【深度学习】深度学习的起源、发展和现状
1、深度学习的起源
人工智能(Artificial Intelligence)就像长生不老和星际漫游一样,是人类最美好的梦想之一。虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。计算机能够具有人的意识起源于图灵测试(Turing Testing)问题的产生,由“计算机科学之父”及“人工智能之父”英国数学家阿兰·图灵在1950年的一篇著名论文《机器会思考吗?》里提出图灵测试的设想:
把一个人和一台计算机分别隔离在两间屋子,然后让屋外的一个提问者对两者进行问答测试。如果提问者无法判断哪边是人,哪边是机器,那就证明计算机已具备人的智能。

但是半个世纪过去了,人工智能的进展,远远没有达到图灵试验的标准。这不仅让多年翘首以待的人们心灰意冷,认为人工智能是忽悠,相关领域是“伪科学”。直到深度学习(Deep Learning)的出现,让人们看到了一丝曙光。至少,图灵测试已不再是那么遥不可及了。2013年4月,《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术之首。
了解深度学习的起源,首先让我们先来了解一下人类的大脑是如何工作的。1981年的诺贝尔医学奖,分发给了David Hubel、Torsten Wiesel和Roger Sperry。前两位的主要贡献是,发现了人的视觉系统的信息处理是分级。如图1所示,从视网膜(Retina)出发,经过低级的V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层V4的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化。
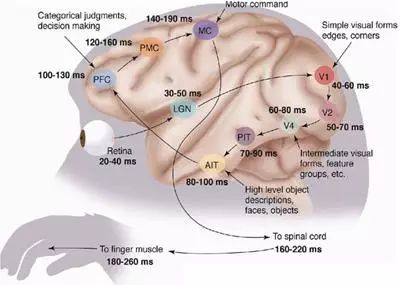
图1 人的视觉处理系统
这个发现激发了人们对于神经系统的进一步思考。大脑的工作过程,是一个对接收信号不断迭代、不断抽象概念化的过程,如图2所示。例如,从原始信号摄入开始(瞳孔摄入像素),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定眼前物体的形状,比如是椭圆形的),然后进一步抽象(大脑进一步判定该物体是张人脸),最后识别人脸。这个过程其实和我们的常识是相吻合的,因为复杂的图形,往往就是由一些基本结构组合而成的。同时我们还可以看出:大脑是一个深度架构,认知过程也是深度的。

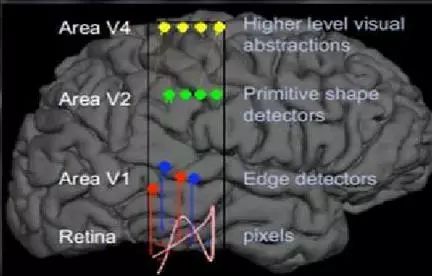
图2 视觉系统分层处理结构
而深度学习,恰恰就是通过组合低层特征形成更加抽象的高层特征(或属性类别)。例如,在计算机视觉领域,深度学习算法从原始图像去学习得到一个低层次表达,例如边缘检测器、小波滤波器等,然后在这些低层次表达的基础上,通过线性或者非线性组合,来获得一个高层次的表达。此外,不仅图像存在这个规律,声音也是类似的。
2深度学习的发展
2.1从感知机到神经网络
2.1.1 感知机
1943年,心理学家Warren Mcculloch和数理逻辑学家Walter Pitts在合作的论文[7]中提出并给出了人工神经网络的概念及人工神神经元的数学模型,从而开创了人类神经网络研究的时代。
1949年,心理学家Donald Hebb在论文[8]中提出了神经心理学理论,Hebb认为神经网络的学习过程最终是发生在神经元之间的突触部位,突触的联结强度随着突触前后神经元的活动而变化,变化的量与两个神经元的活性之和成正比。
1956年,心理学家Frank Rosenblatt受到这种思想的启发,认为这个简单想法足以创造一个可以学习识别物体的机器,并设计了算法和硬件(如图3所示)。直到1957年,Frank Rosenblatt在《New York Times》上发表文章《Electronic ‘Brain’ Teaches Itself》,首次提出了可以模型人类感知能力的机器,并称之为感知机(Perceptron)[2]。

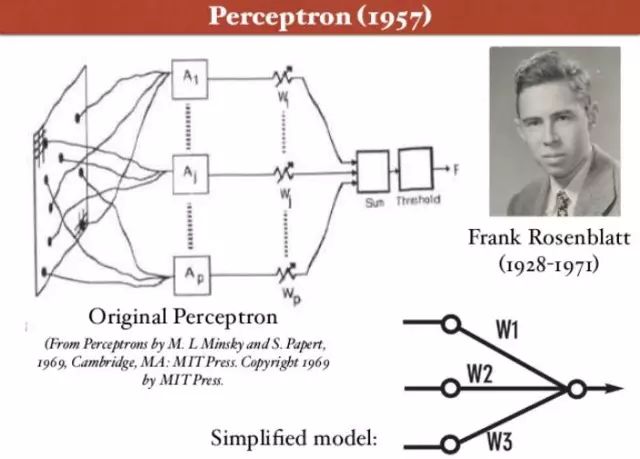
图3 Frank Rosenblatt和感知机的提出
感知机是有单层计算单元的神经网络,由线性元件及阈值元件组成。感知机的逻辑图如图4所示。
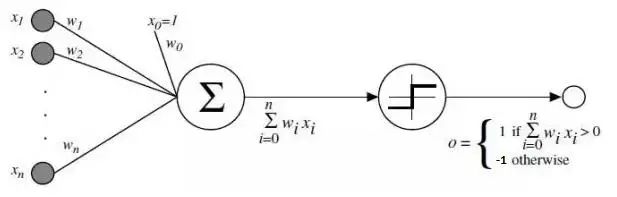
图4 感知机模型
Frank Rosenblatt对Hebb的理论猜想提出了数学论证方法:
感知机的数学模型( 是阈值):
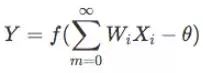
其中,f[.]是阶跃函数,并且有:
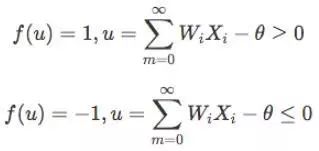
感知器的做大作用就是对输入的样本分类,故它可以作为分类器,感知器对输入信号的分类如下(A类,B类):
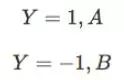
当感知器的输出为1时,输入样本为A类;输出为-1时,输入样本为B类。由此可知感知器的分类边界是:
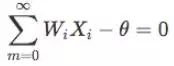
在输入样本只有两个分量x1和x2时,则分类边界条件:
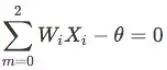
即:
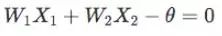
从坐标轴上表示如图5所示:
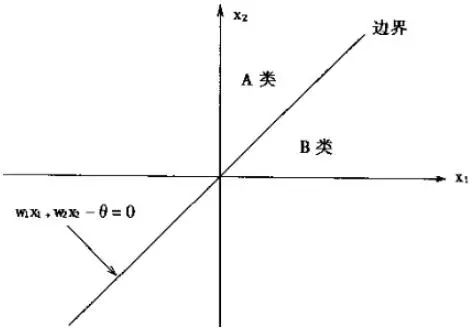
图5 感知机的二元线性分类
2.1.2感知机算法
感知机的学习算法:目的在于计算出恰当的权系数(w1,w2,…,wn),使系统对一个特定的样本(x1,x2,…,xn)能产生期望值d。
感知机学习算法步骤如下:
1) 对权系数设置初值;
2) 输入一个样本(x1,x2,…,xn)以及它的期望输出d;
3) 计算实际输出值:
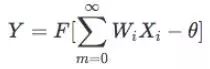
4) 根据实际输出求误差e:
e=d-Y
5) 用误差e去修改权系数:
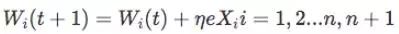
6) 转到第2步,一直执行到一切样本均稳定为止。
感知机是整个神经网络的基础,神经元通过激励函数确定输出,神经元之间通过权值进行传递能量,权重的确定根据误差来进行调节,这个方法的前景是整个网络是收敛的。这个问题,Frank Rosenblatt在1957年证明了这个结论。
有关感知机的成果,由Frank Rosenblatt在1958年发表在文章[9]里。1962年,他又出版了[10]一书,向大众深入解释感知机的理论知识及背景假设。此书介绍了一些重要的概念及定理证明,例如感知机收敛定理。
2.1.3 单层感知机的局限性
单层感知机仅对线性问题具有分类能力,即仅用一条直线可分的图形,如图6所示。还有逻辑“与”或逻辑“或”,采用一条直线分割0和1,如图7所示。
图6 线性可分问题
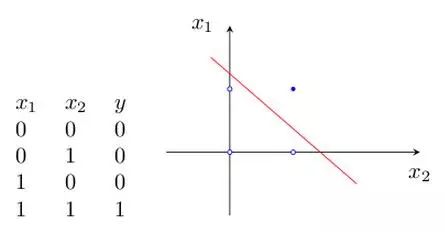
(a)逻辑“与”的真值表和二维样本图
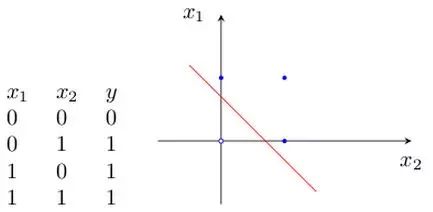
(b)逻辑“或”的真值表和二维样本图
图7逻辑“与”和“或”的线性划分
但是,如果让感知机解决非线性问题,单层感知机就无能为力了,如图8所示。例如,“异或”就是非线性运算,无法用一条直线分割开来,如图9所示。
图8 非线性不可分问题
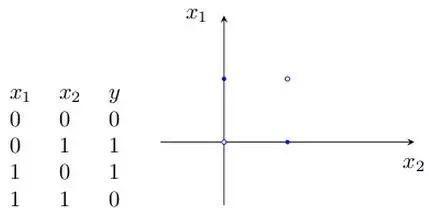
图9 逻辑“异或”的非线性不可分
2.1.4 多层感知机的瓶颈[3]
虽然,感知机最初被认为有着良好的发展潜能,但是感知机最终被证明不能处理诸多的模式识别问题。1969年,Marvin Minsky和Seymour Papery在[11]中,仔细分析了以感知机为代表的单层感知机在计算能力上的局限性,证明感知机不能解决简单的异或(XOR)等线性不可分问题,但Rosenblatt和Minsky及Papery等人在当时已经了解到多层神经网络能够解决线性不可分的问题。
既然一条直线无法解决分类问题,当然就会有人想到用弯曲的折线来分类样本,因此在单层感知机的输入层和输出层之间加入隐藏层,就构成了多层感知机,目的是通过凸域能够正确分类样本。多层感知机结构如图10所示。
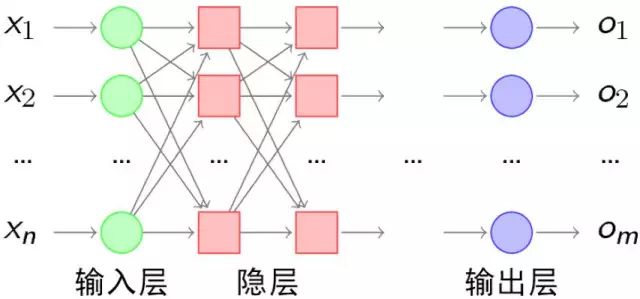
图10 多层感知机
对单层感知机和多层感知机的分类能力进行比较,如表1所示:
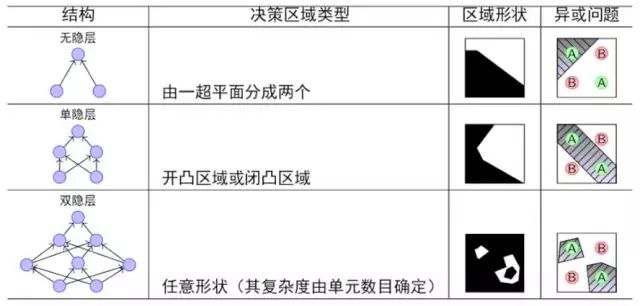
由表1可知,随着隐藏层的层数增多,凸域将可以形成任意的形状,因此可以解决任何复杂的分类问题。虽然多层感知机缺失是非常理想的分类器,但是问题也随之而来:隐藏层的权值怎么训练?对于各隐层的节点来说,它们并不存在期望输出,所以也无法通过感知机的学习规则来训练多层感知机。因此,多层感知机的训练也遇到了瓶颈,人工神经网络的发展进入了低潮期。
通过图11可见人工神经网络最初的发展史。1969年Marvin Minsky和Seymour Papery在[11]一书中提出了上述的感知机的研究瓶颈,指出理论上还不能证明将感知机模型扩展到多层网络是有意义的。这在人工神经网络的历史上书写了及其灰暗的一章。对于ANN的研究,始于1890年开始于美国心理学家W.James对于人脑结构与功能的研究,半个世纪后W.S.McCulloch和W.A.Pitts提出了M-P模型,之后的1958年Frank Rosenblatt在这个基础上又提出了感知机,此时对ANN的演技正处在升温阶段,[11]这本书的出现(1988有所更正并更名为[12])为这刚刚燃起的人工神经网络之火泼了一大盆冷水。一时间人们仿佛感觉以感知机为基础的ANN的研究突然走到尽头。于是,几乎所有为ANN提供的研究基金都枯竭了,很多领域的专家纷纷放弃了这方面课题的研究。
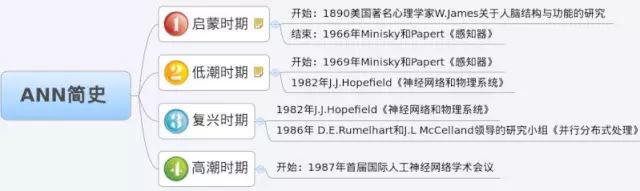
图11 ANN简史
2.1.5神经网络的崛起
真理的果实总是垂青于能够坚持研究的科学家。尽管ANN的研究陷入了前所未有的低谷,但仍有为数不多的学者致力于ANN的研究。直到1982年美国加州理工学院的物理学家John J.Hopfield博士提出的Hopfield网络和David E.Rumelhart以及James L.McCelland研究小组发表的《并行分布处理》。这两个成果重新激起了人们对ANN的研究兴趣,使人们对模仿脑信息处理的智能计 算机的研究重新充满了希望。
前者暂不讨论,后者对具有非线性连续变换函数的多层感知器的误差反向传播(Error Back Propagation)算法进行了详尽的分析,实现了 Minsky 关于多层网络的设想。误差反向传播即反向传播算法(Backpropagation algorithm,BP)[13]。
前面我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想:学习过程由信号的正向传播与误差的反向传播两个过程组成。如图12所示。
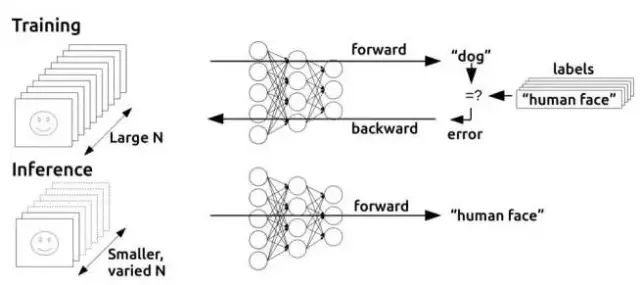
图12 反向传播的基本思想
1) 正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。
2) 反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
结合了BP算法的神经网络称为BP神经网络,BP神经网路模型中采用反向传播算法所带来的问题是:基于局部梯度下降对权值进行调整容易出现梯度弥散(Gradient Diffusion)现象,根源在于非凸目标代价函数导致求解陷入局部最优,而不是全局最优。而且,随着网络层数的增多,这种情况会越来越严重。这一问题的产生制约了神经网络的发展。
2.2 神经网络之后的又一突破—深度学习
直至2006年,加拿大多伦多大学教授Geoffrey Hinton对深度学习的提出以及模型训练方法的改进打破了BP神经网络发展的瓶颈。Hinton在世界顶级学术期刊《科学》上的一篇论文[1]中提出了两个观点:(1)多层人工神经网络模型有很强的特征学习能力,深度学习模型学习得到的特征数据对原始数据有更本质的代表性,这将大大便于分类和可视化问题;(2)对于深度神经网络很难训练达到最优的问题,可以采用逐层训练方法解决。将上层训练好的结果作为下层训练过程中的初始化参数。在这一文献中深度模型的训练过程中逐层初始化采用无监督学习方式。
值得一提的是,从感知机诞生到神经网络的发展,再到深度学习的萌芽,深度学习的发展并非一帆风顺。直到2006年,Geoffrey Hinton提出深度置信网(Deep Belief Net:DBN),其由一系列受限波尔兹曼机(Restricted Boltzmann Machine:RBM)[3]组成,提出非监督贪心逐层训练(Layerwise Pre-Training)算法,应用效果才取得突破性进展,其与之后Ruslan Salakhutdinov提出的深度波尔兹曼机(Deep Boltzmann Machine:DBM)[4]重新点燃了人工智能领域对于神经网络(Neural Network)和波尔兹曼机(Boltzmann Machine)[5]的热情,才由此掀起了深度学习的浪潮。从目前的最新研究进展来看,只要数据足够大、隐藏层足够深,即便不加“Pre-Training”预处理,深度学习也可以取得很好的结果,反映了大数据和深度学习相辅相成的内在联系。此外,虽说非监督(如DBM方法)是深度学习的一个优势,深度学习当然也可用于带监督的情况(也即给予了用户手动标注的机会),实际上带监督的卷积神经网络(Convolutional Neural Network:CNN)[6]方法目前就应用得越来越多,乃至正在超越DBM。
深度学习是一列在信息处理阶段利用非监督特征学习和模型分析分类功能的,具有多层分层体系结构的机器学习技术。深度学习的本质是对观察数据进行分层特征表示,实现将低级特征进一步抽象成高级特征表示。
深度学习可以分为三类:(1)生成型深度结构:生成型深度结构旨在模式分析过程中描述观察到的课件数据的高阶相关属性,或者描述课件数据和其相关类别的联合概率分布。由于不关心数据的标签,人们经常使用非监督特征学习。当应用生成模型结构到模式识别中时,一个重要的任务就是预训练。但是当训练数据有限时,学习较低层的网络是困难的。因此,一般采用先学习每一个较低层,然后在学习较高层的方式,通过贪婪地逐层训练,实现从底向上分层学习。属于生成型深度结构的深度学习模型有:自编码器、受限玻尔兹曼机、深度置信网络等。(2)判别型深度结构:判别型深度结构的目的是通过描述可见数据的类别的后验概率分布为模式分类提供辨别力。属于判别型深度结构的深度学习模型主要有卷积神经网络和深凸网络等。(3)混合型深度结构:混合型深度结构的目的是对数据进行判别,是一种包含了生成和判别两部分结构的模型。在应用生成型深度结构解决分类问题时,因为现有的生成型结构大多数都是用于对数据的判别,可以结合判别型模型在预训练阶段对网络的所有权值进行优化。例如通过深度置信网络进行预训练后的深度神经网络。
3 什么是深度学习
深度学习作为机器学习算法研究中的一个新的技术,其动机在于建立、模拟人脑进行分析学习的神经网络。深度学习是相对于简单学习而言的,目前多数分类、回归等学习算法都属于简单学习或者浅层结构,浅层结构通常只包含1层或2层的非线性特征转换层,典型的浅层结构有高斯混合模型(GMM)、隐马尔科夫模型(HMM)、条件随机域(CRF)、最大熵模型(MEM)、逻辑回归(LR)、支持向量机(SVM)和多层感知器(MLP)。(其中,最成功的分类模型是SVM,SVM使用一个浅层线性模式分离模型,当不同类别的数据向量在低维空间无法划分时,SVM会将它们通过核函数映射到高维空间中并寻找分类最优超平面。)浅层结构学习模型的相同点是采用一层简单结构将原始输入信号或特征转换到特定问题的特征空间中。浅层模型的局限性对复杂函数的表示能力有限,针对复杂分类问题其泛化能力受到一定的制约,比较难解决一些更加复杂的自然信号处理问题,例如人类语音和自然图像等。而深度学习可通过学习一种深层非线性网络结构,表征输入数据,实现复杂函数逼近,并展现了强大的从少数样本集中学习数据集本质特征的能力。
深度学习可以简单理解为传统神经网络的拓展。如图13所示,深度学习与传统的神经网络之间有相同的地方,二者的相同之处在于,深度学习采用了与神经网络相似的分层结构:系统是一个包括输入层、隐层(可单层、可多层)、输出层的多层网络,只有相邻层的节点之间有连接,而同一层以及跨层节点之间相互无连接。
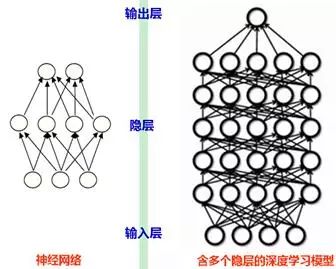
图13 传统的神经网络和深度神经网络
深度学习框架将特征和分类器结合到一个框架中,用数据去学习特征,在使用中减少了手工设计特征的巨大工作量。看它的一个别名:无监督特征学习(Unsupervised Feature Learning),就可以顾名思义了。无监督(Unsupervised)学习的意思就是不需要通过人工方式进行样本类别的标注来完成学习。因此,深度学习是一种可以自动地学习特征的方法。(准确地说,深度学习首先利用无监督学习对每一层进行逐层预训练(Layerwise Pre-Training)去学习特征;每次单独训练一层,并将训练结果作为更高一层的输入;然后到最上层改用监督学习从上到下进行微调(Fine-Tune)去学习模型。)
深度学习通过学习一种深层非线性网络结构,只需简单的网络结构即可实现复杂函数的逼近,并展现了强大的从大量无标注样本集中学习数据集本质特征的能力。深度学习能够获得可更好地表示数据的特征,同时由于模型的层次深(通常有5层、6层,甚至10多层的隐藏层节点)、表达能力强,因此有能力表示大规模数据。对于图像、语音这种特征不明显(需要手工设计且很多没有直观的物理含义)的问题,深度模型能够在大规模训练数据上取得更好的效果。相比于传统的神经网络,深度神经网络作出了重大的改进,在训练上的难度(如梯度弥散问题)可以通过“逐层预训练”来有效降低。
值的注意的是,深度学习不是万能的,像很多其他方法一样,它需要结合特定领域的先验知识,需要和其他模型结合才能得到最好的结果。此外,类似于神经网络,深度学习的另一局限性是可解释性不强,像个“黑箱子”一样不知为什么能取得好的效果,以及不知如何有针对性地去具体改进,而这有可能成为产品升级过程中的阻碍。
近年来,深度学习的发展逐渐成熟。2012年6月,《纽约时报》披露了Google Brain项目,吸引了公众的广泛关注。这个项目是由著名的斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家Jeff Dean共同主导,用16,000个CPU Core的并行计算平台去训练含有10亿个节点的深度神经网络(Deep Neural Networks,DNN),使其能够自我训练,对2万个不同物体的1,400万张图片进行辨识。在开始分析数据前,并不需要向系统手工输入任何诸如“脸、肢体、猫的长相是什么样子”这类特征。Jeff Dean说:“我们在训练的时候从来不会告诉机器:‘这是一只猫’(即无标注样本)。系统其实是自己发明或领悟了‘猫’的概念。
2014年3月,同样也是基于深度学习方法,Facebook的DeepFace项目使得人脸识别技术的识别率已经达到了97.25%,只比人类识别97.5%的正确率略低那么一点点,准确率几乎可媲美人类。该项目利用了9层的神经网络来获得脸部表征,神经网络处理的参数高达1.2亿。
以及2016年3月人工智能围棋比赛,由位于英国伦敦的谷歌(Google)旗下DeepMind公司的戴维·西尔弗、艾佳·黄和戴密斯·哈萨比斯与他们的团队开发的AlphaGo战胜了世界围棋冠军、职业九段选手李世石,并以4:1的总比分获胜。AlphaGo的主要工作原理就是深度学习,通过两个不同神经网络“大脑”合作来改进下棋:第一大脑:落子选择器 (Move Picker)和第二大脑:棋局评估器 (Position Evaluator)。这些大脑是多层神经网络跟那些Google图片搜索引擎识别图片在结构上是相似的。它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像图片分类器网络处理图片一样。经过过滤,13个完全连接的神经网络层产生对它们看到的局面判断。这些层能够做分类和逻辑推理。
4深度学习的研究现状
深度学习极大地促进了机器学习的发展,收到世界各国相关领域研究人员和高科技公司的重视,语音、图像和自然语言处理是深度学习算法应用最广泛的三个主要研究领域:
4.1深度学习在语音识别领域研究现状
长期以来,语音识别系统大多是采用高斯混合模型(GMM)来描述每个建模单元的概率模型。由于这种模型估计简单,方便使用大规模数据对其训练,该模型有较好的区分度训练算法,保证了该模型能够很好的训练。在很长时间内占据了语音识别应用领域主导性地位。但是GMM实质上一种浅层学习网络模型,特征的状态空间分布不能够被充分描述。而且,使用GMM建模数据的特征为数通常只有几十维,这使得特征之间的相关性不能被充分描述。最后GMM建模实质上是一种似然概率建模方式,即使一些模式分类之间的区分性能够通过区分度训练模拟得到,但是效果有限。
从2009年开始,微软亚洲研究院的语音识别专家们和深度学习领军人物Hinton合作。2011年微软公司推出基于深度神经网络的语音识别系统,这一成果将语音识别领域已有的技术框架完全改变。采用深度神经网络后,样本数据特征间相关性信息得以充分表示,将连续的特征信息结合构成高维特征,通过高维特征样本对深度神经网络模型进行训练。由于深度神经网络采用了模拟人脑神经架构,通过逐层的进行数据特征提取,最终得到适合进行模式分类处理的理想特征。
4.2深度学习在图像识别领域研究现状
对于图像的处理是深度学习算法最早尝试应用的领域。早在1989年,加拿大多伦多大学教授Yann LeCun就和他的同事提出了卷积神经网络(Convolutional Neural Networks, CNN)它是一种包含卷积层的深度神经网络模型。通常一个卷机神经网络架构包含两个可以通过训练产生的非线性卷积层,两个固定的子采样层和一个全连接层,隐藏层的数量一般至少在5个以上。CNN的架构设计是受到生物学家Hube和Wiesel的动物视觉模型启发而发明的,尤其是模拟动物视觉皮层的V1层和V2层中简单细胞和复杂细胞在视觉系统的功能。起初卷积神经网络在小规模的问题上取得了当时世界最好成果。但是在很长一段时间里一直没有取得重大突破。主要原因是卷积神经网络应用在大尺寸图像上一直不能取得理想结果,比如对于像素数很大的自然图像内容的理解,这使得它没有引起计算机视觉研究领域足够的重视。2012年10月,Hinton教授以及他的学生采用更深的卷神经网络模型在著名的ImageNet问题上取得了世界最好结果,使得对于图像识别的领域研究更进一步。
自卷积神经网络提出以来,在图像识别问题上并没有取得质的提升和突破,直到2012年Hinton构建深度神经网络才去的惊人的成果。这主要是因为对算法的改进,在网络的训练中引入了权重衰减的概念,有效的减小权重幅度,防止网络过拟合。更关键的是计算机计算能力的提升,GPU加速技术的发展,使得在训练过程中可以产生更多的训练数据,使网络能够更好的拟合训练数据。2012年国内互联网巨头百度公司将相关最新技术成功应用到人脸识别和自然图像识别问题,并推出相应的产品。现在的深度学习网络模型已经能够理解和识别一般的自然图像。深度学习模型不仅大幅提高了图像识别的精度,同时也避免了需要消耗大量时间进行人工特征的提取,使得在线运行效率大大提升。
4.3深度学习在自然语言处理领域研究现状
自然语言处理问题是深度学习在除了语音和图像处理之外的另一个重要的应用领域。数十年以来,自然语言处理的主流方法是基于统计的模型,人工神经网络也是基于统计方法模型之一,但在自然语言处理领域却一直没有被重视。语言建模时最早采用神经网络进行自然语言处理的问题。美国NEC研究院最早将深度学习引入到自然语言处理研究中,其研究院从2008年起采用将词汇映射到一维矢量空间和多层一维卷积结构去解决词性标注、分词、命名实体识别和语义角色标注四个典型的自然语言处理问题。他们构建了一个网络模型用于解决四个不同问题,都取得了相当精确的结果。总体而言,深度学习在自然语言处理上取得的成果和在图像语音识别方面相差甚远,仍有待深入研究。

产业智能官
子曰:“君子和而不同,小人同而不和。” 《论语·子路》
云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。
在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。
云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
人工智能通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
新一代信息技术(云计算、大数据、物联网、区块链和人工智能)的商业化落地进度远不及技术其本身的革新来得迅猛,究其原因,技术供应商(乙方)不明确自己的技术可服务于谁,传统企业机构(甲方)不懂如何有效利用新一代信息技术创新商业模式和提升效率。
“产业智能官”,通过采编对甲、乙方参考价值巨大的云计算、大数据、物联网、区块链和人工智能的论文、研究报告和商业合作项目与案例,面向企业CEO、CDO、CTO和CIO,从而服务新一代信息技术输出者和新一代信息技术消费者。
助力新一代信息技术公司寻找最有价值的潜在传统客户与商业化落地路径,帮助传统企业选择与开发适合自己的新一代信息技术产品和技术方案,消除新一代信息技术公司与传统企业之间的信息不对称,推动云计算、大数据、物联网、区块链和人工智能的商业化浪潮。
给决策制定者和商业领袖的建议:
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临较高失业风险的人群;
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及创造性思维等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
产业智能官 AI-CPS
用新一代技术操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在商业应用场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com