对偶性解法,赋予强化学习更多可能性!

文 / 研究员 Ofir Nachum 和 Bo Dai,Google Research
强化学习 (RL) 是一种用于训练智能体制定在复杂环境中成功的决策序列的常用方法。如机器人导航,智能体控制机器人寻找通往目标位置的路径;或者游戏玩法,希望能在最短时间内通关。Q-learning 和 actor-critic 等许多现代的成功 RL 算法都提出将 RL 问题简化为 约束满足 (Constraint-Satisfaction) 问题,即对环境中的每个可能“状态”都设定约束条件。例如,在基于视觉的机器人导航中,环境的“状态”对应于每个可能的摄像头输入。
尽管实践中约束满足方法无处不在,但这一策略通常难以与现实世界的复杂环境相协调。在实践场景中(例如机器人导航),可能的 “状态“ 很多,有时甚至不可计数,该如何学会并满足如此大量的输入相关的约束呢?Q-learning 和 actor-critic 的实现通常会忽略这些数学问题,或者通过一系列粗糙近似解掩盖它们,从而导致这些算法的实践实现与其数学基础之间出现巨大差异。
在“通过 Fenchel-Rockafellar 对偶性进行强化学习(Reinforcement Learning via Fenchel-Rockafellar Duality)”中,我们开发了一种新的 RL 方法,使算法既实用又符合数学原理 - 也就是说,算法避免使用过于粗糙近似解将数学基础转换为实践实现。这种方法基于 凸对偶性。凸对偶性是经过充分研究的数学工具,用于将以一种形式表示的问题转换为可能对计算更友好的不同形式的等效问题。我们开发了在 RL 中应用对偶性的具体方法,将传统的约束满足数学形式转换为无约束且更实际的数学问题。
通过 Fenchel-Rockafellar 对偶性进行强化学习
https://arxiv.org/abs/2001.01866
对偶性解法
基于对偶性的方法首先将强化学习问题表述为有若干约束项的数学目标,约束的数量可能无限。将对偶性应用于数学问题会对相同问题产生不同表述。不过,这种双重表述仍是具有大量约束的单个目标,与原始问题格式相同,尽管特定的目标和约束已发生变化。
下一步是对偶性解法的关键。我们使用 凸正则化器 (Convex Regularizer) 扩充对偶目标,这是优化中经常使用的一种方法,可以使问题平滑化。正则化器的选择对于最后一步至关重要,在这一步,我们再次应用对偶性来产生等效问题的另一种表述。我们在案例中使用了 f 散度 (F-Divergence) 正则化器,得到现在 无约束 的最终表述。尽管凸正则化器还有其他选择,但 f 散度正则化是产生无约束问题的特殊理想方法,产生的问题尤其适合在需要异策略或离线学习的实践和现实世界环境中进行优化。
异策略
https://ai.googleblog.com/2020/04/off-policy-estimation-for-infinite.html离线
https://ai.googleblog.com/2020/04/an-optimistic-perspective-on-offline.html
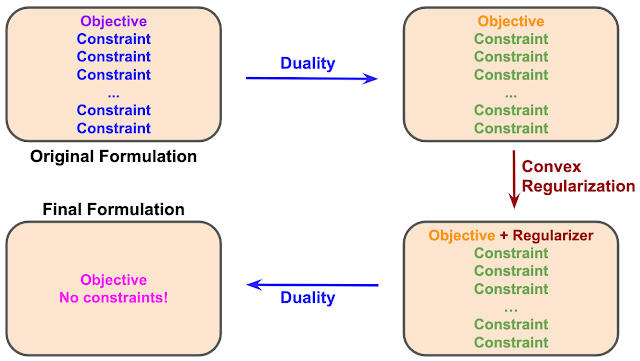
值得注意的是,在许多情况下,对偶性方法规定的对偶性和正则化应用 并不会 改变原始解法的最优性。换句话说,尽管问题形式改变,但是解法依旧不变。因此,新表述获得的结果与原始问题的结果相同,但实现的方式更为轻松。
实验性评估
为了测试新方法,我们在导航智能体上实现了基于对偶性的训练。智能体从多房间地图的一个角开始,必须导航到相对的另一个角。我们将自己的算法与 actor-critic 方法进行了对比。尽管这两种算法都基于相同的基本数学问题,但 actor-critic 由于无法满足大量约束而使用了大量的近似。相反,对比两种算法的性能可以看出,我们的算法更适合实践实现。在下图中,我们针对每个算法,绘制了学习智能体获得的平均奖励与训练迭代次数的关系图。与 actor-critic 相比,基于对偶性的实现获得了明显更高的奖励。
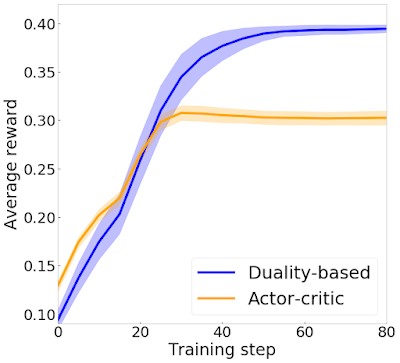
使用对偶性方法的智能体(蓝色)与使用标准 actor-critic 的智能体(橙色)相比所取得的平均奖励图。我们的方法不仅更符合数学原理,也产生了更好的实践结果
结论
综上所述,如果将 RL 问题表述为具有约束条件的数学目标,那么结合重复应用凸对偶性与正确选择的凸正则化器,即可生成一个 无约束 的等效问题。由此产生的无约束问题很容易在实践中实现,并且适用于广泛环境。我们已经将通用框架应用于智能体行为策略优化,策略评估和模仿学习。我们发现,我们的算法不仅比现有 RL 方法更符合数学原理,而且往往能够产生更好的实践性能,展现出将数学原理与实践实现相结合的价值。
更多 AI 相关阅读:






