上海交大卢策吾团队CVPR 2018论文(五篇)简介

上海交大卢策吾团队(MVIG lab)在CVPR 2018发表五篇论文(第一作者,通信作者均为MVIG成员),简介如下,也请各位同行多提宝贵意见,不胜感谢。
01
Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer
Spotlight
human parsing是像素级别的人体部位分割,比人体关键点提供更精细信息量,但其标注量巨大,限制了准确率。那么能不能通过迁移学习,用人体关键点(human keypoint)来生产得大量的human parsing数据呢? 我们团队这篇论文做出了深入研究,并在human parsing 数据集上取得目前最好结果。(代码开源在MVIG的Github账号)
02
DBNet: A Large-Scale Dataset for Driving Behavior Learning
我们一直希望无人驾驶,从视觉信号(视频,点云)到驾驶行为能端到端(end-to-end)地学习。但在这一问题上一直缺乏一个大规模数据库。我们和厦门大学(共同一作,共同通信作者)联合推出了驾驶行为数据集DBnet(Driving Behavior net)包括代码,近期发布(会有相关媒体报道),希望能为该问题提供研究基础,敬请关注。
03
Environment Upgrade Reinforcement Learning for Non-differentiable Multi-stage Pipelines
Spotlight
增强学习如何修正不良结果,逐步走向正确结果。
04
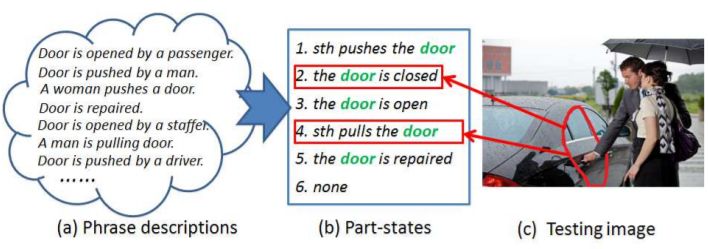
Beyond Holistic Object Recognition: Enriching Image Understanding with Part States
为了更深入理解各种语义,我们需要深刻理解到knowledge in part label,而不是简单地知道object category,我们提出一种part-state的概念,即物体part的状态来推断更为深刻的语义信息比如:object functionality,geometry relationship ,affordance, moment situation, interaction。
05
Recurrent Residual Module for Fast Inference in Videos
视频帧与帧之间存在冗余性,有没有可能利用这种冗余性,达成普遍加速。我们这篇论文给出一个算法,在各种视频应用(video object detection,video pose estimation等等)上普遍降低了计算量。(implementation非常简单)。


AlphaPose
最后,再次推广一下我们的alphapose (72 mAP),在coco超过openpose 相对17% (61 mAP)。我们团队一直持续优化,目前有pytorch版本,速度到5PFS,期望近期能推出25PFS版本。详情请参考我们的项目主页和开源代码。


Prof. Cewu Lu is a research Professor at Shanghai Jiao Tong University, leading Machine Vision and Intelligence Group. He is also one of MIT TR35 -"MIT Technology Review, 35 Innovators Under 35 (China)". He was Postdoc at Stanford AI lab (under Fei-Fei Li and Leonidas Guibas) and selected as the 1000 Overseas Talent Plan (Young Talent) (中组部青年千人计划).





