GBDT与XGBOOST串讲

XGBOOST怎么生成一棵树?
GBDT算法是什么?
GBDT与BT(提升树)是一回事吗?
本篇文章结构:
Boosting Tree(提升树)

其中2.a步是计算残差,2.b步通过把2.a的残差当作标签,可以使用线性回归的方法进行拟合残差。通过M次循环一共得到M+1颗树,每个输入数据X的结果,是M+1棵树预测的结果之和。
GB算法
当提升树的损失函数是平方损失和指数损失时,每一步优化很简单;但是对于一般函数,优化不是非常简单,因此采用梯度下降法进行优化。至于为什么是“梯度提升”,我的理解是首先基于当前模型损失函数的负梯度信息进行拟合形成新的弱分类器,然后根据残差进行寻找该新分类器的权重!由此,即为梯度提升!
具体算法如下:

第4步,使用梯度作为标签进行拟合新的一棵树;第5步是基于残差进行得到新的一颗树的权重,其中残差来自于第i个数据的标签y与前m-1棵树的差得到的。其中F(x)表示前几棵树的总的函数。
GBDT算法
有了上面的GB算法介绍,那么使用决策树作为弱分类器的GB算法被称为GBDT(Gradient Boosting Decision Tree)。一般采用CART得到决策树,CART是采用基尼指数作为决策树的损失增益函数。基尼指数反应了数据集D中任意两个样本不一致的概率。其基尼指数越高则数据集D的纯度越高;纯度越高正是决策树每个叶子节点的类别越一致。信息熵和基尼指数都是《信息论》中的内容。
XGBOOST
XGBOOST是GBDT算法的工程实现,XGBOOST的公式推导采用二阶泰勒公式的展开形式进行推导,使得每棵树之间得变化更小,而且还使用了正则化项,控制了每棵树的复杂度,进而防止过拟合。
公式推导也可以参见论文XGBoost: A Scalable Tree Boosting System
XGBOOST在生成一颗树的时候,使用如下公式进行左右分支。
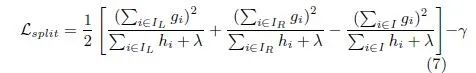
训练得到第M棵树的损失函数:
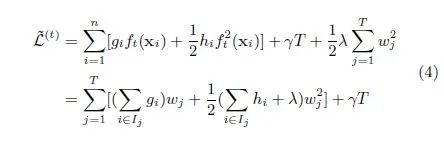
其实XGBOOST每一次分支采用的是贪心算法,对于决策说来说每次分支也是采用贪心算法,只不过每次进行分支使用的损失函数不一样。对于决策树有基尼指数、信息熵等loss函数。
参考文献:
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



