RL中的default policy 和 decision states 及 options(skill)是什么关系?
最近几篇论文都提出了学习一个默认的减轻认知负担的default policy;就像人默认情况直走即可,特殊情况才需要调整:有人,有车,有拐弯等;特殊情况就是decision states,这些情况下面需要重新决策切换行动的方式,要停下还是拐弯等;
default policy 和 decision states 及 options(skill)是什么关系?
default policy就是没有关键状态出现的时候的默认行为;离开default policy的时候就说出现了特殊情况,出现了decison states(sor bottleneck states 区别见后面);然后执行的skill也发生了变化;skill 切换执行
decison states=决策状态 类似关键状态
这几篇论文的关键公式分别如下:
1 deepmind kl default policy:
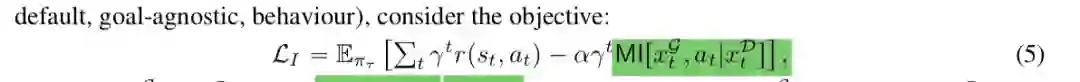
这里目标和动作的互信息要尽量小,动作基本和目标没什么关系,所以是default policy;下面的infobot也是目标和动作的互信息要尽量小;
动作尽量和目标没有什么关系,只有在出现目标或关键状态的时候动作和目标才有一定的互信息。
2 infobot:

上面都是基于目标监督学习的,下面一篇是无监督学习decision states
3 ds-vis:empowerment skill options类似第四篇dads
empowerment是要学习一个尽可能可靠的动作,执行动作尽量达到期望的结果,动作和结果states互信息要尽量大;

ds-vis是学习一个高层的动作抽象skill:语义级别的动作类似直行,跑,跳等语义动作,这里的约束是高层的skill动作和强化学习底层的action要尽量的互信息最小,论文解释是:选择skill不需要太多思考;作者的介绍没有看明白;而且可以进一步通过互信息高低确定决策状态;
技能skill和action的互信息小指的是skill是以action最方便的方式组合在一起?比如直行就是相同动作的持续repeat;拐弯是某一个角度的转弯动作的持续repeat,组成skill的action是 I(skill;action|s)两者互信息最小;
从互信息的熵的分解解读一下
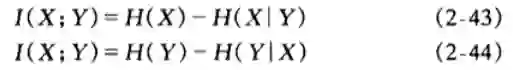
I(skill;action)=H(action)-H(action|skill)这个不好解释 = H(skill)-H(skill|action) 即skill熵小,skill的多样性尽量少;但是基于action的skill尽量多元化,多样化;
可用的总的skill不多,但是尽量覆盖到尽可能多的情况;
论文里面的一个解释可以类比看看:

上面的意思是基于某个skill的结果是可控的,可以预测的,reliable reachable;即empowerment
dads的action states解读也可以类比看看:也是上面的意思,动作以可控可预测的方式到达很多状态;

上面skill和action的互信息最小和下面dads的第二项基本一样,下面dads的I(a;(st,z))
4 dads skill options;

4 dads connect empowerment;
上面熵分解类似的一个dads的公式:

这里对互信息的两种分解都做了解释:当前状态有很多动作可以选择,当前状态可以到达很多其他状态
基于前后状态中间的动作或skill是尽可能确定;基于状态和动作,结果尽可能确定;
这两个解释和EMI的两个互信息式子的EMI论文解释是对应的

decision states 区别 bottleneck states



default policy 和 decision states 及 options(skill)是什么关系你搞懂了吗?
欢迎加入我们!更多内容请访问公众号CreateAMind菜单。
更多理论公式可以参考原论文,这里附几篇论文的简单内容:
dads:
Dynamics-Aware Unsupervised Discovery of Skills 笔记 v2
infobot:
infobot paper:


paper:
INFORMATION ASYMMETRY IN KL-REGULARIZED RL


paper:
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning


欢迎加入我们,更多内容请访问公众号CreateAMind菜单。



