深入机器学习系列之:Bisecting KMeans


导读
k-means算法分为两步,第一步是初始化中心点,第二步是迭代更新中心点直至满足最大迭代数或者收敛。

来源: 星环科技丨作者:智子AI
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

二分k-means算法
二分k-means算法是分层聚类(Hierarchical clustering)的一种,分层聚类是聚类分析中常用的方法。 分层聚类的策略一般有两种:
聚合。这是一种自底向上的方法,每一个观察者初始化本身为一类,然后两两结合
分裂。这是一种自顶向下的方法,所有观察者初始化为一类,然后递归地分裂它们
二分k-means算法是分裂法的一种。
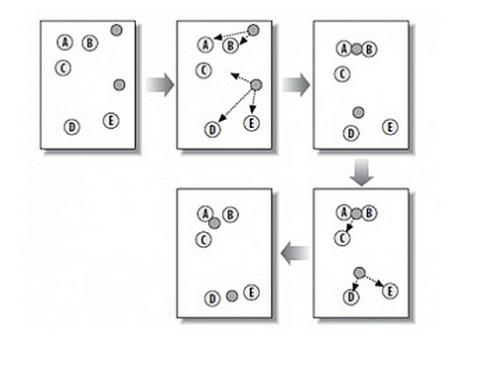
二分k-means的步骤
二分k-means算法是k-means算法的改进算法,相比k-means算法,它有如下优点:
二分k-means算法可以加速k-means算法的执行速度,因为它的相似度计算少了
能够克服k-means收敛于局部最小的缺点
二分k-means算法的一般流程如下所示:

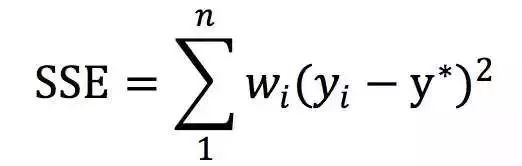
(3)使用k-means算法将可分裂的簇分为两簇。
(4)一直重复(2)(3)步,直到满足迭代结束条件。
以上过程隐含着一个原则是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于它们的质心,聚类效果就越好。 所以我们就需要对误差平方和最大的簇进行再一次的划分,因为误差平方和越大,表示该簇聚类越不好,越有可能是多个簇被当成一个簇了,所以我们首先需要对这个簇进行划分。
二分k-means的源码分析
spark在文件org.apache.spark.mllib.clustering.BisectingKMeans中实现了二分k-means算法。在分步骤分析算法实现之前,我们先来了解BisectingKMeans类中参数代表的含义。

上面代码中,k表示叶子簇的期望数,默认情况下为4。如果没有可被切分的叶子簇,实际值会更小。maxIterations表示切分簇的k-means算法的最大迭代次数,默认为20。 minDivisibleClusterSize的值如果大于等于1,它表示一个可切分簇的最小点数量;如果值小于1,它表示可切分簇的点数量占总数的最小比例,该值默认为1。
BisectingKMeans的run方法实现了二分k-means算法,下面将一步步分析该方法的实现过程。
(1)初始化数据

(2)将所有数据初始化为一个簇,并计算代价

在上述代码中,第一行给每个向量加上一个索引,用以标明簇在最终生成的树上的深度,ROOT_INDEX的值为1。summarize方法计算误差平方和,我们来看看它的实现。
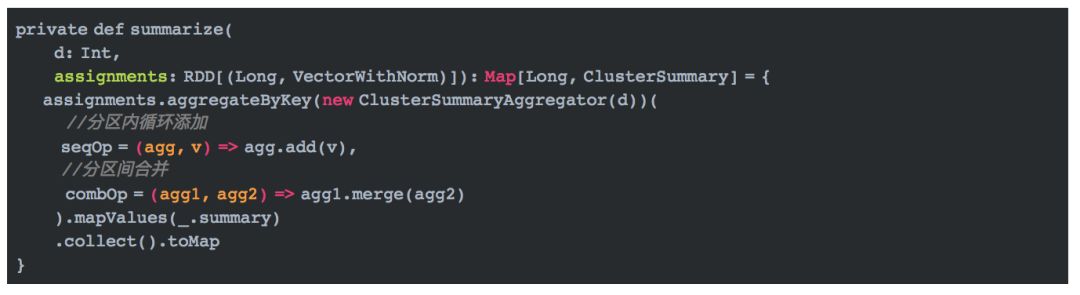
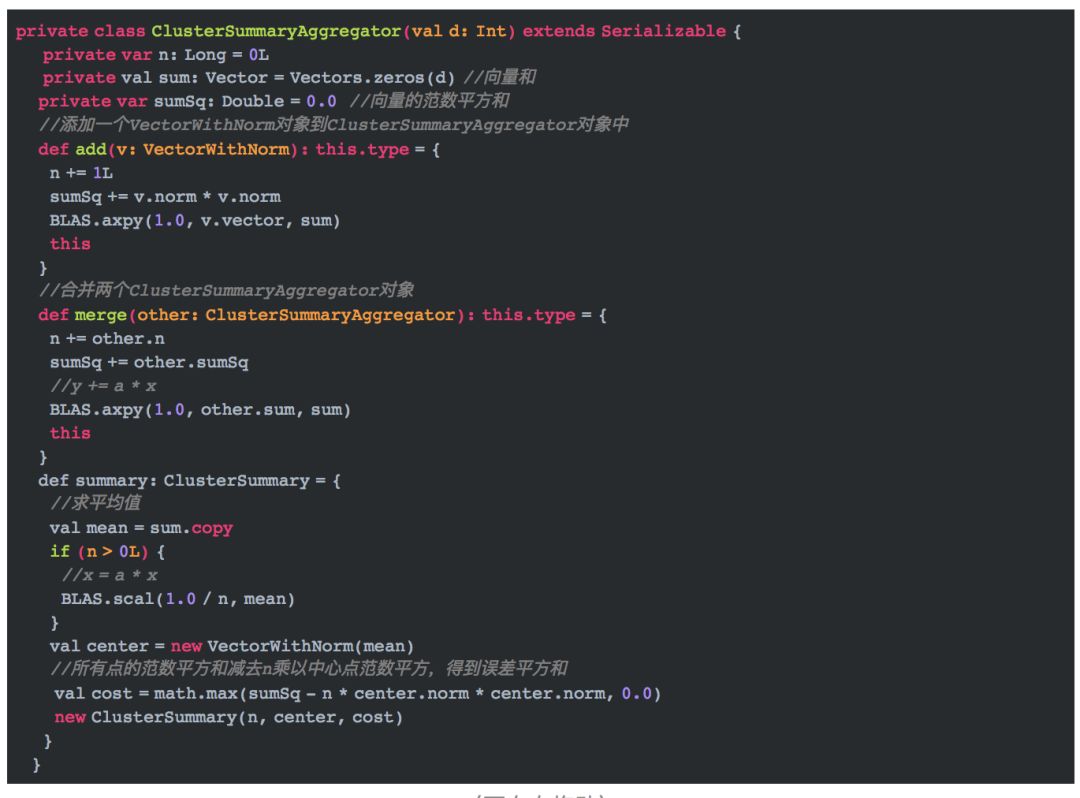
这里的d表示特征维度,代码对assignments使用aggregateByKey操作,根据key值在分区内循环添加(add)数据,在分区间合并(merge)数据集,转换成最终ClusterSummaryAggregator对象,然后针对每个key,调用summary方法,计算。 ClusterSummaryAggregator包含三个很简单的方法,分别是add,merge以及summary。
这里计算误差平方和与第一章的公式有所不同,但是效果一致。这里计算聚类代价函数的公式如下所示:
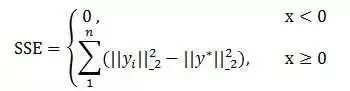
获取第一个簇之后,我们需要做的就是迭代分裂可分裂的簇,直到满足我们的要求。迭代停止的条件是activeClusters为空,或者numLeafClustersNeeded为0(即没有分裂的叶子簇),或者迭代深度大于LEVEL_LIMIT。

这里,LEVEL_LIMIT是一个较大的值,计算方法如下。

(3)获取需要分裂的簇
在每一次迭代中,我们首先要做的是获取满足条件的可以分裂的簇。
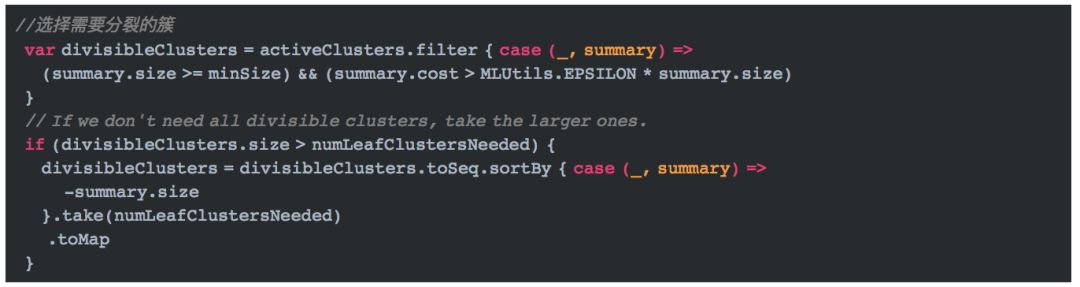
这里选择分裂的簇用到了两个条件,即数据点的数量大于规定的最小数量以及代价小于等于MLUtils.EPSILON * summary.size。并且如果可分解的簇的个数多余我们规定的个数numLeafClustersNeeded即(k-1), 那么我们取包含数量最多的numLeafClustersNeeded个簇用于分裂。
(4)使用k-means算法将可分裂的簇分解为两簇
我们知道,k-means算法分为两步,第一步是初始化中心点,第二步是迭代更新中心点直至满足最大迭代数或者收敛。下面就分两步来说明。
-
第一步,随机的选择中心点,将可分裂簇分为两簇

在上面的代码中,用splitCenter方法将簇随机地分为了两簇,并返回相应的中心点,它的实现如下所示。

-
第二步,迭代更新中心点
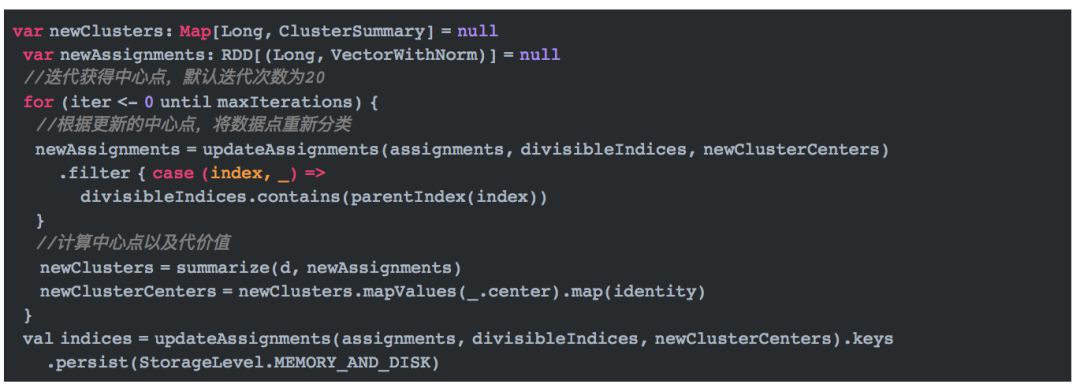
这段代码中,updateAssignments会根据更新的中心点将数据分配给距离其最短的中心点所在的簇,即重新分配簇。代码如下:
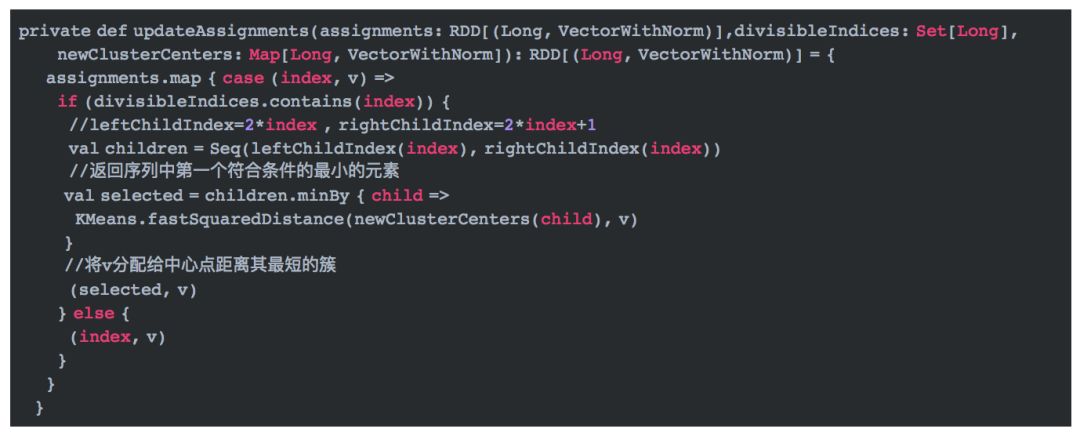
重新分配簇之后,利用summarize方法重新计算中心点以及代价值。
(5)处理变量值为下次迭代作准备