大数据杀熟背后,是我们裸奔的隐私

作者 | 汉阳树
数据支持 | 勾股大数据

最近发生了一件令人气愤的事情。
我一般出差都是选择一个固定品牌的酒店,称之为A酒店吧,因为感觉价格合适,质量又比较稳定。久而久之,每到一个地方,我都会通过手机中某个APP选择附近的A酒店,因为每次在APP中显示的价格波动不大,便没有多留意。
但是上次通过手机订好房间后,到了酒店大堂,发现这里有显示实时房间价格的电子显示屏,不知道你们有没有注意到,很多酒店都并没有这种装置。看到电子屏相同的标准间比我订的价格便宜很多,我好奇是不是由于下单的时间原因,但在反复对比后,我发现并不是,我用app订的价格就是贵了一些,而前台客服的手机APP里显示的价格就明显低了很多。
我问了我身边的朋友们,发现针对老用户收更高价格的现象并不少见——上班族们往返打车的路段往往会比不常在此路段打车的人收费更高;反复搜索某个型号商品后会发现商品的价格在逐渐上涨,选择越来越少;甚至于部分购物网站会搜集不经常给评论或者很少给出差评的数据,进而商家可以利用这些数据向他们发出质量较次的产品。
如今有一个名词来描述这种现象——大数据杀熟。

1
杀熟的背后,信息泄露日益普遍
而大数据杀熟别后,反映的不过是日益严重的个人信息泄漏现实的冰山一角。
通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌,称之为用户画像。用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息。
在知乎“信息泄露可以有多恐怖?”话题下面有5000多条回答和6000多万的浏览量。
如果你曾经使用过支付宝或者微信的消费贷,那么你大概率会隔三差五地接到各种小额贷款的短信或者电话;如果最近曾将开过股票账户的话,你估计最近会收到很多配资的短信;连你自己都忘记何时注册了一个在线学习英语的账户,但是你仍然会频繁地受到各种推销电话的骚扰。
2
到底是谁泄露了我们的信息
我用一个陌陌软件的安装过程来举例APP会获取我们什么信息以及怎样获取信息。
在应用市场搜索陌陌后,在应用详情介绍下的应用权限项里,可以看到系统显示该应用获取了14个敏感隐私权限。

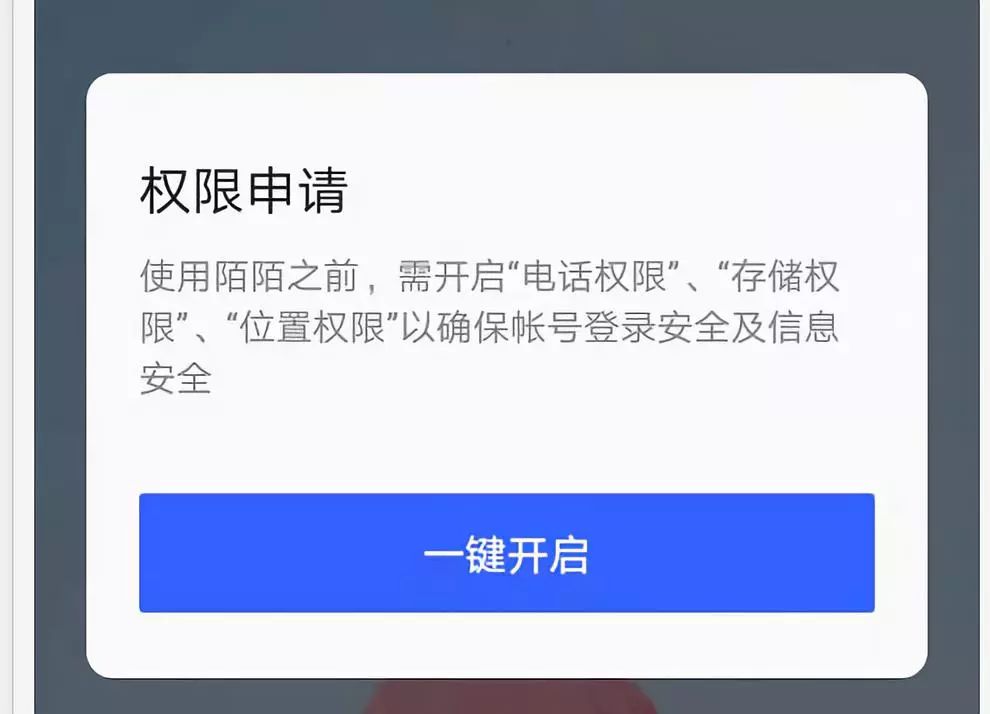
当然有人会说你可以在安装过程中不接受啊。在我实际安装过程中,首先弹出来的页面就是下面这个,没有不接受选项。在选择一键开启之后,会一一显示是否接受这三个选项的界面,如果不接受的话就不能启动陌陌。所以这三个是必须接受的,当然作为一款社交软件,这个是可以接受的。
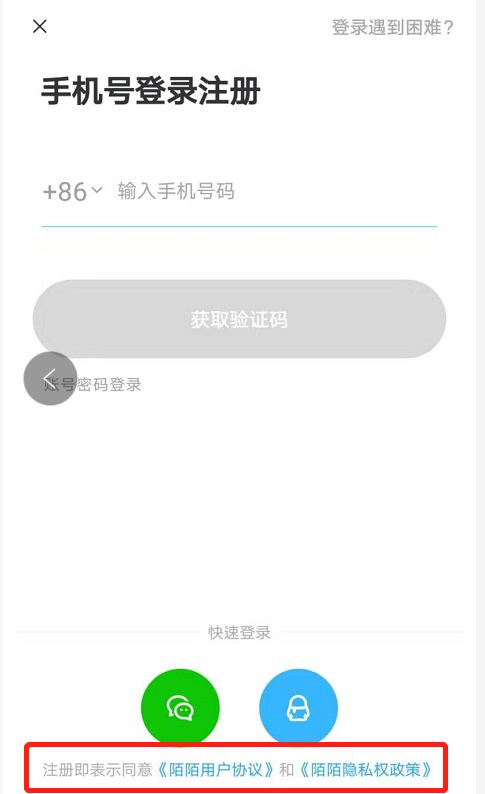
接下来进入手机登录页面,当然你也可以选择微信或者qq登录,当时你仍然要绑定手机号。这里最关键的就是最下面这一行不起眼的小字:注册即表示同意《陌陌用户协议》和《默默隐私权政策》。
分别点开之后,《陌陌用户协议》共计10791个字,《陌陌隐私政策》共计8674字。我分别在其中截取了一些内容:

最后陌陌还保留了最终解释权。

陌陌在该处详细列举了用户信息的收集和使用:

如:

除了以上这些较为容易理解的条款之外,协议中还有大量很多普通人难以理解的条款。一般人注册这些账号时,很少会关注这些隐私协议,基本都是秒按同意安装。在这个过程中,你也就是默认了商家对你的诸多信息进行采集和利用。
目前绝大多数APP都有这种隐含的协议,搜索软件、购物软件、社交软件、地图软件、听歌软件,我们在接受算法带来的更好的使用体验时,放弃的是我们部分的隐私权作为代价。有些放弃也许是我们愿意的,有些放弃是被迫的,或者是不知不觉的。
除了这种通过单个APP内数据的采集信息的方式,还有一种是基于设备的采集方式。一些第三方数据服务公司通过各种开发者服务的SDK嵌入在各类APP中,通过各种各样的APP获取海量的和提供服务息息相关的匿名设备行为数据。
对比之下,其他APP收集到的用户信息仅仅是该领域内的信息,例如汽车类APP往往收集到的仅仅是用户与“汽车”相关的信息,美妆类APP往往收集到的仅仅是用户与“化妆品”相关的信息,在APP所针对的领域之外,用户的其他信息都是模糊的。
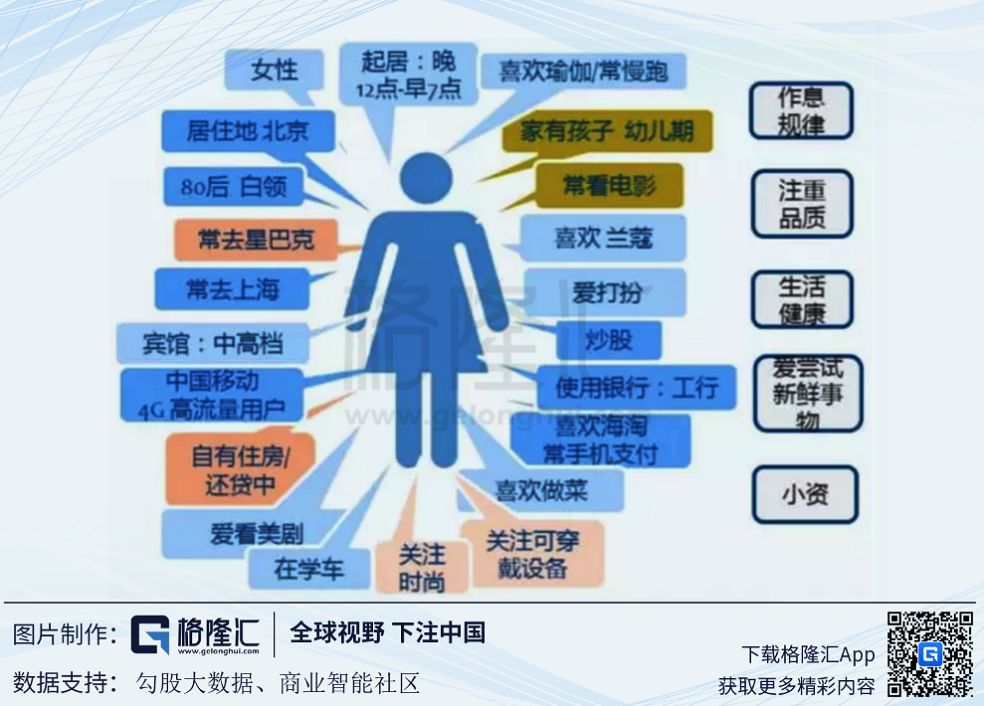
但是这种基于设备的采集方式,通过一定的人工智能,机器学习,算法加工等,就能大概勾画出这个手机设备持有者的一些特征和行为标签,并建立立体的、精准的用户画像。例如手机中装了一堆美妆APP、大姨妈监测软件、链家和安居客等软件,且经常打开海淘软件的用户,大概率是一个打算买房的消费水平较高的女性,用户画像十分立体。
3
如何形成用户画像
以上所说的仍然只是信息的采集,就好比是原材料,通过海量数据提取出真金白银,最后形成具有商业价值的特征数据,这需要考验数据公司的大数据处理和分析技术,而不同的技术能够产生的数据精度存在很大的差距。
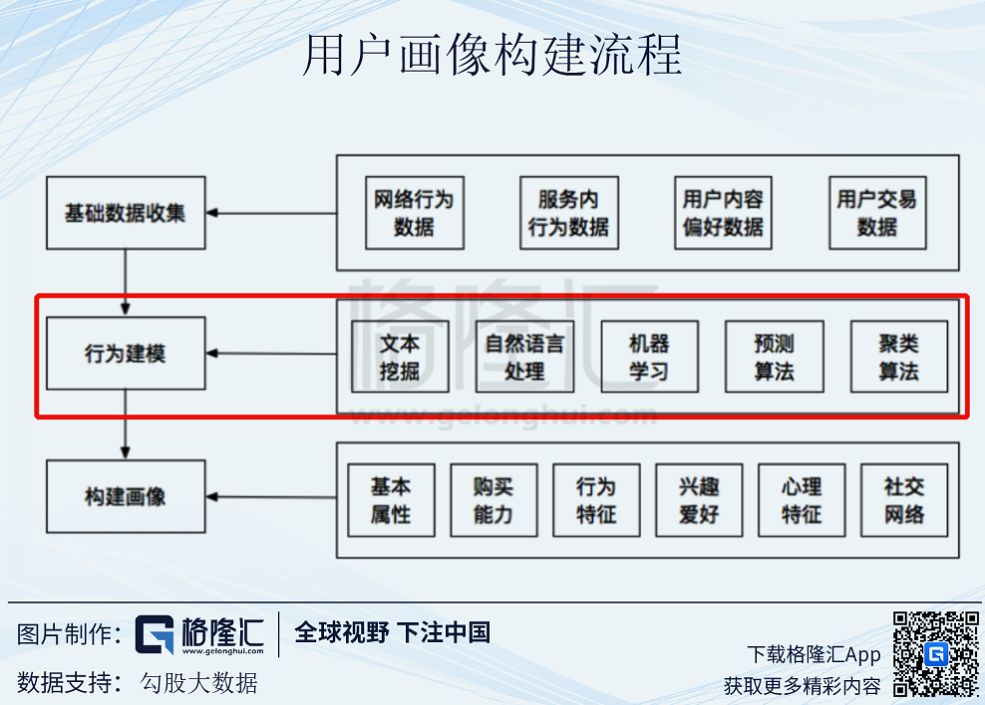
用户画像构建流程主要包括三部分:基础数据收集、行为建模和构建画像。其中数据处理的差异就体现在行为建模这一环中。
在行为建模这一过程中,需要抽象出能够代表实物的一些典型特征,对于人类来说,比如身高、体重、肤色、眼睛大小等等。然后通过机器学习的方法,构建一个类似于Y=kX+b的算法,其中X代表已知信息,Y代表用户画像,通过不断的精确k和b来精确Y。
我们通过网易云音乐来介绍建模过程。相信很多人都知道网易云音乐会根据你之前的听歌习惯来给你推荐新的歌曲,在这背后,也是由算法来支持的,而且这种算法也在持续的改进,最终推荐的歌曲也会越来越满足特定用户的口味。
这里尝试介绍一种简单的算法,其核心是数学中的“多维空间中两个向量夹角的余弦公式”。此处引用了知乎“网易云音乐的歌单推荐算法是怎样的?”下邰原朗的回答:
以三首歌来举例子,《最炫民族风》,《晴天》,《Hero》。
A,收藏了《最炫民族风》,而遇到《晴天》,《Hero》则总是跳过;
B,经常单曲循环《最炫民族风》,《晴天》会播放完,《Hero》则拉黑了
C,拉黑了《最炫民族风》,而《晴天》《Hero》都收藏了。
这里可以看出,A,B二位品味接近,C和他们很不一样。那么问题来了,说A,B相似,到底有多相似,如何量化?
我们把三首歌想象成三维空间的三个维度,《最炫民族风》是x轴,《晴天》是y轴,《Hero》是z轴,对每首歌的喜欢程度即该维度上的坐标,并且对喜欢程度做量化(比如: 单曲循环=5, 分享=4, 收藏=3, 主动播放=2 , 听完=1, 跳过=-1 , 拉黑=-5 )。
那么每个人的总体口味就是一个向量,A君是 (3,-1,-1),B君是(5,1,-5),C君是(-5,3,3)。我们可以用向量夹角的余弦值来表示两个向量的相似程度, 0度角(表示两人完全一致)的余弦是1, 180度角(表示两人截然相反)的余弦是-1。
根据余弦公式, 夹角余弦 = 向量点积/ (向量长度的叉积) = ( x1x2 + y1y2 + z1z2) / ( 跟号(x1平方+y1平方+z1平方 ) x 跟号(x2平方+y2平方+z2平方 ) )。 A君B君夹角的余弦是0.81 , A君C君夹角的余弦是 -0.97。
以上是三首歌的情况,对于多首歌也可以进行如法炮制,建立N维N首歌的坐标系。以上的思想核心就是,一个和你听歌习惯特别相似的人,那么他喜欢听的其他歌也大概率是你喜欢听的歌。这是建立在以人为本的基础上。
还有一种思想是建立在以物为本的基础上,简单说,就是买了X物品的人,一般都会买Y。比如网易云音乐新来了一个用户D,只知道她喜欢最炫民族风,那么问题来了,给她推荐啥好呢?
如下图,数字代表对某首歌的好感度。通过将A/B/C三人对最炫民族风和其他两首歌的好感度之差求平均,得出一般人对这些歌好感度差值的平均值。最后求出D对于另外两首歌的好感度。
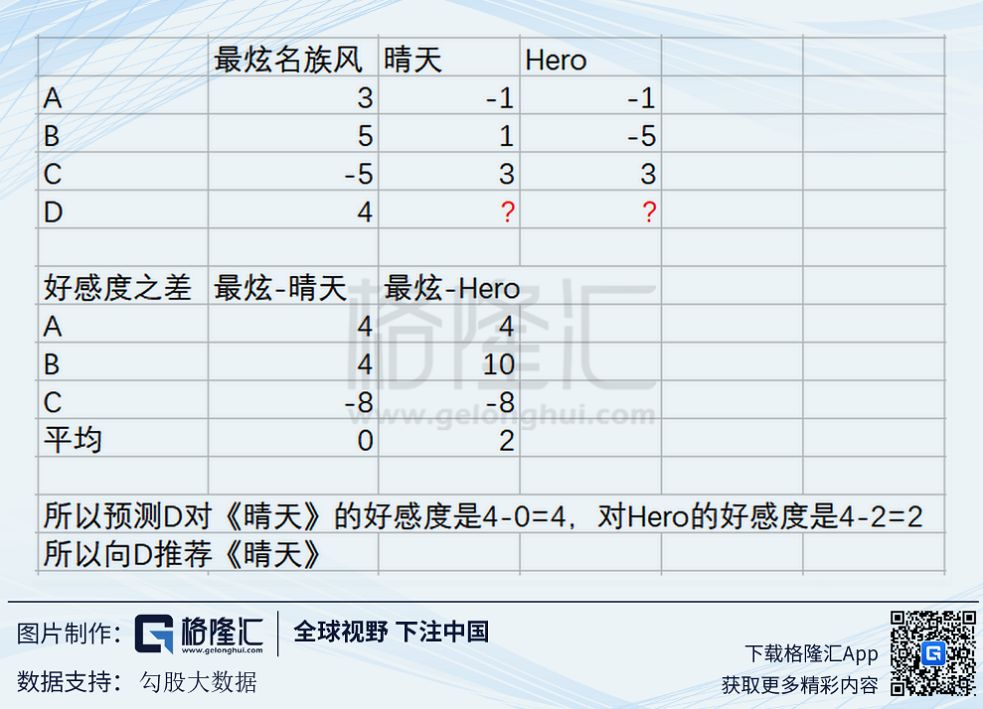
现实中,由于数量量更大,算法也更加复杂,所以最后得出的预测值精度也会更好。同样的,也有海量的模型用于预测其他类型的用户特征。
4
我们能保护我们的隐私吗?
在浏览器中搜索“如何保护隐私”,我们可以得到大量保护隐私的技巧,比如说不在公共区域登录wifi,及时清除上网数据,在安装手机APP时注意有没有不合理的隐私获取请求、远离那些测试自己的心理年龄爱情运势的小网站等等。
然而网络的发达和各种手机应用的兴起本质是服务我们的生活,如今我们为了保护隐私反而不得不小心谨慎,这必然是舍本逐末的。再者,就算你小心谨慎,你采取的这些防护措施在多大程度上真的可以保护你的隐私?
前段时间的一篇爆款文章《为什么我的儿子不沉迷游戏?》,讲的是一个资深游戏策划现身说法如何让孩子不沉迷游戏。在文中,作者提到商业化的网络游戏,都是为让玩家沉迷所设计的。每一个爆款游戏背后都是成百上千的经验丰富的工程师、游戏策划甚至心理学家,在反复揣摩怎样将游戏设计的让人上瘾,游戏产品也在持续反复迭代。
势单力薄的个人该如何与这种精心设计的诱惑向对抗?同样的,数据公司也会绞尽脑汁地采用新的技术来采集你的数据,你们两者根本就不在同一个维度。
26年前《纽约客》封面的漫画上,洋洋得意地宣扬“在互联网上,没人知道你是一条狗”。

然而26年的今天,利用大数据,你是黑是白、住在什么地方、吃什么牌子的狗粮、喜欢在哪里散步这些都是可以获取的。
在庞大的数据面前,人类越来越像一个提供输入的变量角色。你使用的APP,正在试图了解和定义你。







