GluonNLP v0.6: 让可复现的 BERT 模型走到你身边
BERT 模型正在自然语言处理领域大杀特杀!例如,BERT 模型在包含 9 种任务的 GLUE 基准测试上将得分从 72.7 提高到了 80.5 ——这是最新的重大突破 [6]。
虽然 BERT 模型很好很强大,GluonNLP 小分队却没有找到任何开源代码能够同时:
提供可扩展的 GPU 预训练
复现各种任务上的结果
支持模型输出和部署
为了解决以上所有的痛点,GluonNLP 0.6 版本站了起来!

用 8 块 GPU 预训练 BERT ,拢共要几天?
BERT 是 Bidirectional Encoder Representations from Transformers 的简称。它 1) 使用了堆叠的双向 Transformer 编码器, 2) 在大型语料库上通过带自监督机制的 Masked Language Model 及下一句预测进行学习, 3) 仅需用一小撮标注过的数据进行微调即可将学习完毕的文本表示转移给特定的下游自然语言处理任务。
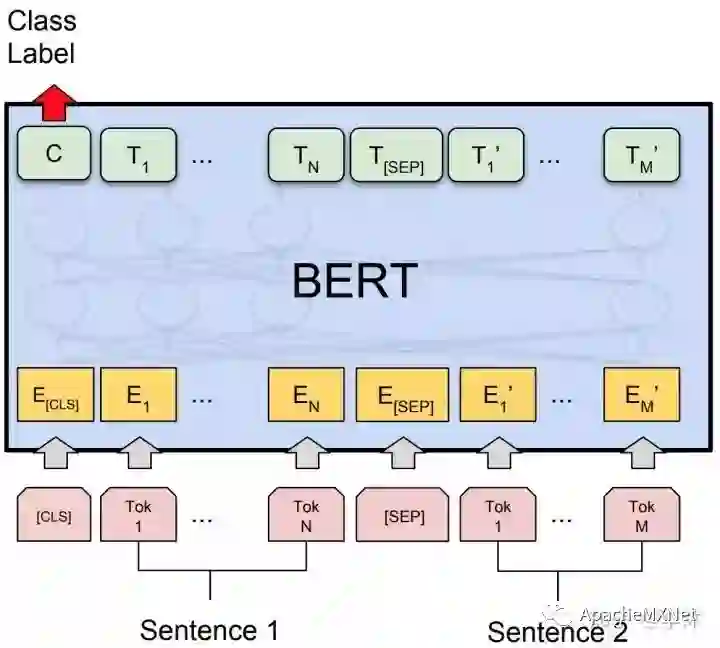
一个精明的读者或许会问:既然 BERT 模型的官方代码库已经放出了多个用大量 TPU 训练好的预训练模型,我们为何还要自己出资预训练一个自己的 BERT 呢?那当然是因为预训练选择的语料库非常重要!如同其他的迁移学习场景一样,如果预训练的数据源和你手头任务的数据相近,最后的性能当然会更好。举个栗子,受不同的语言风格影响,用维基百科的语料库预训练的模型在微博上的效果非常有限。
明知山有虎,偏向虎山行,我们从头开始对 BERT 基本版模型进行了预训练。训练中使用了包含 20 亿词(除去图片和表格)的英文维基百科以及去重后包含 5 亿 7950 万词汇的书籍语料库。在利用混合精度训练以及梯度累加的条件下,8 块 Volta V100 GPU 使用了 6.5 天将 BERT 基本版模型训练好,并在验证集上得到了如下结果:
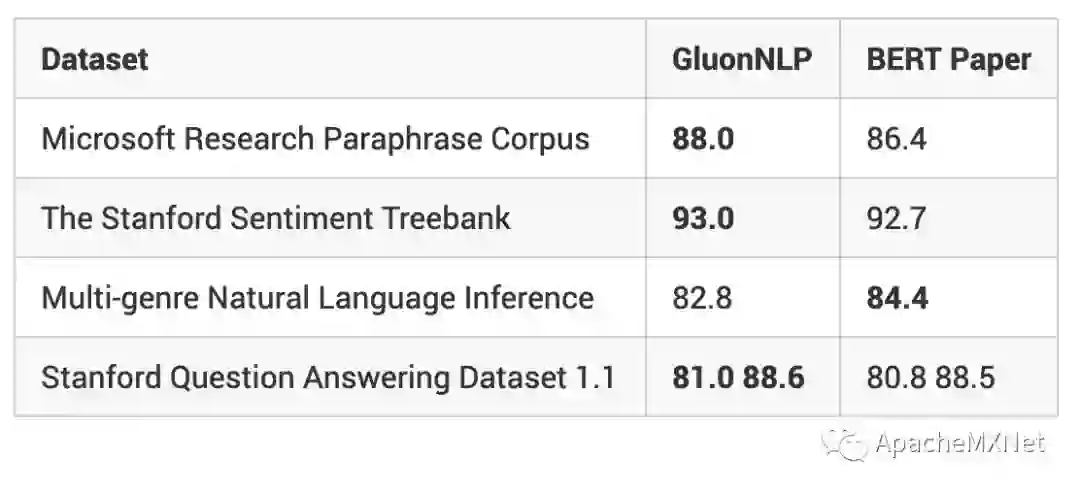
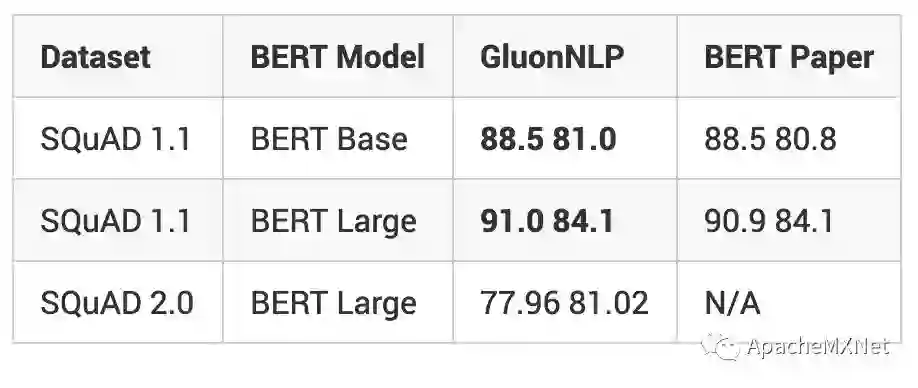
GluonNLP 的目标是?消灭无法复现的研究结果!我们提供了可复现 RTE [6]、MNLI [8]、SST-2、MRPC [10]、SQuAD 1.1 [9] 和 SQuAD 2.0[11] 最先进结果的训练脚本和训练日志。并且我们模块化的代码可以在同一框架内将 BERT 应用到各类任务上。 我们在以下问答任务数据集上得到了这些 F1 和精确匹配得分:
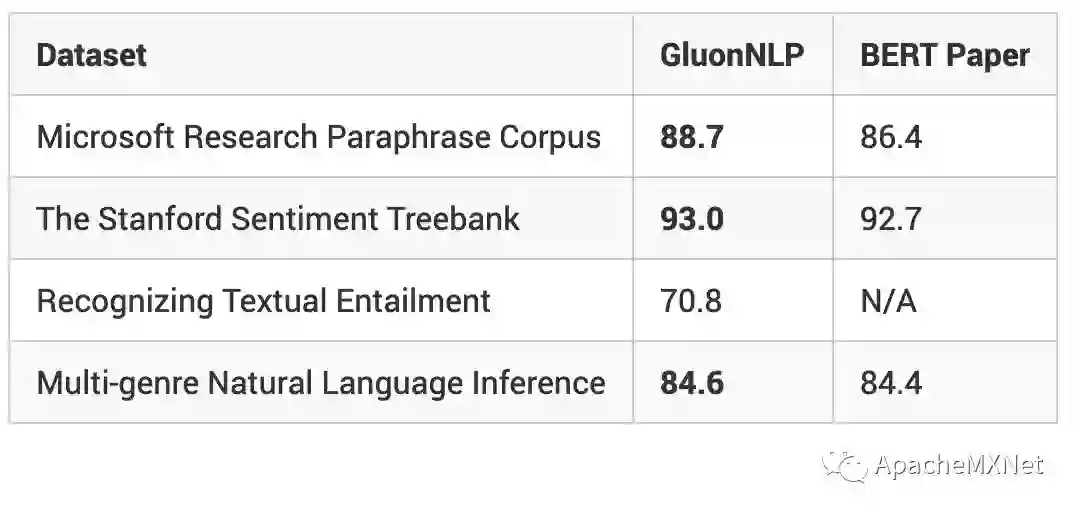
以下是我们用 BERT 基本模型在句子分类任务验证集上得到的精度:
部署 BERT ?轻松搞定!
借助 Apache MXNet 的力量,我们提供的 BERT 模型可以输出到 json 格式并在 C++、Java、Scala以及其他多种语言上进行部署。与此同时,16 位浮点数的运算支持为 GPU 上的 BERT 推断带来了约 2x 的加速。CPU 上的 8 位整数模型量化正在施工中,敬请期待。
所以这么好的代码,在哪里才能找到呢?
要开始使用 GluonNLP 调戏 BERT,请点击我们关于如何针对句子分类任务对 BERT 进行微调的教程。您也可以逛一下 BERT Model Zoo,查看 BERT 预训练脚本以及针对 SQuAD 和 GLUE 基准测试的微调脚本。
更多更新详情,请移步我们的发布文档。未来 GluonNLP 还将致力于增强 BERT 的分布式训练,以及带来 GPT-2、BiDAF [12]、QANet [3]、BERT 在命名实体识别/文本解析等更多功能。
还在等什么少年?快用 GluonNLP 0.6 让 BERT 为你创造奇迹吧!
鸣谢
在此感谢所有 GluonNLP 社区的贡献者: @haven-jeon @fiercex @kenjewu @imgarylai @TaoLv@Ishitori @szha @astonzhang@cgraywang
参考文献
[1] Peters, Matthew E., et al. “Deep contextualized word representations.” arXiv preprint arXiv:1802.05365 (2018).
[2] Howard, Jeremy, and Sebastian Ruder. “Universal language model fine-tuning for text classification.” arXiv preprint arXiv:1801.06146 (2018).
[3] Yu, Adams Wei, et al. “Qanet: Combining local convolution with global self-attention for reading comprehension.” arXiv preprint arXiv:1804.09541 (2018).
[4] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[5] Sebastian Ruder. NLP’s ImageNet moment has arrived, 2018 (accessed November 1, 2018). URL thegradient.pub/nlp-ima.
[6] Wang, Alex, et al. “Glue: A multi-task benchmark and analysis platform for natural language understanding.” arXiv preprint arXiv:1804.07461 (2018).
[7] Liu, Xiaodong, et al. “Multi-Task Deep Neural Networks for Natural Language Understanding.” arXiv preprint arXiv:1901.11504 (2019).
[8] Williams, Adina, Nikita Nangia, and Samuel R. Bowman. “A broad-coverage challenge corpus for sentence understanding through inference.” arXiv preprint arXiv:1704.05426 (2017).
[9] Rajpurkar, Pranav, et al. “Squad: 100,000+ questions for machine comprehension of text.” arXiv preprint arXiv:1606.05250 (2016).
[10] Dolan, Bill, Chris Brockett, and Chris Quirk. “Microsoft research paraphrase corpus.” Retrieved March 29 (2005): 2008
[11] Rajpurkar, Pranav, Robin Jia, and Percy Liang. “Know What You Don’t Know: Unanswerable Questions for SQuAD.” arXiv preprint arXiv:1806.03822 (2018).
[12] Tuason, Ramon, Daniel Grazian, and Genki Kondo. “BiDAF Model for Question Answering.”
点原文链接访问 Release Note



