用机器学习玩转金融之入门秘籍二(五万字长文)
作者:江海/爱荷华州立大学的物理phd
不会金融的物理学家不是好厨子
知乎:http://t.cn/RodJhci
接触金融的这两三年发现大家都喜欢吐槽宏观报告,报告里一条条理由说的都对很有道理令人信服,但结论总是变成了random walk甚至反向指标。 学习宏观和machine learning之后发现这两个真是天生一对,这也是我为什么想要写这篇文章。
全文分为三部分,本文是连载第二章,接下来会继续连载内容。
一. 金融和统计背景介绍(戳我)
二. machine learning各个方法和在trading上的应用
2.1 Supervised Learning: Regressions
2.2 Non-Parametric Regression: K-Nearest Neighbor and LOESS
2.3 Tree Based Method ( Random Forest 和 Extreme Gradient Boosting )
2.4 Classification ( Logistic Regression 和 Support Vector Machine )
2.5 Unsupervised Learning ( Principal Component Analysis 和 期权科普 )
三. 随便结个尾
二. machine learning各个方法和在trading上的应用
这里报告里面只大概介绍了各个方法怎么运用,但是对于一般没有统计基础的读者来说还缺少了事前对于每个方法本身的介绍。我这里想做的事情就是先从统计的角度介绍每一个方法,然后再解释其在金融上面怎么应用(大部分的书都是要么单纯关于统计的推导,要么直接写金融,但我觉得其合起来一次性顺着看下来其实是最符合理解整个过程)。
每一个方法我都会大概的介绍其数学推导的机理和方向(为了尽量使得每一个方法简洁易懂,所以需要牺牲一定程度的严谨性,希望写的不准确的地方大家见谅),并且加上我自己的理解给出其相应在金融上具体是怎么应用。
还得强调一下,这里并不是说这些推导不重要所以才省去,而是极其重要以至于很难在一篇文章里面用文字说清楚,推导的细节才是这些方法的核心和精华,所以如果不想只懂皮毛的话还是需要细心去思考每一个方法的构建过程,毕竟其应用的利弊和假设条件都隐藏在芸芸的细节之中。
首先我们需要知道一些区分统计方法的概念:
一个是parametric和non-parametric,一个是supervised和unsupervised,还有一个是regression和classification,分别是代表了问题的不同的特性或者要求。
parametric和non-parametric的区别是model中有没有参数。
supervised和unsupervised的区别是有没有Y,比如我们只研究Xi之间关系的话就是属于unsupervised。regression和classification的区别是在有Y的supervised方法下面,Y是定量的(quantitative,比如涨跌幅度)还是定性的(qualitative,比如涨跌方向)。
接下来我们就开始介绍各个不同的统计方法和其应用:
2.1 Supervised Learning: Regressions
对于supervised方法,我们最重要的就是要弄清楚我们想要predict的是什么,我们有的因子又是什么;也就是分别弄清楚在实际问题里面Y是什么和X是什么。
Penalized Regression Techniques: Lasso, Ridge, and Elastic Net
对于处理线性的问题,我们可以用ridge还有lasso 好处是非常易于理解背后的关系,坏处就是对于non-linear的问题fitting效果不好,弱点还有变量Xi数目比较多,或者变量之间有correlation的时候也会效果不好。但是这个是所有regression方法的基础,所以必须掌握。
一般的形式如下:
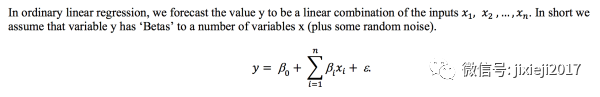
Xi是变量,𝛃是相应变量的系数,𝝴是随机的一个不可消除的误差,Y是我们想要预测的目标。
比如一个具体的形式是:
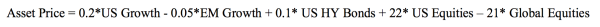
这里的US growth,EM growth,US HY Bonds,US Equities,Global Equities是五个变量Xi,想要预测的Y就是Asset Price。
这里我们可以看到US Equities和Global Equities前面的系数相对其他变量大很多,这就说明了这两个变量对于这个Asset Price的影响最大,当然US Equities是正面的影响,Global Equities是负面的影响。
这里我们就可以发现一个问题,那就是比如像EM growth这个变量前面的系数非常小,说明这个因子对于Asset Price的贡献不大,所以如果依然把这个因子加入model的会就会导致过拟合,因为本来这个因子是不应该在model里面结果我们却放进去了,自然就导致变量更多,model更复杂增加了其对于data的dependence,也就是variance。
当变量比较少的时候我们自然可以手动把这些不需要的因子剔除掉,但是如果变量有成百上千甚至上万的话,人工来选择因子就会非常繁琐,而且还容易造成错误。有没有一种方法可以自动帮我们做这件事情呢?有,就是接下来我们说到的Lasso方法。

Lasso做的事情就是加入一个penalty因子,使得自动将相关性不强的因子自动筛选掉,也就是使得其前面的系数变为0。
然后还有一个方法,就是ridge。唯一不同的地方就在于ridge的penalty函数是系数的平方之和,而不是Lasso里面系数绝对值之和。 其实他们做的事情都比较类似,都是为了减小不相关因子的系数大小。
但是这里有一个问题,那就是如果有一个因子确实是一个非常强的因子,并且前面系数非常大。如果用Lasso和Ridge的话就会使得其前面的系数减小,那这样的话不是underestimate这个因子的重要性了么?毕竟系数越大的,在这个penalty下面会减小的越多。
对于这个很大系数的主要因子的问题,理论上可以证明出Lasso和Ridge并不会首先将系数大的主要因子系数变为最小,而是首先将不那么重要的因子的系数变小。
可以从主观的感觉上面来理解,如果将主要因子的系数降低的话,会造成公式前面那个RSS这一项的值变得很大,这样即使后面penalty会减小,但整体的和不一定会降低,反而可能会升高(毕竟penalty只是一个调节的项,RSS才是想要降低的主体)。但是如果降低的是不那么重要的因子的系数,就会使得前面RSS的值增加不多,但是后面的penalty会降低不少,特别是penalty前面系数a足够大的情况下。
所以综合而言,Lasso的作用是把不重要的因子剔除出去(也就是使得其前面的系数变为0)。 Lasso相对于Ridge的优势也正在于可以将主要因子的系数直接降为0,这样也就是一个选因子的model。
关于Lasso和Ridge之间的对比,至于为什么Lasso可以将不重要的因子的系数降为0而Ridge不行,我们可以看下面这个图更加直观:
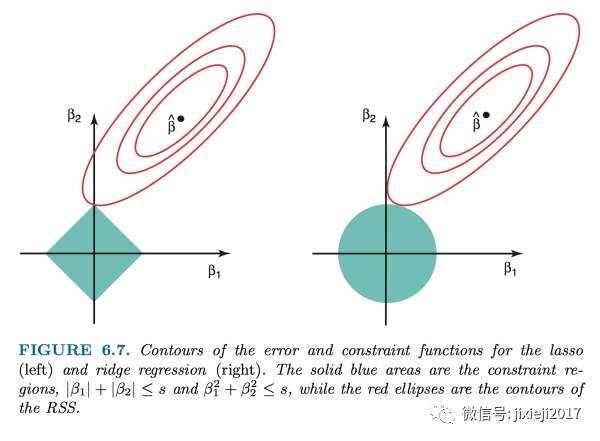
假设我们只有两个因子X1和X2,他们分别的系数是𝛃1和𝛃2。然后上面那个椭圆就是前面那个loss function RSS画在𝛃1和𝛃2的平面上,每一个椭圆代表的是不同的RSS的值,并且椭圆越小的时候RSS越小,也就是我们想要其越小越好。对于Lasso和Ridge,因为前面那一项RSS都是用同一套数据经过同样的least square方法计算出来,所以椭圆的形状对于Lasso和Ridge都是一样的。不一样的仅仅是第二项,也就是阴影的面积。
一方面我们想要这个椭圆越小越好,最好的情况就是直接缩小成中间的点𝛃 hat。
另一方面,我们又想要阴影部分的面积最小,因为我们所加的penalty一定程度上就代表了阴影的面积。
所以两个方面的平衡下,我们就需要找到这个椭圆和阴影面积的切点,这样可以使得椭圆足够小,这个阴影的面积也足够小。 现在我们知道了切点是我们需要找的点,这个点的坐标是(𝛃1, 𝛃2)。
我们可以看到Lasso的情况是正方形的阴影面积和椭圆相切,由于正方形是有四个突出的顶点,所以这四个顶点更容易和椭圆相切。而这四个顶点的坐标都在X或者Y的坐标轴上,也就是要么𝛃1被留下,要么𝛃2被留下,其实这就是为什么可以将被去掉的因子的系数变为0(因为切点在坐标轴上)。
而Ridge的情况是,由于阴影面积是一个圆,所以并没有突出的顶点可以更容易跟椭圆相切,故想要正好相切在坐标轴上是非常困难的,需要RSS的形状满足非常极端的条件才行。
所以如果想要选择因子的时候,我们可以利用Lasso的方法来获得足够重要的因子。
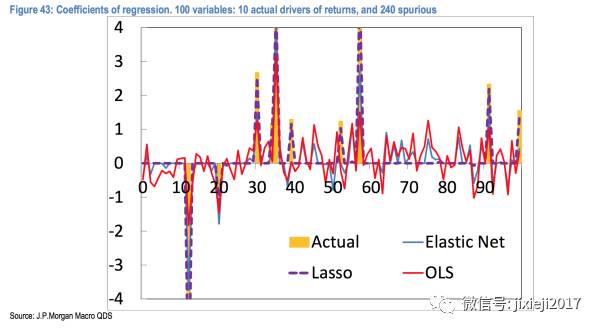
从上面这张图我们可以看到Lasso基本上把真实Actual的主要因子都抓住了,并且给予的系数(权重)基本上和真实值一致。而OLS,也就是最基本的least square的方法(仅仅只有Lasso的第一项)会分配权重给全部的因子,这样就造成了overfiting。也可以看到Lasso里面加上的penalty这一项对于筛选重要的因子的还是很有效的。
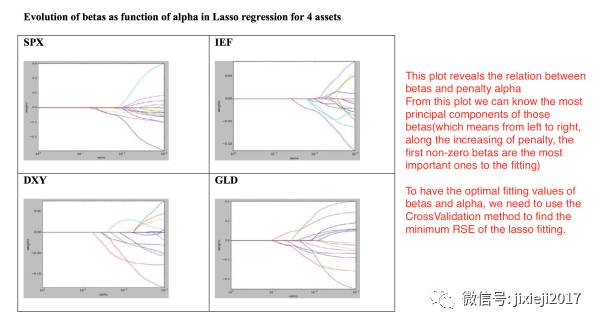
下面是penalty因子系数𝞪的大小(X轴)和得到的每个因子的系数大小(Y轴):
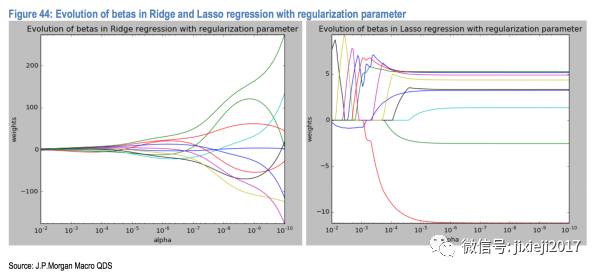
我们可以看到𝞪的值从小到大(X轴从右往左看)的时候,右边的Lasso model会让不同的因子在不同的时期消失。也就是随着𝞪的值增大(也就是penalty的程度越来越大),不断有因子的系数被Lasso归0,也就是剩下的因子的重要性越来越大。最后剩下几个影响非常大的因子。
而左边Ridge的只能让这些因子的系数一起变小,最左边𝞪值也就是penalty非常大的时候,几乎所有的因子系数都变成非常小,这样显然不是我们想要的结果。
Bayesian和ridge还有lasso的关系:
ridge还有lasso都可以由贝叶斯推导出来,只是需要改变贝叶斯里面prior的distribution的形式,ridge需要在贝叶斯里面把prior改变成laplacian,lasso需要把prior改变成gaussian。
理论上来说,这两种prior distribution的贝叶斯得出的结果应该是和ridge和lasso的结果一致。
这里用贝叶斯导出的原因是贝叶斯不需要复杂的计算公式,仅仅需要的到P(u|data)之后做simulation,可以直接从generate出来的sample里面得到系数beta的均值和方差,而不需要像frequentist那样用公式来求。(具体公式的推导在附图中)

并且贝叶斯的方法当data足够大的时候,prior的distribution其实重要性会越来越小(我自己也胡乱写了传统统计方法frequentist和下面Bayesian的证明)。不过data的size什么才叫做足够大,这是一个问题。

接下来我们介绍一个利用Lasso的例子:

这里我们想要预测的Y有4个,S&P 500,10-year UST,US dollar(DXY),还有黄金gold。 并且我们选取了4个Xi,就是他们各自过去1M,3M,6M还有12M的收益。 这样我们对每一个Y都有4个Xi作为变量。我们想要预测的Y是此种asset第二天的收益。如果是大于0就做多,小于0就做空。
比如我们现在单独看S&P500。
我们利用的dataset是滚动的500个交易日,也就是对于S&P500有500个data值,每个data的值是一个5维空间内的一个点(Y, X1, X2, X3, X4),也就是(S&P500第二天的收益,S&P500当天之前1个月的总收益,过去3个月的总收益,过去6个月的总收益还有过去12个月的总收益)。我们想要做的就是利用一个Lasso模型去fit得到这500个点,使得其对于这500个点fitting的最好,也就是RSS+penalty的和最小。
这样我们就在5维空间内找到了一条线,根据坐标(X1, X2, X3, X4)还有其系数我们就可以预测出Y,也就是在当天(接近)收盘的时候,算出来S&P500当天之前1个月的总收益,过去3个月的总收益,过去6个月的总收益还有过去12个月的总收益,也就是在5维空间里面加入今天这个点,并且因为是rolling window,所以将最初始的第一个点(今天之前的第499天)去掉,得到空间中新的500个点,重新获得一个新的Lasso model,并且根据这个update之后的model去预测第二天的收益。
具体应用中似乎是3个月重新renewal一次model。也就是并不是每天都会加入一个点再去除最旧的一个点,而是在三个月之内用同一套model结合这三个月每天的(X1, X2, X3, X4)去预测第二天的收益。等到了三个月之后,就一次性加入这三个月所有的点,去除掉最旧的相同数目的点,重新进行建模得到一个新的Lasso model,然后再用这个model结合接下来三个月每天的(X1, X2, X3, X4)来预测第二天的收益,一直rolling下去。
这里需要注意的是(Y, X1, X2, X3, X4)都需要standardize(具体怎么standardize需要弄清楚, 后面很多方法都会预先将Xi standardize),因为我们知道跨度不一样其值也会有不同的scale。
但这里是仅仅用了(X1, X2, X3, X4)作为变量,但实际上我们有4个不同的asset Y,S&P 500,10-year UST,US dollar(DXY),还有黄金gold, 所以可以将这4个Y的(X1, X2, X3, X4)都设置成共用的16个变量(X1, X2, X3, X4,…X16)。然后用这同一套Xi对这四种asset进行regression,每一种asset就都有一个Lasso model进行预测。结果譬如下图:
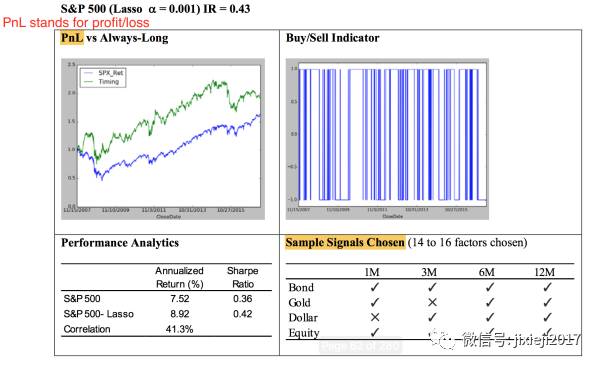
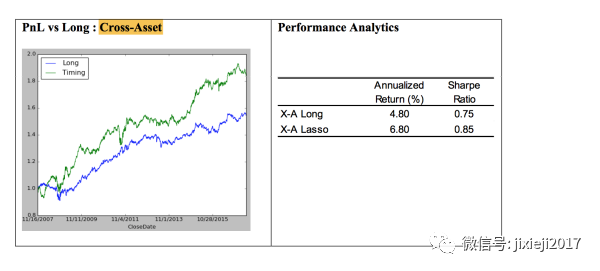
我们可以看到预测S&P500的lasso model用到了14个factors。并且单纯做多的收益和sharp ratio都比直接买S&P500高。
同样我们可以看到其他asset的结果。
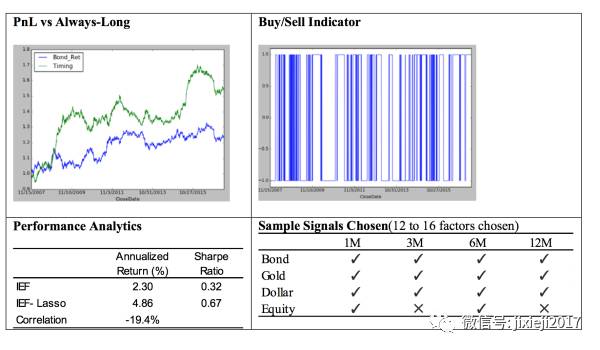
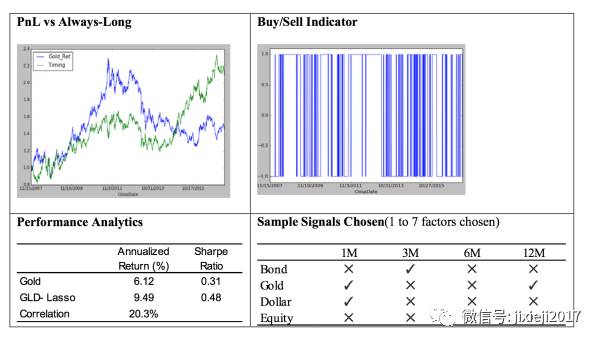
然后同样就像上面解释lasso model时候看到的,我们可以调整其penalty的系数𝞪的值来看对于每个asset,其不同factor系数的变化情况,可以很清楚看到哪些factor是最重要的。
因为这里我们有4个不同的asset,所以可以将其第二天的预测表现进行排序。前两个做多,后两个做空,也就是所谓的多空策略。
好了,这就是linear里面的regression,也是最经典传统的统计方法。
2.2 Non-Parametric Regression: K-Nearest Neighbor and LOESS
对于处理非线性的问题,一个是可以用高阶的linear regression,另一个就是用非参方法KNN之类
非参方法好处就是如果fundamental的model是非线性,效果会比较好。坏处就是如果model本身是线性的,就容易造成overfit,并且KNN对于outlier的点非常敏感。
这里我们用KNN的方法来择时。(也就是选择历史上类似宏观情况的regime,然后平均一下收益率作为预测值)

具体是这么工作的:
我们有7个类别的indicator,然后用这样一个7-d的vector来表示宏观经济的位置regime(或者说是在7-d空间内的一个点)。
具体怎么构建的这7个indicator可以参照如下slides:
https://www.cmegroup.com/education/files/jpm-systematic-strategies-2013-12-11-1277971.pdf
所以这7个indicator就是我们的7个Xi,构成了一个7维空间,并且由于每个月都有这7个indicator的值,所以都可以用这个空间里的一个点表示。
我们想要预测的Y就是20个risk premia的每一个。
或者可以这么说,每一个月作为一个观察。然后每一个观察包含了这7个Xi和Y(20个risk premia的每一个)的值。并且我们用Xi的7维空间来区分regime。仅仅是画点上去,而不是像之前的regression一样想要用一条线去fit,这里获取Y的方法是将想要预测点周围的K个点对应的Y取平均值。
我们将过去的10年每个月都可以画在这7-d indicator的空间中,每一个月都可以被这个空间内的一个点所代表其宏观情况。这样当下这个月也可以画在同样一个空间里,找到其最近的K个点。
当然K也可以用其他的值,这样就是average一下附近的K个点的每一个risk premia的return,这样我们可以得到这个点周围附近K个点(也就是历史上类似宏观情况的K个月)这20个risk premia每一个的平均值,(这个地方距离是standardize之后的距离还是直接用原indicator的scale呢?),这样就找到了历史上最接近现在这个月宏观经济情况的K个月的20个risk premia每一个的平均值。
根据那个月之后的一个月的20个risk premia(此时S=20的情况下)的表现情况(如果20个risk premia是daily的数据,那么就用average来得到一个月每天的平均值,其实也可以直接加起来看每个月的总收益?),并且将其排序,选择其中一部分然后平均分配资金,来决定当下这个月的下个月投在这20个risk premia上的funding distribution。
这里有一个问题就是,因为不能单纯看20个risk premia的收益大小来选取(不然就全部投给预期收益最高那个risk premia了)。我猜测可能还需要看组合起来看总体的sharp ratio值。所以这样排列下来仅仅只能找到最高收益的那个risk premia,而不是找到最好的sharp ratio。所以需要看这些20个risk premia的subset的组合情况,得到最好的sharp ratio。
但是问题在于,怎么将这些S个risk premia策略组合在一起得到最好的sharp ratio?这个可能就需要看回测的结果了。(但是怎么回测这20个risk premia所有subset的可能性?)
是不是还涉及到给weight的问题呢?
这里似乎就是直接给予这些不同的risk premia策略相同的weights,也就是将funding直接均分给不同的策略。但是其实可以用machine leanring来给不同的策略分配不同的weights来改进。
这些细节的问题我也没有一个确定的答案,可能需要问JPM具体做这个策略的人了...
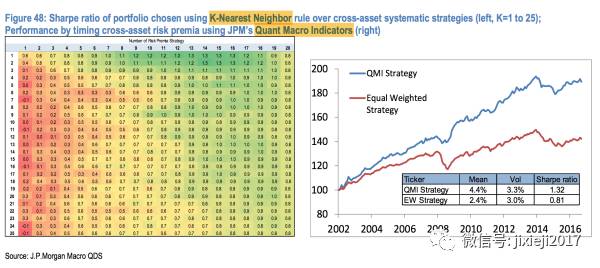
这就是具体的结果。
左边的图的列向量是选择K从0到25,横向量是选择risk premia的个数。方框中的数值就是sharp ratio。从这张图看来,确实是需要对所有的组合进行回测。但这里每一行似乎仅仅区分了risk premia的个数,而不是每一个单独不一样的risk premia? (想要弄清楚,可能需要看看JPM的risk premia是怎么构建的了,应该都是independent,所以并不能单纯以个数来作为loop的条件?)
这里的右图就是单纯给这S个risk premia(S=20所有都用?)平均分配资金,也就是红线。然后就是利用这7个indicator预测的各个risk premia进行排列组合,选出sharp ratio最高的再平均分配资金。
2.3 Tree Based Methods:
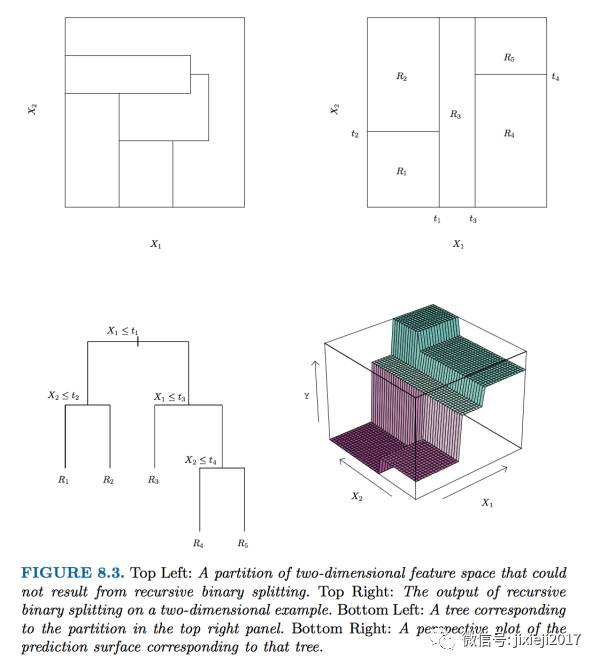
首先介绍tree based method的基础,也就是regression tree。
给定很多变量Xi,它的原理就是取遍所有Xi和每一个Xi所有的值,找到一个让全局的RSS(Residual Sum of Squares是一个指标,用来描述预测的Y和实际的Y之间的差距的平方和,也就是预测的效果好坏)最小的某一个Xi的某一个值,这里就算是一个internal node。
这样,Xi的这个值将所有的点分成了两个区域,每一个区域的点所estimate的值就是这整个区域所有点的平均值。 再同样的过程,得到一个让这一步全局RSS最小的Xi的一个值(这里Xi可以跟上一步的Xi是同一个变量)。
同样的过程不断进行下去,一直到某一个条件停止。比如RSS到达某一个值,或者某一个区域的点小于5之后,等等。
记住,这里的RSS是全局的RSS,也就是所有区域的RSS总和,而不仅仅是所分开区域的RSS之和。
同理,这里需要一个penalty函数。因为树越深其实越overfit(可以想象当树深到极致就是每个区内只有一个点),所以给目标函数RSS加上一个additional的alpha*树的深度,使得其总和达到最小。
合适alpha值的选取就需要通过cross-validaiton来得到,同时可以得到的也有tree的深度。这样一个model就选出来了。
regression tree应用的示意图如下:
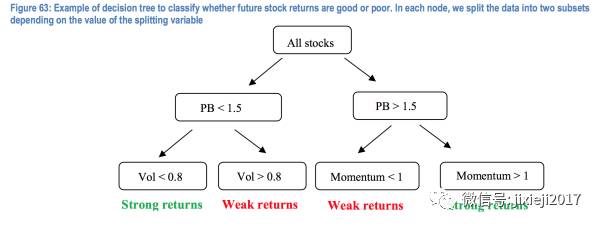
regression tree的好处就是非常容易理解,因为每一个node的Xi取值都一目了然。但是不好的地方就是它对于outliers非常敏感,因为outliers会极大的增加RSS这个指标,所以很容易被影响。
Random Forest:
random forest的意思就是,在上面的regression tree的基础上,我们再利用bootstrap来产生数量为B的test datasets(也就是bagging的model)。对于每一个dataset我们可以利用一个regression tree去fit。所以对于每一个观察,我们都可以得到B个prediction的值。接着我们就把这些值average一下,就得到了我们最终的estimate。这样的好处就是可以降低variance,因为我们用了很多的sample一起求出的平均值,而不是像decision/regression/classification tree那样一次性的estimate。
然后random forest又加了另外一项,也就是限制每一个node可以选取的Xi的数目。比如一共有p个Xi,但是我们可以规定每个node只能randomly选取sqrt(p)的Xi。这样的好处就是为了防止一个factor dominates,不然就会导致这B个tree的correlation非常大,即使求平均值也起不到降低variance的作用。
具体我们可以看如下的例子:

这里要做的事情就是利用random forest的model来选股。我们的股票池里面有1400个股票,然后每个股票我们都有相同的14个factor,也就是有14个Xi(注意这里的factor需要先normalize一下,也就是standardized to mean 0 and variance 1,因为各个factor的scale不一样会导致fitting有bias),这里的Y就是收益率。
我们利用random forest的model来预测。
首先我们利用bootstrap构造100个test datasets,然后针对每一个dataset去fit一个regression tree。并且每一个tree的每个node处,一般每次只能randomly选择sqrt(14)=3 factors。但是这里我们用OOB这个方式来判断每个node处可以选择Xi的个数(得到的是14个全部可以用),并且每个tree的深度也是由OOB这个最小值来确定。
接着我们对于每一个股票都有100个prediction的值,然后average,得到我们最终的estimate。
这里的一个问题也是同样,我们是不是需要将股票的收益向右位移一个单位,使得这14个risk factors Xi所对应的Y是下一个月的收益。毕竟如果放在同一个月,那就不存在预测的问题了,因为都是同时发生,而不是用一个去预测接下来即将发生的另一个。
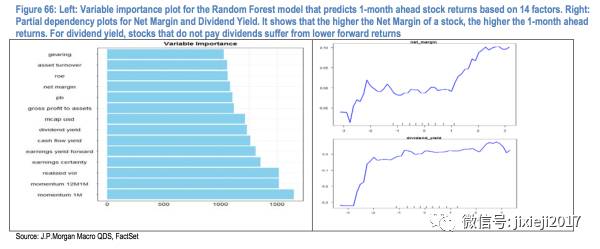
然后利用每个node对于Xi的选择,我们可以得到上图,可以看出来哪个factor影响最显著。
另一张图就是策略的回测结果,通过对于这1400个股票的预测值进行排序,我们就可以得到每一个quantile(一共分为5个quantiles)的股票basket。
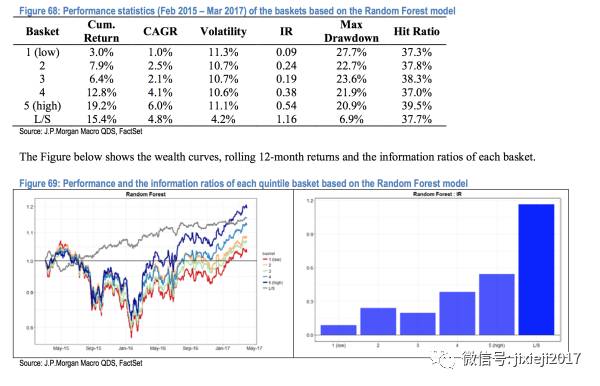
图上表示的就是单纯对于每一个quantile的basket做多(5条曲线),还有long/short的策略(也就是做多第5个最高的quantile basket,同时做空最低的那个quantile basket),其所得到的收益率是最稳定的。
因为我们可以看到benchmark的曲线在1和5之间,所以做多5,做空1的话就会使得曲线更加平滑。不然会跟大盘的相关性非常大,这也就是一种把大盘波动hedge掉仅仅只剩下1 quantile和5 quantile之间的差值的收益。
Extreme Gradient Boosting:
boosting的原理就是慢慢学习,也就是先给一个不太准确的estimate,然后用真实值减去这个estimate得到residual/error,接着用regression tree去fit这个剩余的residual error得到这个residual的estimate,再用上一层residual减去这个estimate得到下一层的residual,然后进行K次(即一共用K个tree去fit K层的residual),实质上是从一层一层的residual里面不断缓慢提取信息不断加到之前的estimate上面,使得最终得到一个总的好fitting。
boosting指的是一类方法,而不是一个方法。Extreme Gradient boosting是boosting中一个的方法。

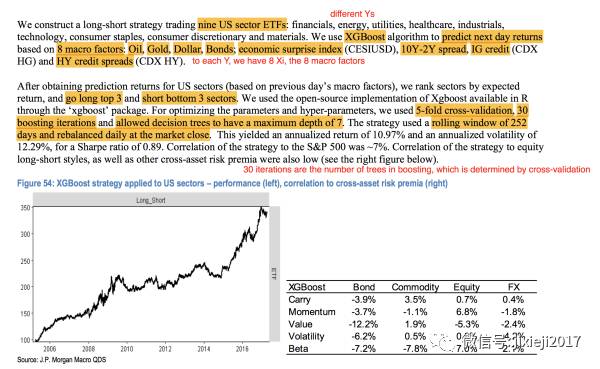
这里做的事情是利用XGBoost来预测9个US sector ETFs的表现,financials, energy, utilities, healthcare, industrials,technology, consumer staples, consumer discretionary and materials,对应于Y1,Y2...Y9。
首先我们有8个Xi,也就是8个宏观的factor,
Oil, Gold, Dollar, Bonds; economic surprise index (CESIUSD), 10Y-2Y spread, IG credit (CDXHG) and HY credit spreads (CDX HY)
然后我们要做的事情就是,用这8个Xi,还有extreme gradient boosting的model去预测每一个Yi的表现。
这里extreme gradient boosting model里面的参数是,5-fold-cross-validation来确定tree的数目为30,也就是经过30次的从residual里面extracting information。并且每个regression tree的深度为7,也就是每个tree被分为了7+1=8个区域。
有了这个extreme gradient boosting model不断的iterate(30遍,每一遍的tree的深度是7)来不断extract信息给想要估计的那个estimate函数f^hat之后,f^hat确定了下来。在同样给定了这个想要预测的observation的8个Xi的值(也就是这个8维空间内的一个点)之后,就可以经过这个model得到我们想要的预测值Yi。
这里应该是用的每天的涨跌幅(里面有说rebalance daily at market close)。因为对于同一个Yi来说,比如我们预测energy这个sector ETF的涨跌幅。我们每一天都有这8个macro的factor的一个值,这样一天在这个8维空间上来说就是一个点,252天的话就是有252个点。
这样才能开始利用boosting tree来划分区域进行预测。甚至都不一定是daily的数据,可以是更小级别的数据,这样点(信息)也就更多了,model的预测也更加贴近真实的model。然后利用这252个点来建立model,建立之后预测energy ETF的涨跌幅。
有一个问题就是,同样我们这里可能需要将energy ETF的向右位移一个单位,也就是将第二天的energy ETF作为这一天的Yi,这样8个Xi预测出来的结果也是第二天的energy ETF的涨跌幅。(但这里还有一个问题就是为什么是位移一个单位,也许这些macro factor传导给ETF是有不同时滞的,所以每个Xi甚至都需要不同的位移?)
然后根据long-short策略,每天我们可以预测出这9个ETF的涨跌幅度,将其排序,做多前三个,做空后三个,形成了一个策略。
除此之外,我感觉还可以用另一种方法。那就不用位移,直接将当天的ETF涨跌幅看做是Yi。这里的一个assumption就是市场是有效的,macro factor的变化可以马上传导给ETF的价格。这样的话我们就可以通过预测的值,看如果当天实际并没有达到这个涨跌幅(在快收盘的时候检查condition),我们可以进去统计套利,也就是赌其一定会往那个涨跌幅移动。
也可以将其量化变成相差多少个sigma(假设围绕预测值是一个normal distribution,其mean就是预测的值,width可以取历史上面的error是不是都一样,如果是近似flat可以直接用这个constant作为error,如果不是的话可以继续分析其error的结构),大于两个sigma的时候进去开仓bet会继续往预测的方向走,不一定是同方向,如果涨跌幅走过了2个sigma那就是bet其一定会reversion。
2.4 Classification
接下来我们要介绍的就是Classification了。
classification跟regression的区别就是Y的类型不同,regression是Y的具体数值的预测,比如涨跌幅度,而classification是对于单纯分类的预测,比如Y的涨(Y值取1)或者跌(Y值取0)。
但是classification里面有一个地方不好处理,那就是如果想要预测的Y不仅仅只有两个分类怎么办,比如当Y有三个值甚至更多。因为如果大于两个值的话就不能简单将Y设置为0,1,2,但是Y的这三个分类值在实际的意义上不一定是等距的,如果我们将其设置成0,1,2的话是默认这三个分类之间的距离相等,但在实际过程中Y不同分类结果之间的距离很难用数字去衡量。
为了简化,此处只考虑Y有两类: 是(Y=1)或否(Y=0)的情况。
logistic regression
而classification里面最出名的一个方法就是logistic regression。这里不要被regression的名字所误导,之所以取的是regression的名字是因为用的是类似regression的方法,但是由于这里Y是离散的(不是具体连续的数值,而是比如说二选一,涨或者跌),所以对于Y的处理上有一些变化。
下面就是logistic regression的公式推导:

是不是看一圈之后懵逼了~ 这里用的是maximum likelihood function的推导,因为涉及到了矩阵运算,所以这里为了让读者更轻松一点暂时省去~
我来用另一种不是那么准确但是更容易接受的方法解释一下,举个例子就明白了。 先上一张图:
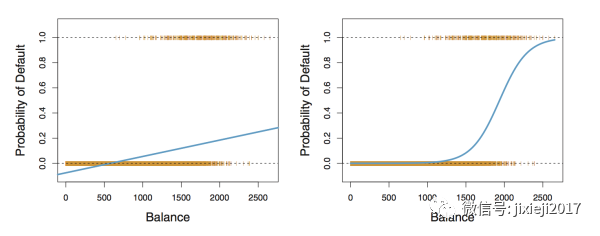
我们现在呢,手上有信用卡的数据,知道每一个人有没有违约还有他们信用卡欠款的数目,想要研究的问题呢就是违约概率(Y)和信用卡欠款数目(X)之间的关系。因为这里一个人是不是违约只有是或者否两种结果,不可能存在第三种情况,所以正好适合我们这里分类classification的问题。
左边的图呢,那一条蓝线就是直接用linear regression来fit Y和X的结果。公式如下:
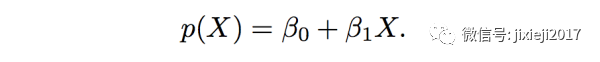
也就是基于一个人的信用卡欠款X,我们想要预测的这个人违约的概率p(X)。这里由于是用的regression,所以p(X)是一个连续的数值。
我们从上图中可以看到明显这个model对于实际非常不符合。
一个是可以看到预测非常不准,即使我们将纵轴probability of Default>0.5看做是,probability of Default<0.5看做否,这个fitting的结果在balance的整个横轴跨度内基本上都是属于否这一类。但实际上从图中我们可以看到当balance这个横轴数值在2000左右的时候,其纵轴probability of Default大部分其实是1,也就是会违约。
另一个问题就是由于linear model是一条线,所以这条线对于横轴balance上的某些点,会使得纵轴probability of Default甚至有小于0和大于1的情况。我们这里讨论的是概率,只会属于0和1之间,所以小于0和大于1的预测在这里明显是不对的。
所以为了解决这两个问题,我们可以想办法把左边图的那条linear曲线做一定的变换mapping到另一种形式,使得其只属于0到1这个区间。
我们需要经过两个步骤:
首先呢,我们要想办法把linear function的𝛃0+𝛃1·X的值(负无穷到正无穷),变成全部是正数,也就是从0到正无穷。有些读者肯定想到了,那就是利用指数函数exponential function。
将其变为e^(𝛃0+𝛃1·X),这样所有的结果都会是0到正无穷。
但是这样还不够,因为我们想要的是将其压缩在0到1之间。所以我们可以同时对上面linear model的右边p(X)进行如下操作:
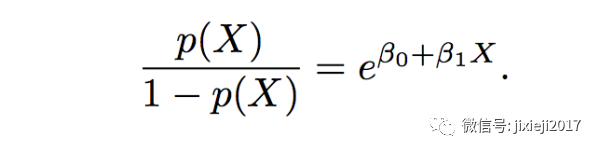
这样就保证了p(X)只会属于0到1这个区间。如果对于这个推导过程不熟悉的,可以自行任意带入负无穷到正无穷间的值取代上述方程中𝛃0+𝛃1·X的位置,检查概率p(X)是否都是落在0到1这个区间。如果发现不是,那么恭喜你,你颠覆了数学,我请你吃饭,管饱~
至于为什么叫logistic regression,看下面这个式子就明白了(完全等同于上一个式子):
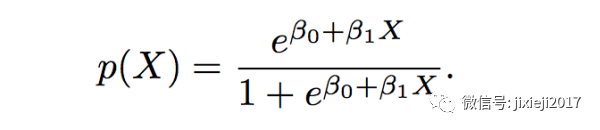
然后我们可以看到数学中标准的logistic function的形式是这样:
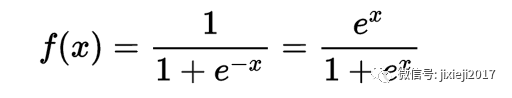
它的图形是长这样:
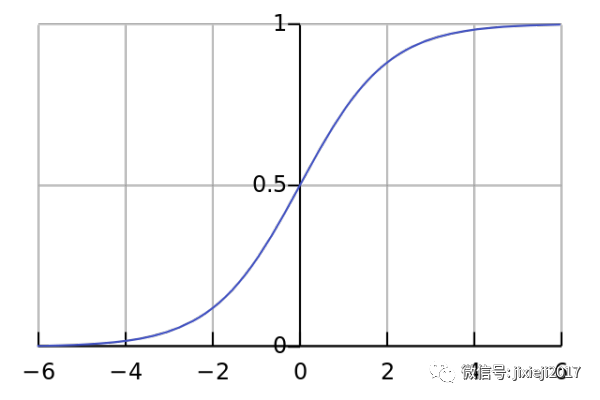
是不是发现正好符合我们想要的需求呢,随着横坐标X的变化,Y永远都被限制在0和1之间。
并且我们把标准的logistic function中的x换成我们的linear function里面的𝛃0+𝛃1·X之后,就完全是我们推导出来的结果。一颗赛艇! 所以这里这个方法是把linear function的内容𝛃0+𝛃1·X嵌入到了标准logistic function里面,自然这个方法就叫logistic regression了。
经过上面的介绍和推导,我们用logistic regression的时候呢也只会关注这个最终形式:
我们输入进去的数据是因子X和相应的Y(也就是是1或者否0),fitting的结果得到的是𝛃0和𝛃1。这样利用这个model,如果有任何的X,我们就可以预测出p(X)的值。如果当概率p(X)>0.5的时候我们就说Y属于”是",当概率p(X)<0.5的时候我们就说Y属于”否”。
至于怎么得到最合适的𝛃0和𝛃1,其实就是上面那个看得懵逼的maximum likelihood的推导图。如果大家还有印象的话,前面linear regression确定参数时候用的是least square approach得到linear model的各个系数𝛃0,𝛃1,𝛃2…,其本质上是maximum likelihood的一种特殊情况。区别就是least square approach比较好理解和表示,而变成non-linear model的情况需要变换成较为抽象的矩阵运算,也就是maximum likelihood的推导。
接下来我们看一个金融中实际应用的例子:
这里JP Morgan用到的是期权(后面我会详细介绍期权是一个什么东西和volatility surface,如果想先弄清楚可以先跳到最后的科普期权部分),内容是对于某个股票一直sell 1M ATM(At The Money)的call,并且不断rolling到下一个月。
因为是sell option,所以可以一直收取premium拿到期。至于为什么是ATM的call,因为在at-the-money的时候,时间价值是最juicy的,也就是自己overwrite的时候可以收的premium会最大。如下图我们可以看到100% at-the-money的时候是最大化收益的。
除之此外,我们还可以看到一个有意思的现象,整体来说102%的收益比98%的低,105%的比95%的低,原因是volatility surface其中一个维度的volatility skew现象导致在相同程度的moneyness情况下,ITM会比OTM的implied volatility更大。
还有一个现象就是102%的比98%波动更大,105%的比95%波动更大,原因是ITM的已经包含了intrinsic value增加了缓冲区,但trade-off就是虽然ITM的会风险更小但是upside potential也会受到限制(我们可以看到102%和105%一开始其实是比98%和95%收益更高的,但当掉下去的时候也掉的更多,所以OTM的波动更大)。
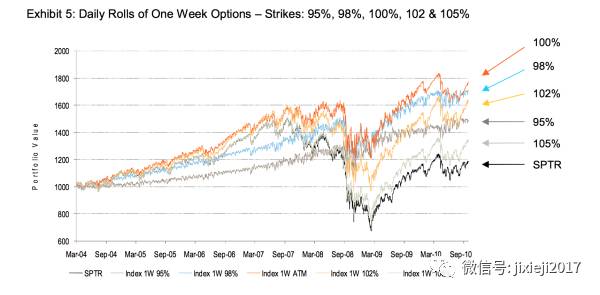
但是JPMorgan取的是1M的rolling,事实上tenor最小的weekly maturity会效果最好(如下图),不知道为什么不用。具体的解释是跟volatility surface的另一个维度term structure有关了,最后期权科普部分会详细介绍。
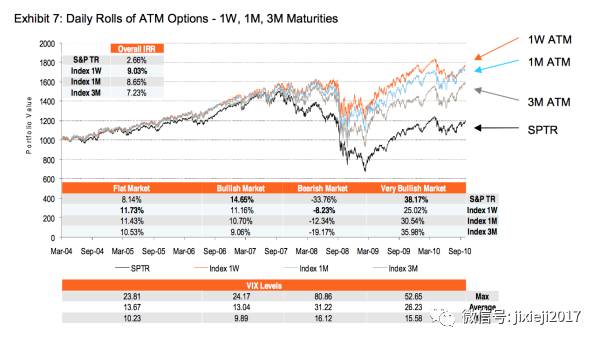
虽然有那么多好处,但由于是单边卖期权,所以存在的风险就是股票的价格会往反方向走。比如说这里如果股票价格一直猛涨的话,还这么卖期权会死的很惨。所以风险就在于预测这个股票的表现强弱。
当然这里衡量股票强弱并不是直接预测股票的价格,而是JPM自己通过各个factor综合构造的一个分数。 如下:
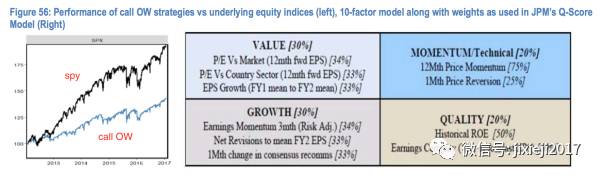
左边的图就是这个“call OW策略” VS sp500大盘的ETF(spy)的表现
有些人可能会问了,这策略表现这么差,有啥用?
股票不一定都会疯涨嘛,总会有不同sector轮转的时候。而且要知道现在美股是超级大长牛,但是股票不会涨上天对吧,总会有经济周期超过均衡太多而掉下来的时候。所以如果我们能用这个策略无缝切换的话那不是就都可以抓住了么?(当然,比较困难...)
右边的图就是形容JMP是怎么给股票打分来决定其表现好坏的。我们可以看到一共分为4大块儿,Value,Momentum/Technical,Growth和Quality,分别在这个股票的得分里面有不同的权重。每一块儿呢又是由其下面的小factor通过不同的权重构成。
比如对于每一个股票我们有这些10个小factors的数值,按照他们自己的权重可以算出这4个大的factor的数值,然后再按照这些大的factor的权重算出来一个最终的得分作为衡量股票表现强弱的标准。应该是得分越高,这个股票的表现越好。但由于我们的策略是不希望股票的表现过于强势,所以当股票表现差的时候会trigger我们的策略(否则就单纯long?或者加入其它的策略也可以)。
OK,现在开始解释怎么用logistic regression来做这件事。
我们首先需要弄清楚我们的Y和Xi分别是什么。这里对于Y呢,我们想要预测的是“call OW策略”是否优于单纯做多这个股票的概率,所以也就是当样本数据中“call OW策略”的收益高于单纯做多的时候Y的取值是1,低于单纯做多的时候Y的取值就是0。对于Xi,这里每个股票的这10个小的factor作为不同的因子Xi。
对于样本数据,由于金融的数据不是很多,所以想要减少model的对于数据本身的依赖程度variance,我们可以用前面bootstrap的方法来抽样得到很多个不同的sample dataset,每一个sample dataset都用logistic regression来拟合,自然每一个sample dataset我们都可以得到一个logistic regression的方程,也就是每一个sample dataset我们都可以得到一套这10个因子的系数,即他们每个因子分别对每一个logistic regression预测概率的贡献程度(感觉自己好啰嗦,这样的解释比较白话了吧...)。
最终的结果就是对这些不同sample dataset拟合的model的结果取平均值。(如果对研究某一个系数感兴趣就是将这个系数取平均值,如果是对最终的预测概率Y感兴趣就用每一个sample dataset的预测概率Y取平均值,实际上也就是取感兴趣东西的distribution的mean)
对于系数的理解可以参照linear regression,系数的正负就是这个因子对于预测结果的影响方向,系数的绝对值大小就是其影响的大小。
bootstrap其实是为了多次重复试验获取Y或各个因子前面系数的distribution(或者quantile,因为distribution本身就含有quantile的信息),也可以用来降低variance。因为是很多次重复试验的平均值,因为bootstrap之后获得分布的均值会比用全sample仅做一次regression的结果的variance更小。
简单来说,就是做无数次实验,然后每一次实验都得到一个结果,将这些结果全部扔进histogram里面,就变成了这个想要观察结果的分布图(这个结果可以是Y,也可以是各个因子前面的系数,下面Figure 57里面10个因子的系数应该就是取平均值之后的结果)。
下图结果的意思是我们需要避免3M Realized Volatility这个因子高的股票,但是Earnings Certainty和12M Price Momentum这两个因子是对股票有利的。
然后通过logistic regression,我们就通过这10个Xi和其系数可以预测出来“call OW策略”的收益优于单纯做多这个股票的概率。并且可以自己自行定义,当概率超过某一个值(不一定是50%,可以更严格比如80%,90%都可以,其实这个也可以用统计的方法来求得最优的一个benchmark)的时候trigger这个“call OW策略”,如果小于这个概率值的话就单纯做多这个股票。
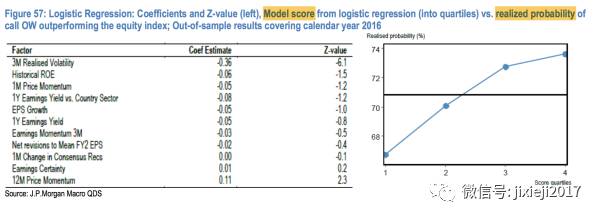
上图里面我其实有一个疑惑的地方,就是这个地方的score quantile(Model score from logistic regression)应该跟前面提到的10个factor的Q-score是不一样的。因为上面右图中随着这个score的增大,“call OW策略”优于单纯做多这个股票的概率越大,也表示着预测的股票的表现会随着这个score的增大而越来越差才对。
但实际上Q-Score的值越高,预测的收益率就越高。
Q-Score里面也有我们用到的这10个相同的因子(因为这10个因子就是从Q-Score的model里面来的),所以我们可以像前面Figure 56里表示的那样根据权重算出来那4个大的factor,再把这些大的factor结合起来变成一个综合的分数来衡量这个股票的强弱程度。但这里似乎没有用到这个方法来衡量股票的强弱。
我稍微搜了一下JPMorgan以前的报告,Q-score具体是长这个样子:
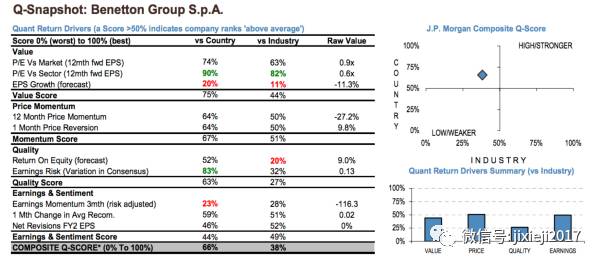
The higher the Q-Score the higher the one month expected return。
这里明显和Figure 57右图不符合。所以现在的问题就变成了Figure 57右图中的横轴"call OW score"是怎么计算的。但我也不知道...感兴趣的读者可以自行研究...可能在文章给的JPMorgan Market的link里,但如果没有access的就看不到那个报告了。
这大概就是怎么运用logistic regression来处理是和否的问题。
当然,任何模型都有其适用范围,logistic regression也不例外。
logistic regression的缺点就是当处理很多个变量Xi的时候,不能很好的解决Xi之间相关性的问题,这个需要很注意。
Support Vector Machine
接下来我们可以看看另一个classification的方法,就是很著名的Support Vector Machine(SVM)。
首先我们可以看一张图:
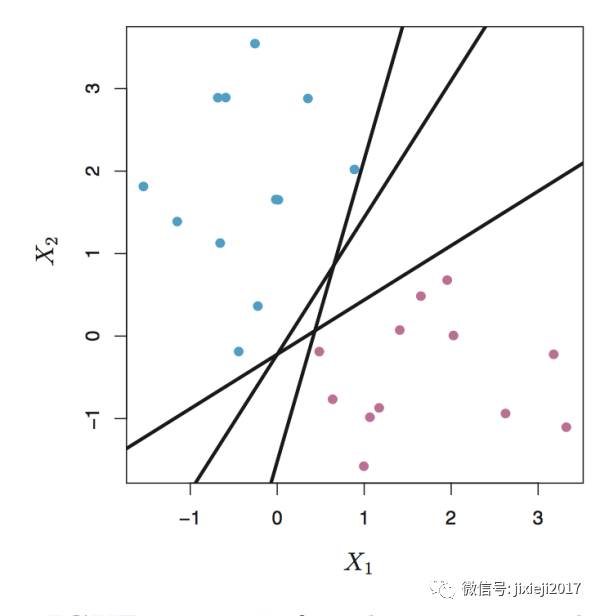
这张图表示的东西呢,就是我们有一堆观察点,每一个观察点都有Y和X1,X2的值。这里Y呢因为是classification,所以只有两个值,一个蓝色(我们分配的值给+1),一个是红色(我们分配的值是-1)。X1的值就是横轴,X2的值就是竖轴。
所以每一个观察的点都有Y,X1,X2这三个属性,画在X1和X2的平面上面,Y的值用颜色来表示。
我们想要做的事情呢,就是用一条线把这些点区分开来(譬如图上的三条黑线都可以把蓝色的点和红色的点分开了)。由于这是二维平面上面的一条线,所以其表示的方程就是:
𝛃0+𝛃1·X1+𝛃2·X2 = 0
这一条线确定之后,系数𝛃0,𝛃1,𝛃2也就确定了,以为其只是用来确定这一条线的系数,并且在这条线上面的点的坐标(X1, X2)都满足这个方程。
所以利用这样一条线,我们就可以用来区分这一条线两边的点了。
当一个点的坐标(X1, X2)满足 𝛃0+𝛃1·X1+𝛃2·X2 > 0 的时候 ,就处于这条线的上方,也就是蓝色(Y=+1)。反之,如果满足 𝛃0+𝛃1·X1+𝛃2·X2 < 0 的时候,这个点就在这条线的下方,也就是红色(Y=-1)。
这样我们就将这两种情况合并成一个式子来表示这条线两边所有点需要满足的条件:
Y·(𝛃0+𝛃1·X1+𝛃2·X2) > 0
但是这里就出现了一个问题,图中有三条线,这三条线都可以将蓝色和红色的点分开,那我们怎么对比这三条线的好坏呢~
这个问题也很好解决,那就是我们希望这两边所有的点离这条线的距离尽可能的远,因为这样就说明这两边的点被这条线区分的最开,区分的结果自然也就更加可信,也就是使两边的点到这条线的垂直距离尽可能的大。
为了使得他们分得更开,我们可以将大于0这个条件更加严格一点,使得
Y·(𝛃0+𝛃1·X1+𝛃2·X2) > M, M是某一个正值,这样也就给两边都增加了缓冲区,使得两边的点距离这条线的距离全部都大于M,并且我们希望这个M的值越大越好。(因为M的值越大,说明两边离这条线的距离最近的点越远,也就保证了其他所有点都会离得更远)
数学上的表达式是这样(这里i是指的每一个点,系数𝛃的和被标准化为1,这样normalize之后可以和M值作对比):
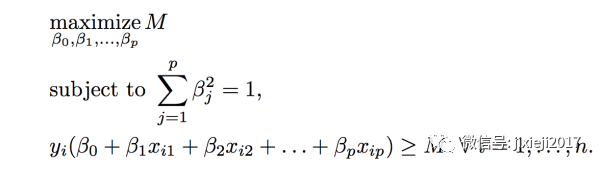
然后就变成了如下这张图,中间那条黑色的实线就是之前M=0的情况,而两条虚线就是方程加上某个正数M之后的效果((其实就是对中间这条黑线分别上下平移距离M)。还需要注意的是,这里M并不是我们人为给的一个值,而是上面的数学式对所有的点经过一定的optimization之后得到的结果,各个Xi系数𝛃的值也是一样经过optimization之后的结果。
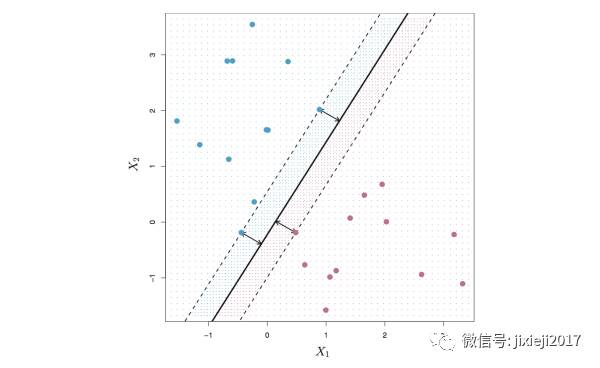
但是,不要以为这样就可以解决问题了,因为实际情况并非这么完美。很可能会产生如下的情况,蓝色和红色的点都混杂在一起,就无法再用一条直线完全将这些点都分开。
这里我们就要进入真正的Support Vector Machine的内容了。 但具体应该怎么做呢? 也许就有人会想到,那如果我把M的值变成负数会怎么样?
这个其实也就是下面要说的,我们可以在上面的数学式子里面加入一定的错误率(也就是那些错误被线分类的点,反应在式子里面就是M加上一个负数),也就是允许这条线两边的蓝色区域允许有红色的点,红色区域允许有蓝色的点,但是需要将这些错误率保持在自己能接受的一定的大小之内,毕竟我们希望其错误率越小越好(最理想的情况就是这条线两边的点完全没有错误率,也就是最开始完全分开的情况,但是现实中基本上不存在),所以可以将其作为一个penalty ϵ加入上面数学的表达式中。
并且我们可以把这个penalty变得更加有效,使得其跟缓冲区结合起来。我们可以看如下的图:
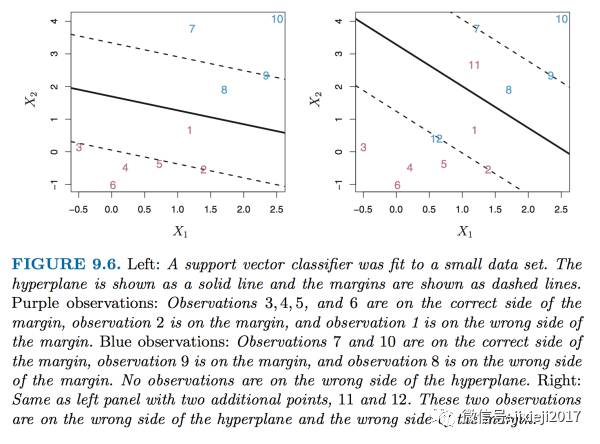
上面的左图中,和前面一样,我们可以看到中间的那条实线代表的是M=0,虚线代表的是蓝色和红色两边的缓冲区。这样所有的点就被划分在了4个区域里面:
蓝色一边: 在缓冲区内,在缓冲区外
红色一边: 在缓冲区内,在缓冲区外
这样我们就可以给予不同区域的点不同的penalty的值ϵ。
因为这实际上和前面一样,都是optimization的问题,所以我们需要先给ϵ在不同区域内不同的loop范围求得其最佳值。
当蓝色的点在蓝色这一边的缓冲区之外,或者红色的点在红色这一边的缓冲区之外的时候,我们将ϵ的值设置为0(因为这是最理想的情况,没有penalty)。
当蓝色的点在蓝色这一边的缓冲区之内,或者红色的点在红色这一边的缓冲区之内的时候,我们将ϵ的值设置为0<ϵ<1(因为在缓冲区内的话就开始有一定的分类错误风险,我们设立缓冲区的目的就是为了使得所有的点分的越开)
当蓝色的点在红色那一边的时候,或者红色的点在蓝色那一边的时候,我们将ϵ的值设置为1<ϵ(这里因为已经形成了错误的分类,所以将ϵ的值设置的更大一点,并且在错误的一端错的越远这个penalty的值就越大,对整体分类效率的负面影响也就越大)
所以我们就有下面的数学表示:
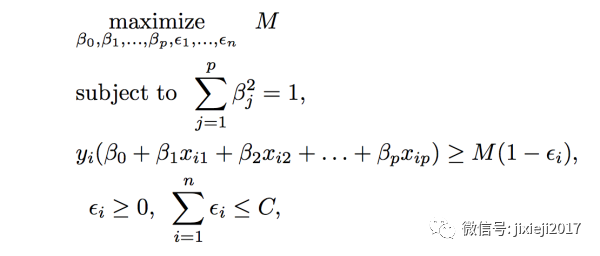
这里中间那一条分类线其实和M还有penalty ϵ无关,因为其本身就是当M=0时候的结果。这里变化的只是最优缓冲区的确定,并且这是整体所有点都考虑进来之后的最优缓冲区。
这里ϵ就是上面说的的penalty。第三个式子右边的M·(1-ϵ)表示的是加入ϵ这个penalty之后改良过的每一个点距离中间那条线的“距离”,在不同的区域内的时候由于ϵ的值不一样,分类越错误,M·(1-ϵ)的值也就越小,错误分类的时候其值甚至是负数。但我们是想要其越大,因为其代表了所有点距离中间这条线的”距离",所以我们需要将整体的ϵ之和控制在一定的范围之内。
这里的C就是我们自己设置用来控制所有在缓冲区甚至错误分类的点的ϵ总和。我们想要整体的(潜在错误:缓冲区内 和实际错误: 在另一个相反区域内)错误率越小,也就是想要C的值越小。当我们设置C为0的时候,也就是让所有的ϵ都是0,也就是一开始最理想的情况,0容忍率。当C设置的越大,也就表示我们对于错误的容忍程度越来越大。
同样,我们希望的是通过这个数学式的optimization得到所有点共享的一个M值(因为存在有错误分类的情况,所有这里的M就不是前面理想情况下距离中间那条线最近的那个点的距离了,而是一个真正使得整个分类最优化的缓冲区域,我们称作Margin)和Xi的𝛃值,还有每一个点分别的ϵ值。ϵ进行optimization逼近的时候的跨度取决于这个点在哪个区域,实际上也是取决于M的取值,因为M代表的就是margin的范围大小。
我们自然是希望M的值越大越好,因为其代表的是分类的有效程度,又不能变得很大,因为加入ϵ之后,当M越大的时候包括进margin的点就越多,也使得ϵ不为0的点就越多,这样分类的效率就越被侵蚀。所以这其实是一个M值和被包括进margin区域的点的ϵ(还有本身就是错误分类的点的ϵ)总和C之间的一个平衡。
我们还可以从上面的式子看出来一个现象,那就是只有在缓冲区内和错误分类的点才会对M的值(或者说优化的缓冲区大小)产生影响。这些点其实就是被称作support vector,他们的作用就是确定最优的缓冲区,我猜名字的来由也就是他们是用来support将两边区分开来的区域。
因为其实我们只需要保证这些点同时距离中间那条分类的直线最远即可,其他在缓冲区之外的点都比这些点离中间的分类线更远,所以也同时保证了缓冲区外的点都更能被分类。这里我们也可以想到,由于在缓冲区外面的点的penalty ϵ为0,所以对于缓冲区的大小其实没有影响,有影响的仅仅只是ϵ不等于0的缓冲区内和错误分类的点(当然这里有一个feedback loop,因为只有确定了缓冲区M的值之后才能知道哪些点在缓冲区外面,所以整体才是属于全局优化的问题)。
缓冲区的重要意义在于,在缓冲区之外的点,我们可以非常确信是这一边的分类,所以我们是希望缓冲区外面的点越多越好,我们对于所有点的整体判断成功率就越高。所以当我们将我们对于错误的容忍程度C的值降低的时候,缓冲区的大小也在收缩。如下图我们可以看到随着C的值减小,缓冲区的宽度也在一直变窄:
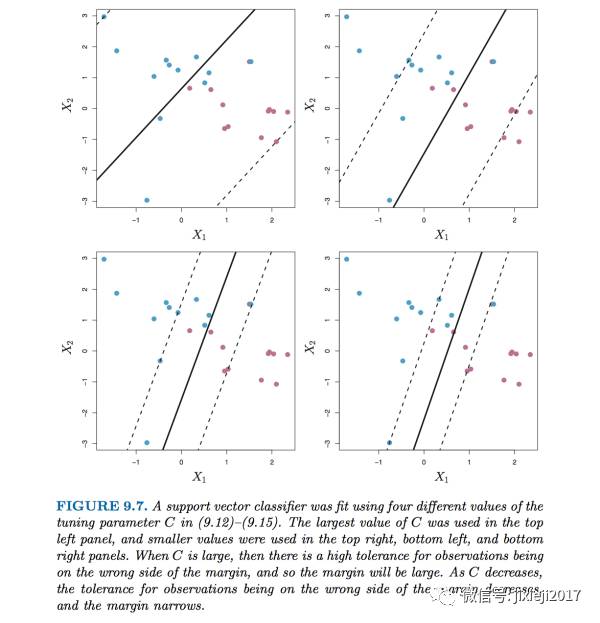
这里我们给予的参数C做的事情其实就是统计模型中最核心的bias和variance的tradeoff。
当C很小的时候,我们对错误分类的容忍程度小(当设置C=0的时候,其实是零容忍),缓冲区会很窄M的值很小,很少的点会在缓冲区内或者被错误分类(即缓冲区被很少的点所决定),这样其实是使得整体的分类效果更好(bias很小),但牺牲的就是model的灵活性,也就是variance很大,对于out-of-sample的数据的分类效率会很低。直观的理解上来说,如果我们将缓冲区内的点稍微变一下,对于缓冲区的影响是非常大的,也就说明这个缓冲区对于数据的依赖是非常大的。
同理,当C很大的时候,错误的容忍程度大,缓冲区会很宽M的值很大,然后几乎所有的点都被包括进了缓冲区,所以整体的分类效果会很差(bias大),但是对于数据的依赖性降低(variance小)。这里的直观理解也类似,如果我们改变一些缓冲区内点的值,对缓冲区的影响非常小,因为缓冲区取决于其他更多的点,也就是对于数据的改变不是那么敏感。
这两种情况我们都不希望发生,我们需要在bias和variance之间找一个平衡点,所以我们就需要用前面介绍的cross-validation的方式来确定最优的C的值。
OK,经过上面的过程,基于我们所有的数据,还有设置合适的C值,就可以得到中间那条分类线和缓冲区了,然后就可以根据他们对于out-sample的点的X1,X2的值进行Y的分类预测。
实际情况其实还经常会更加复杂。上面讲的SVM是仅仅针对linear的情况(也就是直线就可以帮助进行分类)。但如果是如下的情况呢?很明显这样线性的预测就不再适用了。
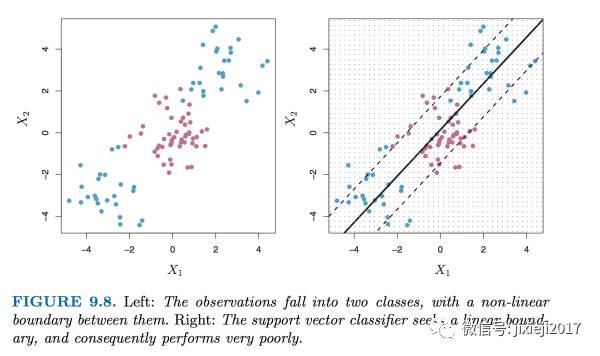
这里我们就需要将线性的空间拓展或者经过映射变成高维非线性的空间(图中的例子是2维,因为只有X1和X2这2个变量,为了得到non-linear的关系,我们需要将X1和X2进行升维,譬如简单的加入另外的因子X1和X2的平方值,开方值,log值等等形式,复杂的就是直接将每一对观察值本身作为因子或者说kernel,将直线变成曲线甚至是圆等等形式),如下图所示:
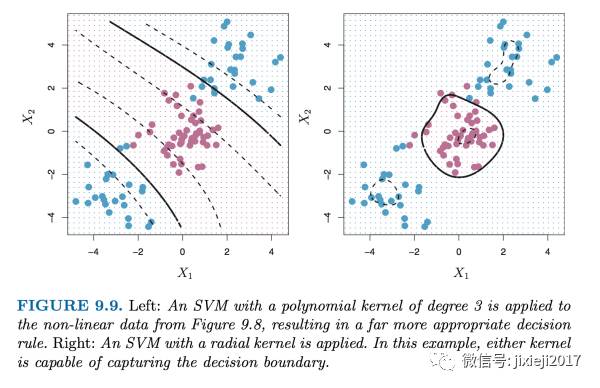
我们可以看到,这样non-linear的SVM分类方式对于上图更为合适,在实际操作中kernel的具体形式可以自行在R中选择(具体选择哪一种更合适可能就取决于自己对于想要处理的dataset性质的了解了)。
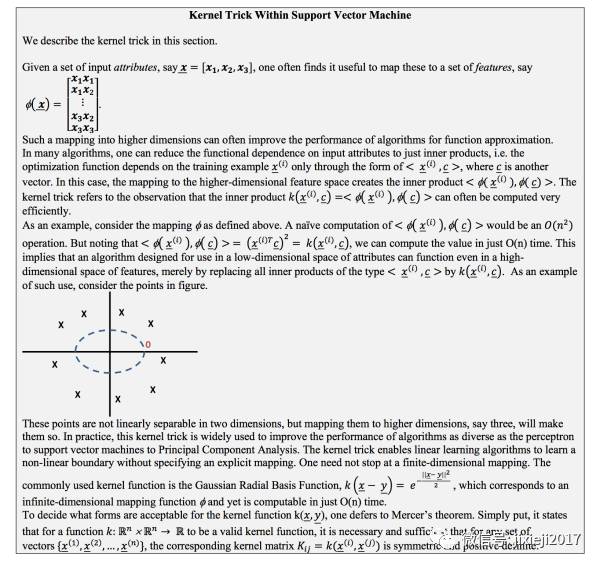
上面就是具体kernel来升维的数学推导过程,感兴趣的童鞋可以仔细推敲。如果不感兴趣的,也可以装作懂了的样子,继续往下看其具体在外汇option上应用的例子了~
这里的主角是外汇期权,1M ATM EURUSD options,
我们来看看Y和变量Xi分别是什么。这里的Y是由rolling这个期权的long position产生的PnL(profit and loss)决定的,并且是分类的类型。
当PnL<-20 bps的时候,Y的分类是”vol sell”,这里vol的意思是波动率volatility,后面的期权部分会详细介绍。
当PnL>20 bps的时候,Y的分类是”vol buy"
当-20<PnL<20 bps的时候,Y的分类是”neutral"
这里的Xi呢,是由如下377个不同的指标构成(由于这些指标的scale不一样,所以依然需要对其normalization处理):
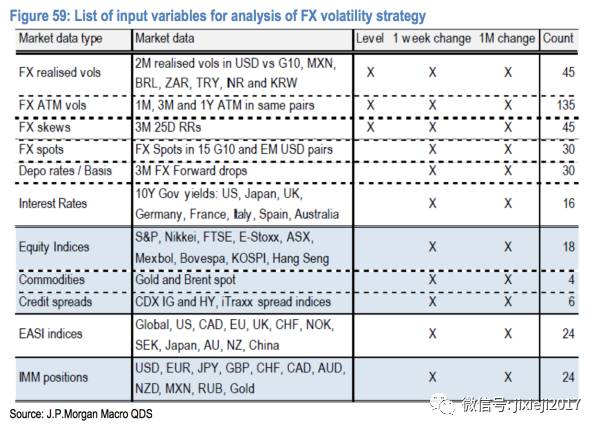
然后对于数据呢,我们是取的过去10年daily的数据,一共是2609个点。为了防止overfitting,我们用Principle Component Analysis(PCA,后面也会详细介绍)来对Xi进行降维(因为这里的Xi有370个,过于多了),我们通过PCA选取最重要的60个,90个,180个变量Zi(这里的Zi是由全部的Xi线性合成的大因子,被称作主成分因子)。如下图:
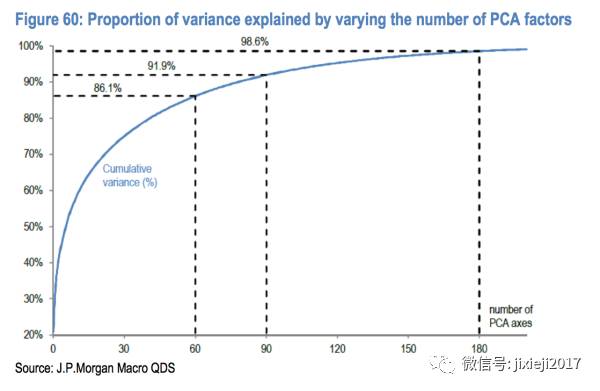
PCA呢,是一种对变量Xi非常多的情况进行降维的方式,下面unsupervised的统计方法里面我们会细致讲这个方法是具体怎么降维的。主要的思路就是将所有的Xi线性组合成若干个主成分因子Zi,使得其能最大程度的代表所有的信息。
上图表示的就是这些最主要贡献的Xi积累起来对于Y的解释程度,也就是这些选中的Xi所包含的信息能涵盖Y的多少信息。横坐标就是由PCA选出来的主成分因子的数目,纵坐标就是对Y的解释程度。
例如在图里我们可以看到,当我们选择前60个最大贡献主成分因子的时候,可以解释86.1%的Y;当增加到前90个因子的时候,可以解释91.9%;当选取前180个因子的时候,可以解释98.6%,相当于我们用了180个主成分因子就代表了原始370个因子的91.9%的信息,使得计算和model复杂程度都大大减少。
有些盆友可能会觉得有疑惑,前面的linear regression的lasso方法似乎也可以用来降维,为什么这里要用PCA这个方法呢。
我觉得有两个原因:
lasso方法需要利用连续的Y的值去做regression才能进行降维,而这里Y是分类不是数值,并且PCA的方法仅仅只需要Xi本身的信息就可以直接对Xi进行线性组合来降维。
第二个原因是这里的因子数目太多,有370个,如果用lasso的linear regression直接做回归会使得模型不稳定和过拟合。
对于数据,我们将其分成两部分,前8年的数据作为training sample,后2年的数据作为test sample,并且对于training sample用了10-fold cross-validation的方式去train model。
10-fold cross-validation其实是k-fold cross-validation中k=10的情况,其内容是将training sample随机均分成10组。然后每次选出一组作为validation set(其实也就是用来做test sample),这一组选出来之后剩下的数据全部作为training set来train模型,模型确定之后再应用在那选出的一组上求得MSE(可以当做test error)。这是一次实验。
接着按照同样的方式将这10组的每一组都作为validation set进行同样的步骤,每一组都可以求得一个MSE的值。然后最终的结果就是将这10组MSE的值取平均,得到这个model最终的MSE。
但是这里为什么要用10-fold cross-validation我比较疑惑。或者说这里的10-fold cross-validation是用来得到10个Y的预测,然后平均一下得到最终的Y?
不太确定10-fold cross-validation是不是可以直接用来对Y求平均值。一般10-fold cross-validation只是用来求得平均的MSE,或者说根据某一个变化的参数画出来最小MSE时候(一般由于这个参数是penalty因子,代表的是bias和variance之间的tradeoff,自然MSE的图会是U型)这个最优参数的位置。
然后得到如下的结果:
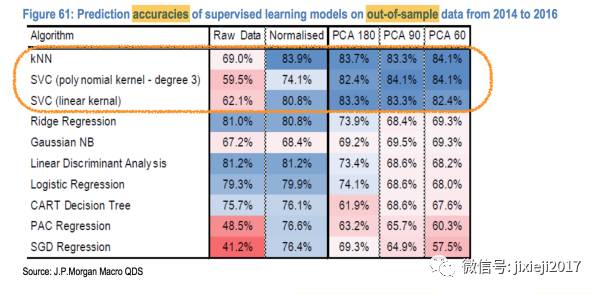
我们可以看到KNN,SVC(也就是SVM,kernel是三阶的polynomial方程)还有SVC(kernel是线性的方程)这三种model表现最好。
预测的结果跟现实的结果对比如下图:
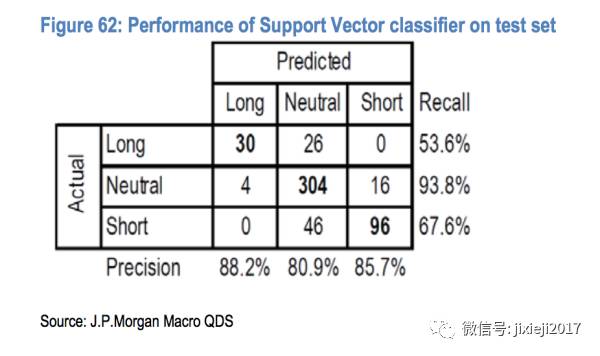
我们可以看到SVM的方法预测准确率还是比较高的(也就是一般预测的都是对的),但是抓住机会的次数(或者说预测trigger开仓的次数)不多。
所以策略的话可以着重利用高准确率这方面,或者重仓。
上面我们了解了两种处理classification问题的方法,一个是logistic regression,一个是SVM。他们的比较是当分类的点非常分散的时候SVM的表现更好(图上的表现就是相同类别的点会聚集在一起,并且不同类别的点尽量分开),当各个类的点混杂在一起的时候logistic regression更加合适(高度混杂在一起的时候SVM就无能为力了)。
SVM可以看作是一种空间上的mapping,所以当不同类的点被糅杂在一起而不是分团聚集在一起的时候(聚集在一起不一定是指在linear情况的在线的同一边,也可以是聚集成圆等等形状,通过mapping到另一个合适的更高维空间依然可以转化成linear的情况来进行处理,继而再mapping回去降维),会难以找到一个合适的映射空间处理问题。
参考文献与推荐书籍:
1.《Machine Learning and Alternative Data Approach to Investing》JP Morgan
2.《Systematic Strategies Across Asset Classes》JP Morgan
3. 《Momentum Strategies Across Asset Classes》JP Morgan
4.《An Introduction toStatistical Learning》
5.《The Elements of Statistical Learning》
6.《Active Portfolio Management》
7. 《Quantitative Equity Portfolio》
8. 若干知乎问答
9. 裂墙感谢身边给予极大帮助的盆友们!
10. 还有我自己...嘚瑟一个,哈哈
用机器学习玩转金融之入门秘籍一
招聘 志愿者
希望你有稳定输出的时间,英文能力佳,从业者优先。
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang







