应对数据安全“黑天鹅”,金融级数据库的多活架构实践

作者介绍
王涛,巨杉数据库联合创始人之一,目前担任SequoiaDB的CTO与总架构师,负责SequoiaDB产品的架构设计与开发。曾是北美IBM DB2 Lab核心研发成员,有着超过十年数据库核心架构设计、数据库引擎研发和企业级数据库应用的经验。
今年以来,公有云事故频发,大有“黑天鹅”不断爆发之势头。近期,北京某初创公司表示,在使用某云平台8个月后,放在云服务器上包括备份的数据全部丢失,导致公司几年来的平台数据全部丢失,造成“近千万元损失”。对此,该云平台表示歉意,愿意赔偿该公司在平台产生的实际消费共计3569元,本着帮助用户迅速恢复业务的目的,承诺为该公司提供13.29万元现金或云资源的额外补偿,赔偿加补偿金额总计13.64万元,达到其在平台中用云金额的37倍。
此外,在近半年时间内,多个平台也曾出现数据安全问题, 相信大家都有耳闻,在此就不一一列举了。显然,频繁出现的数据安全“黑天鹅”,让大众对数据安全的关注再次上升到了新高度。
伴随数据在企业内部价值的不断提升,数据已经成为了企业的生命线与核心资产。无论在中国还是海外,金融行业的数据安全都已成为了监管机构的首要监管重点。
在中国,银行核心系统安全一直是我国银监会所关注的重点,对于大部分银行数据中心,监管机构目前提出了对于数据安全和数据高可用的“两地三中心”以及“双活”能力。
“两地三中心”即生产数据中心、同城灾备中心、异地灾备中心建设方案。这种模式下,两个城市的三个数据中心互联互通,如果一个数据中心发生故障或灾难,其他数据中心可以正常运行并对关键业务或全部业务实现接管。如今,一些大型银行甚至已经实现了“三地五中心”。
“双活”数据中心就是同个城市部署两个数据中心,多活一方面是多中心之间地位均等,正常模式下协同工作,并行的为业务访问提供服务,实现了对资源的充分利用,避免一个或两个备份中心处于闲置状态,造成资源与投资浪费;二是在一个数据中心发生故障或灾难的情况下,其他数据中心可以正常运行并对关键业务或全部业务实现接管,实现用户的“故障无感知”。
当前企业在数据管理方面已经不断开始尝试新的架构和平台,在监管机构强势监管之下,金融行业的这些数据安全要求,是所有行业里最为严苛的,能够真正满足这些要求的产品和解决方案可谓屈指可数。作为承载着企业关键数据的数据库,其安全性、可靠性、稳定性一直是其重要的核心价值。对于数据库平台,如何通过技术实现更好的数据安全保障?在特殊情况下如何实现数据的恢复、容灾和多活?
数据库多活方案对比
随着众多企业客户对于业务延续性需求的增加,传统业务中的停机维护窗口越来越小,甚至在很多互联网类型的应用中要求7×24不间断服务,导致系统对于数据库的运维能力、持续服务能力、高可用能力以及灾难恢复能力都有着新的需求。
其中,数据库的多活架构从RTO/RPO,乃至对业务中间件的任务分发来说都至关重要。在传统多站点主从架构的环境中,往往业务中间件需要了解不同数据中心的角色,确保读写操作永远被导向主站点,而一些允许异步访问的只读类业务可以由备中心完成。但是,在一个复杂的业务环境中,这种构建方式往往会使得业务模型极度复杂,在进行主备中心切换时也会涉及到很多配置的调整。
从架构层面来看,当前传统数据库业界主要以Oracle的RAC与IBM的GDPS为多活架构代表。
其中,RAC一般坐落在单数据中心内,以共享磁盘为基础,上层通过搭建多个Oracle运行实例,共同连接到一个SAN中,所有的事务控制、锁等待等机制都通过高速网络在数据中心内的多个Oracle实例之间共享。
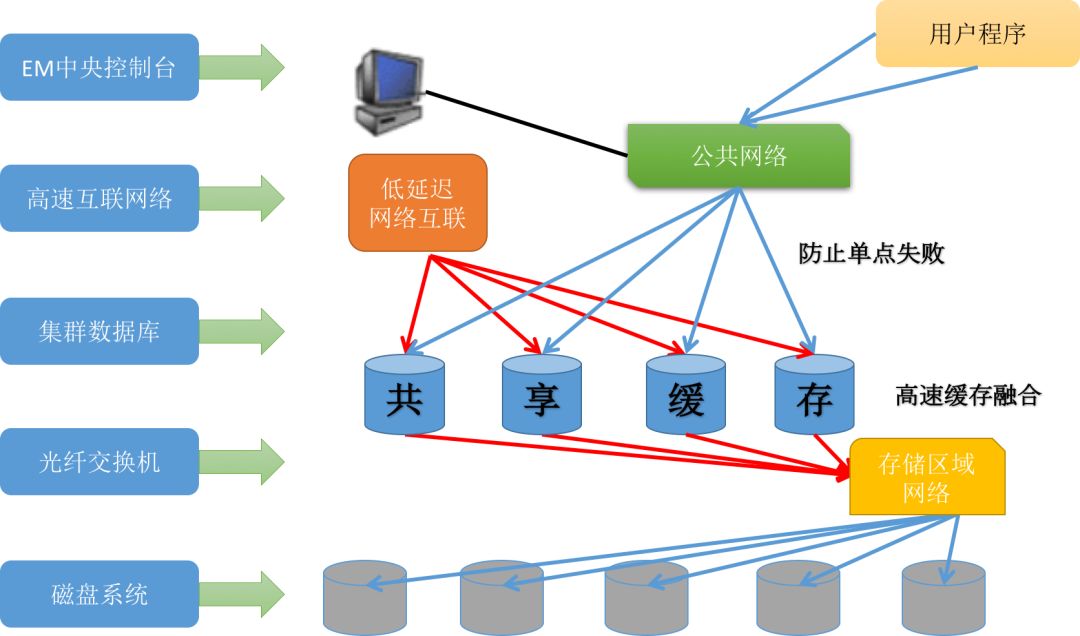
图1:Oracle RAC抽象架构
而GDPS则是更加标准的多活架构。通过在多个数据中心内搭建IBM DB2 for z/OS数据库,并且在数据库之间通过QRep进行数据复制,辅以上层的Workload控制器进行任务分发,实现应用程序在多个站点之间的数据库中做到多活。
传统数据库的一些应用程序层面的多活架构,可以通过对业务进行切分完成。例如,存在于北京和上海数据中心的数据库可以分别负责北方与南方用户的账户维护,同时上海和北京的数据中心可以互相做对方数据中心的灾备节点,这种架构也是比较典型的应用程序逻辑切分的多活模型。
不论是RAC、GDPS,还是应用程序的业务切分,其核心设计理念基本都是基于传统集中式数据库的架构进行设计并实现的。但是,在分布式数据库的领域,其多活设计思路与传统架构设计相比更加优秀。
由于大部分分布式数据库都秉承着计算存储分离的设计思路,因此其SQL解析与执行器往往与数据存储和事务控制分别运行在不同的进程中。在这种情况下,利用数据库自身分布式与三副本复制的特性,将数据打散放置在多个数据中心内,每个数据中心配置本地SQL服务节点,从应用程序的角度看不需要关注底层数据库的主从架构,仅需要通过JDBC连接到本地的SQL服务节点进行读写操作即可。
在这种架构下,每个SQL节点完全对等,并均可以处理读写操作。所有的事务控制、一致性控制、锁等待等机制都由底层的分布式数据库直接提供。
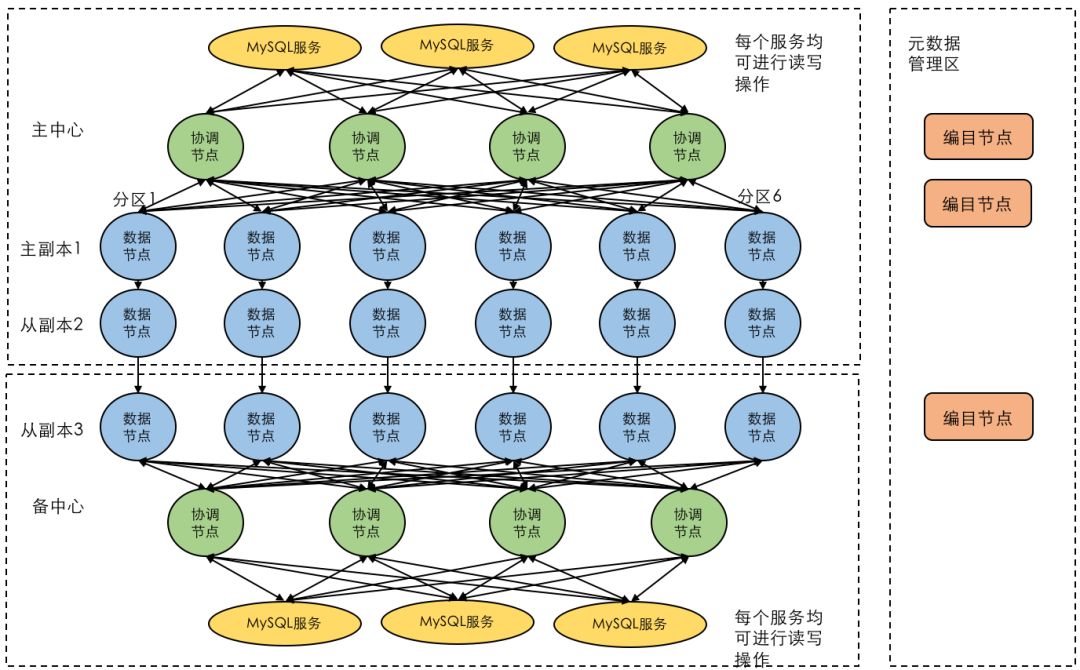
图2:分布式数据库的存储、计算(SQL)分离架构示意
通过该机制,整个集群同样可以提供秒级的RTO与RPO能力,同时对于应用程序来说并不需要关心后台数据库的主备配置,仅需要简单连接到本地的MySQL服务节点即可像使用传统数据库一样使用多活分布式数据库。
金融分布式数据库灾备多活实践
SequoiaDB已经在内部实现了容灾备份以及“双活”的机制,其异地多活架构如下图所示。
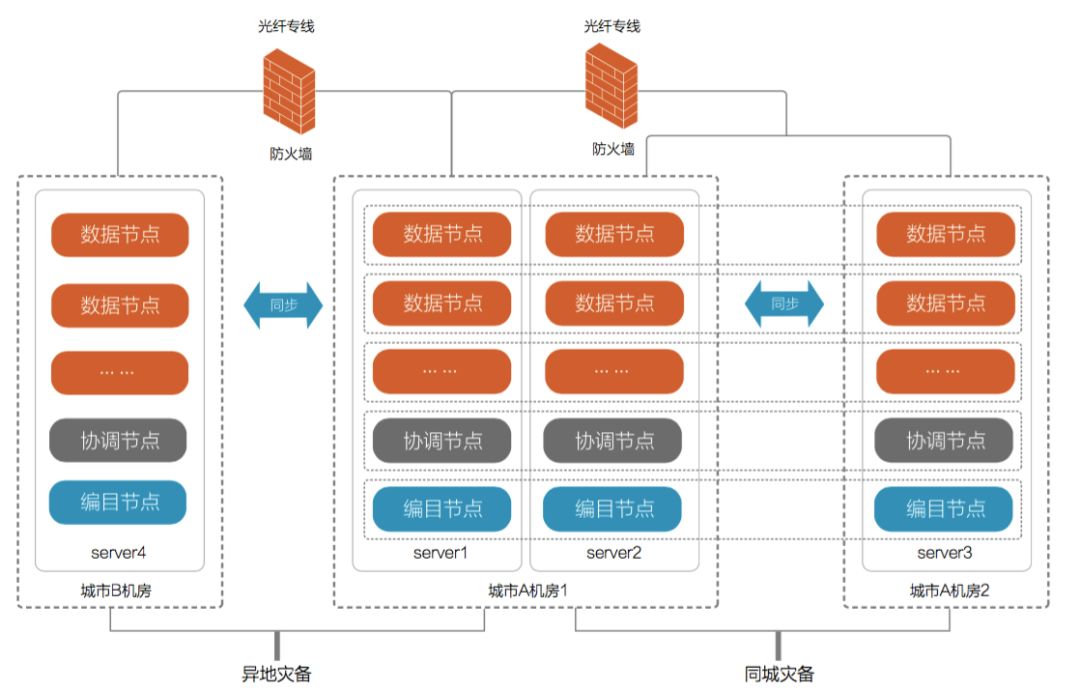
图3:SequoiaDB异地多活架构示意图
针对某大型银行企业,SequoiaDB为其数据库实现了异地灾备的架构,以下就以实际业务对改方案进行简单分享。
该架构是基于SequoiaDB的三副本方案构建的同城灾备,其中两副本部署在本机生产环境中,一副本部署在灾备环境中,整个集群跨越生产环境与灾备环境两个机房。为了保证灾备环境与生产环境的数据保持实时一致,开启SequoiaDB中数据同步强一致性的功能。
开启数据同步强一致性后,每次进行数据更新时,只有当存活的节点全部同步完成后,应用端才回收到更新成功的返回,这样就能在最大程度上保证了数据不丢失。
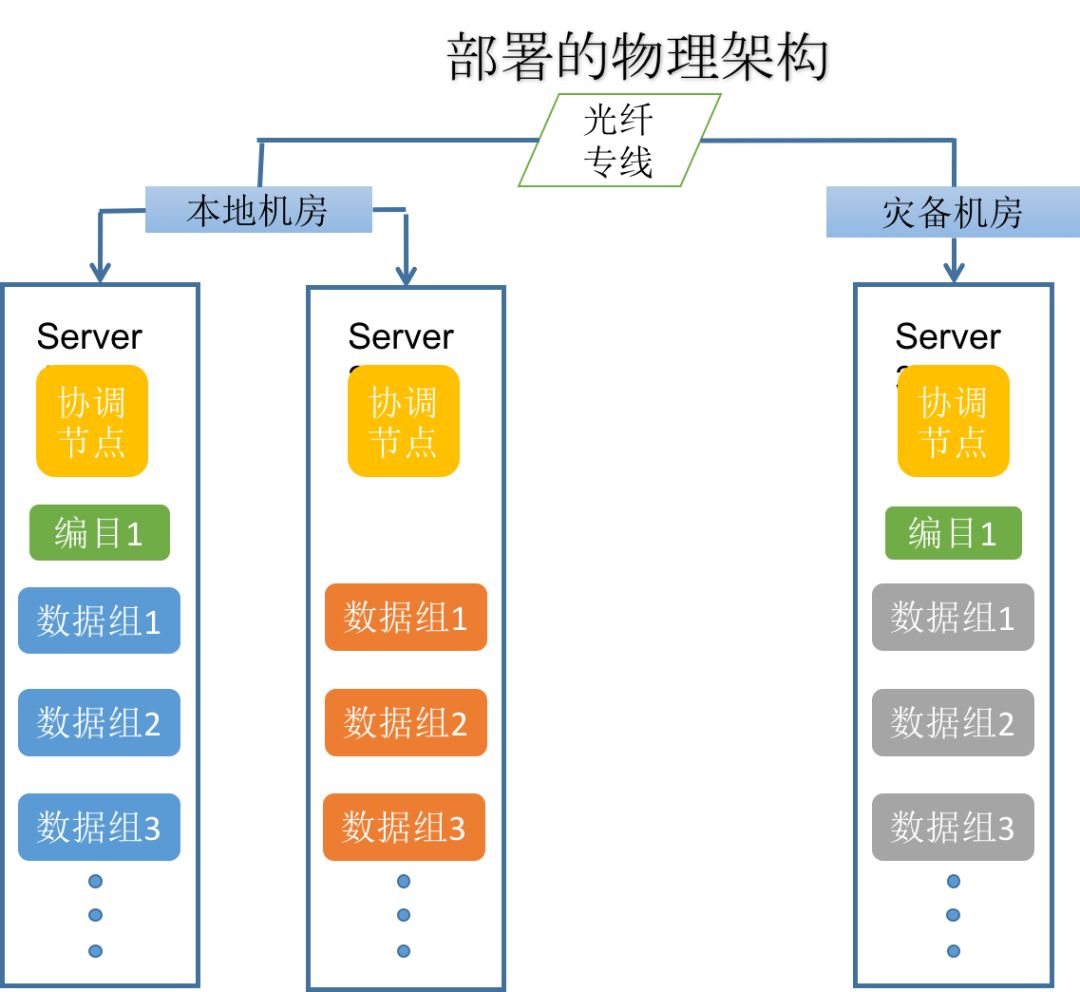
图4:同城灾备物理部署架构图
在同城灾备基础上,于异地机房单独部署一套SequoiaDB集群作为异地灾备集群。异地集群只保持单副本,两地间结构化数据的同步通过传输同城灾备集群日志到异地灾备集群,然后通过重放日志记录的方式实现结构化数据的同步。
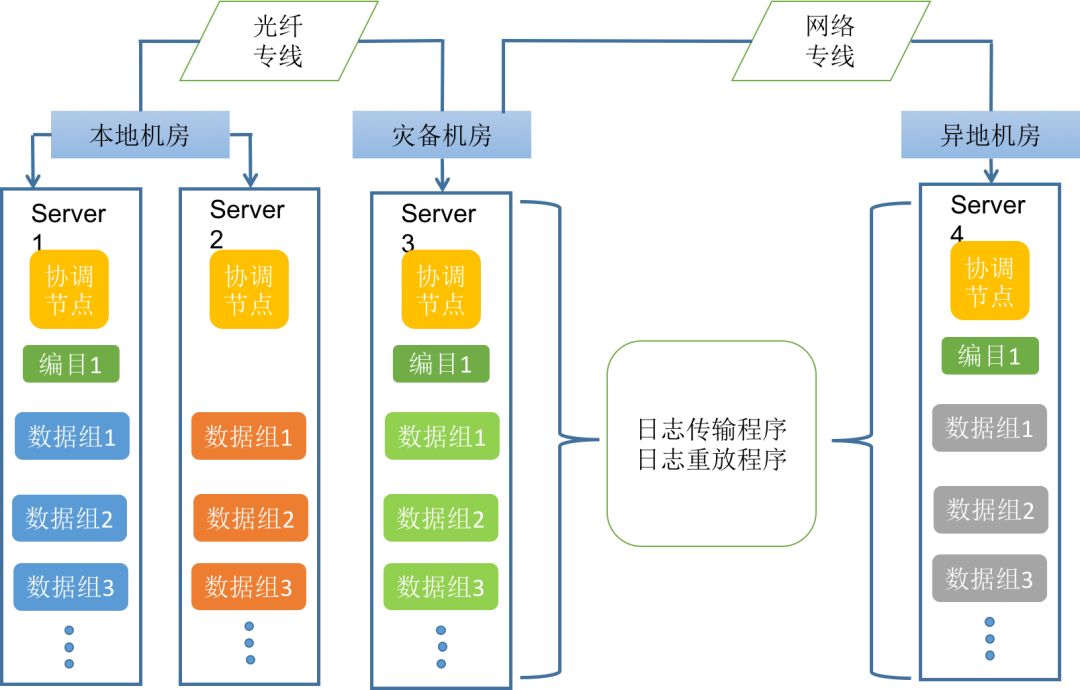
图5:异地容灾部署架构图
1、单节点故障应对
由于采用了三副本高可用架构,个别节点故障情况下,数据组依然可以正常工作。针对个别节点的故障场景,无需采取特别的应对措施,只需及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
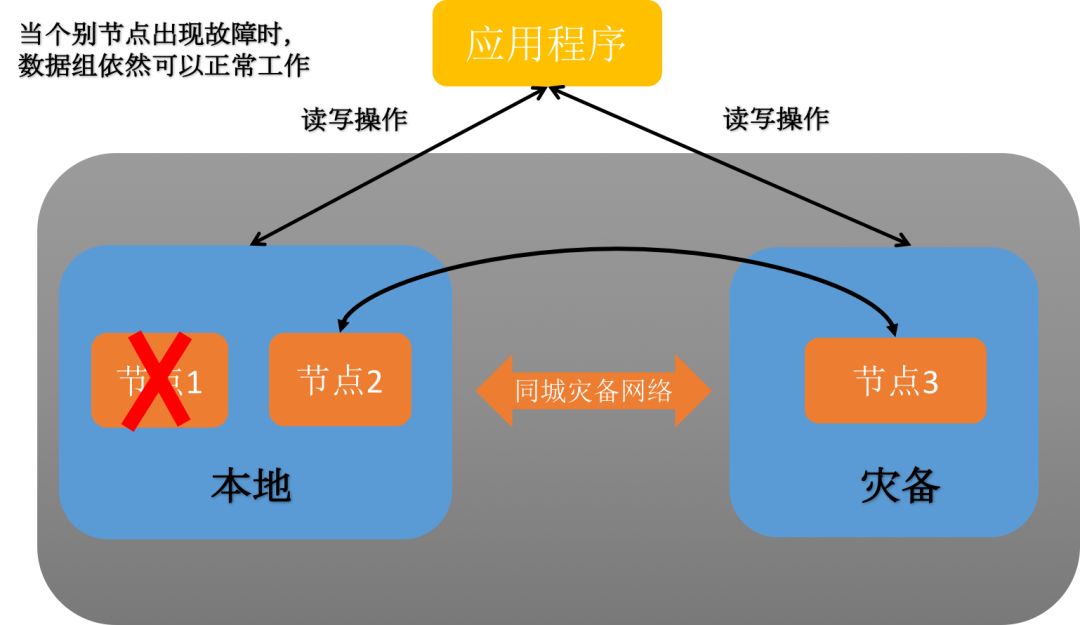
图6:单节点故障情况
2、本地生产环境整体故障应对
当生产环境机房出现整体故障时,整个集群环境将会失去三分二的节点,如果从每个数据组来看,相当于每个数据组有两个数据节点出现了故障,存活的节点只剩余一个。当这种情况发生时,如果不采取任何措施,灾备环境中存活的节点,只能为业务提供查询功能。
当这种场景发生时,为了让使灾备环境中的一个副本继续提供读写服务,这时需要使用SequoiaDB的集群分裂功能,把灾备环境中的集群分裂成单节点集群,这时灾备环境节点均可提供读写服务。分裂集群的耗时相对比较短,一般在十分钟内便能完成。
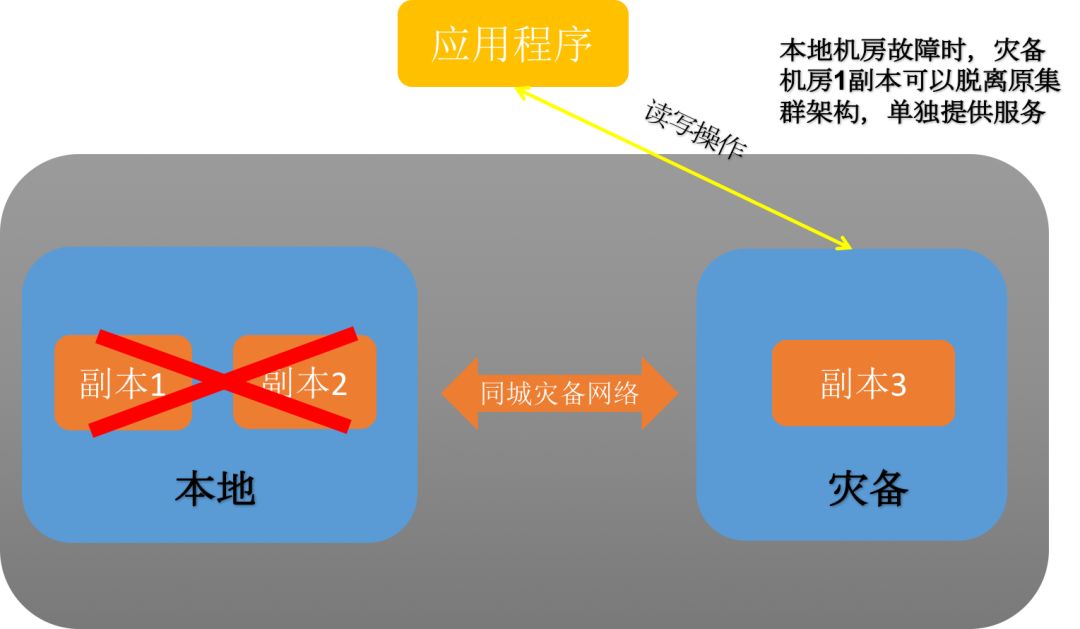
图7:本地环境故障应对示意
其中分裂集群之后,不可再启动生产集群的两个副本,需要使用SequoiaDB的合并集群功能后才能进行启动,否则将出现脑裂,即生产集群也开始提供数据更新服务。将造成生产集群和灾备集群两个数据版本,很难将两者合并。
3、灾备环境整体故障应对
当灾备环境出现整体故障时,由于每个数据组都有两个副本部署在生产环境中,每个数据组存活节点的数量还大于每个数据组的总节点数,所以每个数据组仍然能够为应用层提供读写服务。针对灾备环境整体故障的场景,无需采取特别的应对措施,只需要及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
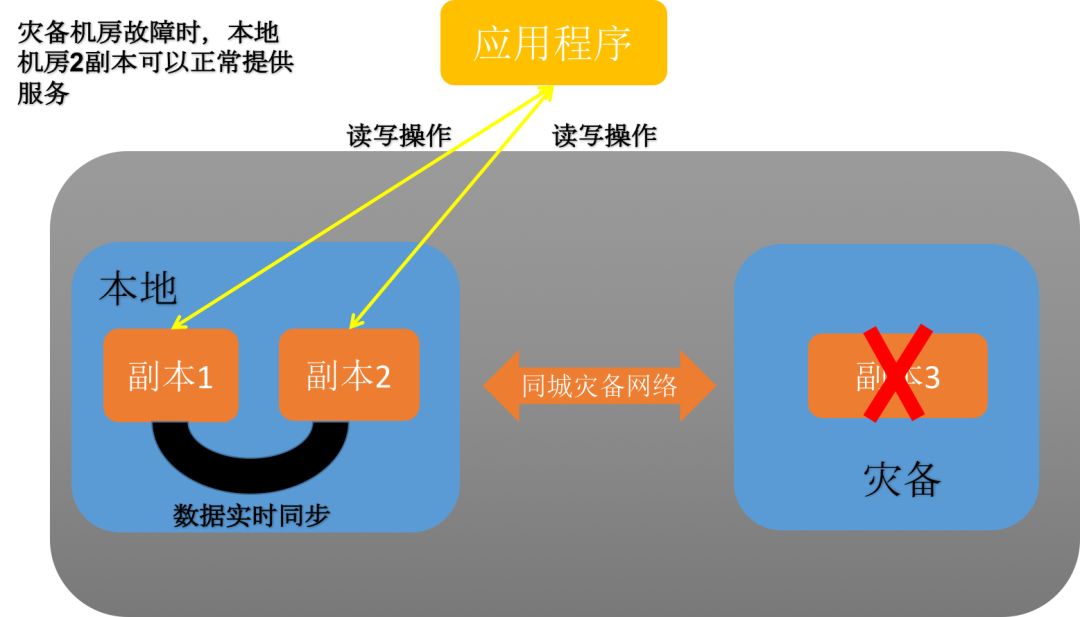
图8:灾备环境故障恢复示意
4、网络故障应对
当同城网络出现故障,导致本地环境与灾备环境无法进行通信时,由于采用了三副本的架构,应用程序可以通过访问本地两副本集群。针对同城网络的故障场景,无需采取特别的应对措施,只需及时修复网络故障,修复后通过自动数据同步或者人工数据同步的方式去恢复灾备节点的数据即可。
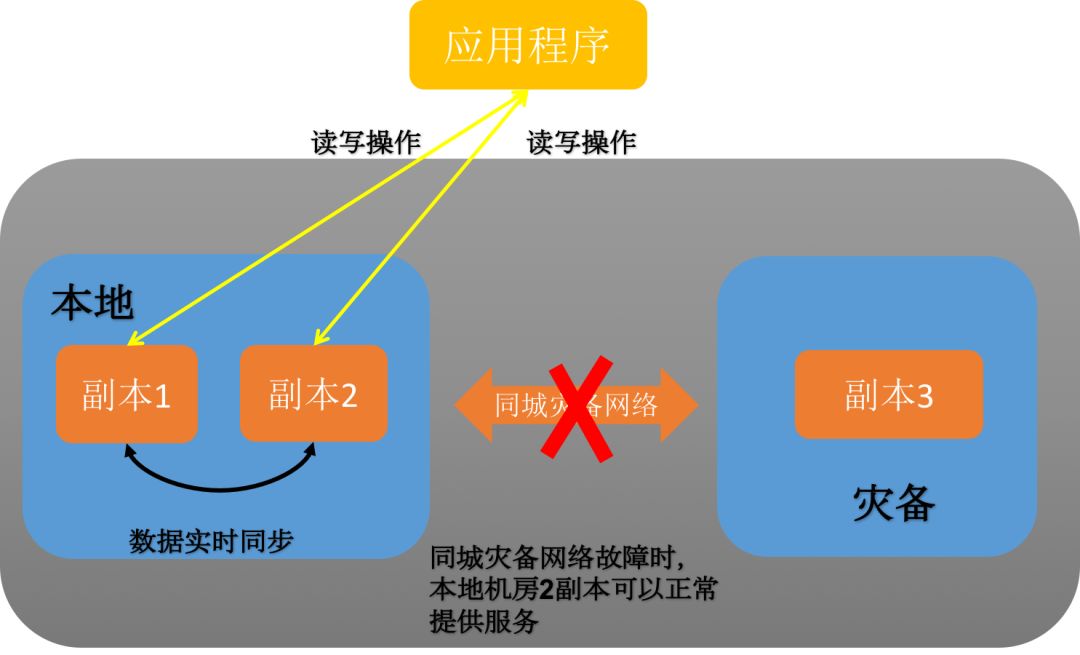
图9:网络故障恢复示意图
该用户的影像平台采用了同城双活架构,每个数据组都有两个节点落在主机房中,另外一个节点落在灾备机房中。在数据同步方面,使用了SequoiaDB的节点强一致性的功能,当数据写入主节点时,数据库会确保节点间的数据都同步完成后才返回,这样即使在主机房发生整体灾难时也能有效保证数据的完整性与安全性。
由于当主机房整体出现故障时,可以使用SequoiaDB的Takeover功能在数分钟内快速地把灾备机房中的单一副本分裂成独立的集群为业务提供服务,因此RTO几乎接近零。由于SequoiaDB开启了节点数据强一致性的功能,因此RPO也几乎接近零。
小结
在金融级强监管的要求之下,无论是“两地三中心”还是数据的容灾备份等要求,使得金融级的分布式数据库不断在数据安全方面进行创新。
未来,分布式数据库作为数据管理的最核心枢纽,也将不断提高数据安全、数据可用性方面的功能。通过双活、多活以及高可用灾备等机制不断创新,数据库安全将会提升一个新的台阶。

一场针对数据库与运维的沉浸式学习,
一众聚焦前沿新技术的大牛汇集,
2018 Gdevops全球敏捷运维峰会北京站
用实战凝练精华,用创新武装头脑,
盛会重磅来袭!
↓↓↓ 点击链接了解更多详情 ↓↓↓