“大数据”如此热门,真正的源头在哪里?
撰文 | 小溪
审校 | 汪璐
近些年来,“大数据(Big Data)”已成为一个受全世界关注的热门词汇,在科研、电信、金融、教育、医疗、军事、电子商务甚至国家及政府机构的决策时都离不开大数据技术的身影,几乎人类发展的所有领域都有大数据技术的应用,甚至有人宣告:人类已经被大数据浪潮席卷而进入了大数据时代。
其实,“大数据”并不是很新的概念,早在好几十年前,从事粒子物理实验研究的科学家就已经面临了如何处理实验中所获得的海量数据的问题,可那时大多数人还根本不知道大数据是什么。真正的大数据并不仅是数据量大,而是一个包含了数据的获取、传输、存储、分析等综合性的最前沿技术。最早拥有这种全面应对技术的正是粒子物理实验领域。以这个视角看,真正的大数据之源应属于科学基础研究前沿的粒子物理实验。
1
计数的进制
先需要说明一下数字的进位制,这与后面要说到的数据格式相关。
进位制是人们为了计数和运算而约定的记数方式。多位数中,数字的位置不同表示的数值是不同的。约定一个基数n,只要满了n就进一位,这就是n进位制,简称n进制。
从古至今,人类使用过的计数进制五花八门,以下列出的是最主要的几种:
60进制:古巴比伦人的计数采用60进制,每小时60分钟,每分钟60秒,以及将圆周分为360度角,每度为60分,每分为60秒,这些都是巴比伦人最早提出的。中国古历法使用的“干支”纪年也属于60进制,将10个“天干”(甲、乙、丙、丁、戊、己、庚、辛、壬、癸)与12个“地支”(子、丑、寅、卯、辰、巳、午、未、申、酉、戌、亥)按顺序排列组合可列出60个不同的年份。
20进制:古代玛雅人计数时20以下用5进制,20以上用20进制。
16进制:中国旧时称重使用的是1斤=16两。
12进制:公元年月是12进制。古人由观察天象认识了天、月、年,以及气候冷暖的变化周期。因一年中月亮有12次盈亏,由此对应将一年分为12个月,这就是最初的12进制。
10进制:很可能是因为人有10个手指,用手指数数最方便,10进制就成了人类最自然的计数方式,很多民族的文字中都有10个数字。目前使用最广泛的10进制阿拉伯数字0-9其实是古印度人发明的,后经阿拉伯人传到了全世界,被称为阿拉伯数字。中国早在商代就采用十进制(一、二、三、四、五、六、七、八、九、十、百、千、万)。
2进制:只用0和1两个基本数字,逢2进位。大部分历史资料中将2进制的发明与18世纪德国的数理哲学大师莱布尼兹(G. W. Leibniz)联系在一起,也有资料介绍英国数学家哈里奥特(T. Harriot)17世纪初就提出过这种计数法。莱布尼兹没能见到前人的论述,他一直以为这是自己的独创。但莱布尼茨的确是大力提倡2进制的第一人,他在自己的论文中详细说明了2进制的算术原理,还给出了加、减、乘、除四则运算的规则。只是在那个年代,这套2进制理论就像个数字游戏,并没有发现它有什么实用的价值。
除了上述的几种进制还有8进制、7进制等等。
2
数据的挑战
社会的发展使人们面临了数据的挑战。
1880年,美国政府部门进行了全国人口普查,没想到耗时约8年才完成了所有数据的汇总,但此时很多滞后的数据都已经失去了价值,因为政府确定税收分摊以及国会代表人数等,都需以人口普查的数据为基础。美国政府每10年就进行一次人口普查,由于人口的不断增长,预计汇总1890年进行的人口普查数据将要花费13年。
幸亏美国的一位统计学家霍尔瑞斯(H. Hollerith)发明了利用穿孔卡片收集及整理数据的制表机,这大大加快了汇总人口普查数据的速度,使原本需要10多年才能处理完的数据仅用了1年就处理完毕。这可以算作自动处理数据的开端,只不过霍尔瑞斯的这种方法需要每个人填写一张可制成穿孔卡片的表格然后再进行统计,不仅过程比较麻烦,成本也比较高。当所获的数据用已有的数据处理工具难以应付之时——这就像要被数据所淹没——迫切地需要数据处理的新技术。

美国人口调查局使用霍尔瑞斯发明的制表机汇总数据(图片来自网络)
1965年,美国预算局提出创建一个国家级的数据中心,目的是记录每个美国人的教育、医疗、福利、犯罪和纳税等情况,计划将这些数据保存在磁带上便于有关部门提取。没想到,这个提案在美国国会和公众中引起了一场大风波,人们认为这会侵犯个人的隐私。民众的抵制最终导致该计划于1968年中止,但这个计划通常被认为是大规模存储数据的第一个尝试。
那时,虽然人们已经遇到了大量数据的挑战,但这并不能算是大数据的源头,因为在那个年代,人们处理大量数据的能力实在太弱了。
3
技术基础
20世纪40年代,初级的计算机已有人发明了。计算机的运行要靠电流,对每个电路节点而言,电流通过的状态只有通电和断电两种状态,而计算机的信息存储一般采用磁带、磁盘,对每个记录点来说只有磁化和未磁化两种状态,正因如此,多年前认为没有什么实用价值的2进制运算模式很自然地被应用在计算机上了,计算机运行时1表示通电,0表示断电,存储信息时1表示磁化,0表示未磁化。
20世纪70年代后期,个人电脑开始正式进入商业市场,只是仅有计算机而没有网络仍然对付不了大量的数据。
1980年,美国思想家、未来学家托夫勒(A. Toffler)在他所撰写的《第三次浪潮》中预言:大数据将成为“第三次浪潮的华彩乐章”。
全球性的计算机网络体系——因特网于80年代基本形成,而真正为全世界信息交流和传播带来革命性变化的万维网(Web)则于1990年12月在欧洲核子研究中心(CERN)诞生。
这里还有个关键的问题:1993年4月30日,CERN正式决定将Web软件放到因特网的公共领域,并宣布Web软件可对任何人开放,不收取任何费用。CERN和Web的发明人伯纳斯-李(Tim Berners-Lee)放弃了为Web技术申请专利,这对因特网在全世界的推广起了极为重要的作用。此后,Web的应用远远超出了最初的设想。【扩展阅读:你从哪里来?我离不开的Web】
设想一下,如果没有二进制等数学基础、没有计算机、没有存储设备、没有因特网在全世界的广泛应用…,根本谈不上如何应对大数据的挑战,正因为有了这些关键技术的基础,人们处理大量数据的能力才得以大大提高。
4
“大数据”之源
2008年9月,《自然》杂志推出一个“大数据”封面专栏,“大数据”此时已受到了关注。
而“大数据”真正成为互联网技术的热门词汇大约是在2009年之后。据媒体资料的介绍,世界著名的管理咨询公司麦肯锡公司2011年5月发布了一份题为“大数据:竞争、创新和生产力的下一个前沿”的报告。该报告认为,所谓大数据是指“规模已经超出典型数据库软件所能获取、存储、管理和分析能力之外的数据集”,报告提出了对大数据进行收集和分析的设想,并对大数据会产生的影响、所需关键技术以及应用领域等进行了较详尽的分析。


《自然》杂志2008年9月的“大数据”封面专栏(上)、麦肯锡公司2011年5月发布的“大数据”报告(下)(图片来自网络)
如果据此认为大数据起源于上述时间段有些失于偏颇。实际上,大数据并不算个全新的概念,早在麦肯锡公司发布大数据报告的好几十年前,从事粒子物理研究的科学家就已经面临了如何处理粒子物理研究所获得的海量数据信息的问题,可那时大多数人还根本不知道大数据到底是什么。
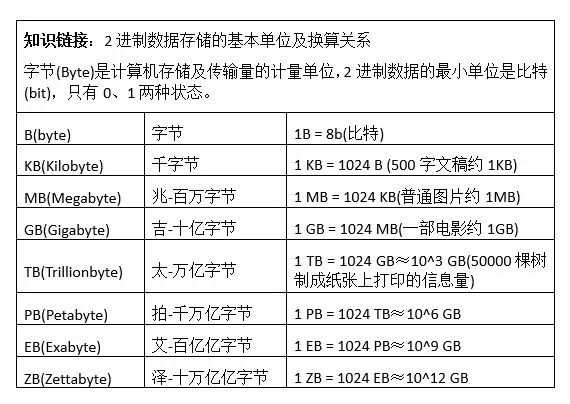
世界上任何东西的“大”与“小”都是相对的,大数据也是一个相对术语,设置某个具体的数据量标准作为大数据的“门槛”,即数据量超过多少字节就算大数据(参考知识链接)并不科学。大数据应是一个动态的、能够随着数据规模和处理能力增长而不断变化的概念。真正的大数据也并不仅是指所获数据的量大,而是包含了数据的获取、传输、存储、分析等综合性的最前沿技术。数据也并不总是量越大越有价值,没有价值的大量数据只会造成数据传输、存储方面的过重负担,对数据的准确分析产生负面的影响。
基于计算机、因特网、万维网等高新技术的发展,人们在面临大数据挑战的同时,也在不断增强收集、传输、存储、分析处理及广泛应用大数据的能力。大数据的范畴及内涵也在此过程中不断丰富及延伸,不仅与数据量的规模、数据即时处理的速度、数据格式的多样化相关,还涉及到数据的准确性、可视性、合法性等等特性。
5
粒子物理实验
那么粒子物理实验与大数据有何关系呢?
粒子物理实验主要研究构成宇宙中所有物质的基本粒子,以及使这些物质聚集在一起的基本作用力。粒子物理实验研究除了可通过接收宇宙射线进行,主要是通过粒子加速器将某种粒子加速至很高能量后与其他粒子相碰撞,然后由各种类型的粒子探测器记录下粒子碰撞产生的各种事例(包括事例发生的位置、能量、时间等等数据信息)。这些数据记录到磁带、磁盘等存储设备中并提供给科学家们分析研究。
最早使用的粒子探测器有云室、气泡室、流光室等,属于记录粒子径迹类型。这些粒子实验所获的事例图像直接保留在照相底片上,通过扫描测量仪将信息数字化后成为原始数据。之后,陆续发展了多丝正比室、漂移室、闪烁计数器等多种电子学型的粒子探测器。
20世纪70年代后,随着超大型粒子物理实验装置的建设以及电子学、计算机技术的快速发展,数据的传输、存储、分析等方面的技术也有了质的飞跃,粒子物理实验所获的原始数据量的规模越来越大,不得不设定各种条件初步筛选后再存入存储设备。这些数据要通过科学家分析后实现重构,再现各类粒子的物理性质(如能量、电荷、磁矩等等)还原事例中的物理过程,经模拟计算便可了解探测器里到底发生了什么。
1989年3月,CERN建造的大型正负电子对撞机LEP开始运行,正负电子分别被加速至每秒围绕周长27公里的加速器真空管道运转11000周(接近光速)。LEP上有四个大型粒子探测装置:ALEPH、DELPHI、L3和OPAL,探测器获得原始数据的速率为1 MB/秒,每年的总数据量达0.2-0.3 TB(1 TB相当于50000棵树制成纸张上打印的信息量),这在当时已属空前,属于真正的大数据了。
到了2008年,CERN在原LEP的隧道中建成了能量更高的大型强子对撞机LHC(拆除了LEP的全部磁铁和设备)。LHC上建有ATLAS、ALICE、CMS和LHCb等规模更大的粒子探测器。LHC每25纳秒就可发生一次质子对撞,各类探测器获得的数据达1 PB/秒。如此大的数据量实际上无法完全记录下来,只能通过特殊的方法进行过滤后将那些科学家们可能感兴趣的数据存储在特殊的存储设备上。近年来,过滤后每年的数据量竟达60 PB(每保存1 PB的数据就需要约22.3万张DVD盘的容量),这数据量已大到令人瞠目结舌。

大型强子对撞机LHC鸟瞰及探测器位置示意图(图片来自网络)
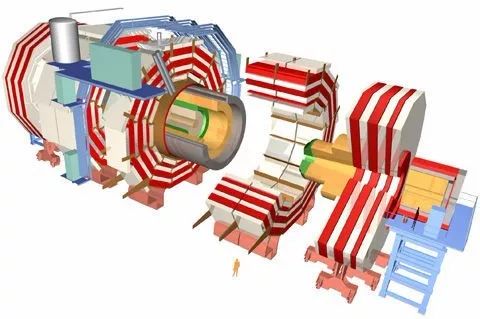
紧凑型μ子螺旋型磁谱仪(CMS)结构示意图(21米×15米×15米)(图片来自网络)

超环面探测谱仪(ATLAS)结构示意图(46米×25米×25米)(图片来自网络)
如何分解存贮和处理这些海量数据正是粒子物理实验研究所面临的巨大挑战,各种类型的数据处理方法应运而生。例如,欧洲在2000年启动的名为DataGrid的研究项目,不仅能满足高能物理实验研究的数据处理需要,同时也扩展到地球观察、生物研究等广泛的应用领域。
粒子物理实验所获得的海量数据经过各种手段的分解、处理,最终以约100 MB/秒的速率写入存储设备。CERN的计算机中心负责将这些数据通过高速网络分配给欧洲、北美、日本等国的区域中心,后者再将任务作进一步分解。提供给世界各相关研究机构的数据量约为1 MB/秒,这样,物理学家们就可以很方便地进行分析研究了。

CERN计算机中心的自动磁带存储库(2008年),磁带用来存储LHC的实验数据,机械臂用于在存储架和驱动器间运送磁带,磁带的调用完全自动化(图片来自网络)
正因具备了超强的数据获取及处理能力,CERN才能在极为复杂的数据背景之下,以海底捞针的精湛技术于2012年7月捕捉到了物理学家们期盼已久的希格斯(Higgs)粒子,其中,大数据技术功不可没,发挥了极为重要的作用!
由此可见,在一般人认为的“大数据”成为互联网技术热门词汇(约2009年)之前,粒子物理实验研究早已与“大数据”打了多年交道,真正的“大数据”之源在哪里应该毫无悬念了。
6
结语
粒子物理、宇宙天文学、人体基因等最前沿的基础研究都离不开大数据,随着信息技术的飞速发展和应用,大数据近些年来已深深渗入了社会的发展及人类的日常生活。网格计算、云计算、物联网、车联网、社交网、移动互联网、GPS定位、电子商务、医学影像、安全监控、金融、电信、人工智能等技术的发展都基于大数据并且更疯狂地产生着大数据,大数据就如大海的浪潮一浪高过一浪,势不可挡。
而科学家们面临的则是更严峻的挑战:需要处理的数据量更加庞大,数据类型更加多样,需要更快的数据传输及处理速度,需要容量更大而体积更小的存储介质,需要更智能的数据分析工具…,这些需求又进一步推动了相关高新技术的发展。
浪潮自有源头,在几乎人人都被大数据浪潮席卷的时代,不能忘记粒子物理实验研究在大数据的获取、传输、存储、分析等最前沿技术领域打下的基础与巨大的贡献。真正的“大数据”源头来自基础研究最前沿的粒子物理实验研究。
参考资料
1、Michael S. Turner,Bigscience is hard but worth it,《Science》24 Apr. 2015
2、A Brief History of Big Data
http://www.dataversity.net/brief-history-big-data/
3、BIG DATA wizards: LEARN from CERN, notthe F500
http://www.theregister.co.uk/2015/03/23/cerns_atom_big_data_f500/
4、欧洲数据网格DataGrid介绍
http://www.net130.com/netbass/grid/wg20040410024.htm
5、王学敏,欧洲原子核研究中心(CERN)LEP对撞机的建造和实验研究概况,《原子核物理评论》 1987年第2期
http://www.cnki.com.cn/Article/CJFDTotal-HWDT198702014.htm
6、陈刚,高能物理粒子实验中的大数据技术,《科研信息化技术与应用》2016,7(1)
7、大数据:美国技术创新新前沿
http://tech.hexun.com/2013-07-15/156142018.html
8、从穿孔卡片到电路板:计算机时代的到来
http://history.sina.com.cn/bk/sjs/2014-12-22/1315112986.shtml
9、赵振江,莱布尼茨——他的二进制和计算器,《科学文化评论》第4 卷第3 期(2007)
10、高能物理实验产生的海量数据如何处理?
http://chuansong.me/n/555276949954
11、陈和生,大科学的数据挑战与应对策略--粒子物理大数据
http://wenku.it168.com/d_001529993.shtml
12、大数据:美国技术创新新前沿,环球财经2013年第7期
http://tech.hexun.com/2013-07-15/156142018.html
13、高能物理——引领网格新时代
https://www.douban.com/group/topic/3184669/
14、世界最大高能物理实验基地——欧洲核子研究中心(CERN)
http://bbs.tianya.cn/post-no04-526908-1.shtml





