一行代码调用预训练模型,上海交大开源视频理解工具箱AlphaVideo
机器之心编辑部
近期,上海交通大学卢策吾团队在《自然 - 机器智能》上发表视觉序列理解的研究成果,通过模仿人类的认知机制,提出了可应用于高维度信息的半耦合结构模型(SCS)。此外,他们还开源了视频理解工具箱 AlphaVideo。


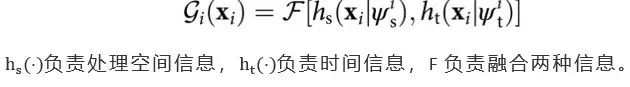
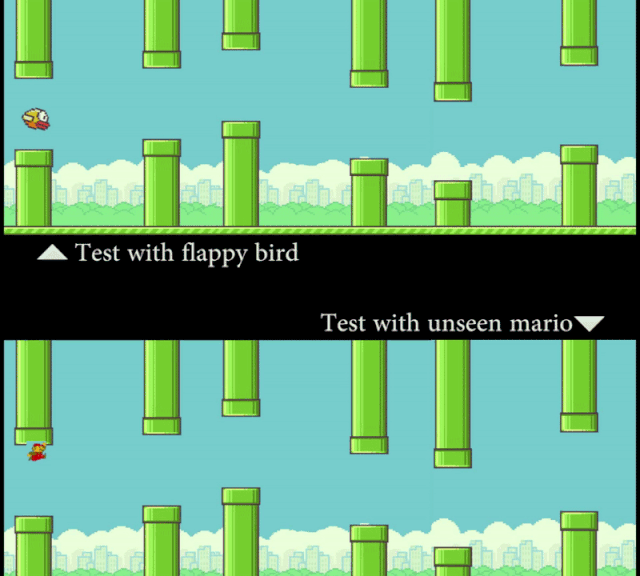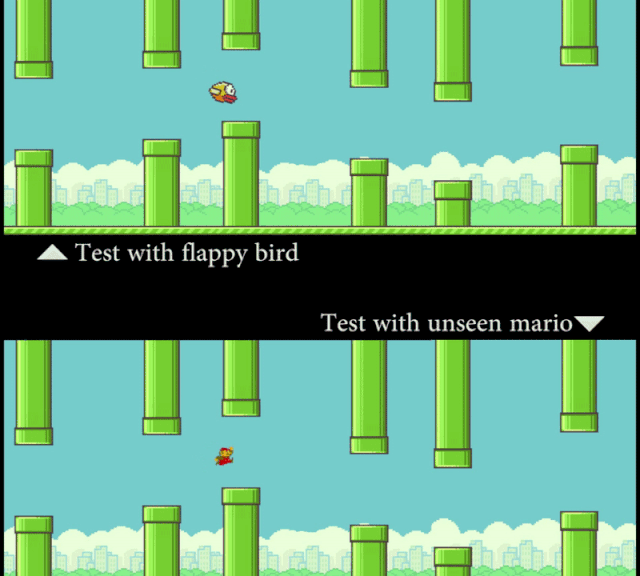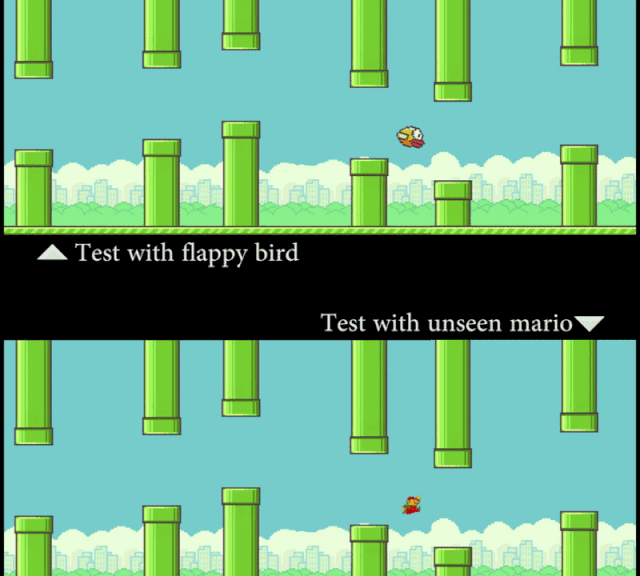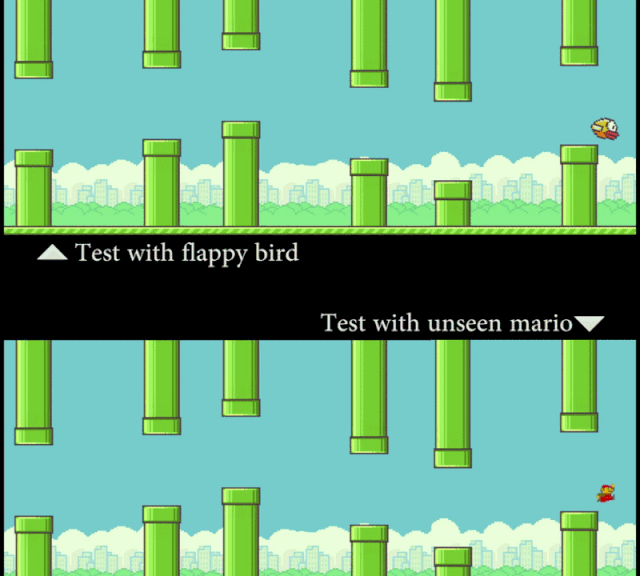
研究者让计算机看 Flappy Bird 的视频,然后看一张静态的 Mario 图片(外观形象)。在这个过程中,模型并没有接触到任何 Mario 在管道中穿梭的运动信息。但通过「概念编辑」,在测试时 SCS 可以准确地预测 Mario 的运动轨迹。
视频理解工具箱 AlphaVideo
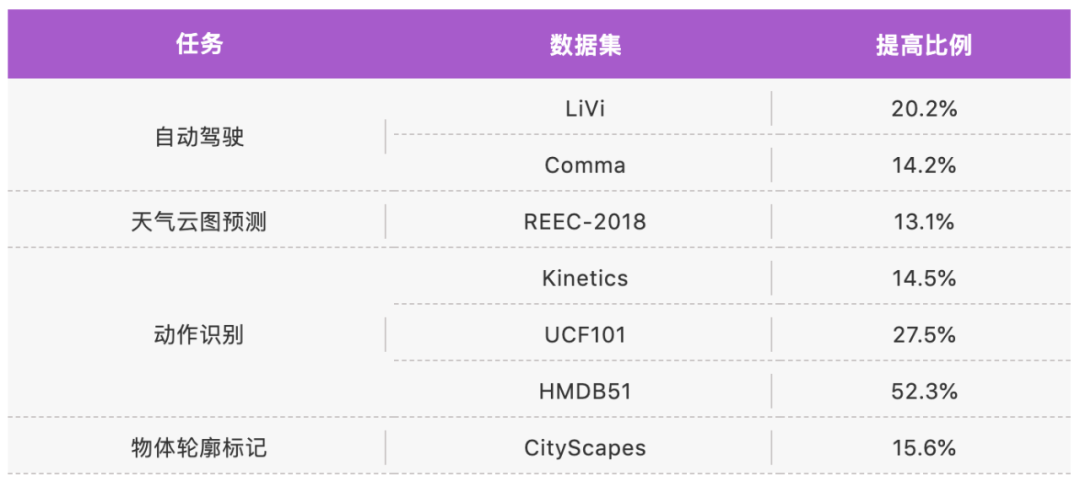
在视频理解工具箱 AlphaVideo 中,除了上述 SCS 时空概念分解,研究者还提供了单阶段端对端训练的多目标跟踪模型 TubeTK 和视频动作检测模型 AlphAction。使用一行代码,即可调用预训好的各类模型。
AlphAction
AlphAction 是面向行为理解的开源系统,基于 MVIG 提出的交互理解与异步训练策略 [5] 在 AVA 数据集上达到最优准确率,速度达到 10 帧每秒。其中包含的 15 个开源常见行为基本模型的 mAP 达到约 70%,接近可以商用的水平。
TubeTK
TubeTK 是上海交大 MVIG 组提出的基于 Bounding-Tube 的单阶段训练模型(CVPR2020-oral),是首个单阶段端对端训练的多目标跟踪模型。它在 MOT-16 数据集上达到了 66.9 MOTA 的精度,是目前 online 模型仅在 MOT 训练数据下达到的最高精度 [3]。

图 7:TubeTK 可视化结果
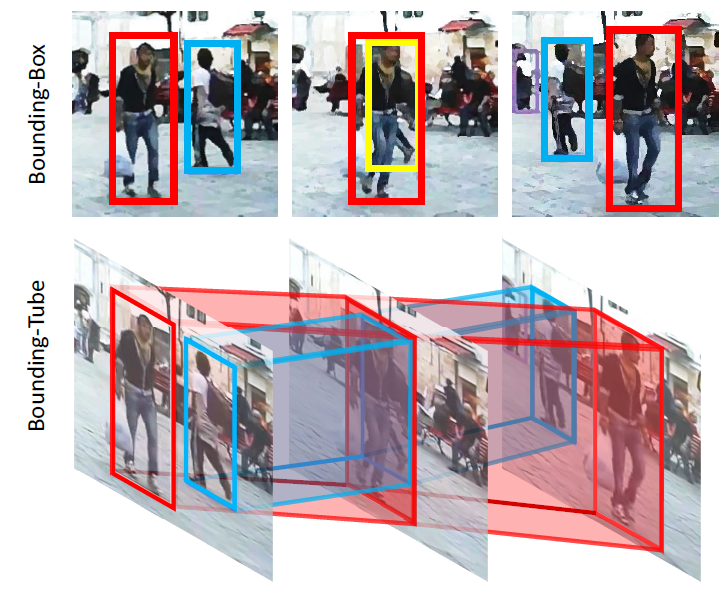
图 8:Bounding-Tube 示意图。使用 bounding-tube 可以轻松跟踪到 bounding-box 无法检测到的被遮挡目标(图中黄色框)。
参考文献
[1] Kitamura, T. et al. Entorhinal cortical ocean cells encode specific contexts and drive context-specific fear memory. Neuron 87, 1317–1331 (2015).
[2] Simonyan, K. & Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems 568–576 (ACM, 2014).
[3] https://motchallenge.net/tracker/3184&chl=5
[4] Feichtenhofer, C., Fan, H., Malik, J., & He, K. (2019). Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision (pp. 6202-6211).
[5] Tang, J., Xia, J., Mu, X., Pang, B., & Lu, C. (2020). Asynchronous Interaction Aggregation for Action Detection. arXiv preprint arXiv: 2004.07485.






