准确率和因果解释性显著提高!京东基于机器学习模型的报警系统

文章作者:京东搜索数据科学团队
出品平台:DataFunTalk
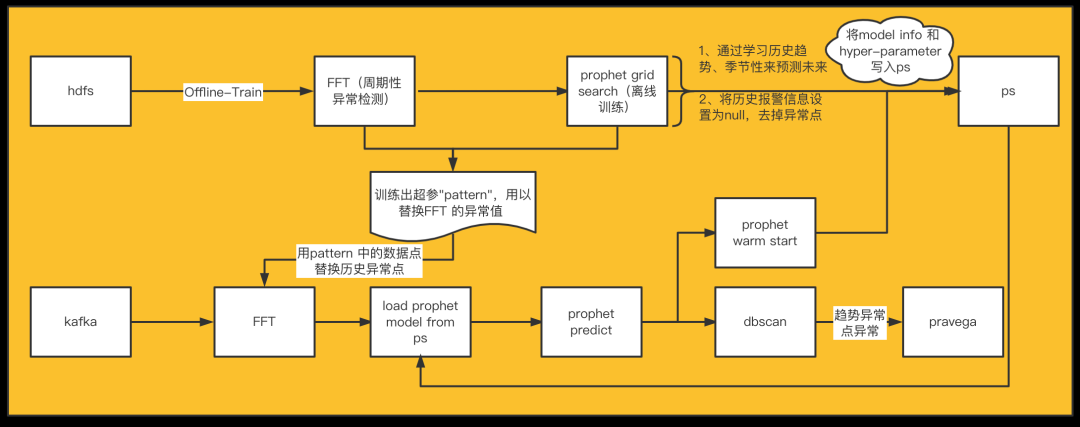
这是一个典型的在线学习训练实现方案,如图所示:
离线训练任务:一个训练任务在 hdfs load 训练数据,先将训练数据进行特征工程等的加工之后,将模型进行离线的训练,训练完成之后将 model info 和模型参数数据写入 parameter server,该任务天级运行,每次运行训练比如说 28 天的数据。
实时训练任务:实时任务方面,该任务从 kafka 读取样本数据,将样本数据进行一 定积累之后比如说小时级、分钟级、条数等进行小批量的训练,先去 parameter server pull 模型参数和超参数据,load 模型之后如果有预估需求的话,可能进行一次 predict,如果没有预估需求,可以直接进行模型训练,并且将训练之后的模型数据 push 给 parameter server。
敲黑板重要提示:在该图中,因为 FFT(傅里叶变换)是一个无状态的机器学习算法,为了防止将错误的数据加入训练集,我们需要离线训练一个常规 pattern,当 FFT 训练数据中有异常时,用 pattern 的同一时段数据替换异常数据,避免训练数据的异常趋势影响周期性检验的精准度。比如说,离线训练出来的模型周期是一个星期,因此,pattern 是一个横轴为 time 纵轴为 value 的数据集,只要将异常点的时间的 value 用 pattern 里面相应时间的 value 替换即可;当然了,为了避免一些异常值的影响,我们还需要移动平均滤波,并且需要通过现行回归学习长期趋势来排除数据中长期趋势的影响。
1. FFT - 周期性检测
FFT 算法是一个典型的将时域信号转换到频域的思想,时域可以拆解为多个频域波的的叠加,因此频域上是各种频率和振幅的波,所以时域上的周期性可以由此得来,目前傅里叶变换是数字信号处理的基本操作,在此处的应用是判断时序数据的周期性。到了这里,大家可能会问,差分法也是一种判断时序周期性的方法,我们为何不用差分法来判断周期性?相对差分法,傅里叶变化的优点是不需要遍历多阶差分,无论周期是多少,即使存在大小多周期共存,都可以在一次计算中得到,当然了,这个算法也有自己的缺点,那就是数据中有异常数据时会影响周期判断的精准度,不过我们可以用上面提到过很多次的 pattern 超参训练来解决这个问题。
(1) 数据的毛刺是有必要去除一下的,因此,我们移动平均滤波,来剔除异常值的影响;此外,通过线性回归学习数据长期趋势来去除长期趋势的影响;另外,就像上面提到的针对异常趋势的一个处理,我们离线训练一个常规 pattern,当 FFT 训练数据中有异常时,用 pattern 的同一时段数据替换异常数据,来避免训练数据的异常趋势影响周期性检验的精准度。
(2) 那么我们如何确定有些数据是异常数据还是抖动性比较大的正常数据呢?因此,我们需要分析数据抖动频率,通过周期差分,得到数据抖动分布,根据抖动分布分位数定义数据的异常敏感度,当前数据抖动超过分位数所对应的抖动频率时,认为数据达到异常标准,当数据抖动频繁时,通过增大分位数适当降低异常敏感度,才反之提高异常敏感度。
(3) 傅里叶变换得到频谱图,根据频谱中的频率和能量值找到周期,通过 FFT 分析一方面可以判别数据有无周期性,满足有周期性时才可以进行时序预测、另一方面根据当前值对频谱变化影响判别当前数据趋势的异常增、降情况。因fft对异常相对敏感,而实际应用场景中可能对异常敏感度要求不一样,所以频谱图结合数据抖动频率分析,进行周期性检测。
2. PROPHET - 时序预测
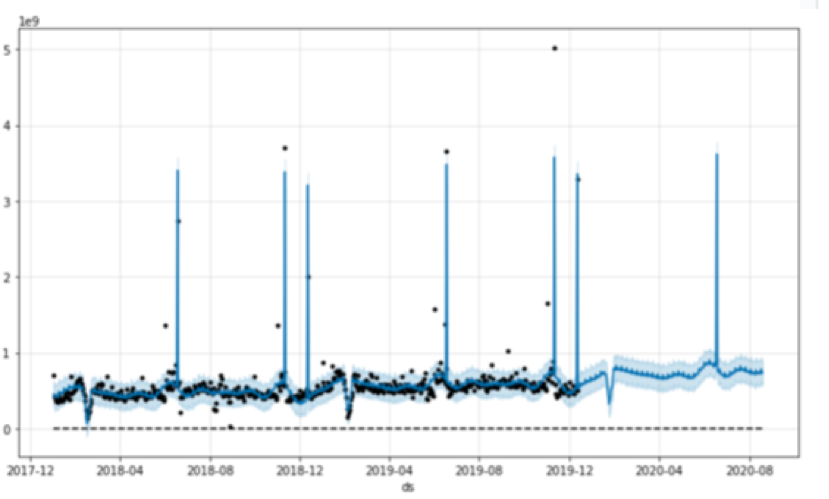
如上图,Prophet时序预测效果
PROPHET 是由 facebook 开源的、通过学习历史趋势、季节性来预测未来的一种时间序列模型,一般应用在有规律、有季节性的时序数据中,在商业数据上应用较多。PROPHET 不仅像 ARIMA 模型可以学习长期趋势,并将季节性、节假日也纳入进来,且对缺失值不敏感,模型灵活使用简单方便,可以通过调参的方式,训练出适合的模型,且可以多步预测。
(1) 我们如何进行数据选择与处理呢?首先,训练数据长度要保证大于等于上述 FFT 算法识别出的周期的2倍(2倍周期长期趋势更稳定),保障学习到完整的数据周期;第二,之前我们识别到的异常值需要做一下记录,对异常值做缺失值处理。
(2) 模型训练与预测:首先,对于模型的重要参数 changepoint_prior_scale、seasonality_prior_scale、daily_seasonality 等,需要离线寻参找到最优参数并作为超参保存到模型里面;第二,我们的训练集与测试集需要尽量满足1:1,这样能最大的保证模型的真实效果和预估接近;第三,模型评估指标有 MAE 平均绝对误差、MSE 平均平方差、RMSE 方均根差、mape 平均绝对百分比误差等多种,这里选择其中的 mape,计算 mape 均值满足 1-mape 大于等于0.9模型就可以使用了;第四,predict 可以设置任意预测步长,但步长越大置信度越小,所以我们选择每次预测1步,随后立即更新模型用于下一次预测,这里具体的实现思路在后续文章中解释。
(3) 个性化支持:对于个性化这一点,我们可以选择分时段建模、条件日季节性建模等。分时段建模适用于不同时段数据差异很大时,如流量集中在白天,凌晨或清晨的数据特别少;条件日季节性建模的适用场景是日、周季节性共存时,如车流量有早晚高峰、同时也有工作日和周末的区别。个性化建模提高了预测准确率和模型泛化性。
3. DBScan-异常点检测
DBScan是一种基于密度的空间聚类算法,将具有足够密度的区域划分为簇,即紧密相连的样本划分为一类,所有各组紧密相连的样本划分成不同的类别,孤立的样本自成一类,由此得到最终的聚类结果。该算法可以发现任意形状的聚类簇,不像 K-measn 仅适用于凸数据集。聚类的同时还可以找到异常点;缺点是不适用于样本集的密度不均匀、聚类间距很大的数据。
训练数据用到的维度,一个是数据原始值、一个是 prophet 预测残差绝对值,通过设置参数聚类密度和聚类半径完成聚类,然后用轮廓系数来评估模型效果,轮廓系数越接近1说明聚类效果越好,最后找到 label=-1 的类,即是异常值。
1. 基于 Alink 的模型分布式调用 python 方法
该链路的模型都是单机的,因此在大规模数据量的情况下分布式化是一个急需解决的问题,经过大量调研之后,为了保证前后技术栈的统一,我们决定采用 Alink 来解决这个问题,在该背景下,我们打通了 Alink 分布式调用 python 方法的通路,可以最大程度的提高数据并行的效率。
2. load balance 策略
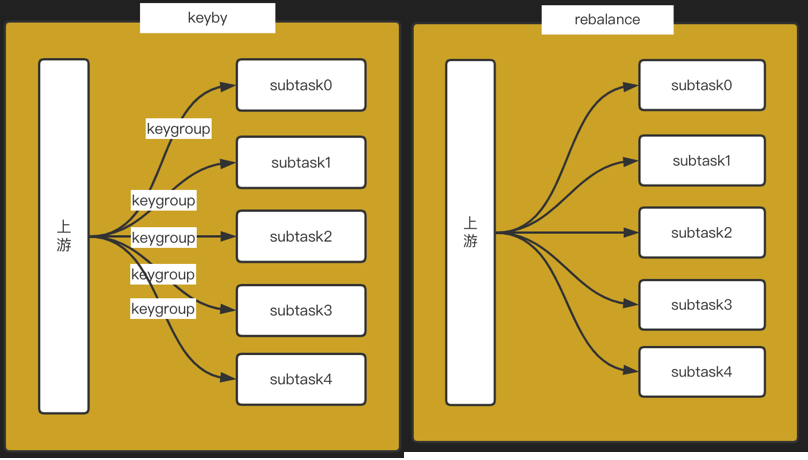
上述优化方案采用的是数据并行的分布式方式,因此选择一个合适的数据分发策略是非常重要的。最开始的时候我们采用了 flink 里面 keyby 的形式来分发数据,该方式的特点是相同的 key 会被分发到同一台机器上,采用该种方式会导致大量的机器空闲,且少数机器异常忙碌,cpu 时时处于100%的状态,在该种情况下,大量的数据发生积压,导致数据严重延时。因此我们换成了 rebalance 的策略,且保证整条链路的耗时不超过5min。
假如某个时间里面点击、加购等数据流全部都进行了异常报警,我们仅仅去查相应的点击流的问题或者是加购流的问题是远远不够的,因此这里可能是曝光出现了问题进而导致的一系列的问题。同样,在数据科学领域,仅仅是异常检测是远远不够的,我们希望能做到异常数据的归因来直接定位问题所在,因此,我们希望通过一些因果推断模型来判断该异常发生的最根本的原因,以此来降低相应团队排查故障的时间。
今天的分享就到这里,谢谢大家。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“机器学习” 就可以获取《机器学习专知资料合集》专知下载链接



