【神经网络】解神经网络与深度学习的3大必看知识点
神经网络与深度学习的3大必看知识点

一、神经网络与深度学习简介
神经网络是基于大脑的生理研究成果,抽象和模拟人脑神经网络若干基本特性进行信息处理的一种机器学习模型,它是由大量模拟人感知神经元的基本处理单元组成的多层次、非线性的网络。这些基本处理单元我们称之为神经元,神经元接受多个输入并产生一个输出,它的数学模型可以描述为:
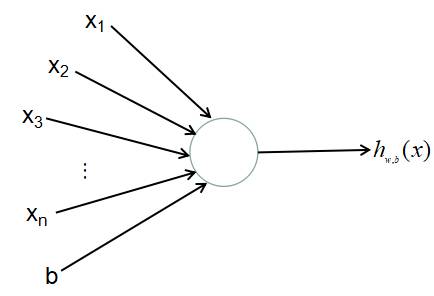
函数f称为激活函数,W是权重向量,x是输入向量,常量b称为截距。
多个神经元联结在一起即组成一个神经网络:
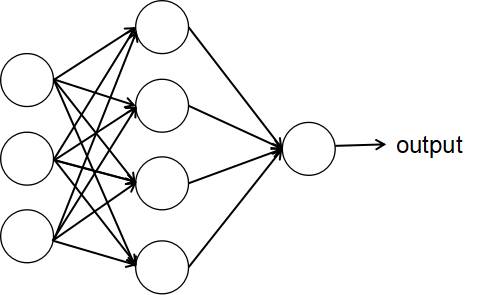
上图最左边称为输入层,最右边称为输出层,中间称为隐层。
深度学习就是基于含多隐层的神经网络逐层抽象特征,每个隐层从上一层输出提取特征,层层抽象特征直至输出。

基于多层神经网络的深度学习具有非线性特性,

对于深度学习,黑盒子可以描述为一个复合函数f(x):
及神经网络发展历史
2.1从传统机器识别到神经网络
机器识别的传统方法依赖人工预先设计的特征对原始数据进行分类和处理:

例如,对于图像识别,需要研究者长期的研究来设计更为准确的识别特征。传统机器识别依赖于人的先验知识,受限于人的知识,对于海量数据,人工设计特征费时费力,而且很难设计具备多样性、准确性的特征。所以在天气预测、股票分析等领域,传统方法很难奏效。
受益于David Hubel、Toeserl Wiesel两位诺贝尔医学奖获得者在人类视觉信息处理系统上的发现,人们意识到人的不同神经元对不同的刺激产生响应,神经系统逐层处理信息,人的大脑工作是一个逐层迭代、不断抽象的过程。
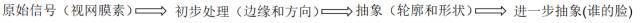
这给机器学习带来了启发,模拟人的神经系统工作机制在机器学习上是一种行之有效的方法。
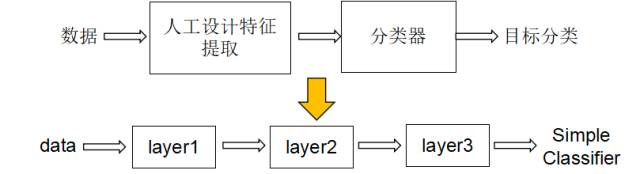
这种模拟人的神经系统工作机制的层次特征学习系统采用多层网络结构对原始数据进行处理,通过端到端的方式训练,极大地减少了对人的依赖度,网络的的所有层的特征都是从数据学习到的,每层从上层输出中提取特征。
2.2反向传播算法
在2.1阐述的神经网络概念在上世纪80年代就已出现,当时人们使用的神经网络训练算法称为反向传播算法(BP算法),它定义了一个损失函数来优化每层神经元的权重参数。损失函数是描述实际输出与预期输出差别的函数,应用链式求导法则可以求出每层权重参数的偏导数。反向传播算法工作过程有三个步骤:
(1)前向传播激励响应
(2)和目标比较得到损失
(3)反向传播修正权重,重新进行步骤(1)
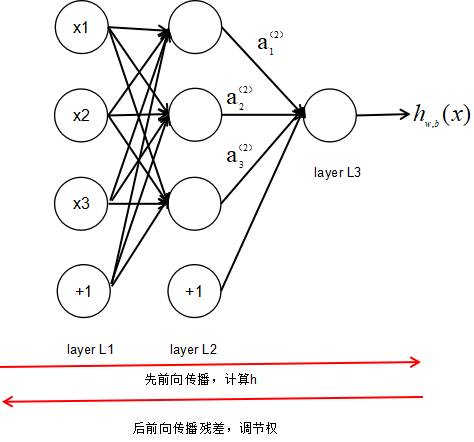
反向传播算法训练神经网络存在以下三个问题:
(1) 数据获取:训练深层神经网络依赖有标签的数据,大量有标签数据获取比较困难
(2) 局部极值:求解一个高度非凸的优化问题,非常容易局部最小,多层非线性神经网络优化很难得到全局最优
(3) 梯度弥散:当网络层次较多时,梯度传到前几层严重衰减,前几层不能有效训练,从而深度神经网络不能有效工作
这些问题严重阻碍了深度神经网络的应用,一度导致神经网络发展停滞。
2.3自编码器
2006年针对2.2中阐述的反向传播算法存在的三个问题取得重大突破—逐层无监督训练方式的提出。不同于从顶层开始训练的方式,逐层无监督训练从离数据最近的底层开始训练,这样就解决了单纯有监督方式深层神经网络无法训练的问题。
自编码器就是一种逐层无监督神经网络训练方式,自编码器的特点是预先对从最接近数据的底层开始对每一层输入进行重构,即每一个隐含层的输出等于它的输入,并引入约束条件避免平凡解。在逐层进行上述的预处理后,再对全局使用反向传播算法进行调参优化。
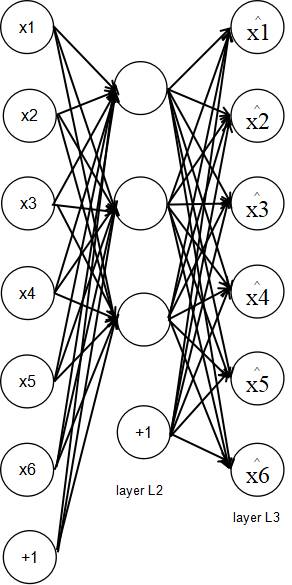
这种通过无监督逐层训练获得一个较好的初始值,再通过有监督训练进行微调的方式可以有效解决数据获取、局部极值和梯度弥散问题。
三、深度学习应用
3.1语音识别

语音识别主要做的工作是将输入语音数据映射到特定因素上,可以是一个元音、一个词、或一句话。语音识别一种做法是先将语音信号变换到频域,然后输入到一个深度神经网络模型,经过逐层无监督训练预处理,再整体训练,会获得比传统机器识别更好的匹配效果。另一方面,深度神经网络可以将在一种语言上学习到的特征复用到另一种语言上,这对数据量少的小语种来说尤为有利。语音识别另一种较为流行的做法是将语音信号输入到RNN(循环神经网络),这样做可以节省很多预处理工作。
3.2 图像识别

人脸识别技术
图像识别做的工作是识别图像中各种不同模式的目标和对像。对于图像而言,输入数据维度很大,这会导致神经网络很大,我们很难去训练这样的神经网络。所以在输入神经网络之前需要对图像数据进行降维处理,首先进行卷积操作,即每个神经元只连接图像的一个区域,由多个神经元对一个图像完成扫描,这些神经元共享权值,然后经过下采样降低维度后再次重复上两步操作。这样我们就可以用比较少的参数描述图片里的重要信息。在图像识别中,特征复用可以用来做目标检测、看图说话等工作。
3.3 AlphaGo
2016年围棋人工智能程序AlphaGo引发广泛的讨论,传统的下棋程序采用蒙特卡洛搜索方式,每次随机下子,经过多次搜索,然后选择一种最有利的下子方式。

AlphaGo利用CNN(卷积神经网络)构建策略网络模拟人的“棋感”,然后利用价值网络判断局面优势,再结合蒙特卡洛搜索,利用策略网络和价值网络减少搜索的宽度和深度。多个神经网络组合成神经系统、神经网络和逻辑推理结合使AlphaGo取得了成功。AlphaGo还有一个具有启发性的特点:它通过自我博弈获得大量数据。
3.4 自然语言处理
自然语言处理做的工作是让计算机理解人的语言,神经网络不擅于处理语言这种离散的符号,这就需要利用词嵌入技术将离散的词转换为连续的向量。词嵌入是将词汇映射到实数向量的方法。
对于文本序列处理任务,例如文本翻译,需要训练模型具有记忆能力,它能够知道过去时刻的状态,RNN(循环神经网络)就是一种有记忆的模型,RNN隐单元除了接受上一层的输出,它还接受上一刻的状态作为输入。RNN记忆能力有限,训练长度dt>10时,RNN就很难训练。
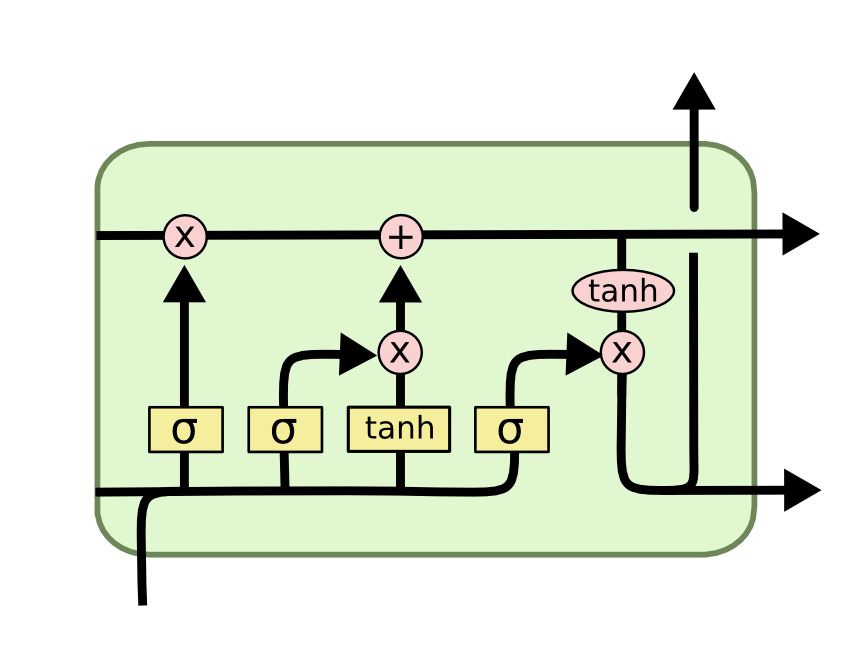
LSTM(Long Short-Term Memory)
为了改进这一点,LSTM(长短时记忆模型被提出)。LSTM区别于RNN的地方,在于它RNN中加入了一个特殊记忆单元,特殊记忆单元有三扇门,分别叫做输入门、遗忘门和输出门,根据规则来对信息进行不同的操作。LSTM不同于RNN替换的隐单元更新方式,它采用累加的方式更新隐单元,具有更稳健的动力学特性。另外在长句子翻译出来上常用注意力机制,注意力机制主要有两个:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。这相当于给神经网络增强记忆,这类记忆增强的神经网络包括NTM、MenNN、DNC等。
深度学习在语音、图像识别、自然语言处理等领域都取得了广泛的利用,这不仅是因为深度学习算法研究上的成果,还受益于数据资源的大量增加,和GPU的应用。目前人工智能应用主要集中在感知问题领域,对于解决认知问题、真正具有和人一样的智能,仍然是当下人工智能不能做到的。
作者:鄙人苟富贵
编辑:Yiri
本文为《从神经网络到深度学习》课程的学习心得
“激活函数”知识清单…

一、激活函数目的与历史
目的
模拟生物神经元对刺激的响应
在神经网络中加入非线性的魔法
拟合不同函数的实用道具
历史
1943 Mc Culloch-Pitts 模型
第一个神经元的数学模型
使用二值阶跃函数
1958 Bosen blatt 感知机
M-P模型,考虑神经元间信息传递与计算
多层感知机+可微激活函数=可学习模型
采用阈值函数或S型函数
二、激活函数的生物学与机器学习观点
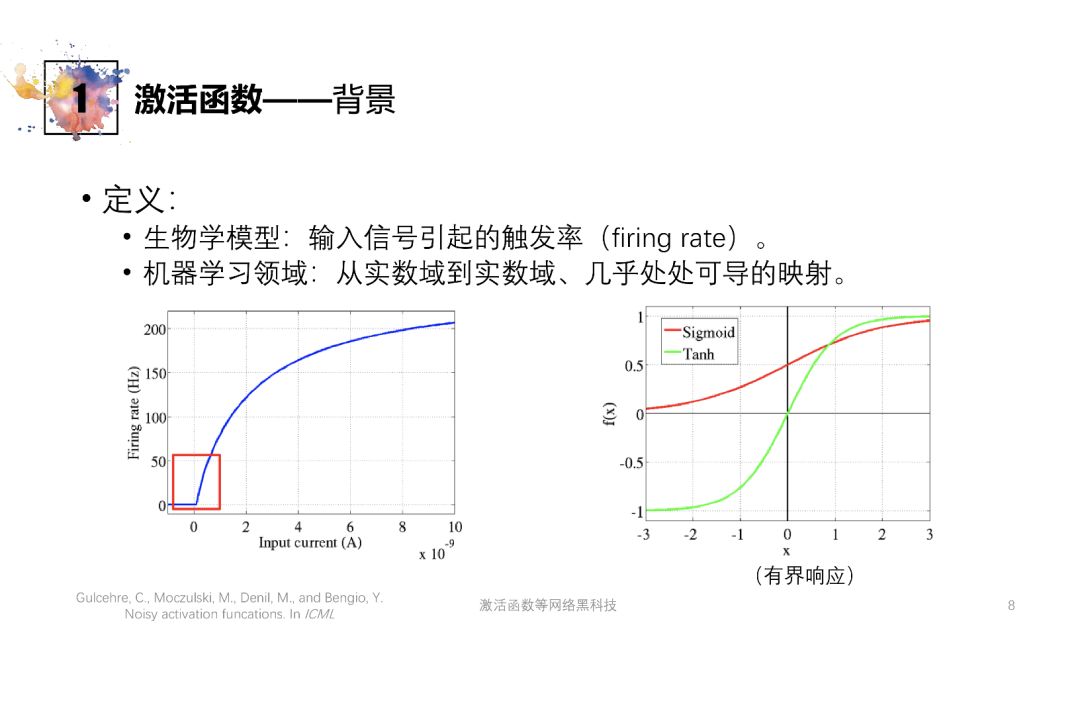
计算生物学
得到的激活函数基于实验
描述输入电信号强弱与神经细胞发射信号多少之间的关系
机器学习
适合理论的拟合/预设函数
描述单个神经元模型多个输入值与单个输出值之间的关系
EX: 机器学习领域的Sigmoid 函数与生物学模型的区别
Sigmoid函数没有生物学上的单侧抑制(考虑到学习时优化的必要)
相比于Sigmoid函数而言,生物学模型的兴奋边界更宽阔(实际需要)
生物学模型具有较大的稀疏激活性(即更少的神经元真正在工作)
NOTE:从Sigmoid函数与tanh函数看如何分析激活函数性能
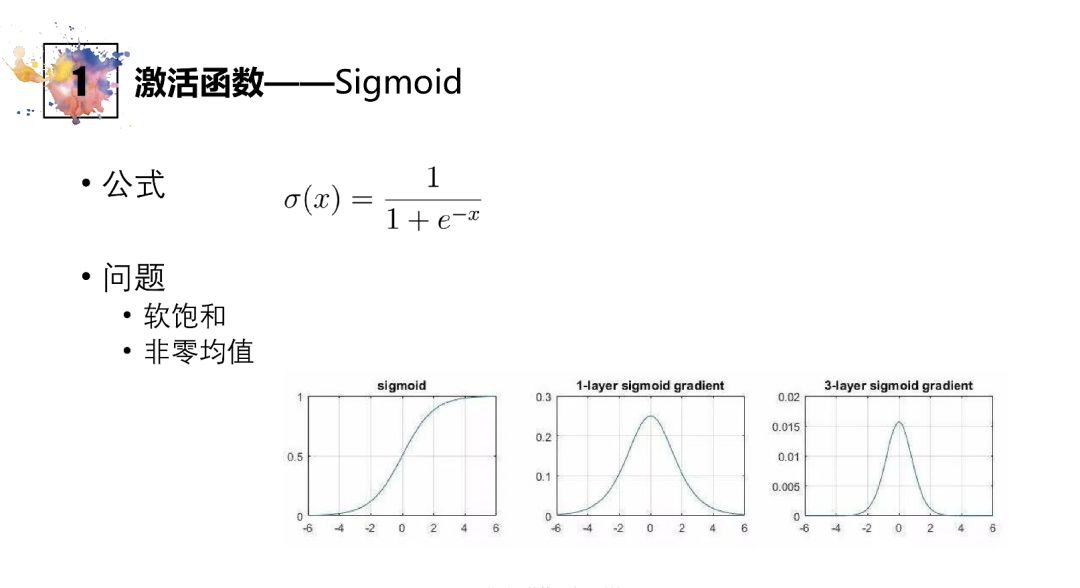
Sigmoid
软包和指当x较大时y梯度趋于零,变化不明显
非零均值使得优化时效率受损
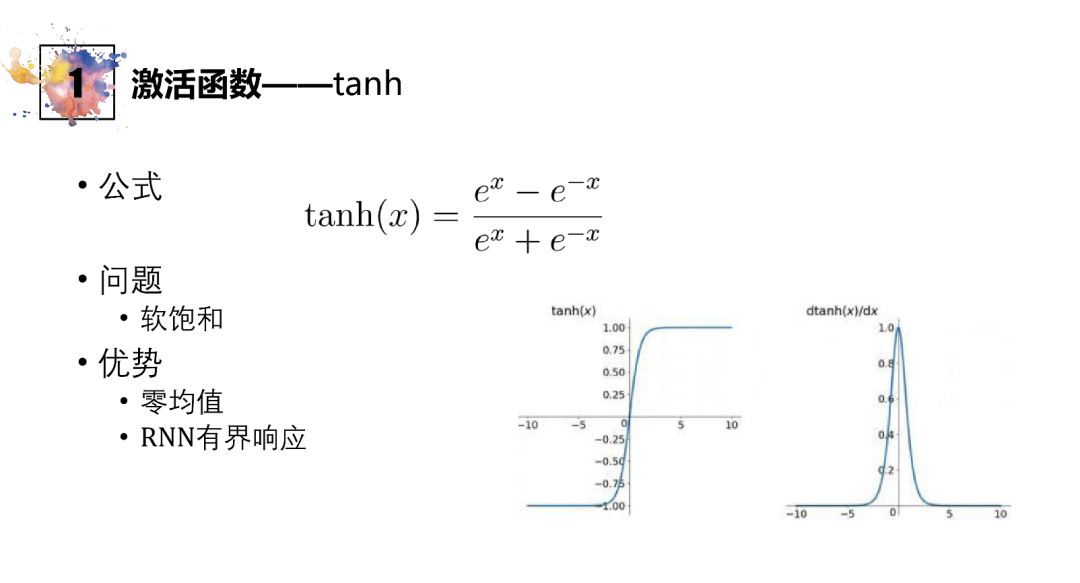
tanh
通过小变化将Sigmoid变为零均值,优化了表现
三、激活函数的性质
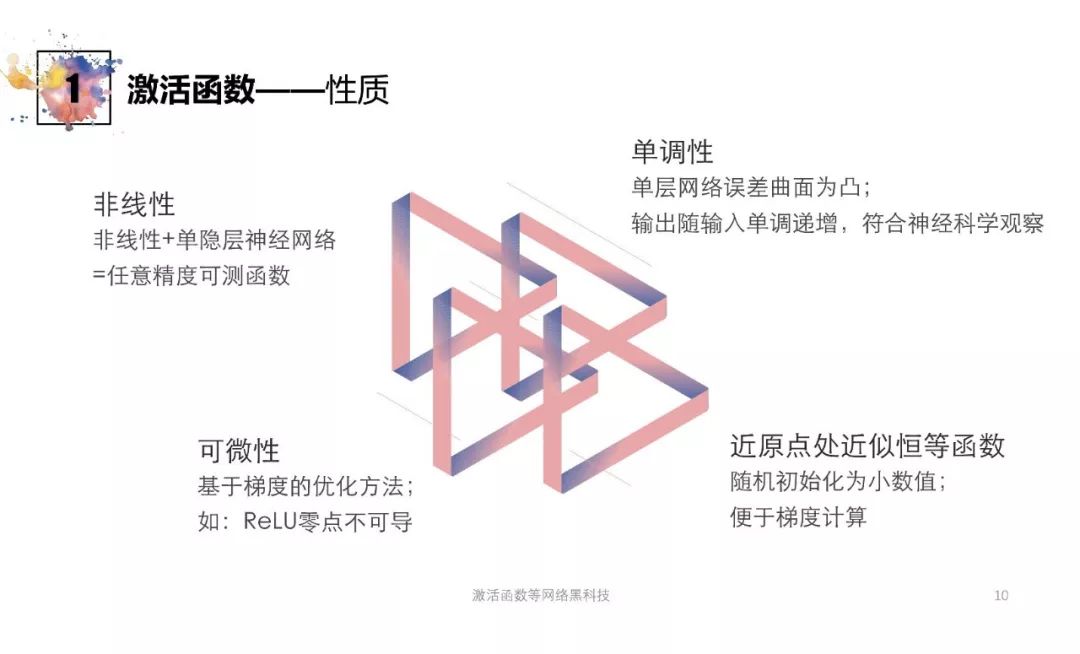
非线性
必要性上需要在线性的矩阵网络中引入非线性的因素
充分性上仅需要单隐层神经网络与非线性激活函数便能拟合任意函数
可微性
学习的方法(基于梯度优化)需要非线性激活函数可微
同时应注意对此可微函数计算可行性进行考虑
单调性
生物学上符合科学观测,更有可能实现感知功能
机器学习上单层网络误差曲面为凸,易于优化
原点局部常数性
学习开始时随机初始化性能难以预测,此性质保证初始优化定向
初始导数易于计算,缩短模型“渐入佳境”的时间
四、稀疏性
生物学观察中的稀疏性
总体输入信息巨大,实际激活神经元仅占1%-4%
总体耗能较小,分布式计算
稀疏性在机器学习中的优势
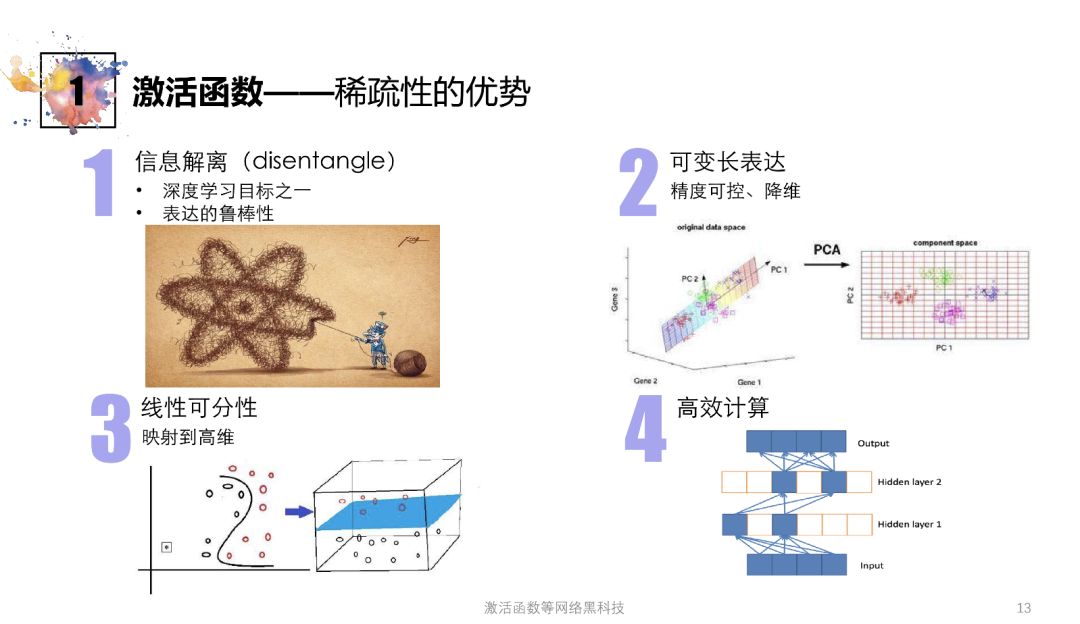
信息解离
深度学习目标之一——复杂数据分析的重要部分
通过解离factors,使得多维向量的每一维都可被理解
增加表达的鲁棒性(稍微变动向量,不太影响每维信息理解),抵御噪声
可变长表达
判定不同维重要性后可选取维数,按精度选择个数
选取后可进行降维处理,节省计算量
线性可分性
原本未必可分,映射到高维后可能可分
分类与运算便利
高效计算
有很大部分神经元不响应
产生不用计算的零输出
在前传与反传时都不需计算
稀疏性可能遇到的问题与解决
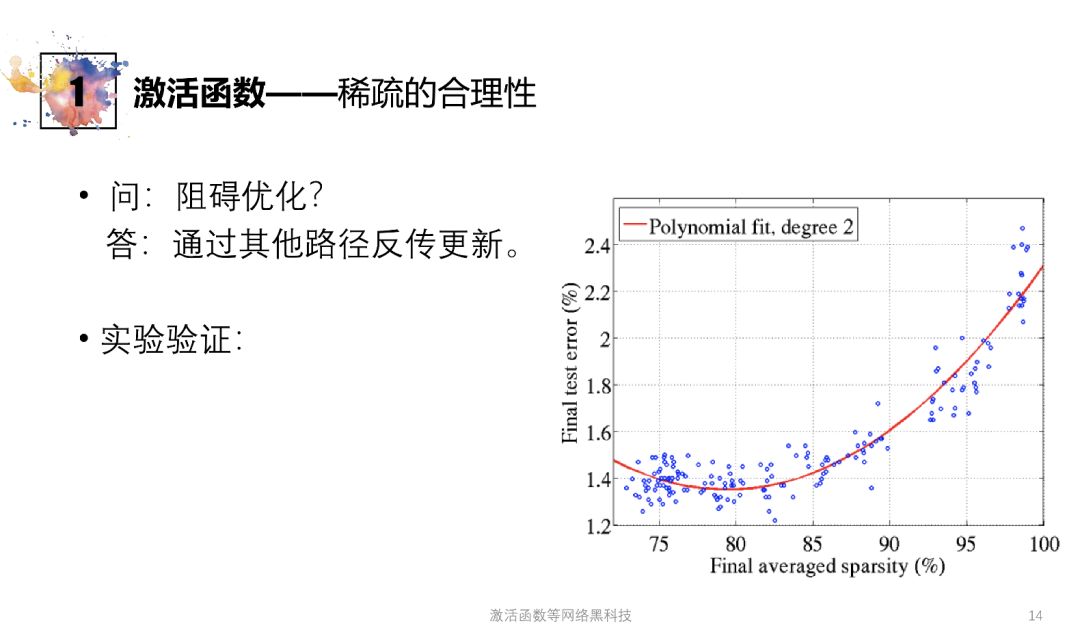
Q:是否会因零输出导致反传更新困难,阻碍优化?
A:事实上可以通过其它路径回传,且效果并不差,甚至更优
ex:上图中稀疏程度在75%-85%时实验错误率最低
五、ReLU函数及其变种与推广
ReLU函数
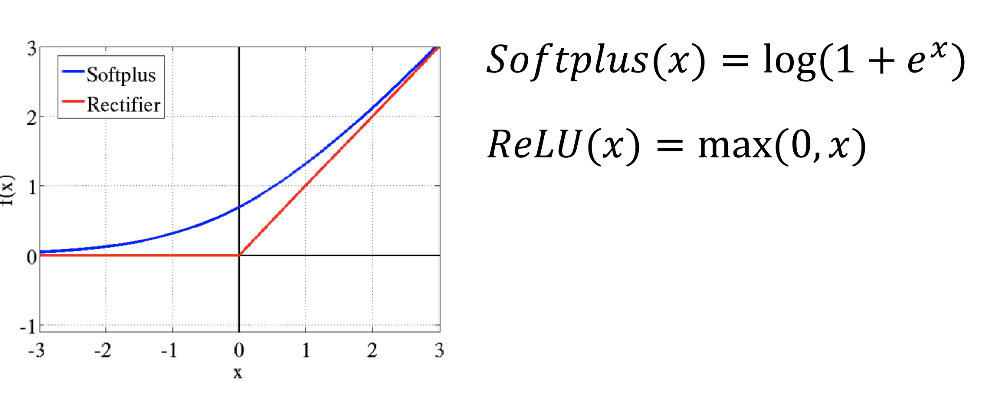
优势
ReLU函数有零值,可以模拟生物学模型的稀疏激活性
形式简单,便于计算
缺点
远点附近并非光滑可微
零值对优化带来挑战,可能带来“死亡神经元”
非零均值,效率不是最高
无上界,不具有BN网络收敛性
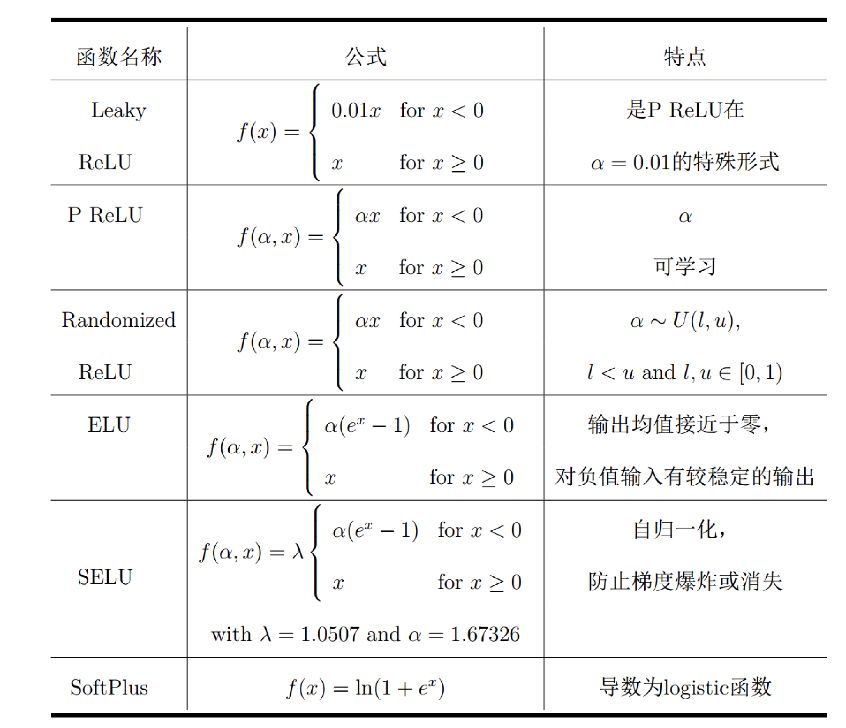
Leaky ReLU

使用人工设置的小参数应对负数时的零值
计算量增大,远慢于ReLU
参数人为调控,可以精细,但工作量大
P ReLU

可看作Leaky ReLU的泛化形式
拥有可学习的参数α,不需要手动调节
函数负值响应可更新,且与Leaky ReLU相比计算量提升并不大
ELU
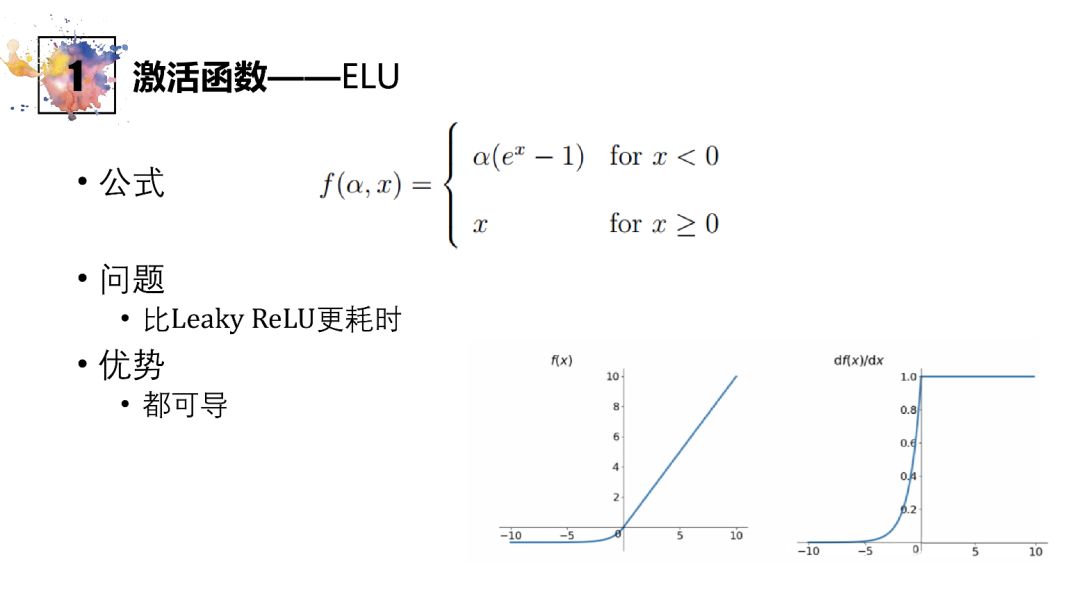
负值软包和,且倒数连续,易于优化
计算量较大,耗时较长
ReLU变种总结
Maxout(推广)
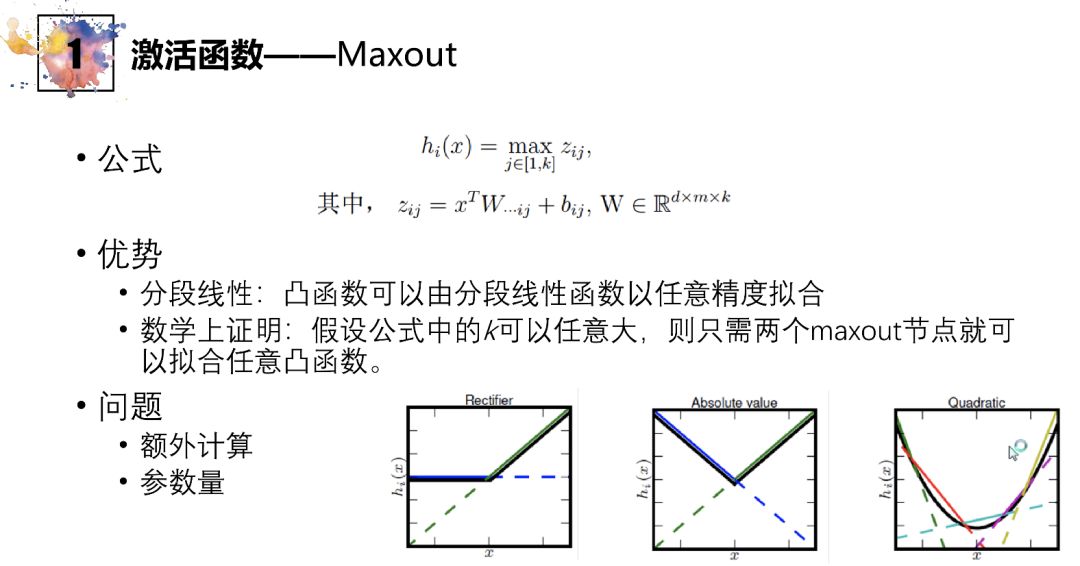
通过对多个输入神经元的数据进行计算,得到一些线性函数,并取各段最大值拼接
ReLU可视为特殊的情况
取足够多段拼接时,可逼近任意下凸函数
当段数过多时,计算量也增大,故应用需谨慎
另有一附加问题在于连接处不可导,优化不便
六、梯度消失与梯度爆炸
原因:
网络太深
激活函数选择不当
理论依据:
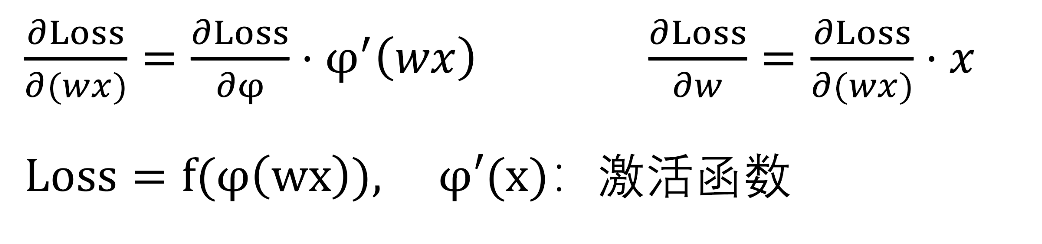
梯度减小/增加的逐层累计效应
S型函数梯度小于1,累积起来得到零结果
如何解决
Hinton 2006 仍使用S型函数,两步分步式训练,预训练加微调
使用其它非S型函数,如Softplus,ReLU,减少梯度的衰减(梯度与1相差不大)
其它方法

七、池化层与DPP简介
何为DPP

2018年paper
idea是不再抹平差异,而是保留差异
认为差异中信息量更大(自然的想法),并通过算法实现
仍是距离加权映射,只是更注重差异
更多calculation见paper
Attention Pooling
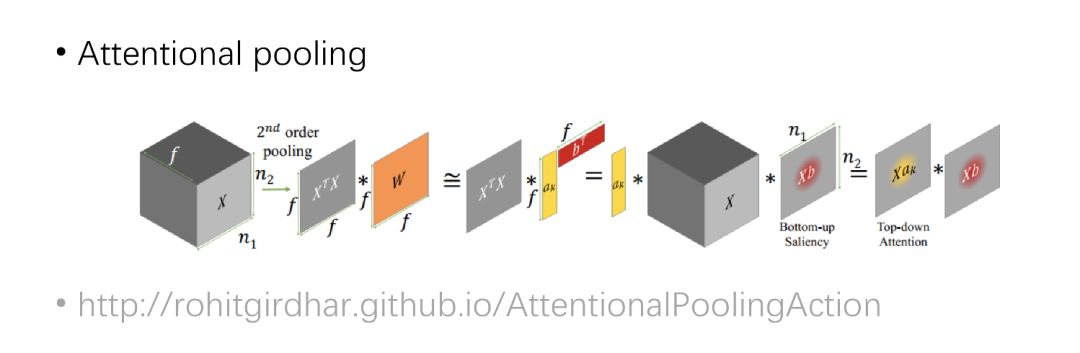
运用二阶池化,通过低置化完成简化,可用作行为识别
八、前沿进展简介
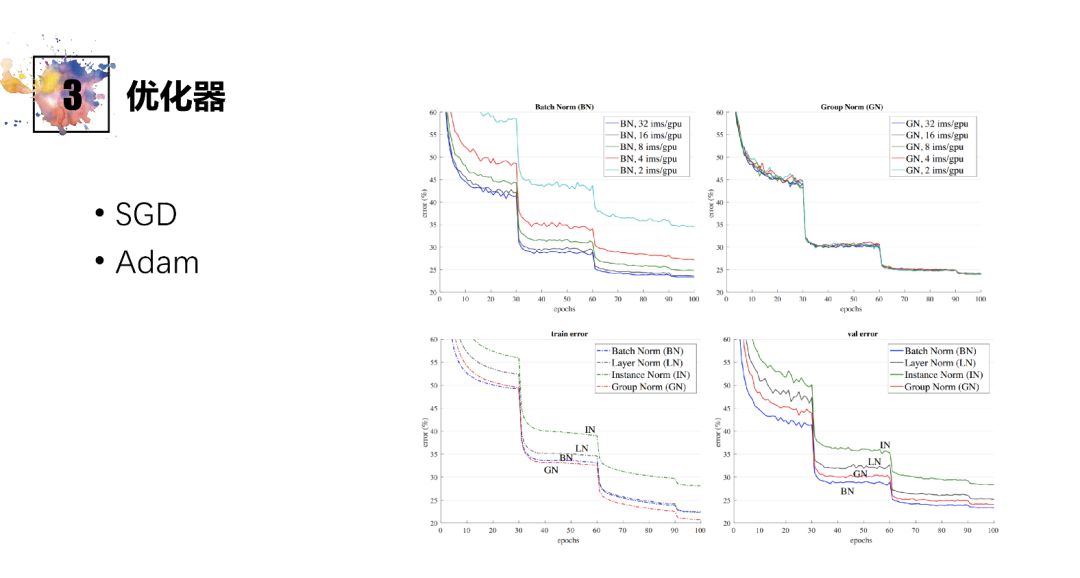
SGD通过人工手调何时减小learning rate,更多工作,但可以更精细
Adam不用人工调参数,但相对的,不会那么精细
作者:光头小海怪
编辑:Yiri
本文为《激活函数》课程的学习心得

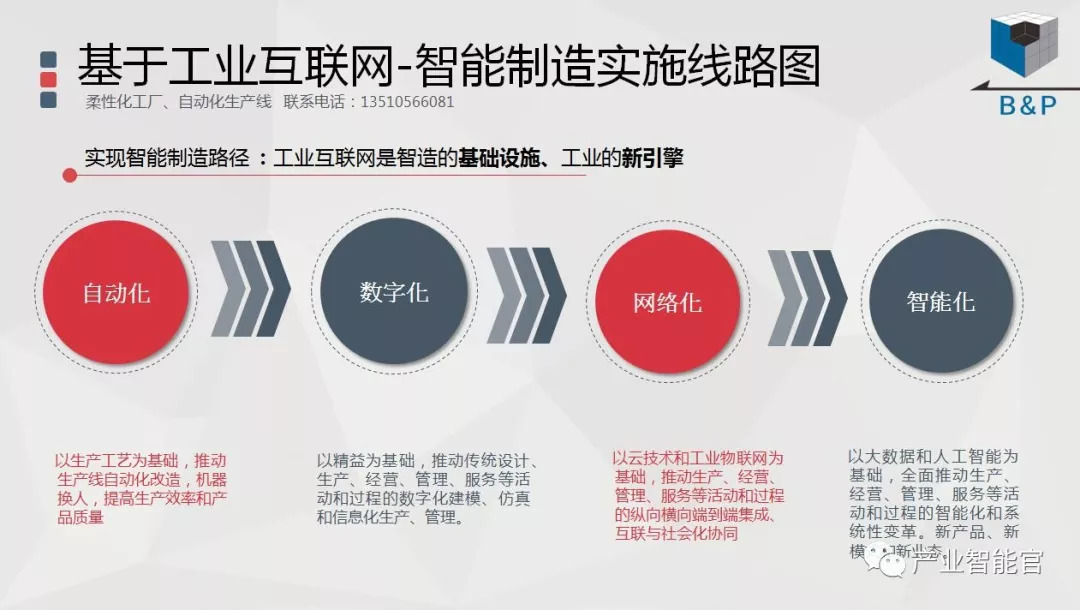
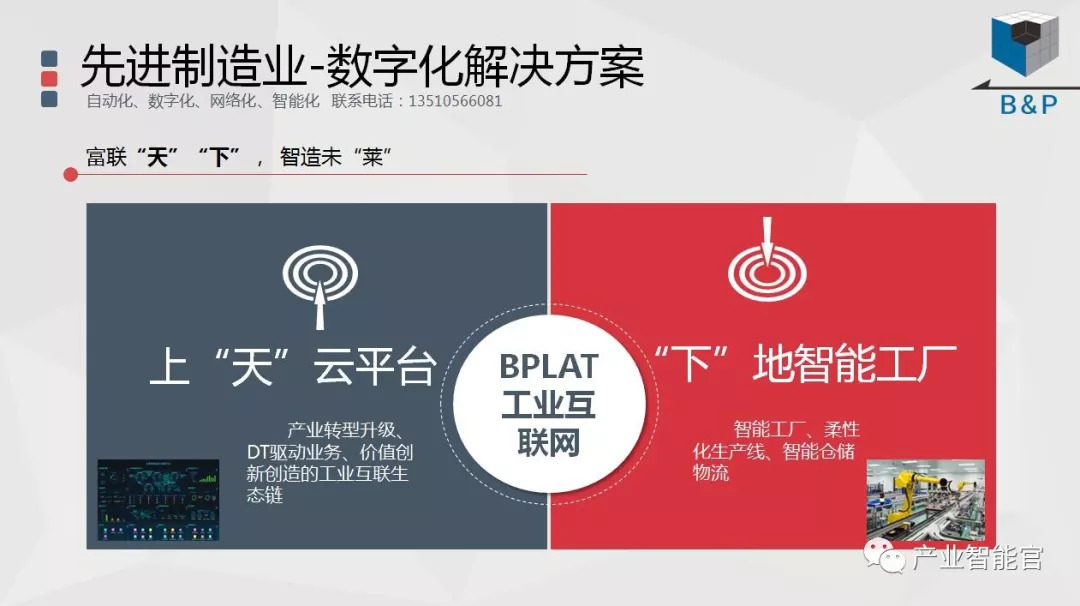
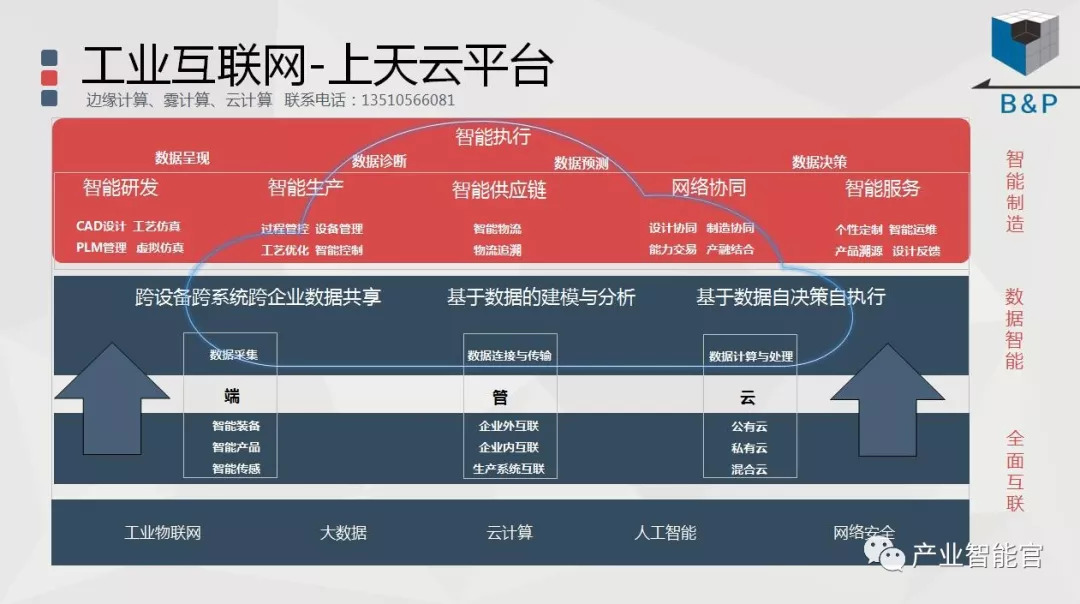
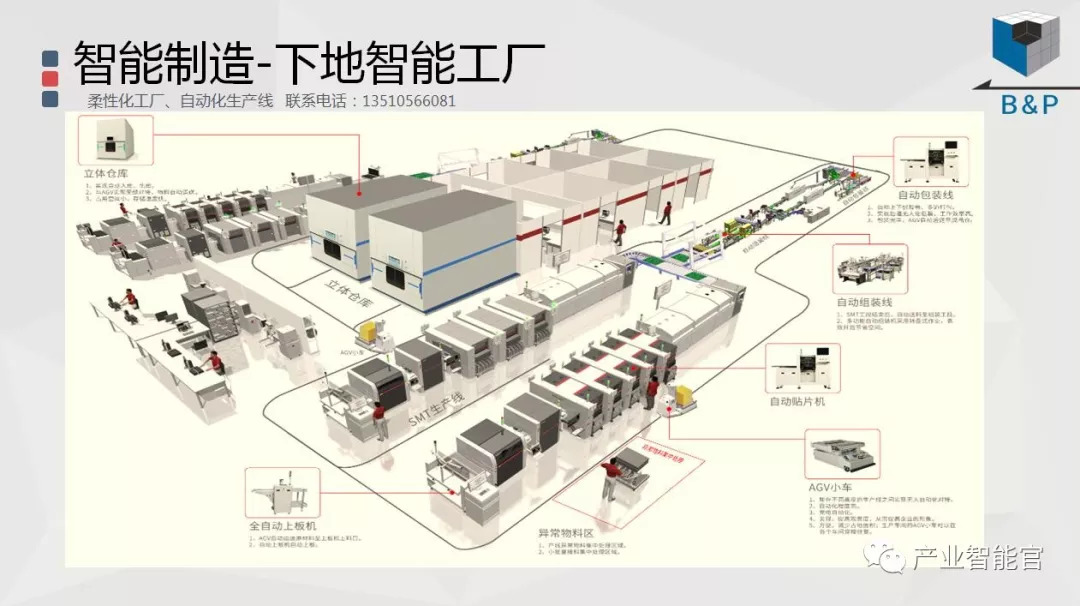
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:产业OT技术(工艺+精益+自动化+机器人)和新一代IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




