前沿 | 看AI侦探如何破解深度学习的黑箱

编者按:AI在很多方面都表现出了与人类相匹敌甚至超越人类的能力。但是AI如何实现这种能力却是一个谜题。随着神经网络和深度学习在科学领域的应用越来越多,AI的黑箱性质已经愈发引起技术专家、科学家以及伦理学家的担心。于是一批AI专家开始把研究目标对准了AI自己,他们利用各种办法试图提高AI执行的透明度,从而形成了一种新兴的AI学科——AI神经科学。《科学》杂志的这篇文章为我们介绍了这些AI侦探是如何破解黑箱的。
加州旧金山,Uber总部,Jason Yosinski正坐在一个小小的玻璃箱里面,揣摩着一个人工智能的思想。身为Uber研究科学家的Yosinski正在对运行在他的笔记本上的AI进行某种脑科手术。就像众多很久快将对现代生活的方方面面提供动力的AI(包括Uber的无人车)一样, Yosinski的程序用的也是深度神经网络,其架构灵感也部分源自大脑。就像大脑一样,该程序外部是很难理解的:它是个黑箱。
这个特别的AI已经用海量的标签图像进行了训练,使得它可以识别诸如斑马、消防车、安全带等随机对象。那它能不能认出在摄像头前面驻足的Yosinski和记者呢?Yosinski放大了这个AI其中的一个独立的计算节点,或者说神经元,好看看是什么促使它响应。两个幽灵式的白色椭圆形弹了出来悬浮在屏幕上。似乎这个神经元已经学会了检测脸部的轮廓。他说:“这个对你我的脸做出响应。它会对不同尺寸不同肤色的脸做出响应。”
没人教过这个网络识别人脸的本领。在它的训练图像中人类并没有被打上标签。但它还是学会了去了解人脸,也是是作为识别伴随着人脸出现的东西,如领带、牛仔帽之类的手段。该神经网络对人类来说实在是太复杂了,所以无法理解其确切决定。Yosinski的调查发现了其中的一小部分,但整体而言,它仍然是晦涩难懂的。他说:“我们建立了令人惊讶的模型,但我们还不是很理解它们。而且这种理解鸿沟每一年都在与日俱增。”
深度神经网络,或者用行话来说,深度学习,似乎每个月都把触角延伸到类型的科学学科。它们可以预测合成有机分子的最佳方式。它们可以检测与自闭症相关的基因。它们甚至可以改变科学本身的进行方式。但凡去做的事情AI往往都成功了。但它们也给以解释作为事业基础的科学家出了一个纠结的难题:为什么?为什么要这样建模?
这个解释问题正在刺激着产业界和学术界新一代的研究者。就像显微镜揭示了细胞一样,这些研究人员正在设计工具来洞悉神经网络是如何做出决策的。一些工具是在没有渗透进AI的进行下进行调查的;一些属于与神经网络竞争的替代算法,但透明度更高;而有的则采用甚至更多的深度学习来探究黑箱。这些凑成一个新学科。Yosinski称之为“AI神经科学”。
打开黑箱
近似模仿人类大脑的深度神经网络正在促进科学的创新。但这种模型的机制却很神秘:它们是黑箱。科学家现在正在开发工具来进入这种机器的大脑。
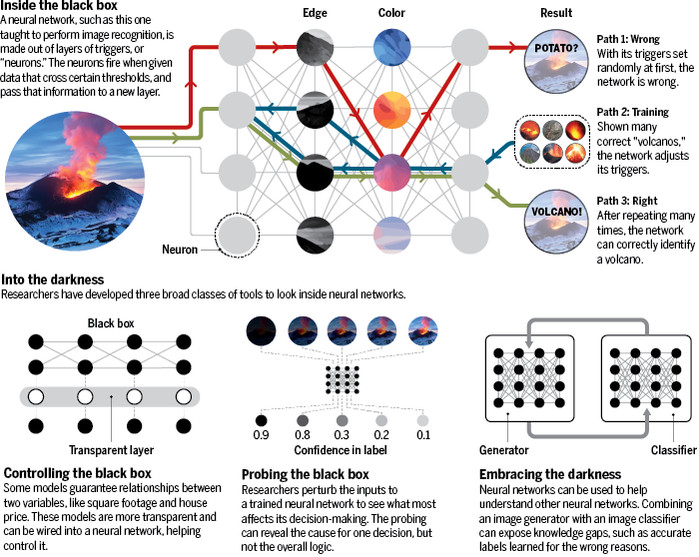
西雅图华盛顿大学的研究生Marco Ribeiro力争理解这种黑箱,他的手段是一类叫做反事实调查的AI神经科学工具。其想法是改变AI的输入——不管是文字、图像还是任何其他东西——然后用聪明的方式看看哪些变化会影响输出,以及是如何影响的。比方说读取电影评论然后对其中积极的打上标记的神经网络。Ribeiro的程序叫做Local Interpretable Model-Agnostic Explanations (LIME),它会把标记为积极的评论取出来,然后通过删除或者替换文字来做出微妙的变化。这些变化然后再被放到这个黑箱里面跑,看看它还会不会认为这些评论是积极的。在数千次测试的基础上,LIME可以识别出哪些单词,或者哪些图像或分子结构或者任何类型的数据的组成部分对AI原先判断最重要。测试可能会发现“恐怖”这个词对于摇镜头极其重要,或者“Daniel Day Lewis”会导致对影片的积极评价。但尽管LIME能够诊断那些个体的例子,在对网络的整体洞察方面这一结果却揭示不了什么。
像LIME这样新的反事实方法似乎每个月都会涌现。但Google的另一位计算机科学家Mukund Sundararajan却构思了一种不需要对神经网络进行上千次测试的调查法:如果你想要理解很多而不是一些决策的话,那这种方法就是一种福利了。Sundararajan和他的团队不是随机地对输入做出变化,而是引入了空白对比——一张空白的图片或者用归零数组替代文字——然后把它一步步地过渡到被测试的例子。通过每一步执行,他们观察神经网络的跳跃情况,并利用这种跳转轨迹推断出对预测重要的特性是什么。
Sundararajan将这种过程与选出他所在的玻璃墙空间的关键特征相提并论——这个地方配备的都是些标准的东西,马克杯、桌子、椅子以及计算机,就像Google的会议室一样。“我可以给出无数个推论。”但比方说你慢慢地调暗了灯光。“等灯光变得很暗时,只有最大的推论最突出。”从空白对比出发的过渡让Sundararajan可以比Ribeiro的变化法捕捉更多的神经网络决策。但更深层次的问题依然无解,Sundararajan说,作为一位父亲这种思想状态他再熟悉不过了:“我4岁的小孩总是不断地提醒我‘为什么?’这个问题的无限递归。”
这种迫切性不仅出自科学。根据欧盟的要求,采用的算法会对公众产生重大影响的公司明年必须对其模型的内部逻辑做出“解释”。美国军方的研究机构The Defense Advanced Research Projects Agency(先进研究项目局)在为一个新计划投入了7000万美元,新计划的名字叫做Explainable AI(可解释的AI),旨在对支撑无人机与情报挖掘行动的深度学习做出解释。Google机器学习研究人员Maya Gupta说,硅谷本身也有打开AI黑箱的驱动力。当她2012年加盟Google时,她询问了AI工程师有什么问题,当时精准度不是他们关注的唯一问题。对方告诉她说:“我不知道AI在干什么。我不知道是不是可以信任它。”
对于这种信任的缺失,微软研究院的计算机科学家Rich Caruana有切身体会。作为1990年代卡内基梅隆大学的研究生,他曾加入一个团队,试图探究是否机器学习可以指导对肺炎病人的治疗。通常来说,把精神充沛的人送回家是最好的,因为这样可以避免在医院里发生二次感染。但一些病人,尤其是患有哮喘等复杂因素的病人,应该马上允许住院。Caruana运用神经网络对78家医院提供的临床与结果数据集进行了分析。看起来似乎工作不错。但令人不安的是,他发现一个基于相同记录训练的更简单、透明的模型却建议把哮喘病人送回家,这说明了数据是有瑕疵的。而他并没有简便的方法来了解他的神经网络是否也得出了同样糟糕的经验。他说:“对神经网络的恐惧完全是合理的。真正令我恐惧的是还有哪些神经网络学到的东西也是错的?”
今天的神经网络比Caruana还是研究生那会儿强多了,但它们的本质是一样的。一头是乱糟糟的一团数据——比方说数百万张狗的图片。这些数据会被吸进有十几甚至更多计算层组成的网络,在这个网络里面,神经元似的连接会“开火”以对输入数据的特征做出响应。每一层会对更加抽象的特征做出反应,使得最后一层能区分出小猎犬与腊肠狗。
一开始的时候这种系统会表现得比较笨拙。但每次结果都会跟打上标签的狗图片进行比较。通过一个名为反向传播的过程,结果会被送回给神经网络,使得它可以对每个神经元的触发器重新赋予权重。这个过程会重复几百万次,直到神经网络知道(但我们不知道它怎么做到的)如何区分不同的狗品种。Caruana说:“”。但这种神秘且灵活的力量正是它们之所以是黑箱的原因。
Gupta对于黑箱采取了不同的策略:回避。几年前,第二职业为复杂实体设计师的Gupta开始了一个叫做GlassBox的项目。她的目标是通过植入可预测性来驯养神经网络。其指导原则是单调性——也就是变量之间这样的一种关系,在其他一切均平等的情况下,一个变量的增加会直接增加另一个,就像一间房子的建筑面积和房子价格的关系一样。
Gupta将这些单调关系嵌入到一个叫做内插值查找表的庞大数据库里面。这些数据库基本上就像你要查找sin 0.5的值时要翻的高中三角学课本背后的那些表。不过她的表不是在一维上有十几个数据项,而是指多维上有几百万个条目。然后她将那些表编排到神经网络里面,这相当于增加了额外的一层可预测的计算层——她说所植入的这些知识最终可以让网络更加可控。
与此同时,Caruana还惦记着肺炎治疗方面的教训。为了开发出一种在准确率上可与深度学习匹敌但可避免不透明性的模型,他向一直跟机器学习及其不协调的方法相处得都不是很好的一个社区——统计学家发出了求助信号。
在1980年代,统计学家开拓了一种新的技术,名字叫做广义相加模型(GAM)。这种技术的基础是线性回归,是一种在一组数据中寻找线性趋势的方法。但通过寻找多种组合起来可以将数据糅合进一条回归线的操作,GAM还可以处理更棘手的关系——比方说,对一组数进行开方,同时对另一组变量求对数。Caruana对这一过程又进行了增强,利用机器学习来发现那些操作——然后再用作一种强大的模式检测模型。他说:“出乎我们意料的是,这种做法在很多问题上都非常精确。”而且关键是,每一种操作对底层数据的影响都是透明的。
在处理特定类型的杂乱数据,比如图像或者声音方面,Caruana的GAM表现没有AI好,一些神经网络正是靠处理那些数据繁荣起来的。但对于任何能放进电子表格的行列之间的数据(关系表),比如医院记录,这个模型就工作得很好。比方说,Caruana又找回了他原来的肺炎记录。用他其中的一个GAM重新分析那些数据,借此他得以发现为什么AI会从准入数据学到了错误的经验。因为医院通常会将肺炎并发哮喘的病人予以重症监护,从而改善了他们治疗的结果。由于只看到了病人的迅速改善,AI会建议将病人送回家。(对于同时患有胸痛和心脏病的肺炎患者AI也会犯同样的乐观错误)
Caruana已经开始向加州医院兜售GAM解决方案,其中就包括洛杉矶儿童医院,该医院的10多位医生评估了他的结果。他们很快就理解了它的决策,在会上把大部分的时间都花在讨论这个东西对判断肺炎是否该住院的意义上。一位医生说:“你对医疗保健懂得不多,但你的模型的确懂。”
有时候你得拥抱黑暗。这是寻求实现可解释性的第三条路径的研究人员的理论。他们说,我们不要去探究神经网络,也用不着回避它们,解释深度学习的办法只要做更多的深度学习就好了。
如果我们无法对为什么它们会做某事提出问题并且获得合理的响应的话,大家就会把它束之高阁
就像许多AI编码者一样,乔治亚理工技术学院Entertainment Intelligence Lab主任Mark Riedl求助于1980年代的视频游戏来测试自己的作品。Frogger是他喜欢的游戏之一,玩家要控制着与游戏同名的这种两栖动物穿越车水马龙的公路去到对面的池塘。训练神经网络玩专业级的Frogger非常容易,但解释AI在做什么却要比通常难很多。
Riedl不去调查那个神经网络,而是让人类受试者玩游戏然后实时描述自己的策略。Riedl把那些话以及青蛙的上下文记录到了游戏的代码里面:“哦,这儿有辆车开过来了;我得往前跳。”在玩家和代码两种语言的帮助下,Riedl训练第二个神经网络在两者之间进行翻译,把代码翻译成英语。然后他再把那个翻译网络植入到原先玩游戏的网络,做出了一个整体的AI,这个AI在车道等待时,会说“我在等待一个洞打开再走。”当被困在屏幕一边时,该AI甚至会发出沮丧的声音,不断抱怨说:“靠,太难了。”
Riedl把他的方法叫做“合理化”,旨在利用这种方法帮助日常用户理解很快就将帮我们打理家务和开车的机器人。Riedl说:“如果我们无法对为什么它们会做某事提出问题并且获得合理的响应的话,大家就会把它束之高阁。”但他补充道,那些解释,不管如何给人以慰藉,却会引发另一个问题:“这种合理化错到什么程度才会让大家失去信任?”
再回到Uber,Yosinski被赶出了他的玻璃箱。Uber以城市命名的会议室总是很抢手,而且这里并没有峰时定价(surge pricing)来限制拥堵。他离开了多哈去找蒙特利尔,下意识的模式识别处理引导着穿越迷宫般的办公区——直到他迷路了。他的图像分类器依然是个迷宫,而且就像Riedl一样,他征召了第二个AI来帮他理解第一个。

研究人员创建了一种神经网络,这种网络除了能补全相片以外,还能识别出人工智能的瑕疵。
首先,Yosinski重新编排该分类器来生成图像而不是给图像打标签。然后他和他的同事给该神经网络提供彩色的静态图,再通过它回送一个信号,要求比方说“更多的火山”。他们假设该网络最终会将此噪音塑造成自己认为的火山的样子。从某种程度上来说,它做到了:那个火山在人类的肉眼看来正好是一团灰色的没有特征的东西。AI和人的视角是不一样的。
接下来,该团队放出了一个针对自身图像的生成对抗网络(GAN)。此类AI包含了两种神经网络。这个“生成器”通过一个图像的训练集学会了图像制作的规则并且可以合成图像。第二个“对抗”网络则试图检测出结果图片是真的还是假冒的,提示生成器再来一次。这样不断反复之后最终就可以得出包含有人类可识别特征的粗糙图像。
Yosinski和他之前的实习生Anh Nguyen把这个GAN连接到他们原先分类器网络内部的层。这一次在被告知要创建“更多的火山”时,GAN会将分类器学到的灰色噪音和自己对图片结构的知识结合起来,将其解码为海量的一组合成的、现实主义风格的火山。一些是在休眠的。一些是在晚上的。一些是白天的。还有一些可能是存在瑕疵的——这些都是了解分类器知识鸿沟的线索。
他们的GAN现在可以绑定到任何利用图像的网络上。Yosinski已经用它来识别受训为随机图像写标题网络存在的问题。他把网络颠倒过来,这样就可以为任何随机标题输入创作合成图像。把把它连接到GAN之后,他发现了一个令人吃惊的纰漏。在收到想象“一只鸟站在树枝上”的提示后,这个按照GAN翻译的指令执行的神经网络生成了一幅乡村风格的树和树枝的临摹,但是却没有鸟。为什么?在给原先的标题模型添加修改的图像之后,他意识到训练网络的那个写标题的人从来都没有描述过有鸟情况下的树和树枝。在鸟由什么构成方面AI学到了错误的经验。Yosinski说:“这给AI神经科学的一个可能的重要方向提供了灵感。”这是一个开端,一张地图正在慢慢地从空白一点一点地显现。
天色渐晚,但Yosinski的工作似乎才刚刚开始。这时候门外又响起了敲门声。Yosinski和他的AI又被从另一个玻璃盒子会议室赶了出来,回到Uber由城市、计算机和人组成的迷宫式的办公区里面。这次他不再迷路了。他穿过了快餐吧,绕过了沙发区,通过出口进入电梯。这是个简单模式。他学得太快了。
来源:36氪

媒体合作请联系:
邮箱:contact@dataunion.org



