从EMD、WMD到WRD:文本向量序列的相似度计算

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
在 NLP 中,我们经常要去比较两个句子的相似度,其标准方法是想办法将句子编码为固定大小的向量,然后用某种几何距离(欧氏距离、cos 距离等)作为相似度。这种方案相对来说比较简单,而且检索起来比较快速,一定程度上能满足工程需求。
此外,还可以直接比较两个变长序列的差异性,比如编辑距离,它通过动态规划找出两个字符串之间的最优映射,然后算不匹配程度;现在我们还有 Word2Vec、BERT 等工具,可以将文本序列转换为对应的向量序列,所以也可以直接比较这两个向量序列的差异,而不是先将向量序列弄成单个向量。

本文要介绍的两个指标都是以 Wasserstein 距离为基础,这里会先对它做一个简单的介绍,相关内容也可以阅读笔者旧作从 Wasserstein 距离、对偶理论到WGAN。
Wasserstein 距离也被形象地称之为“推土机距离”(Earth Mover's Distance,EMD),因为它可以用一个“推土”的例子来通俗地表达它的含义。
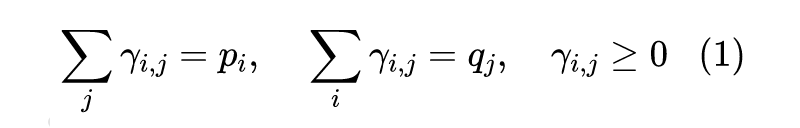
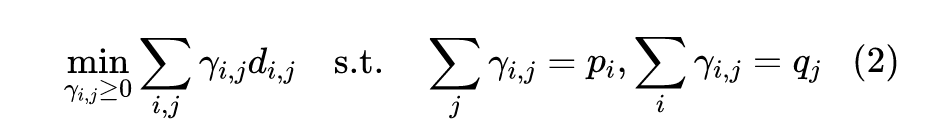
看上去复杂,但认真观察下就能发现上式其实就是一个线性规划问题——在线性约束下求线性函数的极值。而scipy就自带了线性规划求解函数linprog,因此我们可以利用它实现求 Wasserstein 距离的函数:
import numpy as np
from scipy.optimize import linprog
def wasserstein_distance(p, q, D):
"""通过线性规划求Wasserstein距离
p.shape=[m], q.shape=[n], D.shape=[m, n]
p.sum()=1, q.sum()=1, p∈[0,1], q∈[0,1]
"""
A_eq = []
for i in range(len(p)):
A = np.zeros_like(D)
A[i, :] = 1
A_eq.append(A.reshape(-1))
for i in range(len(q)):
A = np.zeros_like(D)
A[:, i] = 1
A_eq.append(A.reshape(-1))
A_eq = np.array(A_eq)
b_eq = np.concatenate([p, q])
D = D.reshape(-1)
result = linprog(D, A_eq=A_eq[:-1], b_eq=b_eq[:-1])
return result.fun
A_eq=A_eq[:-1], b_eq=b_eq[:-1]
,也就是去掉了最后一个约束。

设有两个句子 ,经过某种映射(比如 Word2Vec 或者 BERT)后,它们变成了对应的向量序列 ,现在我们就想办法用 Wasserstein 距离来比较这两个序列的相似度。
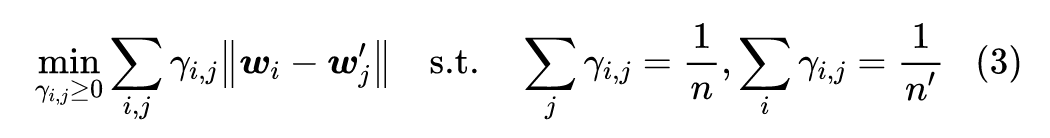
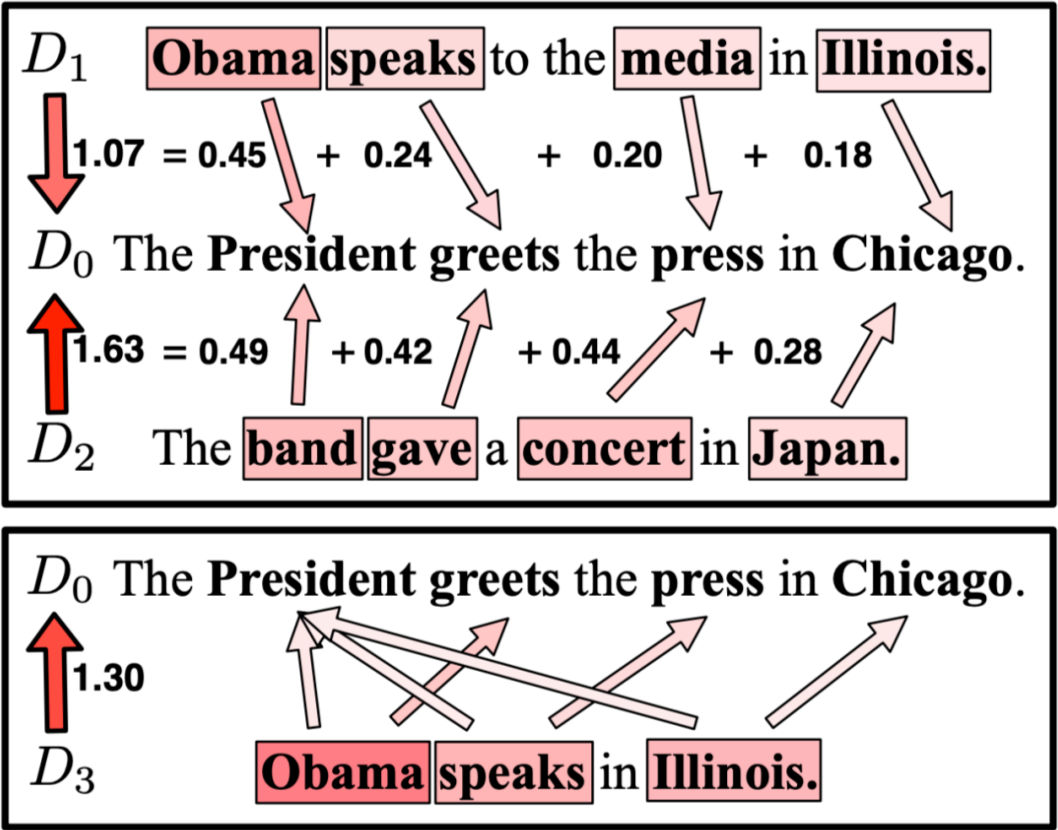
▲ Word Mover's Distance 的示意图,来自论文 From Word Embeddings To Document Distances
2.2 参考实现
参考实现如下:
def word_mover_distance(x, y):
"""WMD(Word Mover's Distance)的参考实现
x.shape=[m,d], y.shape=[n,d]
"""
p = np.ones(x.shape[0]) / x.shape[0]
q = np.ones(y.shape[0]) / y.shape[0]
D = np.sqrt(np.square(x[:, None] - y[None, :]).mean(axis=2))
return wasserstein_distance(p, q, D)
如果是检索场景,要将输入句子跟数据库里边所有句子一一算 WMD 并排序的话,那计算成本是相当大的,所以我们要尽量减少算 WMD 的次数,比如通过一些更简单高效的指标来过滤掉一些样本,然后才对剩下的样本算 WMD。
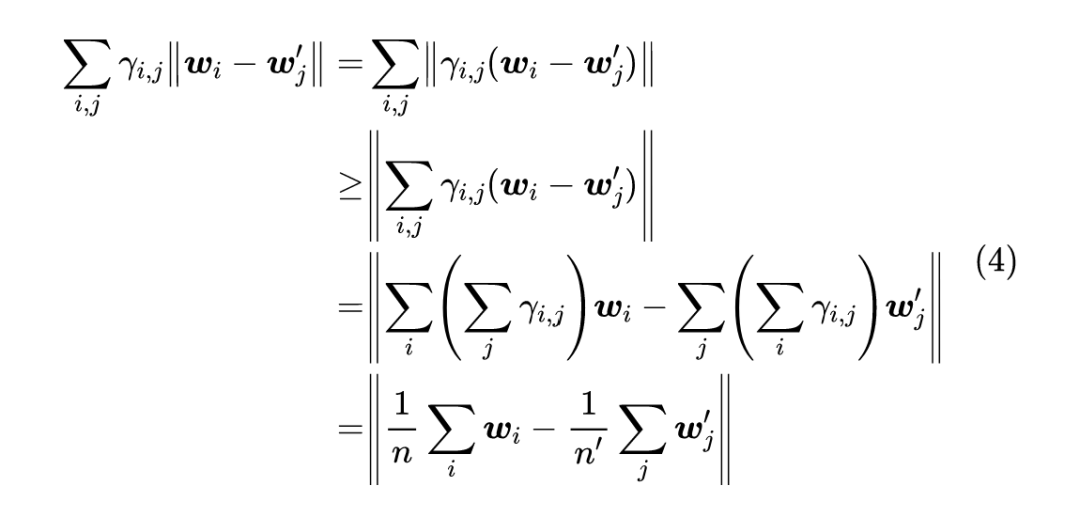

WMD 其实已经挺不错了,但非要鸡蛋里挑骨头的话,还是能挑出一些缺点来:
-
它使用的是欧氏距离作为语义差距度量,但从 Word2Vec 的经验我们就知道要算词向量的相似度的话,用 往往比欧氏距离要好; -
WMD 理论上是一个无上界的量,这意味着我们不大好直观感知相似程度,从而不能很好调整相似与否的阈值。
为了解决这两个问题,一个比较朴素的想法是将所有向量除以各自的模长来归一化后再算 WMD,但这样就完全失去了模长信息了。
最近的论文 Word Rotator's Distance: Decomposing Vectors Gives Better Representations [2] 则巧妙地提出,在归一化的同时可以把模长融入到约束条件 p,q 里边去,这就形成了 WRD。
首先,WRD 提出了“词向量的模长正相关于这个词的重要程度”的观点,并通过一些实验结果验证了这个观点。事实上,这个观点跟笔者之前提出的 simpler glove 模型的观点一致,参考《更别致的词向量模型(五):有趣的结果》[3] 。
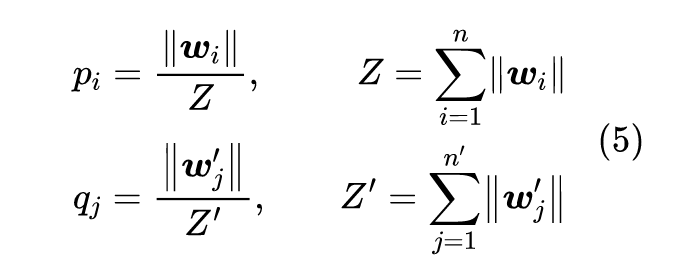
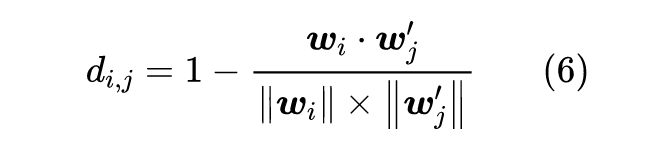
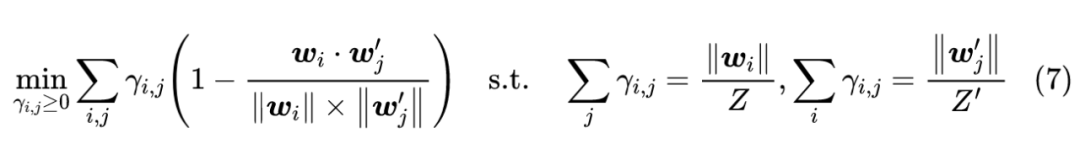
3.2 参考实现
参考实现如下:
def word_rotator_distance(x, y):
"""WRD(Word Rotator's Distance)的参考实现
x.shape=[m,d], y.shape=[n,d]
"""
x_norm = (x**2).sum(axis=1, keepdims=True)**0.5
y_norm = (y**2).sum(axis=1, keepdims=True)**0.5
p = x_norm[:, 0] / x_norm.sum()
q = y_norm[:, 0] / y_norm.sum()
D = 1 - np.dot(x / x_norm, (y / y_norm).T)
return wasserstein_distance(p, q, D)
def word_rotator_similarity(x, y):
"""1 - WRD
x.shape=[m,d], y.shape=[n,d]
"""
return 1 - word_rotator_distance(x, y)3.3 下界公式


小结
参考链接
[1] http://proceedings.mlr.press/v37/kusnerb15.html
[2] https://arxiv.org/abs/2004.15003
[3] https://kexue.fm/archives/4677

点击以下标题查看更多往期内容:

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




