TensorFlow 性能优化
文 / 李锡涵,Google Developers Expert
本文节选自《简单粗暴 TensorFlow 2》,合集回复 “手册”

在上一篇文章中,我们详细介绍了自动求导模块 tf.GradientTape 的使用方法。
本节主要介绍 TensorFlow 模型开发和训练中的一些原则和经验,使得读者能够编写出更加高效的 TensorFlow 程序。
关于计算性能的若干重要事实
-
不同的程序设计语言由于设计机制和理念,以及编译器 / 解释器的实现方式不同,在数值计算的效率上有着巨大的区别。 例如,Python 语言为了增强语言的动态性,而牺牲了大量计算效率。 而 C/C++ 语言虽然复杂,但具有出色的计算效率。 简而言之,对程序员友好的语言往往对计算机不友好,反之亦然。 不同程序设计语言带来的性能差距可达 数量级以上。 TensorFlow 等各种数值计算库的底层就是使用 C++ 开发的;
-
对于矩阵运算,由于有内置的并行加速和硬件优化过程,数值计算库的内置方法(底层调用 BLAS)往往要远快于直接使用 For 循环,大规模计算下的性能差距可达 数量级以上;
对于矩阵 / 张量运算,GPU 的并行架构(大量小的计算单元并行运算)使其相较于 CPU 具有明显优势,具体视 CPU 和 GPU 的性能而定。在 CPU 和 GPU 级别相当时,大规模张量计算的性能差距一般可达
以上。
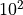 数量级以上。
数量级以上。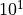 以上。
以上。dot 函数和 TensorFlow 的
matmul 函数,分别计算了两个 10000×10000 的随机矩阵
A
和
B
的乘积。
程序运行平台为一台具备 Intel i9-9900K 处理器、NVIDIA GeForce RTX 2060 SUPER 显卡与 64GB 内存的个人电脑(后文亦同)。
运行所需时间分别标注在了程序的注释中。
import tensorflow as tf
import numpy as np
import time
import pyximport; pyximport.install()
import matrix_cython
A = np.random.uniform(size=(10000, 10000))
B = np.random.uniform(size=(10000, 10000))
start_time = time.time()
C = np.zeros(shape=(10000, 10000))
for i in range(10000):
for j in range(10000):
for k in range(10000):
C[i, j] += A[i, k] * B[k, j]
print('time consumed by Python for loop:', time.time() - start_time) # ~700000s
start_time = time.time()
C = matrix_cython.matmul(A, B) # Cython 代码为上述 Python 代码的 C 语言版本,此处省略
print('time consumed by Cython for loop:', time.time() - start_time) # ~8400s
start_time = time.time()
C = np.dot(A, B)
print('time consumed by np.dot:', time.time() - start_time) # 5.61s
A = tf.constant(A)
B = tf.constant(B)
start_time = time.time()
C = tf.matmul(A, B)
print('time consumed by tf.matmul:', time.time() - start_time) # 0.77s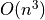 时间复杂度的矩阵乘法(具体而言,
时间复杂度的矩阵乘法(具体而言,
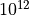 次浮点数乘法的计算量),使用 GPU 加速的 TensorFlow 竟然比直接使用原生 Python 循环快了近 100 万倍!这种极大幅度的优化来源于两个方面,一是使用更为高效的底层计算操作,避免了原生 Python 语言解释器的各种冗余检查等所带来的性能损失(例如,Python 中每从数组中取一次数都需要检查一次是否下标越界)。二是利用了矩阵相乘运算具有的充分的可并行性。在矩阵相乘
次浮点数乘法的计算量),使用 GPU 加速的 TensorFlow 竟然比直接使用原生 Python 循环快了近 100 万倍!这种极大幅度的优化来源于两个方面,一是使用更为高效的底层计算操作,避免了原生 Python 语言解释器的各种冗余检查等所带来的性能损失(例如,Python 中每从数组中取一次数都需要检查一次是否下标越界)。二是利用了矩阵相乘运算具有的充分的可并行性。在矩阵相乘
 的计算中,矩阵
的计算中,矩阵
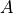 的每一行与矩阵
的每一行与矩阵
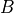 的每一列所进行的相乘操作都是可以同时进行的,而没有任何的依赖关系。
的每一列所进行的相乘操作都是可以同时进行的,而没有任何的依赖关系。
模型开发:拥抱张量运算
在 TensorFlow 的模型开发中,应当尽量减少 For 循环的使用,而多使用基于矩阵或者张量的运算。这样一方面是利用计算机对矩阵运算的充分优化,另一方面也是减少计算图中的操作个数,避免让 TensorFlow 的计算图变得臃肿。
举一个例子,假设有 1000 个尺寸为 100×1000 的矩阵,构成一个形状为 [1000, 100, 1000] 的三维张量 A ,而现在希望将这个三维张量里的每一个矩阵与一个尺寸为 1000×1000 的矩阵 B 相乘,再将得到的 1000 个矩阵在第 0 维堆叠起来,得到形状为 [1000, 100, 1000] 的张量 C 。为了实现以上内容,我们可以自然地写出以下代码:
C = []
for i in range(1000):
C.append(tf.matmul(A[i], B))
C = tf.stack(C, axis=0)这段代码耗时约 0.40s,进行了 1000 次 tf.matmul 操作。然而,我们注意到,以上的操作其实是一个批次操作。与机器学习中批次(Batch)的概念类似,批次中的所有元素形状相同,且都执行了相同的运算。那么,是否有一个单一的操作能够帮助我们一次性计算这 1000 个矩阵构成的张量 A 与矩阵 B 的乘积呢?答案是肯定的。TensorFlow 中的函数 tf.einsum 即可以帮我们实现这一运算。考虑到矩阵乘法的计算过程是 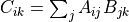
ij,jk->ik 。于是,对于这一三维张量乘以二维矩阵的 “批次乘法”,其计算过程为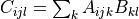
ijk,kl->ijl 。于是,调用 tf.einsum ,我们有以下写法:
C = tf.einsum('ijk,kl->ijl', A, B)这段代码与之前基于 For 循环的代码计算结果相同,耗时约 0.28s,且在计算图中只需建立一个计算节点。
模型训练:数据预处理和预载入
为了优化模型的训练流程,有必要对训练的全流程做一个时间上的评测(Profiling),以弄清每一步所耗费的时间,并发现性能上的瓶颈。这一步可以使用 TensorBoard 的评测工具(参考 查看 Graph 和 Profile 信息 ),也可以简单地使用 Python 的 time 库在终端输出每一步所需时间。评测完成后,如果发现瓶颈在数据端(例如每一步训练只花费 1 秒,而处理数据就花了 5 秒),我们即需要思考数据端的优化方式。
查看 Graph 和 Profile 信息
https://tf.wiki/zh/basic/tools.html#graphprofile
一般而言,可以通过事先预处理好需要传入模型训练的数据来提高性能,也可以在模型训练的时候并行进行数据的读取和处理。可以参考前文的 使用 tf.data 的并行化策略提高训练流程效率 以了解详情。
模型类型与加速潜力的关系
使用针对特定 CPU 指令集优化的 TensorFlow
现代 CPU 往往支持特定的扩展指令集(例如 SSE 和 AVX)来提升 CPU 性能。默认情况下,TensorFlow 为了支持更多 CPU 而在编译时并未加入这些扩展指令集的支持。这也是你经常在 TensorFlow 运行时看到类似以下提示的原因:
I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX
不过,如果你的机器学习任务恰好在 CPU 上训练更加有效,或者因为某些原因而必须在 CPU 上训练,那么你可以通过开启这些扩展指令集,来榨干最后一点 TensorFlow 本体的性能提升空间。一般而言,开启这些扩展指令集支持必须重新编译 TensorFlow (这一过程漫长而痛苦,并不推荐一般人尝试),不过好在有一些第三方编译的,开启了扩展指令集的 TensorFlow 版本(例如 GitHub 上的 fo40225/tensorflow-windows-wheel )。你可以根据自己的 CPU 支持的扩展指令集,下载并安装第三方提供的预编译的 .whl 文件来使用开启了扩展指令集支持的 TensorFlow。此处性能的提升也视应用而定,笔者使用一颗支持 AVX2 指令集的 AMD Ryzen 5 3500U 处理器,使用 tf.function :图执行模式 * 中的 MNIST 分类任务进行测试。针对 AVX2 优化后的 TensorFlow 速度提升约为 5~10%。
性能优化策略
同时,性能优化也存在一个度的问题。一方面,我们有必要在机器学习模型开发的初期就考虑良好的设计和架构,使得模型在高可复用性的基础上达到较优的运行性能。另一方面,代码的可读性在机器学习中尤为重要。正如软件工程中的名言,“premature optimization is the root of all evil” [Knuth1974] 。直白来说,不要浪费时间做一些性能收益不大、而且还会严重牺牲代码可读性的性能优化。
Knuth1974
Knuth D E. Structured programming with go to statements[J]. ACM Computing Surveys (CSUR), 1974, 6(4): 261-301.
福利 | 问答环节
我们知道在入门一项新的技术时有许多挑战与困难需要克服。如果您有关于 TensorFlow 的相关问题,可在本文后留言,我们的工程师和 GDE 将挑选其中具有代表性的问题在下一期进行回答。
在上一篇文章《tf.GradientTape 详解》中,我们对于部分具有代表性的问题回答如下:
Q1:有一个小问题,自定义模型网络层,super 定义一次,然后 call 中多次调用,会不会多次调用里面参数完全一样?是否需要每一层,即使参数相同也要在 super 中定义呢?
A:是的,不好意思出现了笔误,代码最后一行的 optimizer_1 应改为 optimizer_2 (现已经修改,感谢提醒)。
Q3:在《社区分享|如何让模型在生产环境上推理得更快》by GDE 孔晓泉 中,Docker 的确方便,但是对于工程架构上和维护上,又额外增加了一些负担。
Q4:在《TensorFlow 2.0 部署:模型导出》中:请问老师,在 tf2.0 中使用 model.save('my_model.h5') 保存模型为 .h5 格式的,出现错 ValueError: Unable to create group (name already exists),是什么原因呢?
《简单粗暴 TensorFlow 2.0》目录
TensorFlow 性能优化 (本文)

有趣的人都在看