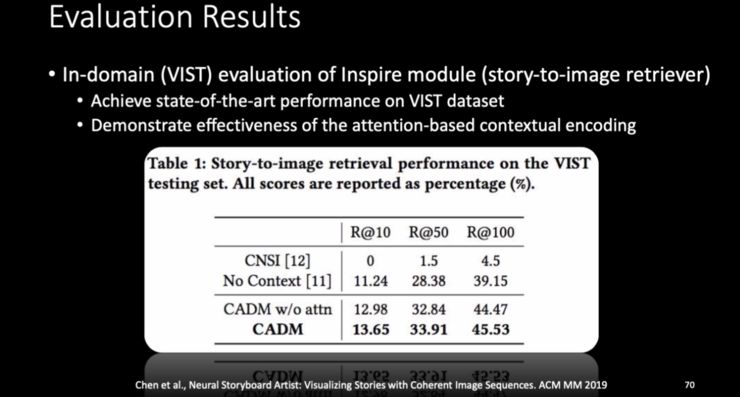
五、跨模态理解:如何让小冰看到文字就能想到画面?


-
第一,基于生成的方法,也就是 GANs; -
第二,基于检索的方法,将文字和图片联合嵌入到一个空间中,以判定文字和哪一个图像比较接近、比较搭配。


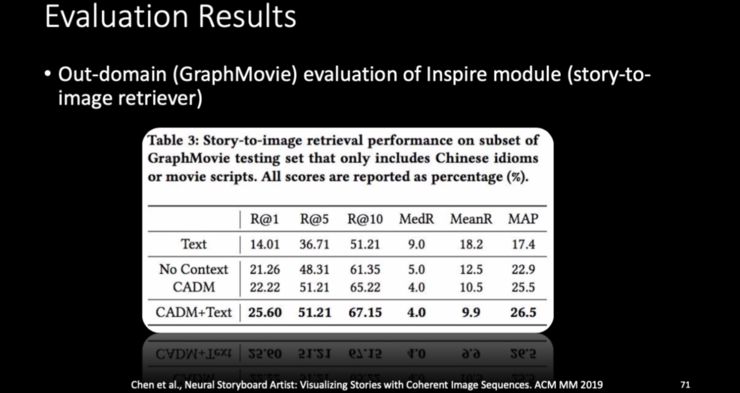
-
在对话方面,希望小冰能够实现更加自主的更新,更加自主地控制对话流; -
在人工智能创造方面,希望小冰能够在才艺上实现更多的创新,其中要重点扩展学习资源以不断突破创新的边界; -
在多模态上,希望小冰能够像人类一样去理解世界以及与人交互,其中既面临着数据问题,也面临着模态大跨度的挑战,这就需要大家研究出更好地融合多模态信息的方法。



登录查看更多
相关内容

Arxiv
4+阅读 · 2019年5月6日
Arxiv
4+阅读 · 2018年4月30日
Arxiv
7+阅读 · 2018年4月6日
Arxiv
6+阅读 · 2018年1月10日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年5月6日
Arxiv
4+阅读 · 2018年4月30日
Arxiv
7+阅读 · 2018年4月6日
Arxiv
6+阅读 · 2018年1月10日