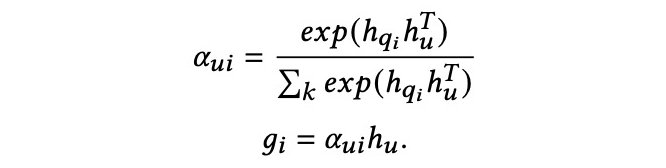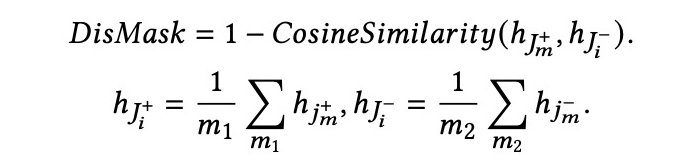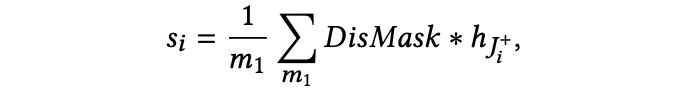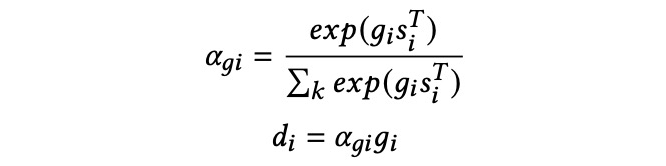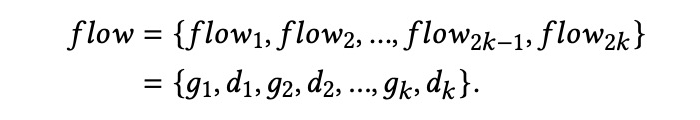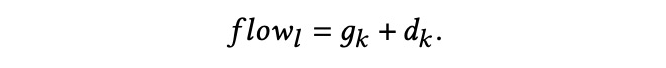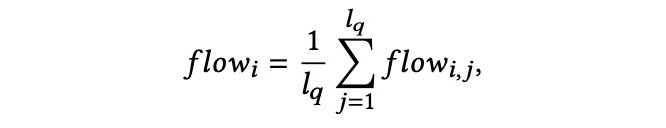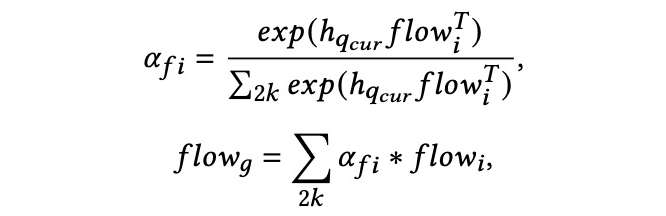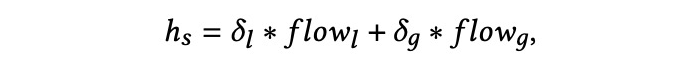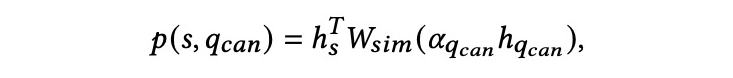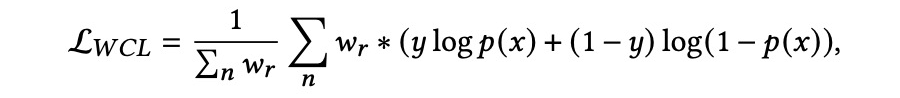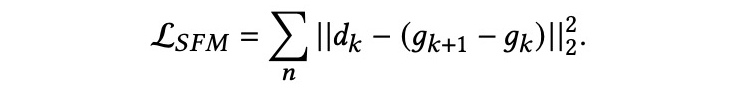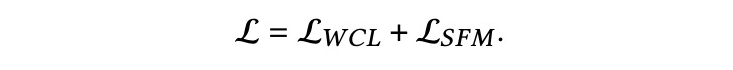本文为中国人民大学联合 BOSS 直聘提出的基于动态搜索流的用户个性化搜索输入提示模型。目前,该论文已被信息检索和数据挖掘领域国际会议 CIKM 2022 接收。
论文标题:
Personalized Query Suggestion with Searching Dynamic Flow for Online Recruitment
CIKM 2022
在这个互联网信息指数增长的时代,使用查询建议技术来帮助用户在在线搜索过程中清楚地表达需求,对搜索引擎来说变得越来越重要。一个好的查询建议系统需要能够准确地理解和建模每个查询背后的用户搜索意图,这离不开利用动态的用户反馈行为和丰富的上下文信息进行个性化查询建议。
在本研究中,我们提出了动态搜索流模型(DSFM),这是一个查询建议框架,能够利用动态流机制在互联网求职招聘场景中逐步建模和细化用户搜索意图。
模型首先引入了局部流和全局流的概念,分别用于捕获用户的实时意图和会话的整体意图;其次,通过利用简历和职位要求中包含的丰富语义信息,DSFM 实现了查询建议的个性化;此外,我们在训练过程中引入加权对比学习,产生了更广泛的有针对性的查询样本,缓解曝光偏差问题;同时,注意力机制的采用也使得我们能够选择最相关的信息构成最终的会话表示;最后,在真实数据集上的大量实验结果证明了我们提出的方法在在线招聘平台查询建议任务中的有效性。
当用户与搜索引擎交互时,常常很难确定自己要输入怎样的查询词。查询建议系统通过提供一组可选择的候选查询词来提高现代搜索引擎的可用性,这些候选查询词通常比用户的原始搜索输入更加有效。因此,查询建议系统需要能够准确全面地理解用户搜索会话中隐含的搜索意图,帮助用户细化其原始查询,从而引导用户找到真正想要的信息。
查询建议系统面临的挑战是多方面的。其中之一是用户提供的搜索查询词具有一定模糊性。对于用户正在搜索的信息,查询建议系统通常需要多次优化查询以满足用户的特定需求。此外,用户在搜索引擎中输入的搜索查询通常较短(一般少于 5 个词)。
为了解决这些问题,查询建议系统必须利用额外的信息,如搜索后的点击行为以及平台上的其他相关文本信息等,从而潜在地减少歧义并更好地理解用户搜索意图。同时,当前查询建议系统普遍存在的另一个问题是缺乏个性化,无论是传统的基于词频的方法还是近年来基于词嵌入的技术都存在这一问题。
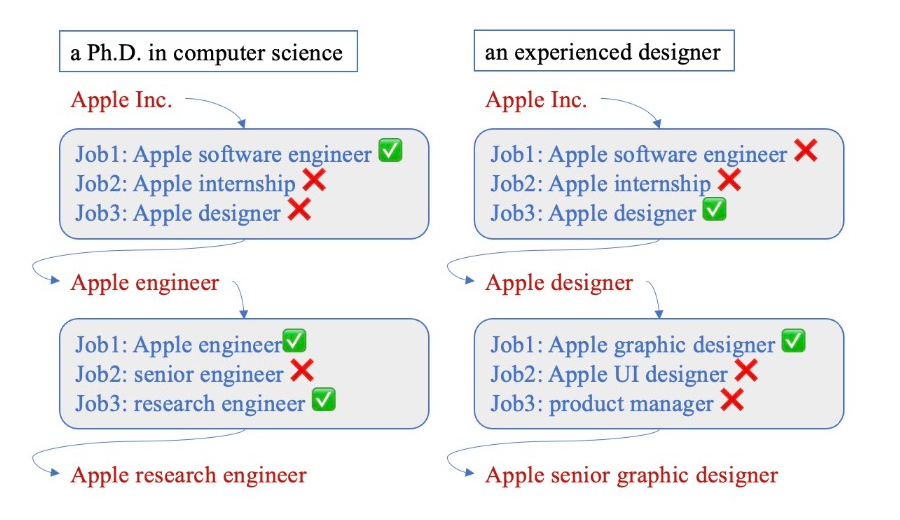
对于使用词嵌入的查询建议系统,如果不利用用户简历信息和上下文会话信息,个性化是很难实现的。然而,搜索引擎用户对个性化的需求越来越高,而且与一般的综合搜索引擎(如 Google、百度)不同,垂直领域的搜索引擎对个性化的要求更高。以互联网求职招聘平台为例,拥有不同背景的用户会对不同的职位类型和职位级别感兴趣,下图给出了一个示例。
如果两个用户都搜索“苹果公司”,一个计算机科学博士毕业生可能会对“苹果研究员”感兴趣,而另一个经验丰富的设计师可能会更关注“苹果高级平面设计师”这样的职位。在这次搜索中,前者随后点击了苹果软件工程师相关的职位,而忽略了苹果实习生和设计师的职位,这表明他接下来的搜索将更倾向于软件工程师职位。
而在搜索“苹果工程师”后,用户又点击了与苹果工程师和研究员相关的职位,但忽略了需要更多工作经验的高级工程师职位,这表明用户的下一步搜索可能会转向研究员相关的方向。而后者在第一次搜索“苹果公司”后点击了设计师职位,表明其确实想找一个设计师的岗位,其第二次输入的查询词也确实是“苹果设计师”,接着她点击了“苹果平面设计师”职位,表明其可能有一定的平面设计经验。随后,她第三次输入的查询词也的确是“苹果高级平面设计师”。
综上,如果在不知道求职者的任何个人信息和搜索上下文的情况下,查询建议系统可能会推荐与用户意图无关的候选查询词,使得用户需要频繁更换搜索词,从而导致不好的用户体验。
我们首先给定一些重要概念和符号的定义。考虑一个用户
(其简历表示为
)正在搜索框中输入一个查询
来申请工作。在当前查询之前,用户最近搜索的查询词按时间从最远到近排列为
,每次查询后平台列出的职位
。模型的目标是:给定一组候选查询词集合
,如何设计一个 ranking 模型,根据用户、当前查询、搜索和浏览的职位行为序列,预测每个查询
的排名。
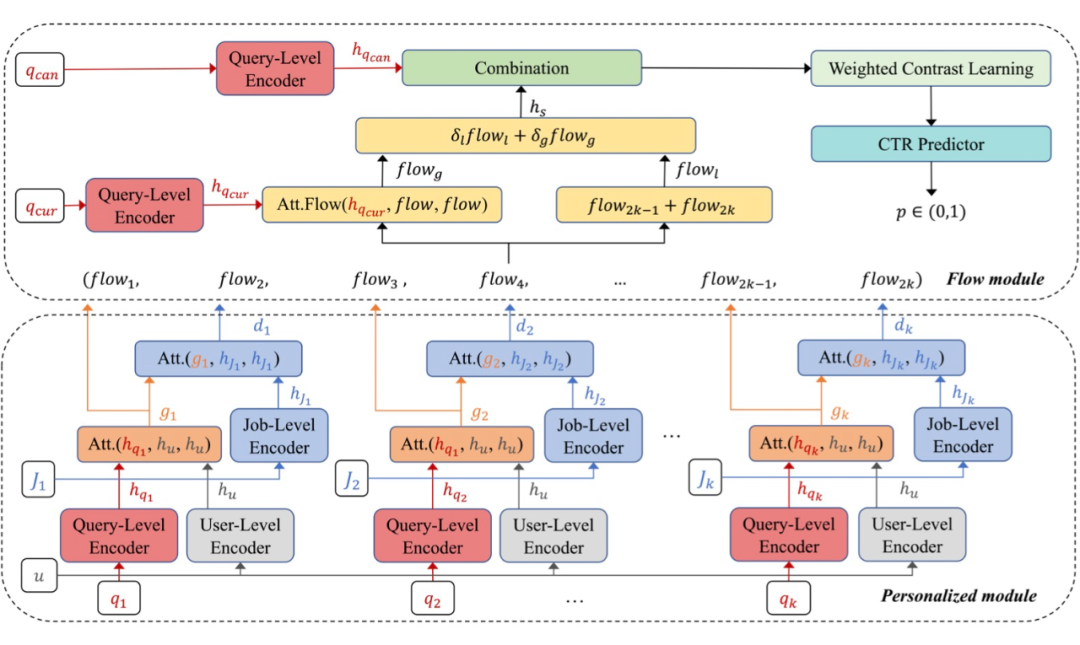
我们提出的学习框架通过加权对比学习对搜索流进行建模,解决了查询建议任务中的长尾分布问题和简单连接向量进行预测的问题。模型框架如下图所示。
该框架主要由个性化模块 Personalized Module 和 Flow Module 组成。具体来说,我们在个性化模块中对 𝑈 和 𝐽 进行了处理:1)首先使用
用户和职位的多视图编码器 对用户简历和职位描述编码;同时,所有查询,包括搜索查询、当前查询和候选查询都由 2)
查询级编码器 编码;然后,通过 3)
结合用户简历信息 和 4)
结合职位描述信息 ,我们得到 𝑞、𝑈 和 𝐽 的组合。在 Flow Module 中,我们利用职位描述,根据 5)
Search Dynamic Flow 和 6)
匹配 session 表示和候选查询 来实现查询建议系统。接下来,我们将讨论方法中每个模块的细节。
在个性化模块中,我们首先设计了一个用户、职位和查询词的编码器,将每个时间步的查询词表示与用户表示、职位表示相结合,得到个性化的用户意图表示。为了初始化用户和职位的嵌入表示,我们首先使用预训练模型 RoBERTa 来初始化用户简历/职位描述的表示。然后,我们分别将文本表示与离散特征的表示连接起来,得到上下文感知的用户表示
和职位表示
。
查询级编码器。 给定一个具有历史查询、搜索查询和候选查询的训练实例,我们使用查询编码器生成它们的表示
和
。在这里,我们使用相同的编码器来获得两种查询的表示,这样方便根据它们的相似度来推荐候选查询。
结合用户信息。 在 DFSM 中,我们首先根据历史查询和用户的个人简历来编码个性化的意图。为了能够精确定位用户搜索意图,这里应用了用户级别的注意力机制。具体来说,我们获得用户的历史个性化查询表示
。
结合职位描述。 在一个会话中,以前的
和新的
之间的语义差异被表示为
,因此
是这个 Session 中的语义影响。我们利用
从用户与列出的职位的交互中提取
。为了准确提取出用户在列出的职位背后的搜索意图,我们尽量保留正例职位
和负例职位
的不同信息,并去掉相似的部分。因此,我们可以得到
到
的偏移方向。具体来说,我们测量
和
之间的相似度,并通过以下步骤获得每个时间步的 DisMask:
然后我们用这个 DisMask 乘以正例职位的均值表示,在时间步
中获得搜索意图
:
最后我们得到语义的影响:
正如上文提到的,现在我们有了个性化模块输出的
和
。请注意,
表示通过当前查询和用户简历提取的搜索意图,
表示从每次搜索后的职位描述中提取的用户意图,我们将它们结合起来,并将它们命名为搜索动态流,然后将它们输入 Flow 模块。
搜索动态流。 假设一个用户正在寻找一份合适的工作,其搜索意图与由个性化模块提取的
和
高度相关。因此,我们需要利用它们来获取动态信息,并简单地表示搜索动态流:
我们假设在进行一次新的查询时,用户从其上一次搜索和历史搜索中能够获得一些灵感。这里我们分别使用 local flow 和 global flow 来提取这两种类型的意图。
在时间步骤
中,
表示最后一个查询的个性化表示,
表示
和单击的查询之间的语义差异。于是我们可以将 local flow 定义为:
实时动态流 local flowflowl 表示实时意图,即在最后一次搜索过程中,用户观察到一些信息后转移了其搜索意图,从而去搜索另一个查询词。
此外,我们引入全局动态流 global flow 来描述 session 中动态流的整体影响。一个 flow 的表示
定义为:
由于并非所有的搜索对用户意图的贡献都是相同的,因此采用 attention 机制从信息流中提取这些信息的贡献权重,并将这些词的表示集合起来,构建一个 global flow 向量。
匹配会话表示和建议查询。 给定会话
的实例和候选查询
,我们的目标是显式地获得
和
之间的匹配分数。为了学习对点击行为的监督,我们引入了一个 CTR 预测任务。在这个任务中,我们首先利用 attention 来获取
和
之间的匹配分数:
通过以下方法,我们将这个匹配得分层的输出定义为概率
,表示特定候选人的点击率为:
为了将 p 映射到(0,1)的范围中,我们选择 sigmoid 作为激活函数。
与以往只使用查询-查询对或简单地将查询连接起来的表示作为会话表示的研究不同,我们的模型输入了包括查询和搜索上下文在内的所有信息流。相应地,我们设计了加权对比学习来创建更多的查询样本,并利用这些样本来解决长尾分布和曝光偏差的问题。
加权对比学习。 当用户只接触到一部分查询时,就会产生曝光偏差,因此未观察到的交互并不总是代表负面偏好。在我们的真实查询建议系统中,用户只会被曝光前 10 个查询词,他们的历史查询通常是满足长尾分布的。因此,我们引入加权对比学习来解决曝光偏差和长尾分布的问题。
考虑到当两个用户的相似度较高时,他们的行为可能趋于一致,我们按照以下方法构建了加权对比学习机制:首先计算当前用户表示与其他用户表示的相似度,然后选择排名前 n 的用户,过滤 ground truth 查询后将其候选查询添加为负样本;一些未被点击的随机查询也被添加为负样本。然后我们用这些样本来优化以下损失函数:
式中表示采用上述方法选择的当前用户与排名第𝑟的用户的相似度。
搜索流建模。 为了描述后续信息对下一次查询的影响,DFSM 根据用户的点击和浏览来预测搜索流。为了更好地捕捉搜索过程中的语义转移,我们将预测的语义影响与实际语义影响之间的 Euclidean 距离最小化为:
我们基于在线招聘平台 BOSS 直聘的数据集对所提出的 DFSM 模型进行验证,对比的方法包括:
Most Popular Suggestion(MPS)。它根据搜索会话中最后一个查询的共现频率对查询进行排序。
基于 GBDT 的排序模型(GRM),基于 GBDT 对候选查询进行排序。简历、职位和查询的每个值都被预处理为特征,作为模型的输入。我们用 Bag-of-Words(BoW)向量表示前缀、上下文和候选查询,然后用这些特征训练一个 LambdaMART 模型。
Behavioral Hypotheses Model(BHM)
[1]
,提出了一个包含行为假设的 encoder-decoder 模型。它还利用对多个行为假设的 attention 来聚合共享 BART 编码的多个行为假设。
DisentanglEd Self-atTentIve NEtwork(DESTINE)
[2]
。它明确地将一元特征重要性的计算与两两相互作用解耦。我们使用 DESTINE 构建用户表示和工作表示,然后将它们与查询级Transformer编码器连接起来,得到整体的表示。
Click Feedback-Aware Network(CFAN)
[3]
,将用户对之前建议查询的点击视为用户反馈,通过对抗性训练提高查询建议系统的鲁棒性。
Multi-View Multi-Task Attentive Approach(M2A)
[4]
,一个用于学习个性化查询自动完成模型的多视图多任务关注框架。它结合了 CTR 预测任务和查询生成任务,在公共数据集上取得了最优的性能表现。
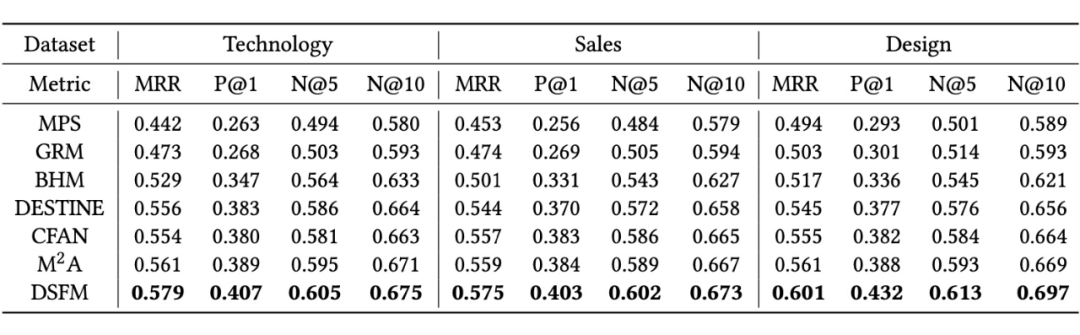
上表总结了各 baseline 模型和 DFSM 在 BOSS 直聘平台不同职类数据集上的实验结果。通过利用会话中的动态信息,DFSM 在所有数据集的所有评价指标中均获得了最高的分数。
具体来说,神经网络方法 BHM、DESTINE、CFAN 和 M2A 的表现极大优于传统方法。在所有基于深度学习的方法中,基于生成的方法 BHM 表现最差,这表明基于生成的方法在查询建议任务中产生了一些模糊的查询。
DESTINE 是一个明确地将一元特征重要性的计算从成对交互中解耦的方法,从 BHM 到 DESTINE 的改进表明在查询建议中准确地组织和利用用户简历和职位描述是重要的。CFAN 利用了更多的上下文,包括输入查询和搜索查询,并引入对抗性学习来提高整体性能,因此它的表现优于 DESTINE。这表明引入额外信息和对抗性学习对查询建议模型有利。此外,多视图多任务注意方法 M2A 略优于 CFAN。这主要是因为 M2A 提出了一种行为级 Transformer 编码器来精确利用用户行为。
在设计(Design)职类上,MPS 的表现比技术(Technology)和销售(Sales)职类更接近 GRM。我们认为,这是因为设计职类的职位分布比销售和技术行业更小众且集中。正如我们所看到的,我们提出的 DSFM 模型在设计职类上比其他 baseline 的表现有了显著的改进。这意味着我们的模型可以更好地处理更小、更集中的数据集。在所有数据集上,DFSM 方法的性能都优于 baseline 方法,证明了该模型的有效性。
[1] Ruey-Cheng Chen and Chia-Jung Lee. 2020. Incorporating Behavioral Hypotheses for Query Generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. 3105–3110.
[2] Yichen Xu, Yanqiao Zhu, Feng Yu, Qiang Liu, and Shu Wu. 2021. Disentangled Self-Attentive Neural Networks for Click-Through Rate Prediction. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3553––3557.
[3] Ruirui Li, Liangda Li, Xian Wu, Yunhong Zhou, and Wei Wang. 2019. Click Feedback-Aware Query Recommendation Using Adversarial Examples. In Proceedings of the 2019 World Wide Web Conference.
[4] Di Yin, Jiwei Tan, Zhe Zhang, Hongbo Deng, Shujian Huang, and Jiajun Chen. 2020. Learning to Generate Personalized Query Auto-Completions via a Multi-View Multi-Task Attentive Approach. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2998–2007.
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧