点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
如今,在 ImageNet 上的图像识别准确率的性能提升每次通常只有零点几个百分点,而来自图灵奖获得者 Geoffrey Hinton 等谷歌研究者的最新研究一次就把无监督学习的指标提升了 7-10%,甚至可以媲美有监督学习的效果。
![]()
如今,在 ImageNet 上的图像识别准确率的性能提升每次通常只有零点几个百分点,而来自图灵奖获得者 Geoffrey Hinton 等谷歌研究者的最新研究一次就把无监督学习的指标
提升了 7-10%,甚至可以媲美有监督学习的效果
。
细心的同学可能会注意到,许久不在社交网络上出现的深度学习先驱 Geoffrey Hinton 最近突然有了新动向。他领导的研究小组推出的 SimCLR 无监督方法瞬间吸引了人们的广泛关注:
![]()
SimCLR 是一种简单而清晰的方法,无需类标签即可让 AI 学会视觉表示,而且可以达到有监督学习的准确度。论文作者表示,经过 ImageNet 上 1% 图片标签的微调,SimCLR 即可达到 85.8%的 Top-5 精度——在只用 AlexNet 1% 的标签的情况下性能超越后者。
![]()
论文链接:https://arxiv.org/pdf/2002.05709.pdf
在这一工作中,研究者们构建了一种用于视觉表示的对比学习简单框架 SimCLR,它不仅优于此前的所有工作,也优于最新的对比自监督学习算法,而且结构更加简单:
既不需要专门的架构,也不需要特殊的存储库。
![]()
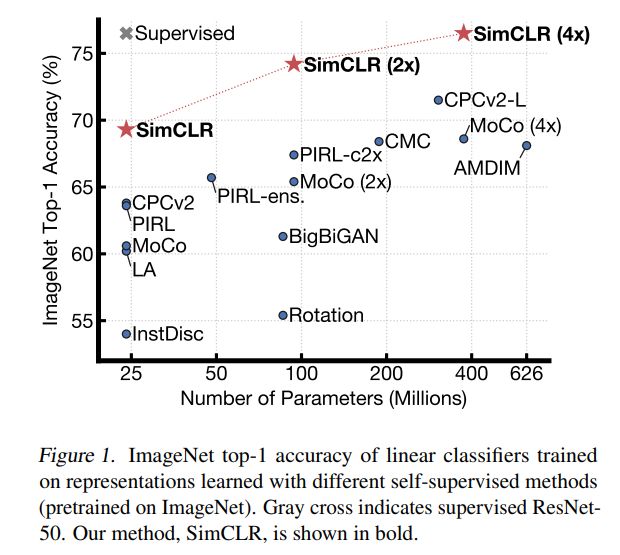
图 1. SimCLR 与此前各类自监督方法在 ImageNet 上的 Top-1 准确率对比(以 ImageNet 进行预训练),以及 ResNet-50 的有监督学习效果(灰色×)。
多个数据增强方法组合对于对比预测任务产生有效表示非常重要。此外,与有监督学习相比,数据增强对于无监督学习更加有用;
在表示和对比损失之间引入一个可学习的非线性变换可以大幅提高模型学到的表示的质量;
与监督学习相比,对比学习得益于更大的批量和更多的训练步骤。
基于这些发现,他们在 ImageNet ILSVRC-2012 数据集上实现了一种新的半监督、自监督学习 SOTA 方法——SimCLR。在线性评估方面,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的 SOTA 提升了 7%。在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。在 12 个其他自然图像分类数据集上进行微调时,SimCLR 在 10 个数据集上表现出了与强监督学习基线相当或更好的性能。
![]()
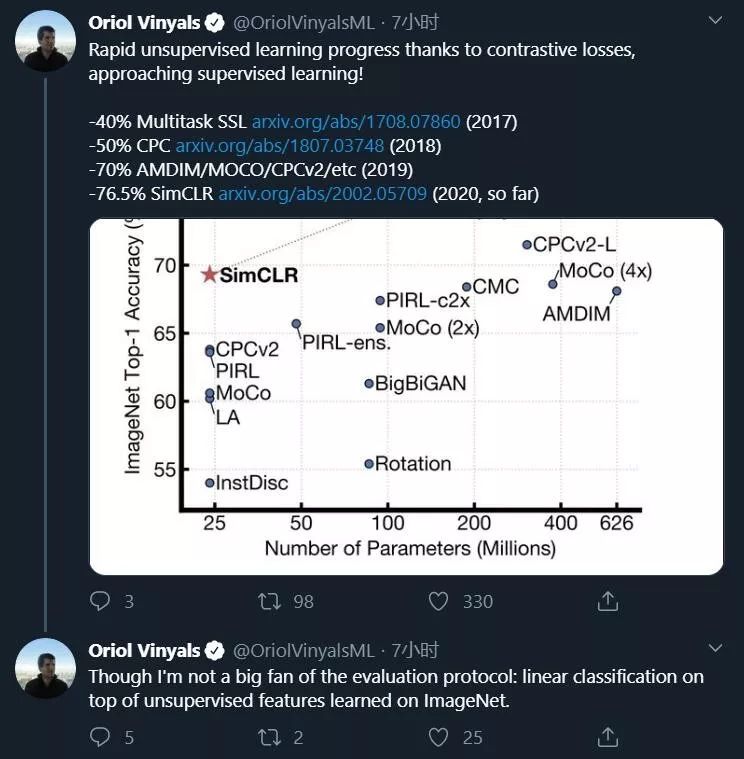
无监督学习的快速发展让科学家们看到了新的希望,DeepMind 科学家 Oriol Vinyals 表示:感谢对比损失函数,无监督学习正在逼近监督学习!
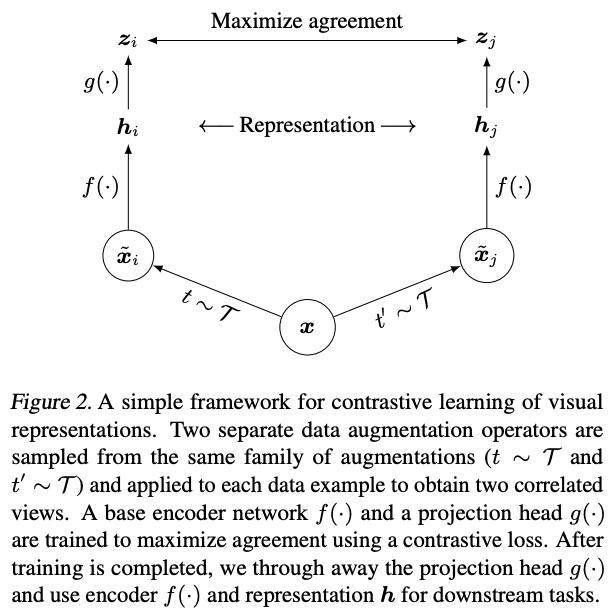
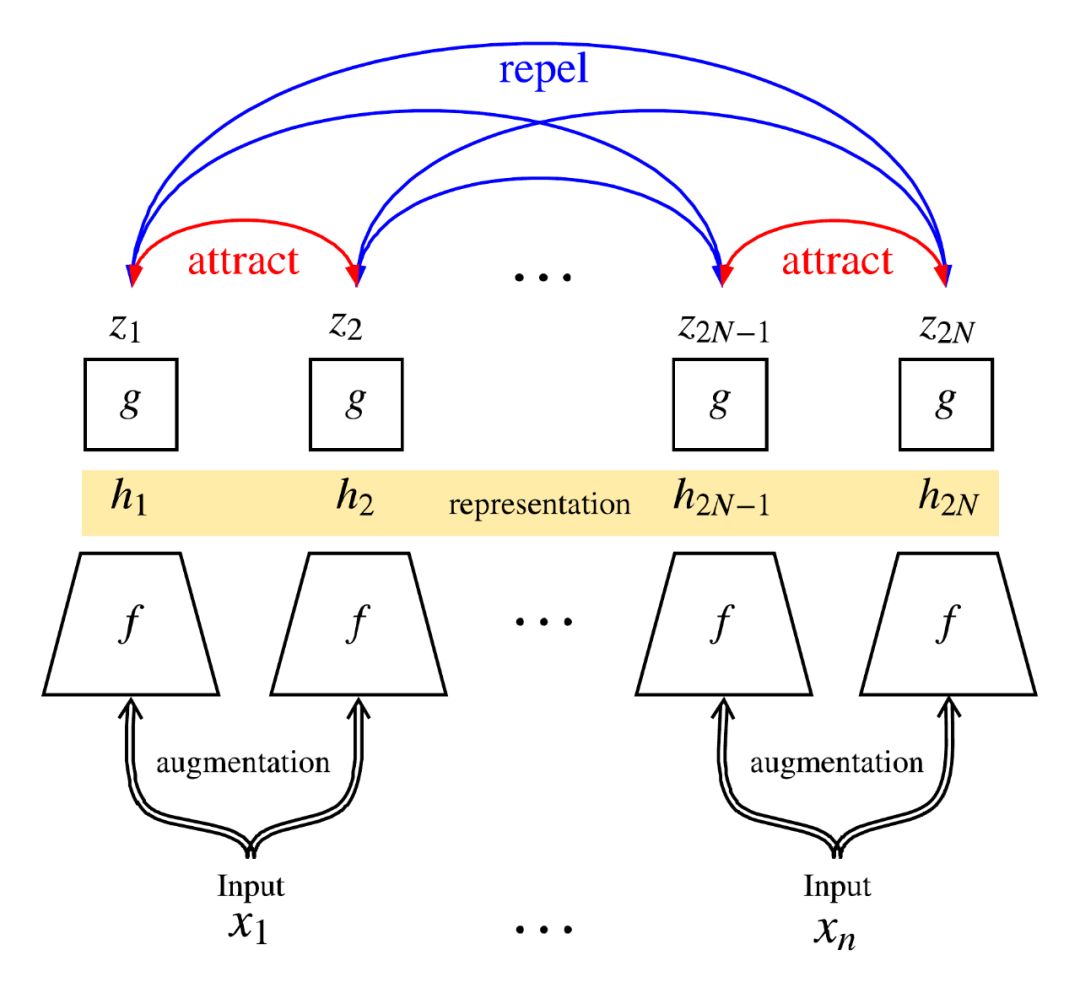
受到最近对比学习算法(contrastive learning algorithm)的启发,SimCLR 通过隐空间中的对比损失来最大化同一数据示例的不同增强视图之间的一致性,从而学习表示形式。具体说来,这一框架包含四个主要部分:
随机数据增强模块,可随机转换任何给定的数据示例,从而产生同一示例的两个相关视图,分别表示为 x˜i 和 x˜j,我们将其视为正对;
一个基本的神经网络编码器 f(·),从增强数据中提取表示向量;
一个小的神经网络投射头(projection head)g(·),将表示映射到对比损失的空间;
为对比预测任务定义的对比损失函数。
![]()
在社交网络上,该论文的作者之一,谷歌资深研究科学家 Mohammad Norouzi 对这一学习算法进行了最简单化的总结:
![]()
![]()
作者将训练批大小 N 分为 256 到 8192 不等。批大小为 8192 的情况下,增强视图中每个正对(positive pair)都有 16382 个反例。当使用标准的 SGD/动量和线性学习率扩展时,大批量的训练可能不稳定。为了使得训练更加稳定,研究者在所有的批大小中都采用了 LARS 优化器。
他们使用 Cloud TPU 来训练模型
,根据批大小的不同,使用的核心数从 32 到 128 不等。
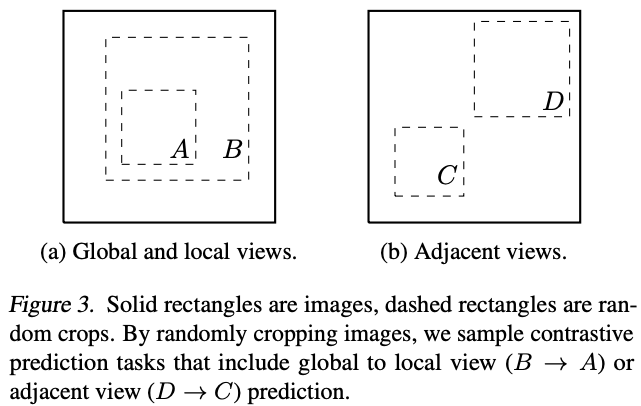
虽然数据增强已经广泛应用于监督和无监督表示学习,但它还没有被看做一种定义对比学习任务的系统性方法。许多现有的方法通过改变架构来定义对比预测任务。
本文的研究者证明,通过对目标图像执行简单的随机裁剪(调整大小),可以避免之前的复杂操作,从而创建包含上述两项任务的一系列预测任务,如图 3 所示。这种简单的设计选择方便得将预测任务与其他组件(如神经网络架构)解耦。
![]()
多种数据增强操作的组合是学习良好表示的关键。图 4 显示了作者在这项工作中探讨的数据增强。
![]()
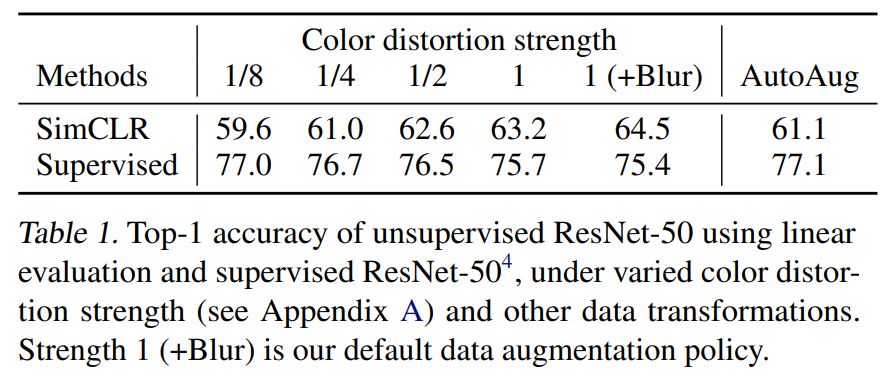
为了进一步展示颜色增强的重要性,研究者调整了颜色增强的强度,结果如下表 1 所示。
![]()
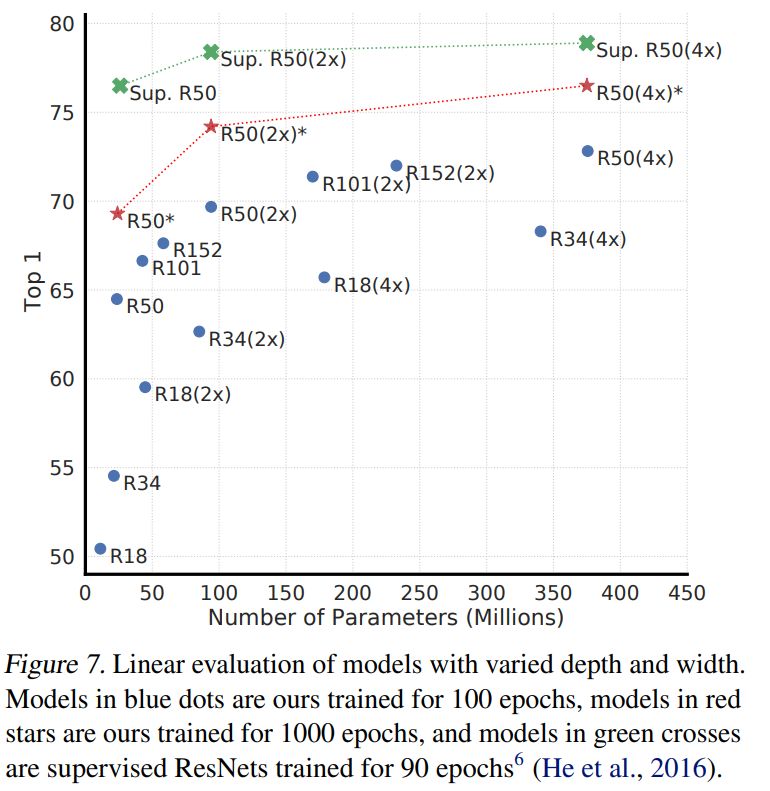
如图 7 所示,增加深度和宽度都可以提升性能。监督学习也同样适用这一规律。但我们发现,随着模型规模的增大,监督模型和在无监督模型上训练的线性分类器之间的差距会缩小。这表明,与监督模型相比,无监督学习能从更大规模的模型中得到更多收益。
![]()
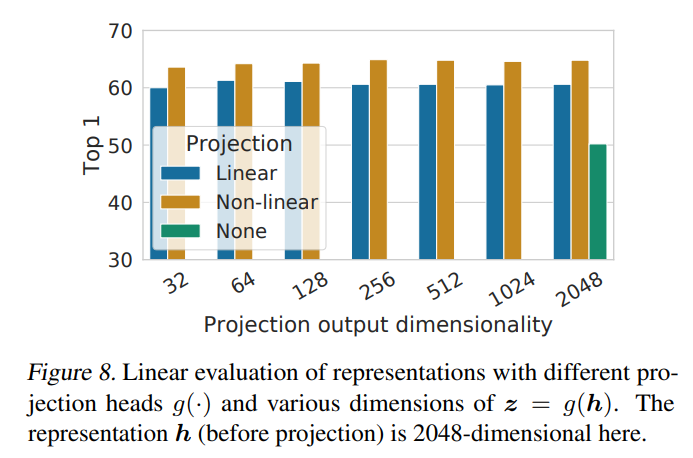
非线性的投射头可以改善之前的层的表示质量,图 8 展示了使用三种不同投射头架构的线性评估结果。
![]()
可调节温度的归一化交叉熵损失比其他方法更佳。研究者对比了 NT-Xent 损失和其他常用的对比损失函数,比如 logistic 损失、margin 损失。表 2 展示了目标函数和损失函数输入的梯度。
![]()
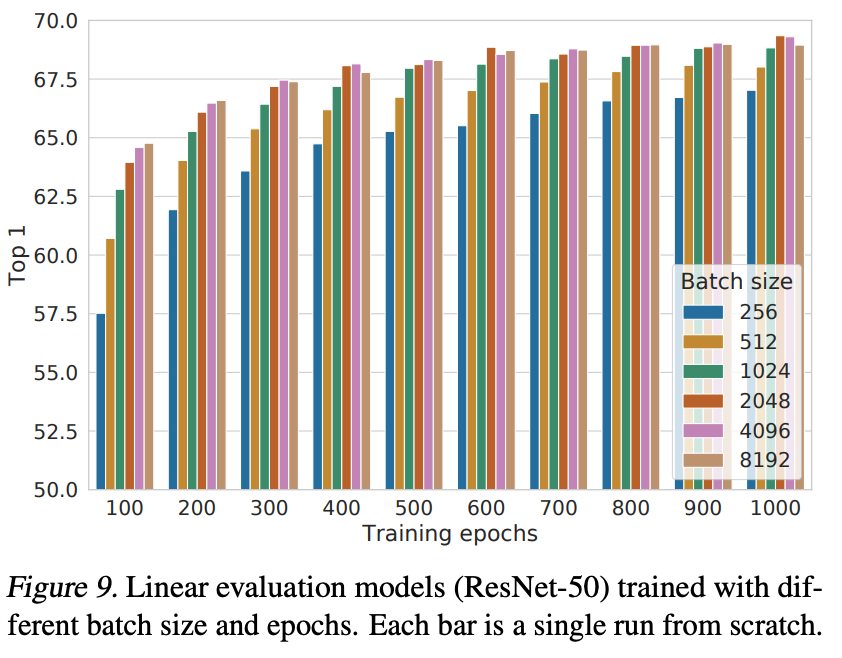
对比学习(Contrastive learning)能从更大的批大小和更长时间的训练中受益更多。图 9 展示了在模型在不同 Epoch 下训练时,不同批大小所产生的影响。
![]()
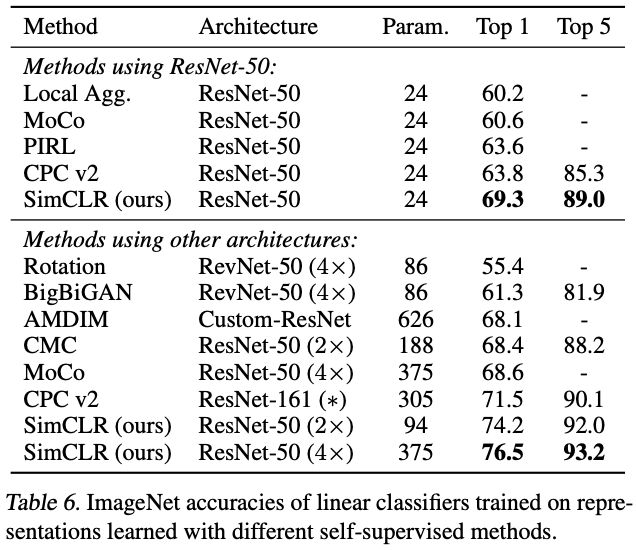
表 6 显示了 SimCLR 与之前方法在线性估计方面的对比。此外,上文中的表 1 展示了不同方法之间更多的数值比较。从表中可以看出,用 SimCLR 方法使用 ResNet-50 (4×) 架构能够得到与监督预训练 ResNet-50 相媲美的结果。
![]()
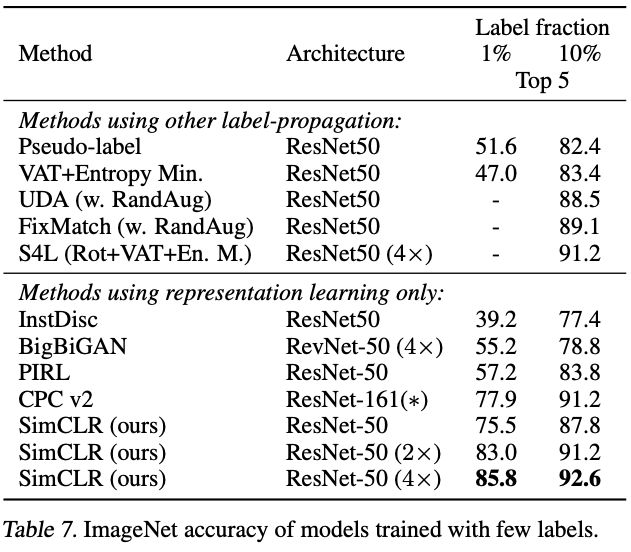
下表 7 显示了 SimCLR 与之前方法在半监督学习方面的对比。从表中可以看出,无论是使用 1% 还是 10% 的标签,本文提出的方法都显著优于之前的 SOTA 模型。
![]()
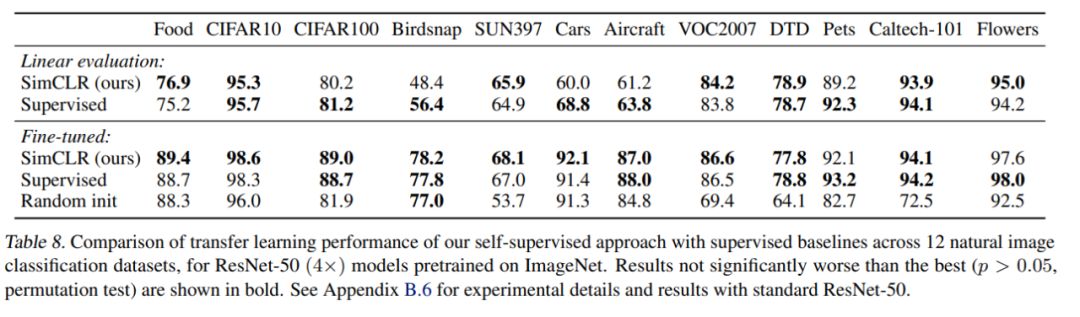
研究者在 12 个自然图像数据集上评估了模型的迁移学习性能。下表 8 显示了使用 ResNet-50 的结果,与监督学习模型 ResNet-50 相比,SimCLR 显示了良好的迁移性能——两者成绩互有胜负。
![]()
该论文的第一作者 Ting Chen 现就职于谷歌大脑,他 2013 年本科毕业于北京邮电大学,从 2013 年到 2019 年在美国东北大学和加州大学洛杉矶分校攻读计算机科学博士学位。2019 年 5 月,他正式入职谷歌大脑,成为研究科学家。此前他在谷歌有过两年的实习经历。
![]()
Ting Chen 的研究兴趣包括自监督表示学习,用于离散结构的高效深度神经网络以及生成模型。
![]()
参考链接:http://web.cs.ucla.edu/~tingchen/
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!