细水长flow之f-VAEs:Glow与VAEs的联姻

作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
前言:这篇文章是我们前几天挂到 arXiv 上的论文的中文版。在这篇论文中,我们给出了结合流模型(如前面介绍的 Glow)和变分自编码器的一种思路,称之为 f-VAEs。理论可以证明 f-VAEs 是囊括流模型和变分自编码器的更一般的框架,而实验表明相比于原始的 Glow 模型,f-VAEs 收敛更快,并且能在更小的网络规模下达到同样的生成效果。
■ 论文 | f-VAEs: Improve VAEs with Conditional Flows
■ 链接 | https://www.paperweekly.site/papers/2313
■ 作者 | Jianlin Su / Guang Wu
近来,生成模型得到了广泛关注,其中变分自编码器(VAEs)和流模型是不同于生成对抗网络(GANs)的两种生成模型,它们亦得到了广泛研究。然而它们各有自身的优势和缺点,本文试图将它们结合起来。

▲ 由f-VAEs实现的两个真实样本之间的线性插值
基础
设给定数据集的证据分布为,生成模型的基本思路是希望用如下的分布形式来拟合给定数据集分布:

其中 q(z) 一般取标准高斯分布,而 q(x|z) 一般取高斯分布(VAEs 中)或者狄拉克分布(GANs 和流模型中)。理想情况下,优化方式是最大化似然函数 E[logq(x)],或者等价地,最小化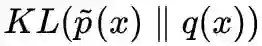
由于积分可能难以显式计算,所以需要一些特殊的求解技巧,这导致了不同的生成模型。其中,VAE 引入后验分布 p(z|x),将优化目标改为更容易计算的上界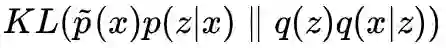
而在流模型中,q(x|z)=δ(x−G(z)),并精心设计 G(z)(通过流的组合)直接把这个积分算出来。流模型的主要组件是“耦合层”:首先将 x 分区为两部分 x1,x2,然后进行如下运算:

这个变换是可逆的,逆变换为:

它的雅可比行列式是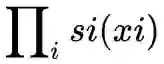
由于直接算出来积分,因此流模型可以直接完成最大似然优化。最近发布的 Glow 模型显示出强大的生成效果,引起了许多人的讨论和关注。但是流模型通常相当庞大,训练时间长(其中 256 x 256 的图像生成模型用 40 个 GPU 训练了一周,参考这里 [1] 和这里 [2]),显然还不够友好。
分析
VAEs 生成图像模糊的解释有很多,有人认为是 mse 误差的问题,也有人认为是 KL 散度的固有性质。但留意到一点是:即使去掉隐变量的 KL 散度那一项,变成普通的自编码器,重构出来的图像通常也是模糊的。这表明,VAEs 图像模糊可能是低维重构原始图像的固有问题。
如果将隐变量维度取输入维度一样大小呢?似乎还不够,因为标准的 VAE 将后验分布也假设为高斯分布,这限制了模型的表达能力,因为高斯分布簇只是众多可能的后验分布中极小的一部分,如果后验分布的性质与高斯分布差很远,那么拟合效果就会很糟糕。
那 Glow 之类的流模型的问题是什么呢?流模型通过设计一个可逆的(强非线性的)变换将输入分布转化为高斯分布。在这个过程中,不仅仅要保证变换的可逆性,还需要保证其雅可比行列式容易计算,这导致了“加性耦合层”或“仿射耦合层”的设计。然而这些耦合层只能带来非常弱的非线性能力,所以需要足够多的耦合层才能累积为强非线性变换,因此 Glow 模型通常比较庞大,训练时间较长。
f-VAEs
我们的解决思路是将流模型引入到 VAEs 中,用流模型来拟合更一般的后验分布 p(z|x) ,而不是简单地设为高斯分布,我们称之为 f-VAEs(Flow-based Variational Autoencoders,基于流的变分自编码器)。
相比于标准的 VAEs,f-VAEs 跳出了关于后验分布为高斯分布的局限,最终导致 VAEs 也能生成清晰的图像;相比于原始的流模型(如 Glow),f-VAEs 的编码器给模型带来了更强的非线性能力,从而可以减少对耦合层的依赖,从而实现更小的模型规模来达到同样的生成效果。
推导过程
我们从 VAEs 的原始目标出发,VAEs 的 loss 可以写为:
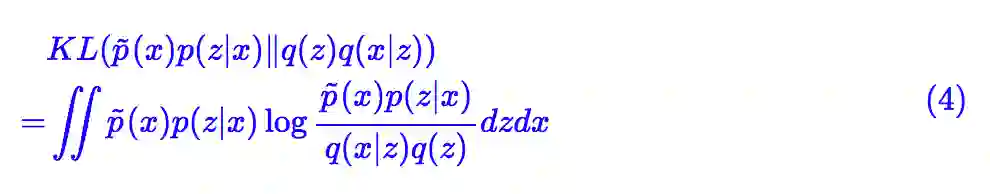
其中 p(z|x),q(x|z) 都是带参数的分布,跟标准 VAEs 不同的是,p(z|x) 不再假设为高斯分布,而是通过流模型构建:
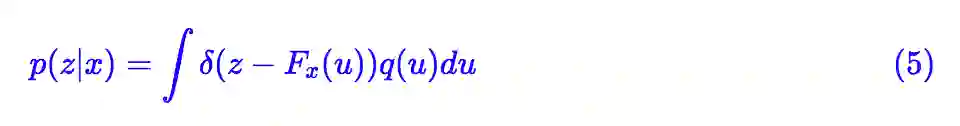
这里 q(u) 是标准高斯分布,Fx(u) 是关于 x,u 的二元函数,但关于 u 是可逆的,可以理解为 Fx(u) 是关于 u 的流模型,但它的参数可能跟 x 有关,这里我们称为“条件流”。代入 (4) 计算得到:
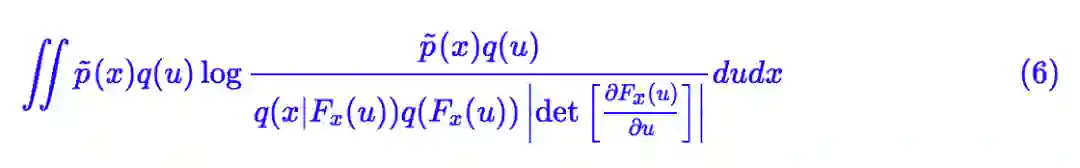
这便是一般的 f-VAEs 的 loss,具体推导过程请参考下面的注释。
联立 (4) 和 (5),我们有:
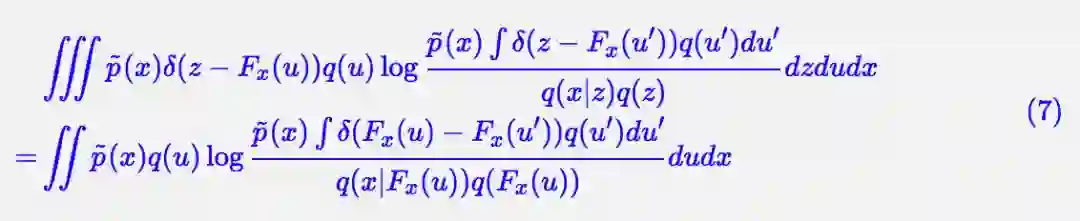
设 v=Fx(u′),u′=Hx(v),对于雅可比行列式,我们有关系:
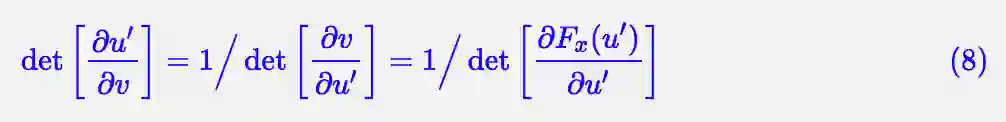
从而 (7) 变成:

两个特例
式 (6) 描述了一般化的框架,而不同的 Fx(u) 对应于不同的生成模型。如果我们设:

那么就有:
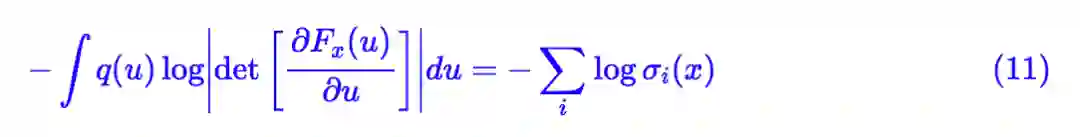
以及:
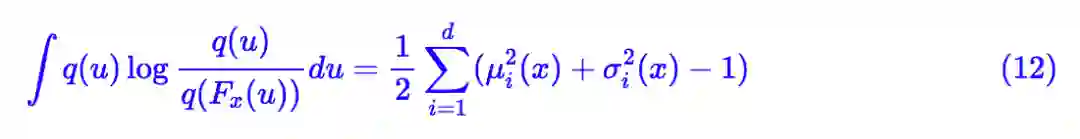
这两项组合起来,正好是后验分布和先验分布的 KL 散度;代入到 (6) 中正好是标准 VAE 的 loss。意外的是,这个结果自动包含了重参数的过程。
另一个可以考察的简单例子是:
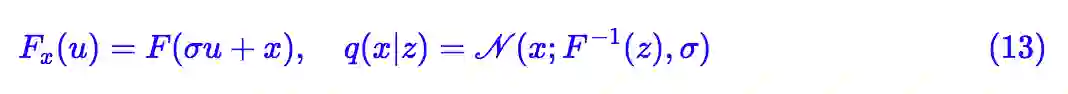
其中 σ 是一个小的常数,而F是任意的流模型,但参数与 x 无关(无条件流)。这样一来:
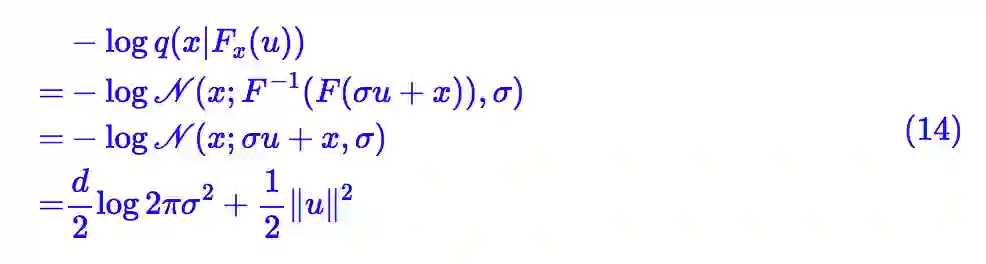
所以它并没有包含训练参数。这样一来,整个 loss 包含训练参数的部分只有:
这等价于普通的流模型,其输入加上了方差为的高斯噪声。有趣的是,标准的 Glow 模型确实都会在训练的时候给输入图像加入一定量的噪声。
我们的模型
上面两个特例表明,式 (6) 原则上包含了 VAEs 和流模型。 Fx(u) 实际上描述了 u, x 的不同的混合方式,原则上我们可以选择任意复杂的 Fx(u) ,来提升后验分布的表达能力,比如:
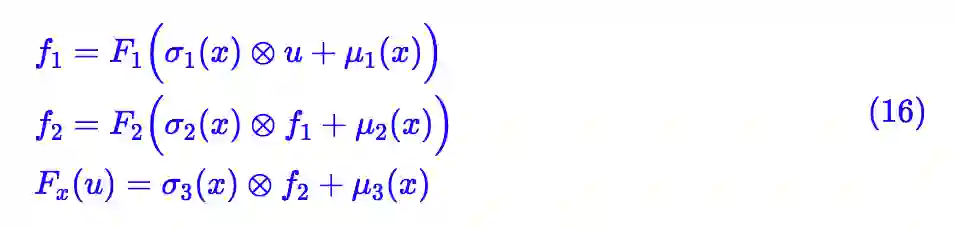
这里的 F1,F2 是无条件流。
同时,到目前为止,我们并没有明确约束隐变量 z 的维度大小(也就是 u 的维度大小),事实上它是一个可以随意选择的超参数,由此我们可以训练更好的降维变分自编码模型。但就图像生成这个任务而言,考虑到低维重构会导致模糊的固有问题,因此我们这里选择 z 的大小跟 x 的大小一致。
出于实用主义和简洁主义,我们把式 (13) 和 (10) 结合起来,选择:

其中 σ1,σ2 都是待训练参数(标量即可),E(⋅),G(⋅) 是待训练的编码器和解码器(生成器),而F (⋅) 是参数与 x 无关的流模型。代入 (6),等效的 loss 为:
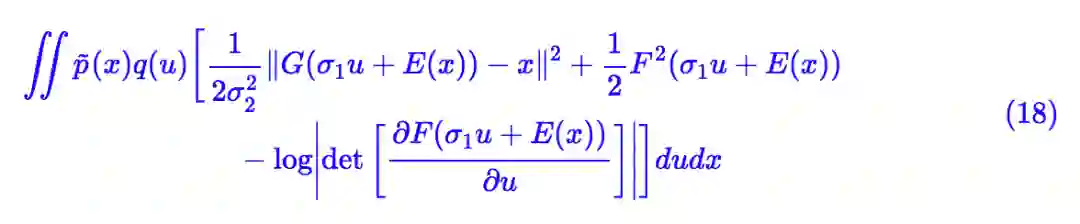
而生成采样过程为:
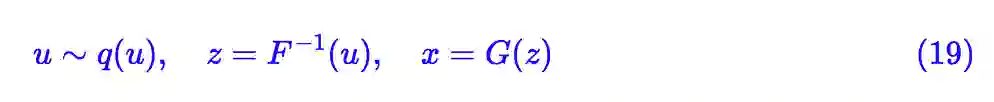
相关
事实上,流模型是一大类模型的总称。除了上述以耦合层为基础的流模型(NICE、RealNVP、Glow)之外,我们还有“自回归流(autoregressive flows)”,代表作有 PixelRNNs 和 PixelCNNs 等。自回归流通常效果也不错,但是它们是逐像素地生成图片,无法并行,所以生成速度比较慢。
诸如 RealNVP、Glow 的流模型我们通常称为 Normalizing flows(常规流),则算是另外一种流模型。尤其是 Glow 出来后让这类流模型再次火了一把。事实上,Glow 生成图片的速度还是挺快的,就是训练周期太长了,训练成本也很大。
据我们了解,首次尝试整合 VAEs 和模型的是 Variational Inference with Normalizing Flows [3],后面还有两个改进工作 Improving Variational Inference with Inverse Autoregressive Flow [4] 和 Variational Lossy Autoencoder [5]。其实这类工作(包括本文)都是类似的。不过前面的工作都没有导出类似 (6) 式的一般框架,而且它们都没有在图片生成上实现较大的突破。
目测我们的工作是首次将 RealNVP 和 Glow 的流模型引入到 VAEs 中的结果。这些“流”基于耦合层,容易并行计算。所以它们通常比自回归流要高效率,可以堆叠得很深。同时我们还保证隐变量维度跟输入维度一样,这个不降维的选择也能避免图像模糊问题。
实验
受 GPU 设备所限,我们仅仅在 CelebA HQ 上做了 64x64 和 128x128 的实验。我们先在 64x64 图像上对类似规模的 VAEs、Glow 和 f-VAEs 做了个对比,然后再详细展示了 128x128 的生成效果。
实验流程
首先,我们的编码器 E(⋅) 是卷积和 Squeeze 算子的堆叠。具体来说, E(⋅) 由几个 block 组成,并且在每个 block 之前都进行一次 Squeeze。而每个 block 由若干步复合而成,每步的形式为 x+CNN(x) ,其中 CNN(x) 是 3x3 和 1x1 的卷积组成。具体细节可以参考代码。
至于解码器(生成器)G (⋅) 则是卷积和 UnSqueeze 算子的堆叠,结构上就是 E(⋅) 的逆。解码器的最后可以加上 tanh(⋅) 激活函数,但这也不是必须的。而无条件流 F(⋅) 的结果是照搬自 Glow 模型,只不过没有那么深,卷积核的数目也没有那么多。
源码(基于Keras 2.2 + Tensorflow 1.8 + Python 2.7):
https://github.com/bojone/flow/blob/master/f-VAEs.py

实验结果
对比 VAEs 和 f-VAEs 的结果,我们可以认为 f-VAEs 已经基本解决了 VAEs 的模糊问题。对于同样规模下的 Glow 和 f-VAEs,我们发现 f-VAEs 在同样的 epoch 下表现得更好。当然,我们不怀疑 Glow 在更深的时候也表现得很好甚至更好,但很明显,在同样的复杂度和同样的训练时间下,f-VAEs 有着更好的表现。

f-VAEs 在 64x64 上面的结果,只需要用 GTX1060 训练约 120-150 个 epoch,大概需要 7-8 小时。
准确来说,f-VAEs 的完整的编码器应该是 F(E(⋅)),即 F 和 E 的复合函数。如果在标准的流模型中,我们需要计算 E 的雅可比行列式,但是在 f-VAEs 中则不需要。所以 E 可以是一个普通的卷积网络,它可以实现大部分的非线性,从而简化对流模型 F 的依赖。
下面是 128x128 的结果(退火参数 T 指的是先验分布的方差)。128x128 的模型大概在 GTX1060 上训练了 1.5 天(约 150 个 epoch)。
随机采样结果

隐变量线性插值
▲ 两个真实样本之间的线性插值

退火参数影响

总结
文章综述
事实上,我们这个工作的原始目标是解决针对 Glow 提出的两个问题:
如何降低 Glow 的计算量?
如何得到一个“降维”版本的 Glow?
我们的结果表明,一个不降维的 f-VAEs 基本相当于一个迷你版本的 Glow,但是能达到较好的效果。而式 (6) 确实也允许我们训练一个降维版本的流模型。我们也从理论上证明了普通的 VAEs 和流模型自然地包含在我们的框架中。因此,我们的原始目标已经基本完成,得到了一个更一般的生成和推断框架。
未来工作
当然,我们可以看到随机生成的图片依然有一种油画的感觉。可能的原因是模型还不够复杂,但我们猜测还有一个重要原因是 3x3 卷积的“滥用”,导致了感知野的无限放大,使得模型无法聚焦细节。
因此,一个挑战性的任务是如何设计更好的、更合理的编码器和解码器。看起来 Network in Network 那一套会有一定的价值,还有 PGGAN 的结构也值得一试,但是这些都还没有验证过。
参考文献
[1]. https://github.com/openai/glow/issues/14#issuecomment-406650950
[2]. https://github.com/openai/glow/issues/37#issuecomment-410019221
[3]. Rezende, Danilo Jimenez, and Shakir Mohamed. Variational inference with normalizing flows. arXiv preprint arXiv:1505.05770, 2015.
[4]. D.P. Kingma, T. Salimans, R. Jozefowicz, I. Sutskever, M. Welling. Improving Variational Autoencoders with Inverse Autoregressive Flow. Advances in Neural Information Processing Systems 29 (NIPS), Barcelona, 2016
[5]. X. Chen, D.P. Kingma, T. Salimans, Y. Duan, P. Dhariwal, J. Schulman, I. Sutskever, P. Abbeel. Variational Lossy Autoencoder. The International Conference on Learning Representations (ICLR), Toulon, 2017

点击以下标题查看作者其他文章:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看作者博客



