美团基于知识图谱的个性化新闻推荐系统

分享嘉宾:刘丹阳博士 美团 实习生
编辑整理:毛佳豪 中国平安浙江分公司(实习)
出品平台:DataFunTalk
导读:新闻阅读是人们日常生活中必不可少的活动,随着新闻逐渐从纸质端转变到电子端,大家可以从各种社交平台上进行新闻的阅读。同时,我们身处信息爆炸的时代,一天可能就有上万篇的新闻文章产生,这对于用户来说,会造成非常严重的信息过载的问题。因此,个性化新闻推荐系统就应运而生,它可以有效地提升了新闻服务的质量。本次分题目为《结合知识图谱的个性化新闻推荐系统》,主要介绍:
背景介绍
新闻知识图谱
知识图谱与新闻推荐的准确性
知识图谱与新闻推荐的可解释性
阅读新闻是人们日常生活中必不可少的活动,并且由于新闻阅读逐渐从纸质端转变到电子端,现在大家可以从各种社交平台上进行新闻的阅读。同时,身处信息爆炸的时代,一天可能就有上万篇的新闻文章产生,这样对于用户来说会造成非常严重的信息过载的问题。因此,个性化新闻推荐系统就应运而生,它能有效地提升新闻服务的质量。
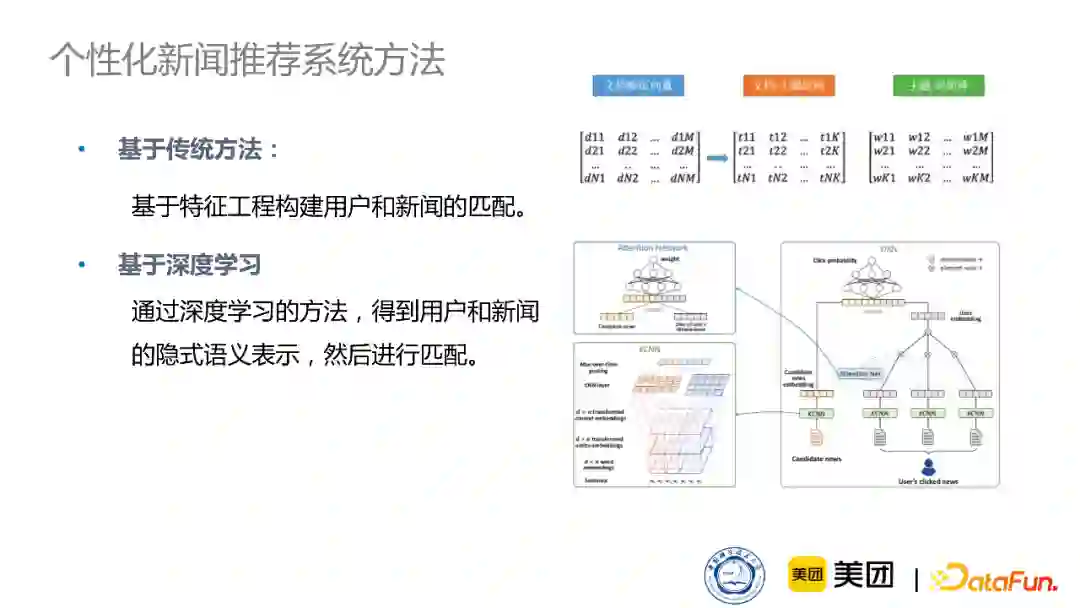
个性化新闻推荐系统的构建有两种方法:
基于传统方法:通过特征工程的方法构建用户和新闻的匹配。比如,将新闻的tf-idf特征和用户之前阅读的新闻的tf-idf特征进行直接匹配。
基于深度学习:通过学习用户和新闻的隐式语义表示,在隐向量空间里进行匹配,再对用户进行推荐。
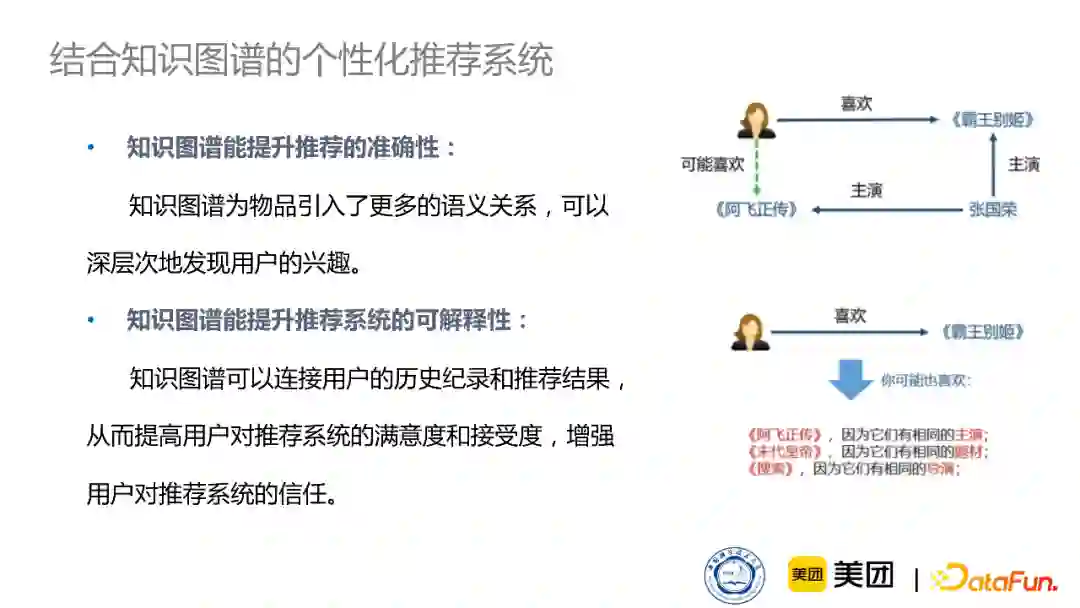
知识图谱能给个性化推荐系统带来哪些好处?
首先,知识图谱为物品引入了更多的语义关系,可以更深层次地发现用户的兴趣。比如用户看一个电影,通过知识图谱就可以知道电影的各种各样的信息,因此通过知识图谱就可以引入高质量的信息,包括用户的表示。同时,因为知识图谱是构建非常优良的图结构,通过连接用户和商品、商品和商品,就可以找到非常有意义的路径,并通过这些路径来构建可解释理由。因此,通过知识图谱就可以在给出推荐的同时,也给出推荐的理由,增强用户对推荐系统的满意度和接受度。
02
新闻知识图谱
1. 新闻知识图谱的研究动机
对于特定的推荐领域,需要专门设计的领域知识图谱,因为特定领域的知识图谱对该领域会更加适用,比如美团外卖就有外卖知识图谱,医疗应用有医疗知识图谱。而新闻推荐与其他领域比如外卖、医疗相比,它有其非常独到的特点——内容非常庞杂。新闻领域会涉及到各个方面的信息,并且由大量的文本构成。接下来,我会以例子去介绍,我们是如何去构建一个新闻知识图谱的,如何把和新闻无关的信息去掉,同时增加一些和新闻紧密相关的信息。
2. 新闻知识图谱的研究方法
首先,做新闻推荐一般都是用类似于百科的知识图谱,百科式的知识图谱构造非常精良,格式统一,知识全面。但是这也就存在了一个问题:包含了大量的与新闻推荐无关的信息,即它里面会包含大量的冗余信息。比如特朗普眼睛的颜色,这样的信息对于新闻推荐是没有太大的作用的。
构建图相关的应用的时候,节点会有很多的邻居,如果在采样的时候,采样到信息量比较少的节点,就会非常影响最终的推荐效果。
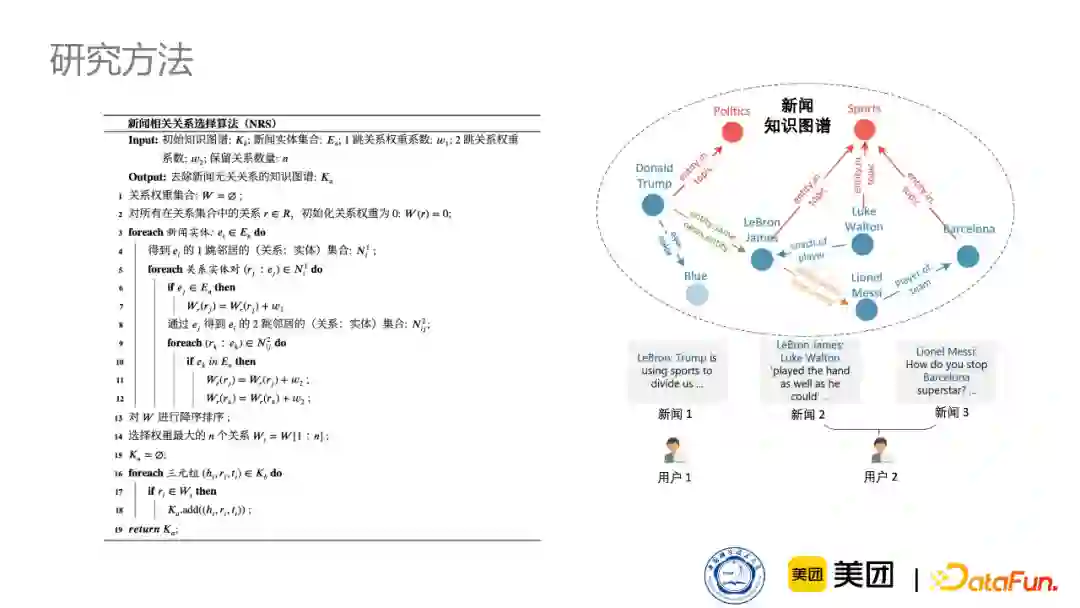
所以我们设计了一个非常简单的选择算法,把跟新闻相关的信息选择进来,主要思想是:
首先统计大量的新闻语料,我们收集了可能几十万上百万篇的新闻语料。然后,把出现在新闻语料中的知识实体当成种子节点,再以这些种子节点为中心,往外层扩展,比如扩展一跳或者两跳,如果一跳或者两跳能到达一些最初的种子节点范围内,就认定这个是跟新闻更加相关的关系。最后,对一跳、两跳分别赋予不同的权重,并统计各种关系的权重,然后把最重要的关系保留下来,同时保存这个关系下的三元组,这就是选择与新闻相关信息的方法。
同时,我们也补充了一些跟新闻相关的特定信息,比如用户在阅读新闻的时候,会非常关注新闻的主题,并且每个用户的兴趣都是比较固定的,比较喜欢某一类的新闻。因此,主题对新闻推荐来说,是至关重要的。所以,我们增加了两种类型的主题节点:显式主题节点、隐式主题节点。
显式主题节点是新闻本身所属的类别,这在编辑中就能体现出来,比如它是体育新闻,是NBA新闻还是足球新闻等等;同时,我们通过LDA topic model也可以对它训练一些隐式的语义节点,作为主题节点增加进来。然后我们通过连接出现在这篇新闻中的实体和主题节点,来构建与新增加的主题相关的三元组。同时,虽然一些新闻实体在知识图谱中没有直接相连,但是它们其实能强烈地体现在新闻阅读习惯中。比如经常出现在同一篇新闻中的实体,或者同一用户感兴趣的实体,这些实体其实反映了用户行为或者新闻本身特征的一个协同关系。举例说明,比如你是个足球迷,你在看到梅西相关新闻的时候,可能也会关注C罗,但是他们在知识图谱中没有直接相连,然后我们通过增加这样的一些连接关系,来丰富新闻领域的知识图谱。
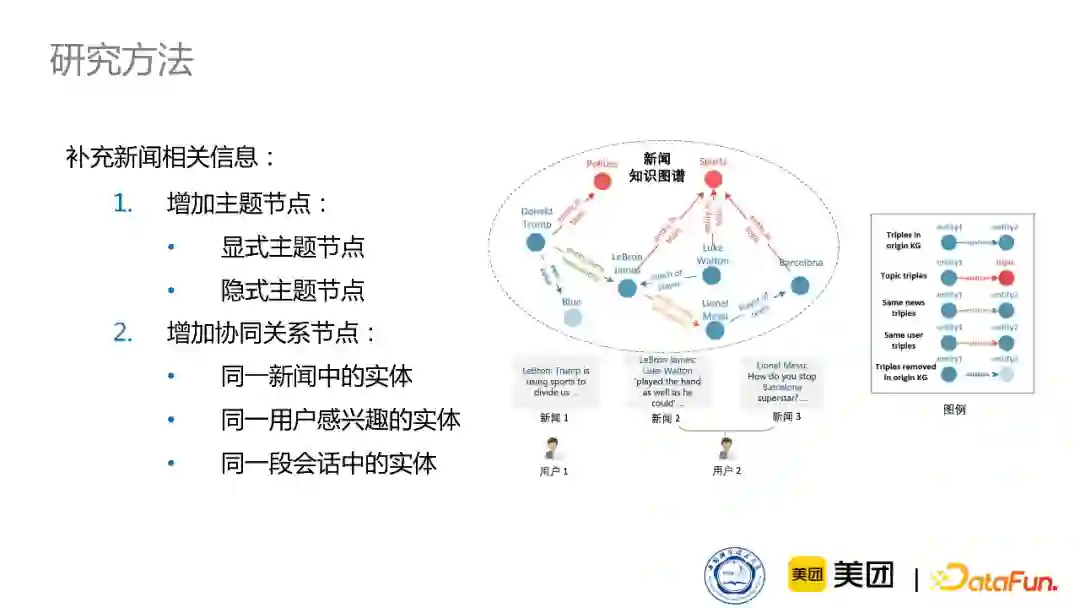
3. 实验过程
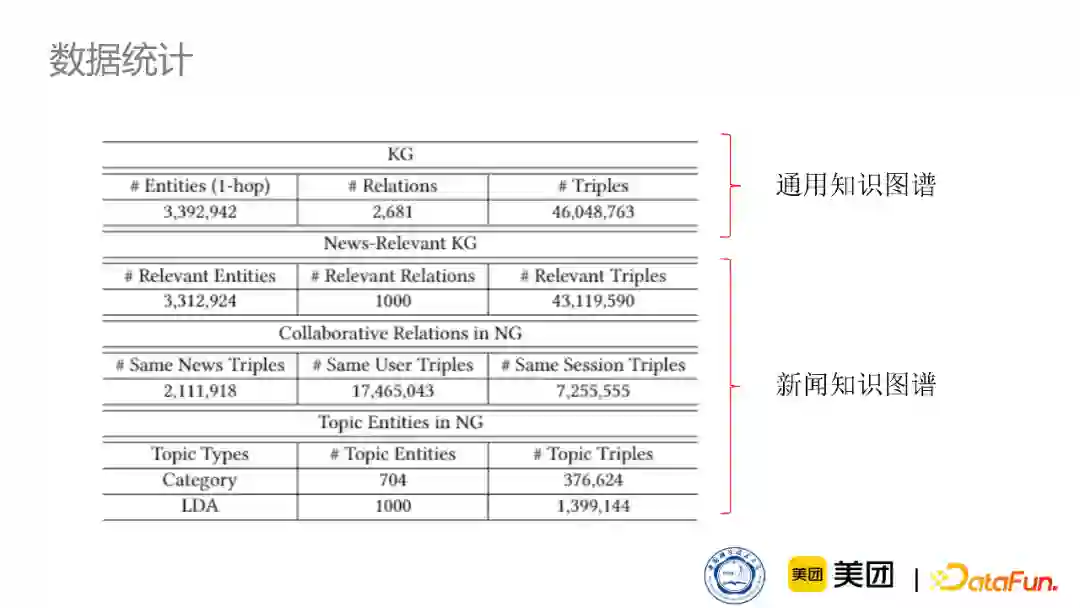
①图谱数据统计
下图是通用知识图谱和我们修改得到的新闻知识图谱的数据对比情况,KG是原始的新闻知识图谱,News-Relevant KG是去掉无关关系后的知识图谱,Collaborative Relations in NG是增加了协同关系的知识图谱, Topic Entities in NG是主题节点的知识图谱。
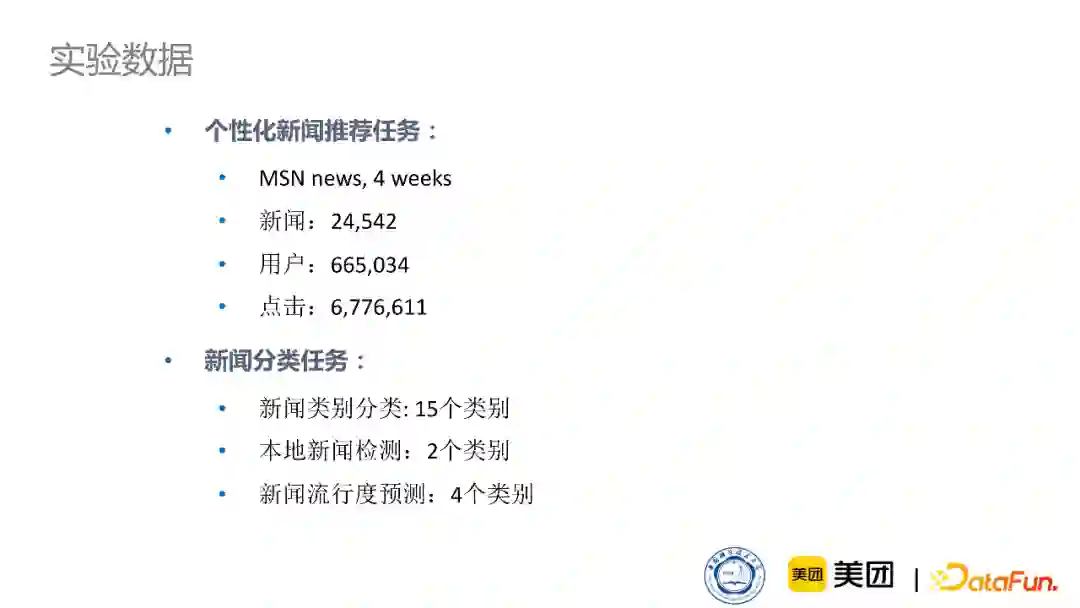
②实验数据介绍
我们选取了MSN新闻四周的语料用来测试我们通用知识图谱和新闻知识图谱,进行对比。同时我们在多种推荐任务上都进行了测试,比如我们最擅长的个性化新闻推荐任务还有新闻分类任务。
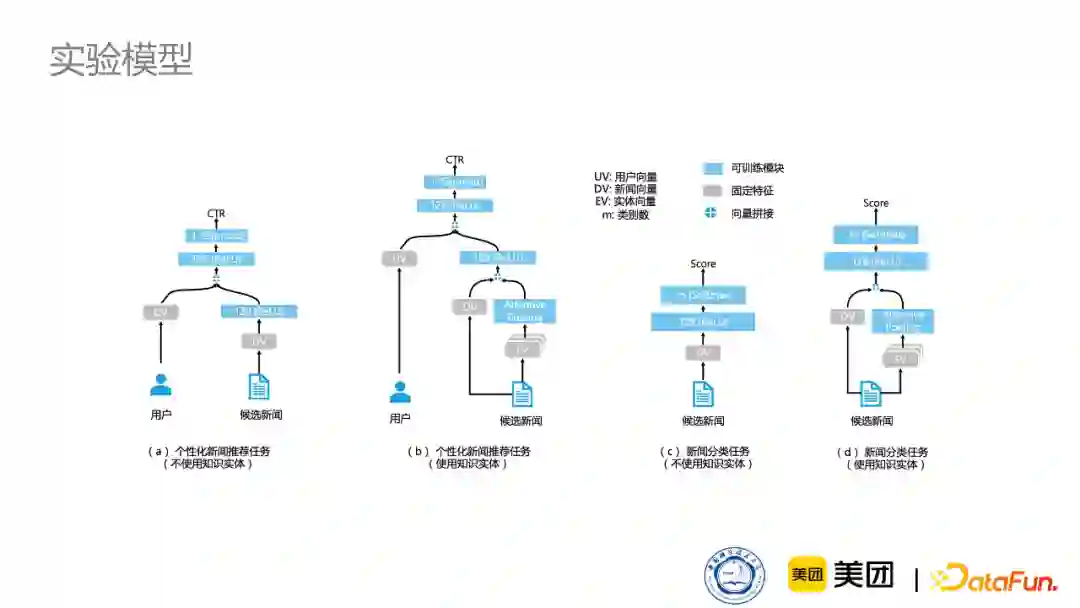
③实验模型介绍
为了更直观地验证效果,我们选择了非常简单的模型,仅仅用到了新闻向量和用户向量,再加上通过知识图谱预训练得到的实体向量。其中,我们对比了两种实体向量,分别是通用知识图谱训练出来的实体向量以及新闻知识图谱训练出来的实体向量。如下图所示,在不同的任务上,我们使用了不同的架构。
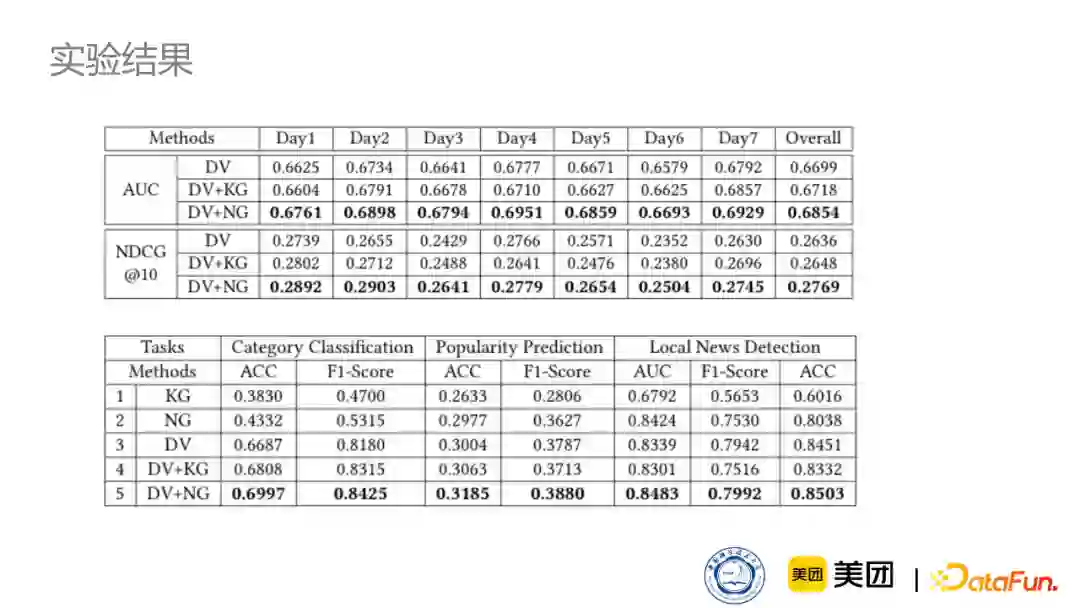
④实验结果
下图是实验结果,对比的是不使用知识图谱的结果、使用通用知识图谱以及新闻知识图谱的结果,上面的表格各模型在个性化推荐任务上的表现,下面的表格是模型在不同的新闻分类任务上的表现。可以看到,新闻知识图谱相对于通用知识图谱是有提升的,说明了新闻知识图谱构建的有效性。而我们也会将新闻知识图谱作为一个基础,应用到后面的工作中。
03
知识图谱与新闻推荐的准确性
1. 新闻推荐特点
新闻推荐系统与其他推荐系统相比,还是存在非常鲜明的不同点的。
首先,新闻推荐有很强的时效性,比如我们不会关注一周前发生了什么新闻,只关心今天发生了什么新闻,这样会造成非常严重的冷启动问题。
其次,理解新闻内容本身的内容是非常重要的。新闻里包含了大量的知识实体,比如人名、地名、事件等等,而知识图谱可以给新闻带来一个非常好的补充,因此知识图谱对新闻推荐有独特的重要意义。
最后,用户在阅读新闻的时候,兴趣也是多样的,比如既关心政治又关心体育。并且随着时间推移以及热点新闻的不断出现,他们的兴趣也会发生一些动态的演化。
因此,对于新闻推荐来说,最主要的几个模块是:如何建模新闻、如何根据用户新闻阅读历史建模用户、如何将新闻建模与用户建模进行个性化的匹配。
2. 知识图谱与新闻推荐结合的研究动机
接下来的工作是我们发表在Recsys2020会议中的一个工作,该工作介绍了如何更好地利用新闻中的知识实体来提升新闻的表示。
首先,介绍一下该工作的问题背景:新闻中包含了大量的知识实体,这些知识实体可以非常好地帮助我们理解新闻内容,不过一篇新闻文章可能会包含几十个实体,每个实体出现的次数可能都不一样,该如何衡量这些知识实体的重要性?并且如何将知识实体和新闻本身的表示进行结合也是非常棘手的问题。同时,因为NLP技术、新闻文本表示技术都在日新月异地发展,我们不可能在每一个新的模型出来时,再针对性地设计一个结合知识的模型,这样工作量就会比较大。所以我们研究的是如何将知识信息融合到我们预训练好的新闻表示中,得到一个更好的表示,来提升最终新闻推荐的效果。

3. 知识图谱与新闻推荐结合的研究方法
①模型结构
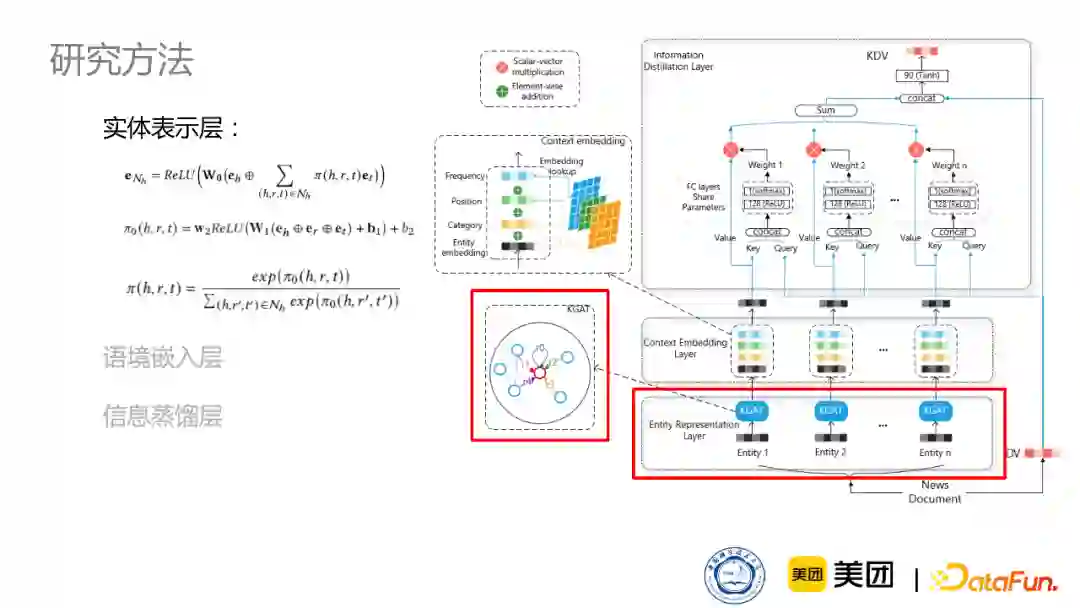
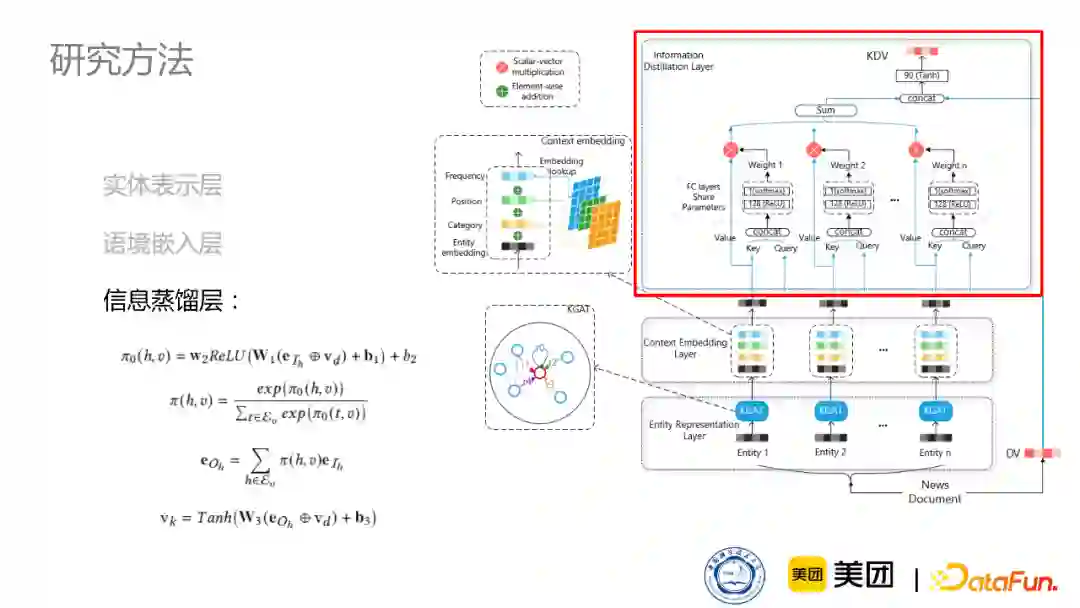
为此,我们设计了一个模型,该模型主要核心有三层:实体表示层、语境嵌入层、信息蒸馏层。通过这三层,给根据NLP模型得到的新闻表示DV注入一个知识实体的信息,得到一个知识增强的新闻表示。
第一层是实体表示层。首先,把出现在这篇新闻中的实体通过预训练的方式取出,但是不同的实体在知识图谱中有各种各样的邻居,这些邻居也能够丰富它的表示,因此我们采取一种KGAT的方式,通过考虑它不同的关系,来聚合它的邻居信息,从而得到更全面的出现在新闻中的实体表示。
第二层是语境嵌入层,这一层主要考虑实体在新闻文章当中的嵌入特点,比如出现的位置是在文章的title里还是body又或者是出现的频次、实体类别是人物还是地点等等。这些信息对于实体信息都是有非常重要的作用,所以我们设计了语境嵌入层来更加全面地建模这个实体。
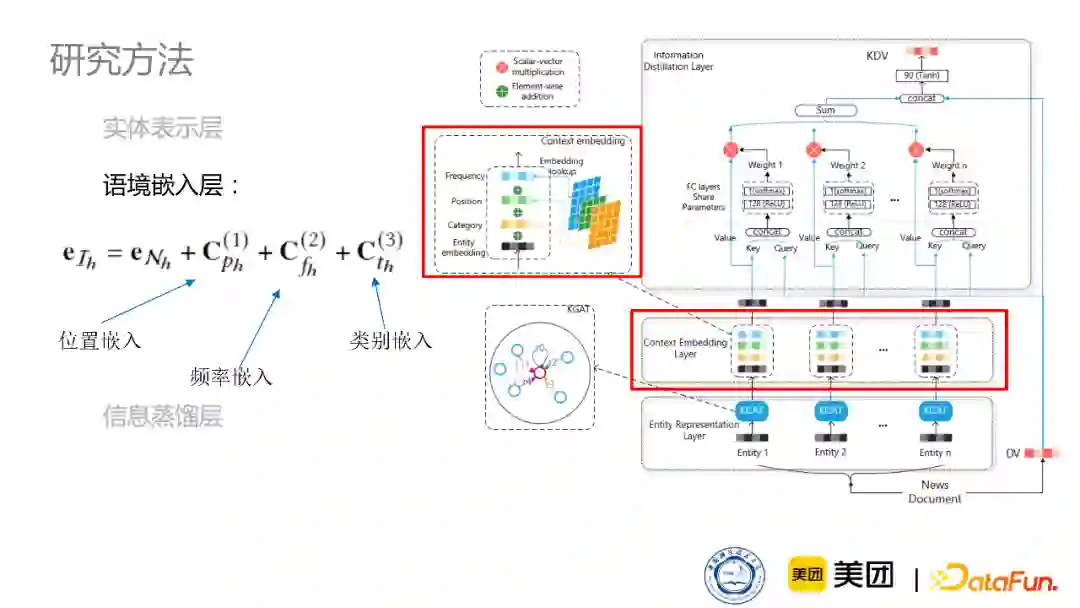
第三层是信息蒸馏层,其目的是判断不同的实体在不同的新闻中的重要性。比如体育新闻中,体育明星的重要性会更高,湖人队的新闻中,可能詹姆斯的重要性会更高一些。所以我们将新闻的文本表示作为监测信号,去监督不同实体的重要性并进行重要性的加权,最后拼接到本身的初始新闻表示上,得到知识增强的新闻表示。
②训练框架
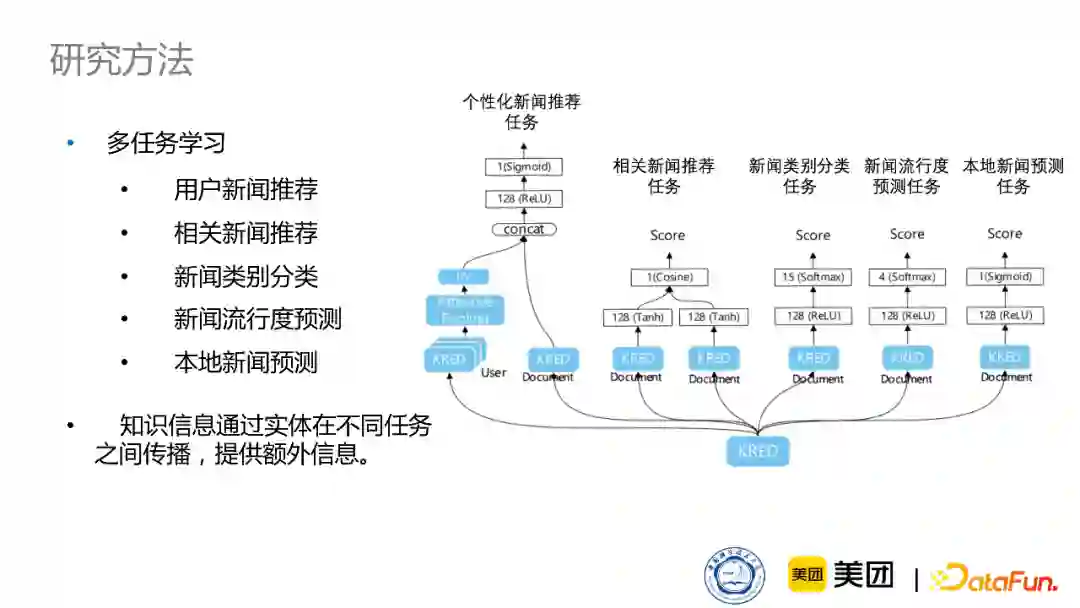
同时我们的框架也可以采取一种多任务学习的方式,因为对于不同的新闻推荐任务来说,任务之间的各种标签会提供一些额外的信息。比如我们通过本地新闻预测任务,来预测新闻是不是与本地相关。在此任务中,知识实体也可以提供不同程度的帮助,有些知识实体是地点,对于本地新闻预测任务就会起到很好的帮助。并且,不同的新闻任务之间也会传递一些信息,通过知识实体来把不同任务之间的标签进行传递,从而对不同任务起到促进作用。
③实验结果
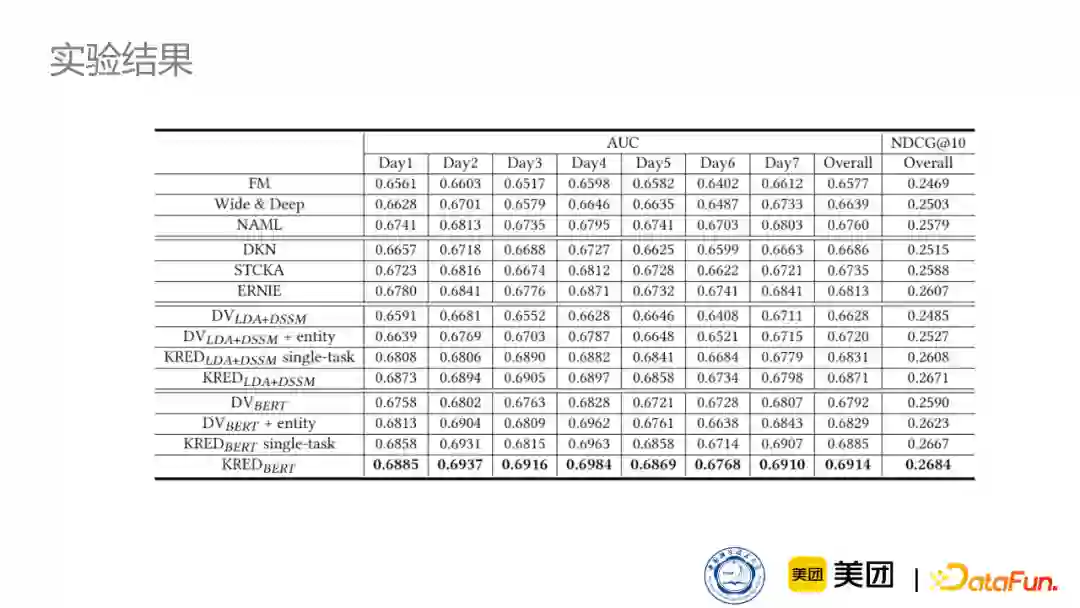
下图是个性化推荐任务上的结果,我们采用了两种基础的新闻向量表示方法,一种是实际业务中使用的LDA+DSSM,另一种是学术界使用非常多的BERT模型。根据这两种模型得到新闻的预训练表示之后,再结合知识实体,并通过我们设计的模型去增强这两种表示。结果显示,无论是在LDA+DSSM模型还是BERT模型上,我们对于这两种基础向量都取得了效果上的提升。因为BERT模型具有强大的表示能力,并且有非常强大的预训练的库,所以会比业务中使用的LDA+DSSM模型效果表示得好一些。
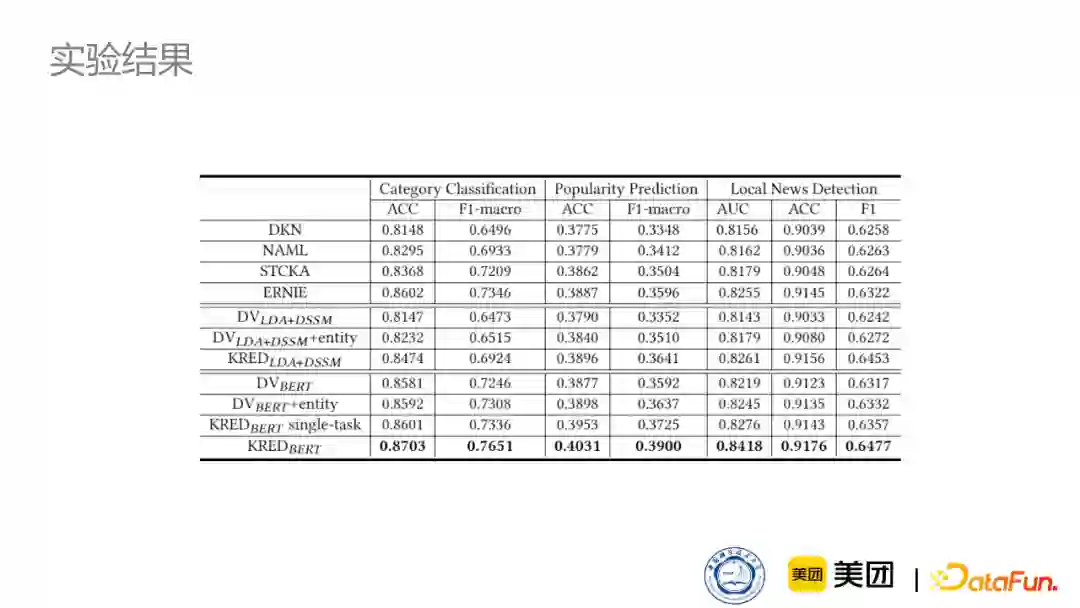
下图是在不同新闻分类任务上的结果:
在item2item的推荐实验上,我们的模型也是取得了比之前baseline更好的效果。
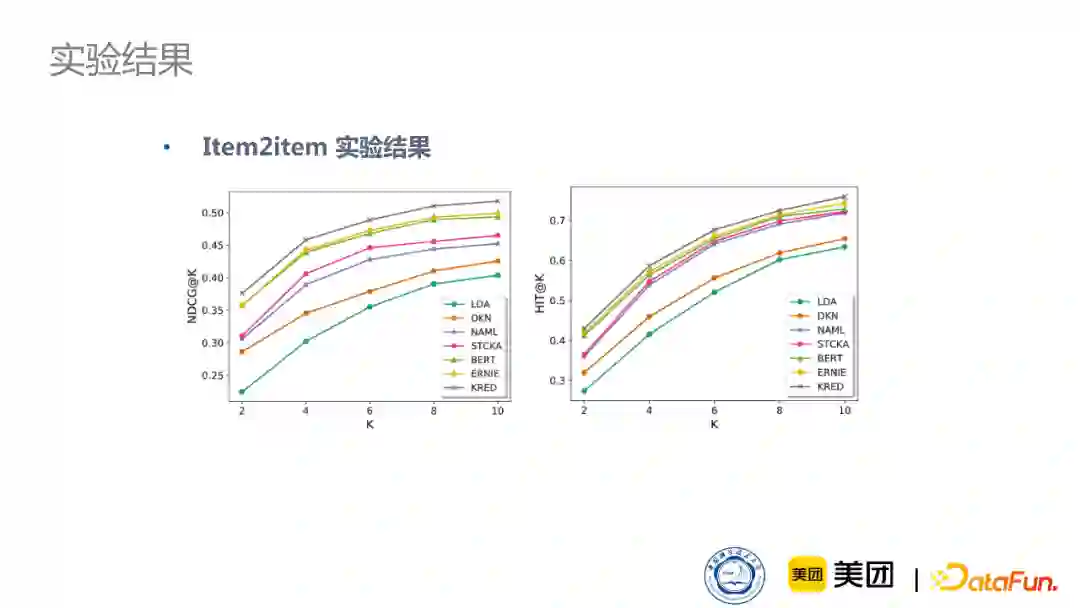
我们也进行了消融实验,将我们模型核心的三层模块进行比较,通过消融实验证明我们每个模块都起到了非常好的作用。由于我们的模型是在预训练表示的基础上再注入知识,所以效率其实是非常高的。相对于以前的一些模型,无论是在训练还是测试任务上,我们的模型在效率上还是非常占优势的。
④可视化分析
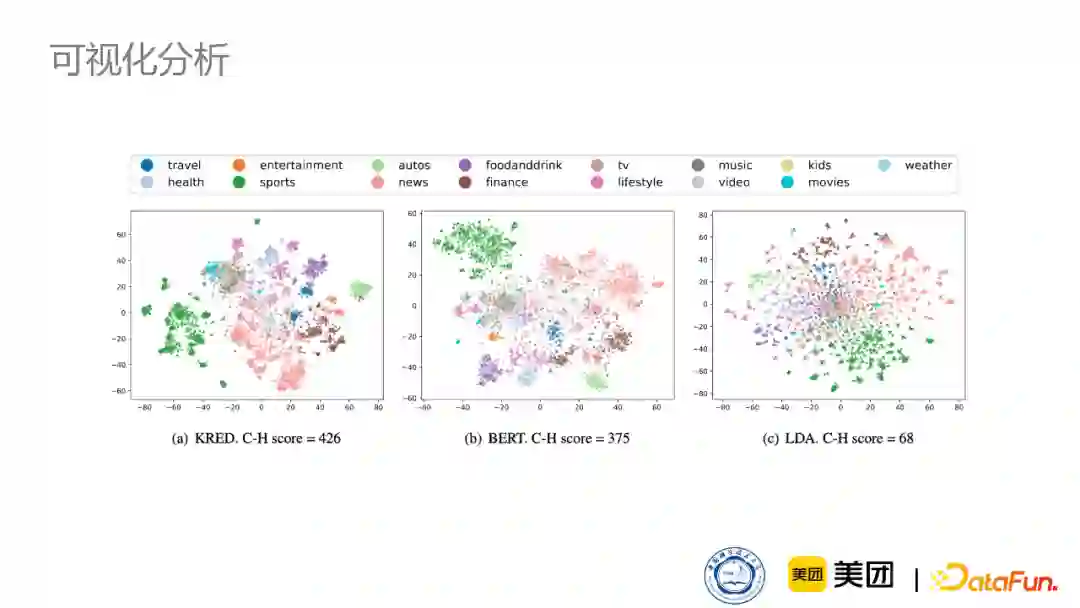
同时我们也做了可视化的分析,下图展示了模型在一篇新闻中最终学到的weight在不同知识实体上的表现。可以看到,对于这篇新闻来说,重要的实体会学习到更高的权重。

下图是我们对于最终生成的向量表示做的一个可视化,以此来证明向量在不同的类别上有更加明显的区分,也说明我们得到的知识增强的向量所学习到的信息是更好的。
4. 我所做的工作
①研究动机
接下来介绍我在美团做的工作,我的工作主要动机有三个:
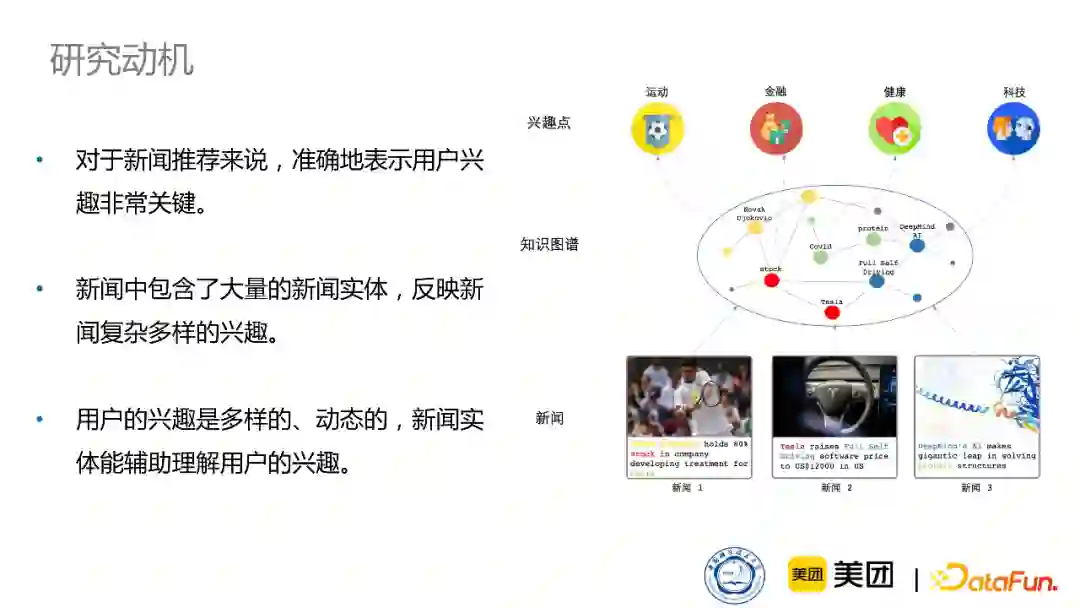
首先,上文讲述了如何通过知识图谱增强新闻的表示,但对于新闻推荐来说,准确地表示用户兴趣也非常关键,所以我们更深层次地研究如何利用知识图谱来更加全面地建模用户在新闻阅读过程中的兴趣的表示。
其次,新闻中其实包含了大量的新闻实体,这些实体能反映一篇新闻复杂多样的兴趣。新闻不同于商品,内容更加复杂,一篇新闻中往往会包含各种各样的兴趣,所以引入知识可以更加全面地了解一篇新闻的兴趣。在此基础上,我们就可以进一步了解用户的多样的、动态的兴趣。
②研究方法
下面介绍一下具体的工作。
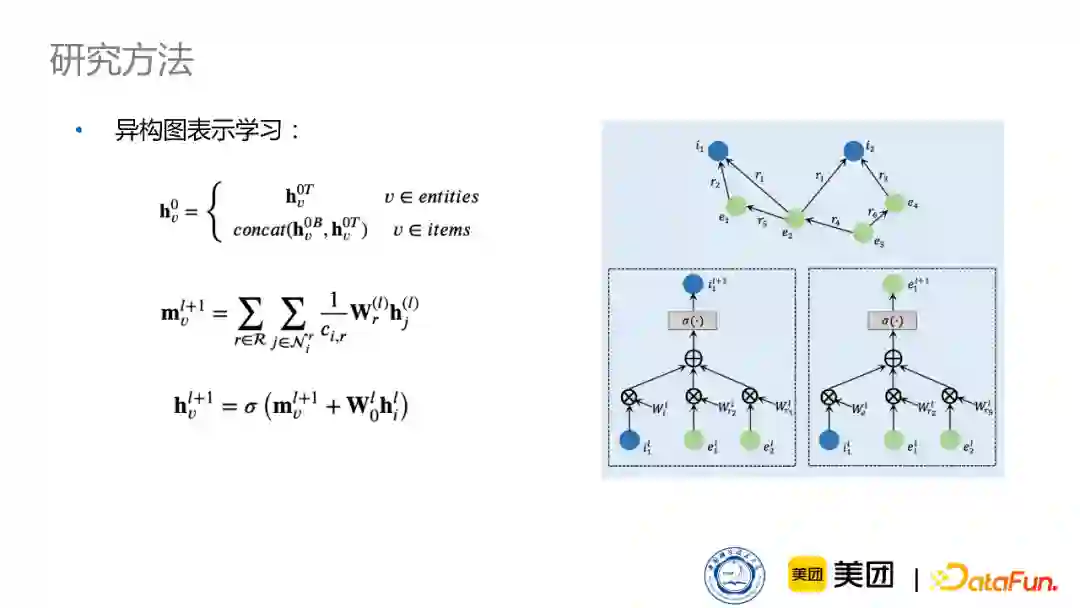
首先是异构图表示学习的方法。新闻本身包含了丰富的文本信息,同时我们通过把它和知识图谱进行连接,得到一个空间的结构化信息。所以我们一方面可以通过一些预训练的模型,得到文本信息的表示,同时也可以通过图学习的结构信息,得到空间结构的表示,最后通过异构图学习的方式,将这两种不同的信息表示融合到一个向量空间里。
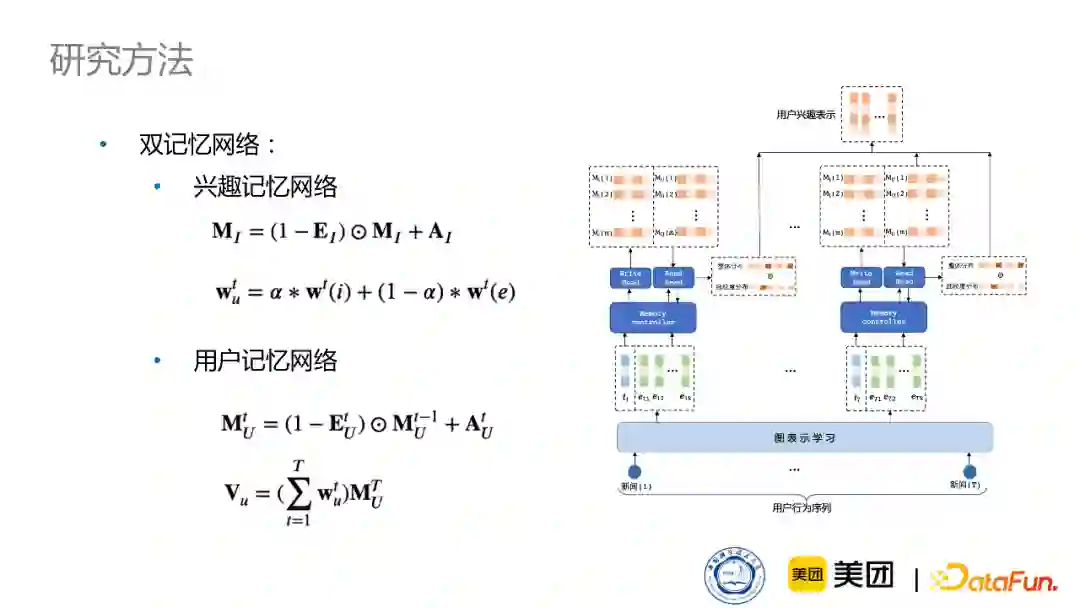
接下来,我又设计了双记忆网络模型来建模用户的多种多样的信息表示。使用记忆网络是因为它有两个非常显著的优势。
对于建模序列化信息,它有非常好的优势。记忆网络,顾名思义,相对于GRU或者LSTM来说,具有更强的记忆能力,因此在建模更长的序列信息时,它有更好的学习能力。
多槽的构造使它对于学习用户的多兴趣或者多向量表示,有天生的结构优势。
因此我这里采用了一个双记忆网络,用兴趣记忆网络学习兴趣的表示,同时用户记忆网络去建模序列化信息。其中,对于兴趣,我们也从两个方面进行建模:
首先,从文章总体的兴趣考虑;其次,因为文章中包含很多实体,所以我们从更细粒度的层次——实体角度,来建模用户的兴趣表示。最终会得到用户总体的兴趣分布和细粒度的兴趣分布,这两个兴趣分布具有相辅相成的作用。
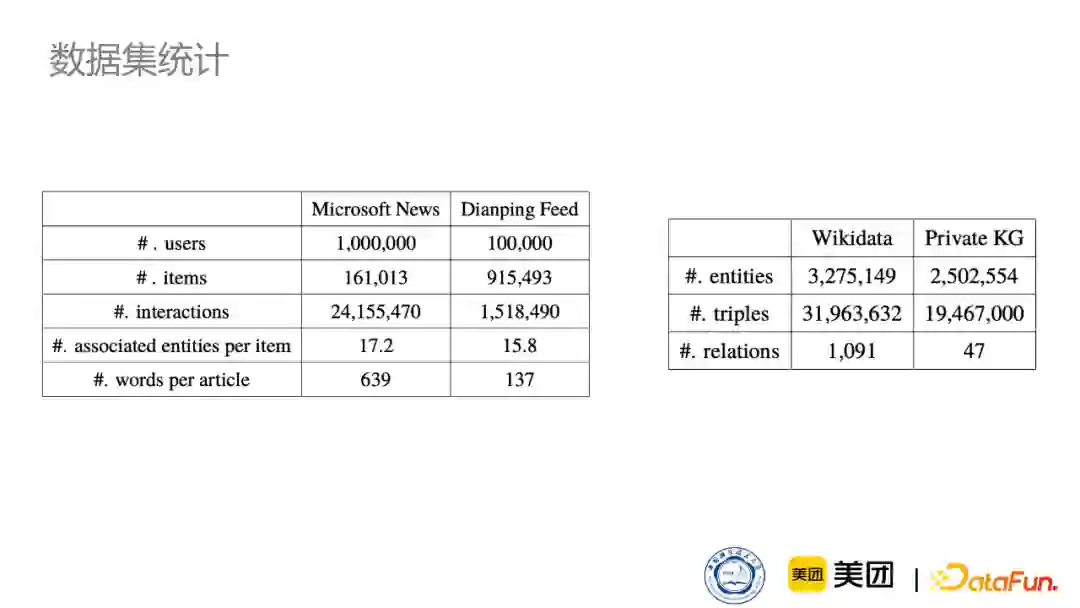
下图是我们的数据集,同时应用了Microsoft News还有美团的点评数据集。
③实验结果
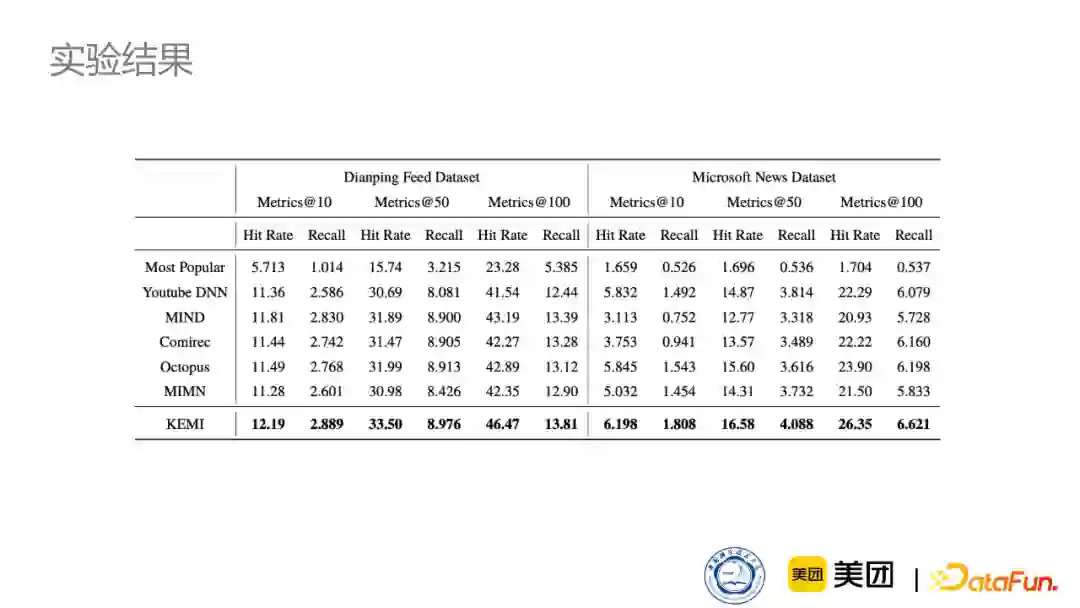
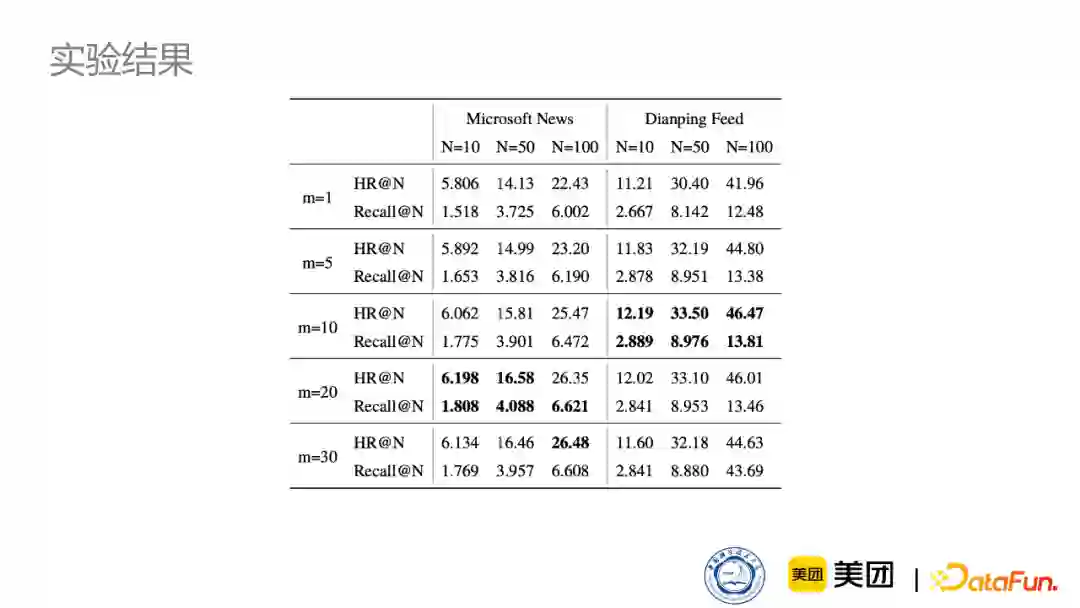
从下表可见,模型在两种不同的数据集上都取得了比baseline更好的效果。
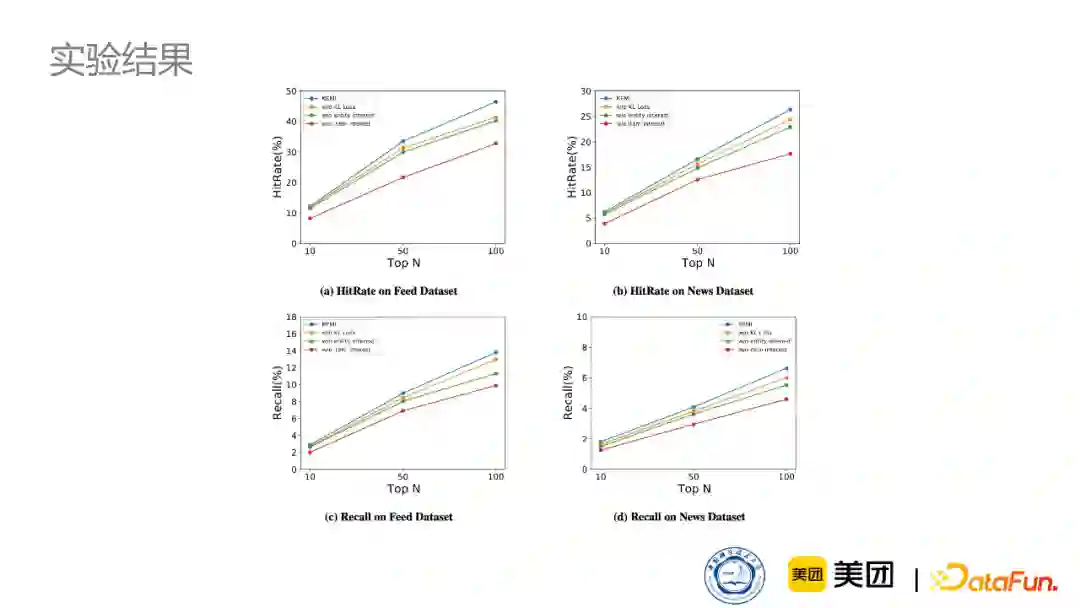
同时,我们对于不同的数据集实验了不同的兴趣数量,可以看到,在Microsoft news上,兴趣数量要比点评数据集上稍微多一点,主要是因为Microsoft news的新闻更加多样性,可以反映用户更多的兴趣。
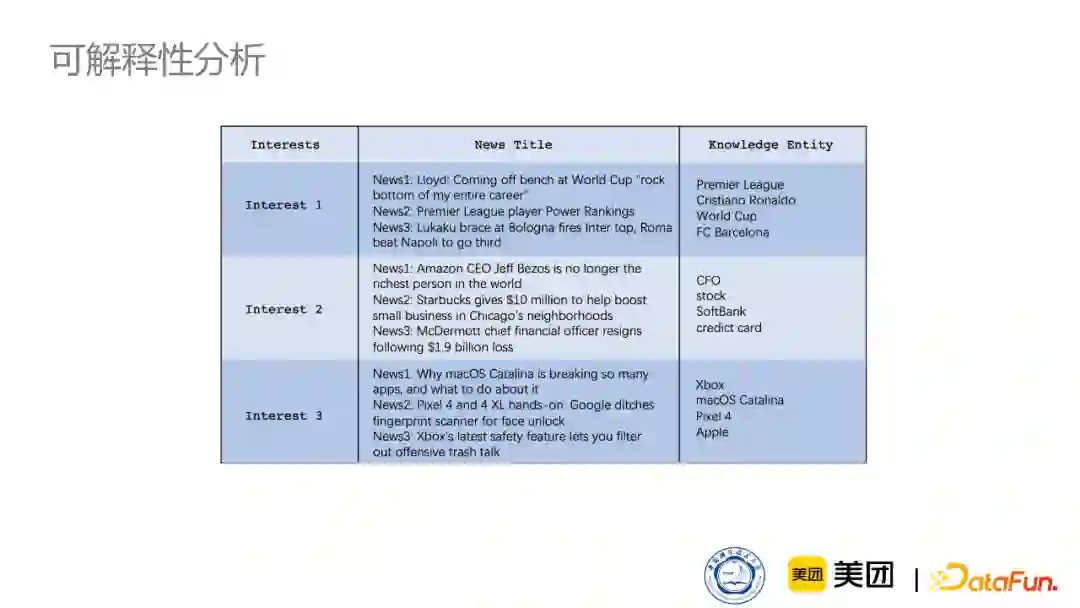
下图是我们做的可解释性的简略分析。引入知识图谱的一个好处是在分析用户兴趣的时候,不光可以在新闻的层次上进行分析,还可以在更加基本更加底层的实体表示层次进行兴趣分析,这样它的兴趣会更加直观。
04
知识图谱与新闻推荐的可解释性
1. 研究动机
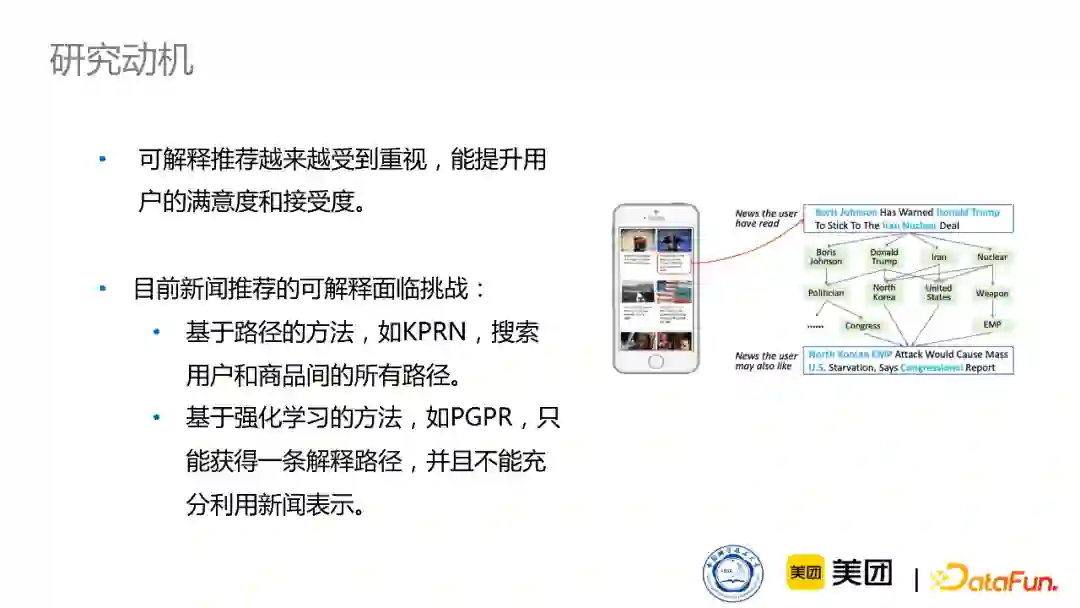
随着技术的发展,很多推荐系统的效果已经非常优良了,所以我们现在更多时候会关注一些更深层次的东西,比如可解释性的效果,这个对于提升用户接受度和满意度是非常有帮助的。
商品推荐可能已经有可解释性工作了,那新闻推荐和商品推荐的可解释性工作有什么不同的地方?
首先,新闻中包含了大量的实体,并且新闻知识图谱也比商品知识图谱要复杂得多,比如新闻知识图谱关系可能有上千种,但亚马逊的商品知识图谱可能只有十几种关系。因此,对于如此复杂的数据和图,如何生成可解释路径是非常有挑战性的工作。
现在也有一些解决的方法,有基于路径的方法,比如KPRN模型,它先搜索用户和商品之间所有的路径,然后对所有路径进行打分,再进行排序,最终选择比较优秀的可解释路径。还有一些基于强化学习的方法,比如PGPR模型,它从用户出发,进行游走,游走到一个item后,就把这个游走的路径作为一个可解释路径。不过新闻中包含了大量实体,所以如果在用户与新闻之间,只给出一条可解释路径,可能会与用户在阅读新闻时关注的地方不同。这样的话,也会造成不全面的问题。
2. 研究方法
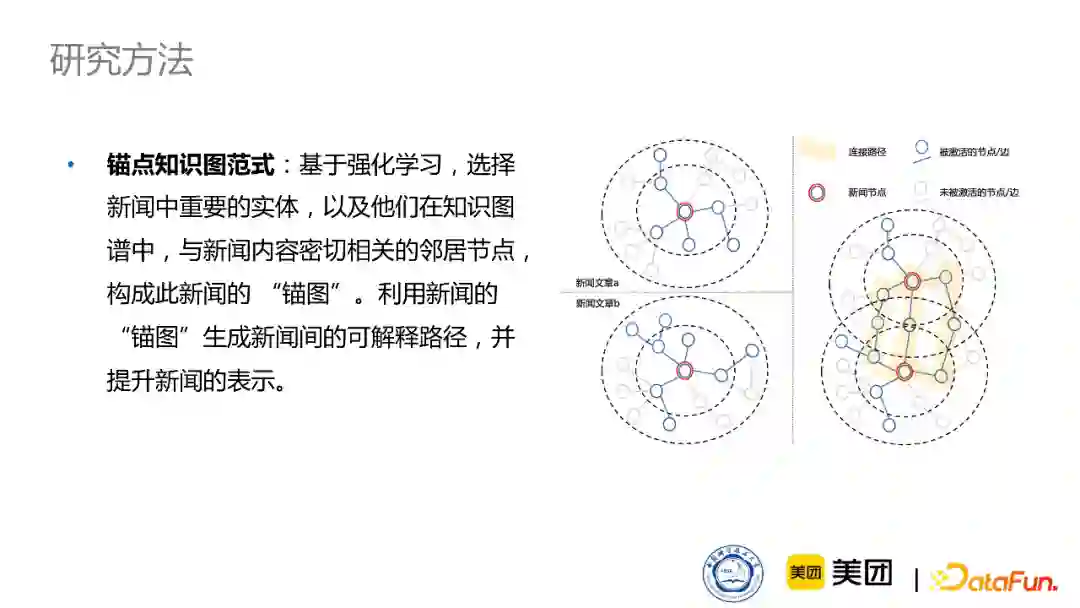
针对这个问题,我们另辟蹊径地设计了一个比较新颖的可解释的范式——锚点知识图。具体原理是:
在做可解释推荐之前,对于每篇新闻都相对应地生成一个锚点知识图,所谓的锚点知识图就是以这篇新闻的节点出发,去搜索与这篇新闻紧密相关的知识实体,比如节点的一跳是包含在这篇新闻中的实体,那我会在这些实体中选择对这篇新闻来说比较重要的实体,并继续选择这些实体在图谱中的邻居。通过这样的选择机制,我们可以给每篇新闻生成一个针对于它的一个紧密的子图,这个图的规模一般在百这种数量级上。在给每篇新闻生成一个锚点知识图之后,我们就可以通过两篇新闻之间的锚点知识图的交互,生成解释路径。相关的新闻之间可能会生成多条路径,而不相关的新闻可能就不需要可解释路径了。
生成锚点知识图采取的方法也是基于强化学习的方法,我们设计了一个MDP决策过程,定义了状态、动作、状态转移三个模块。其中,比较创新的地方在于我们设计了多种多样的奖励机制,比如即时奖励和终止奖励,即时奖励就是在生成锚点知识图的过程中,我们会立刻赋予它一个奖励数值,例如在走到知识图谱上的一个节点的时候,我会立即判断一下,该节点是不是与知识图谱紧密相关的。同时在锚点知识图生成结束之后,会有一个终止奖励,即知识图生成之后,我们会判断一下这个锚点知识图是不是真的与相关的新闻之间产生了比较高质量的解释路径,同时锚点知识图的生成,也会选择一些与新闻比较相关的节点,这些知识节点是不是真的对于新闻推荐有帮助,我们通过这样不同的奖励机制来保证学习过程。
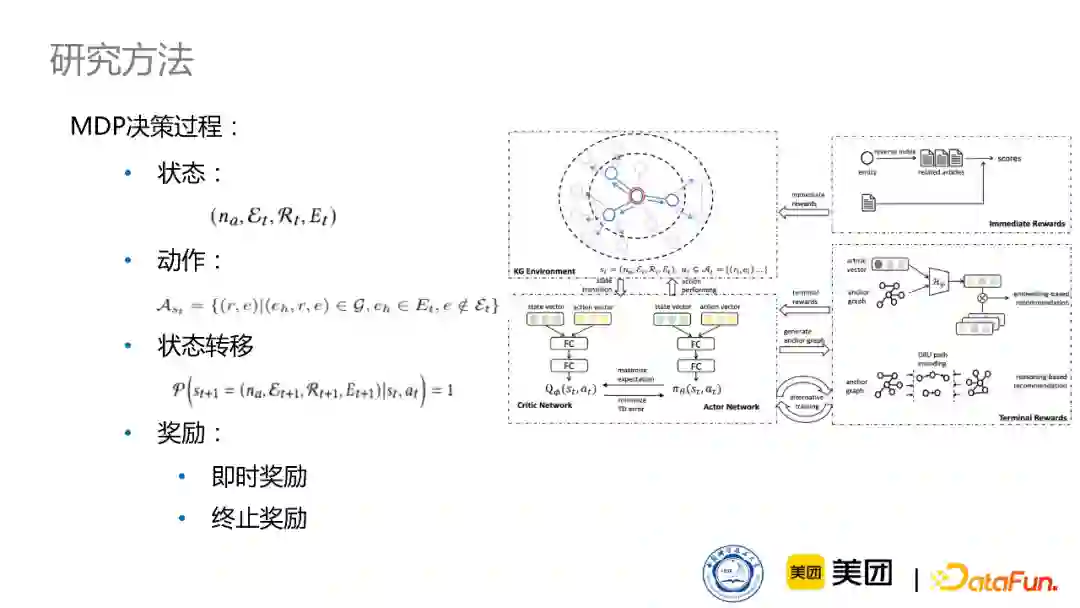
接下来,我们采用演员评论家(actor-critic)算法来训练强化学习网络。演员会根据策略函数,来选择加入锚点知识图中的实体,而我们会通过最大化期望去学习这个演员网络,同时评论家会根据值函数来评估动作选择的好坏。这个过程通过最小化TD error来进行训练。
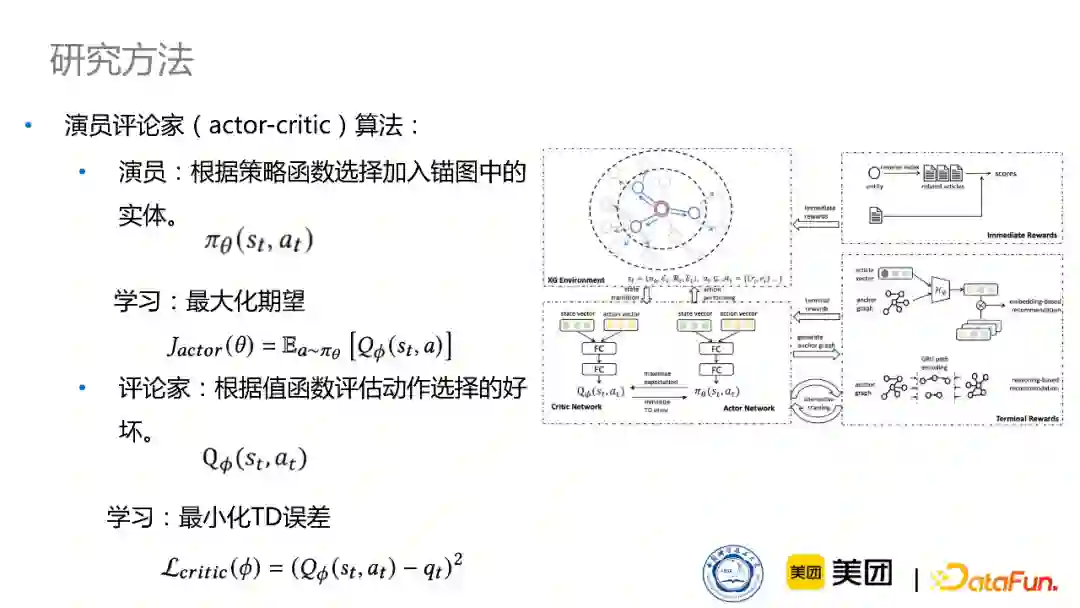
并且我们也采取了多种学习策略来使它更容易学习。首先是热启动训练,我们会选取一个小数据集,去枚举一些路径,通过这个路径来产生监督学习的label,再通过这些label来去初始训练actor-critic网络。同时因为新闻知识图谱比较复杂,对于两篇新闻来说,如果我们选取到完全不相关的两篇新闻作为负样本的话,可能学习不到有用的信息。因此我们采取了在知识图谱上进行游走的策略,让它能更加有效地学习。最后我们会联合训练推荐任务和推理任务,来达到一个多任务学习的更好的效果。

3. 实验结果
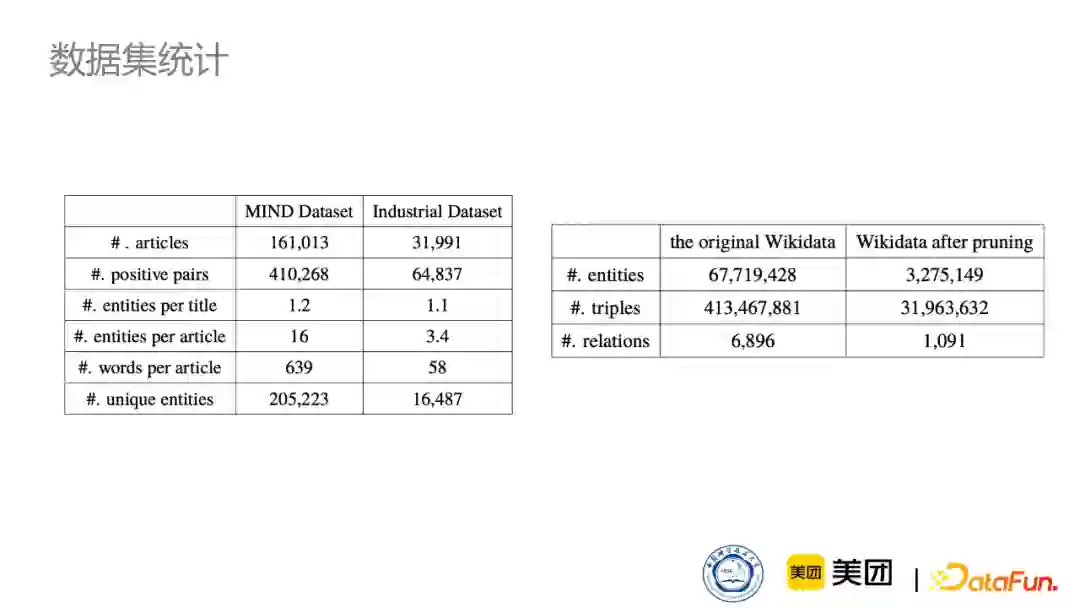
我们这里采取的是微软的新闻推荐数据集还有一个工业数据集:
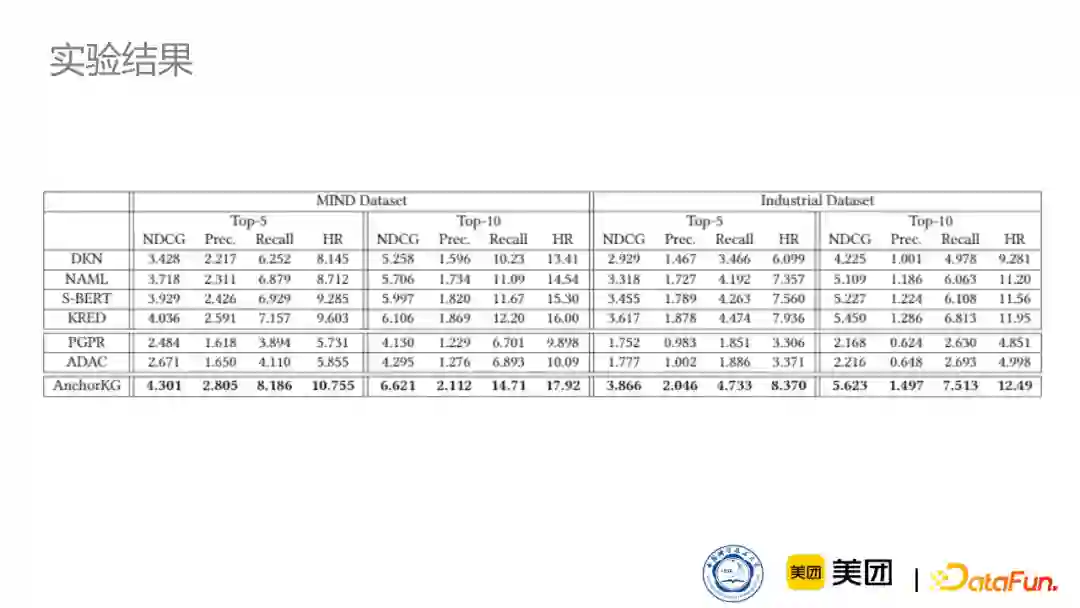
如下表所示,我们选取了两类baseline与我们的模型进行对比。一类是DKN、NAML等传统的新闻推荐方法,这些方法是不具有可解释性的。另一类是基于强化学习的推荐算法PGPR、ADAC,这些推荐算法不能有效利用新闻的文本信息,因此效果比较差。而我们的方法既可以生成可解释路径,同时因为锚点知识图的生成,它也会选取一些跟新闻紧密相关的实体,在一定程度上增强了新闻的表示,在推荐上也取得了不错的效果。
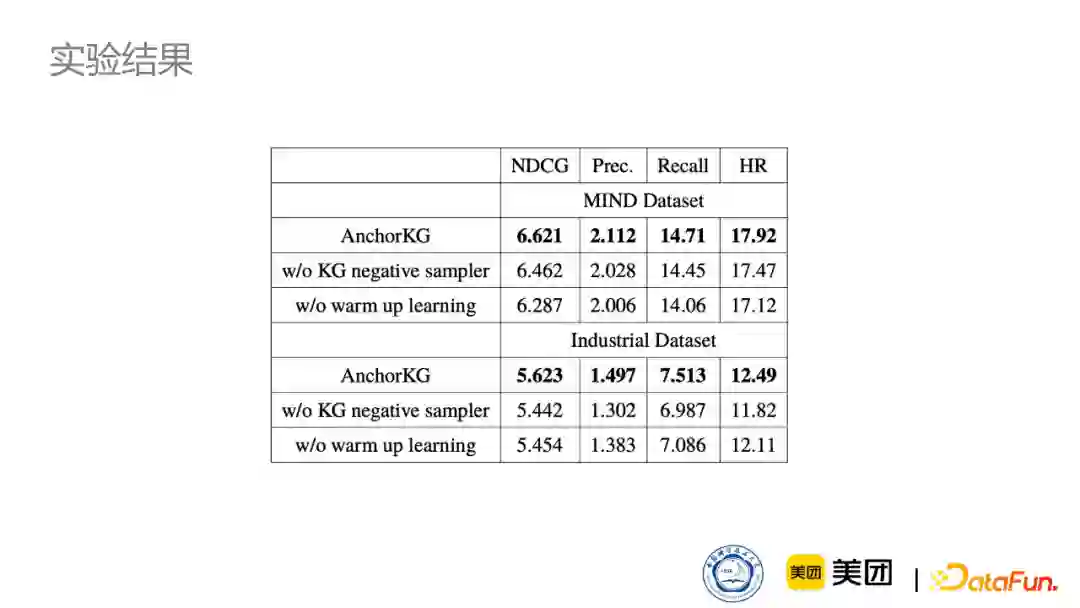
下表是消融实验的结果。可以看到,去除一些模块,效果会有明显下降。
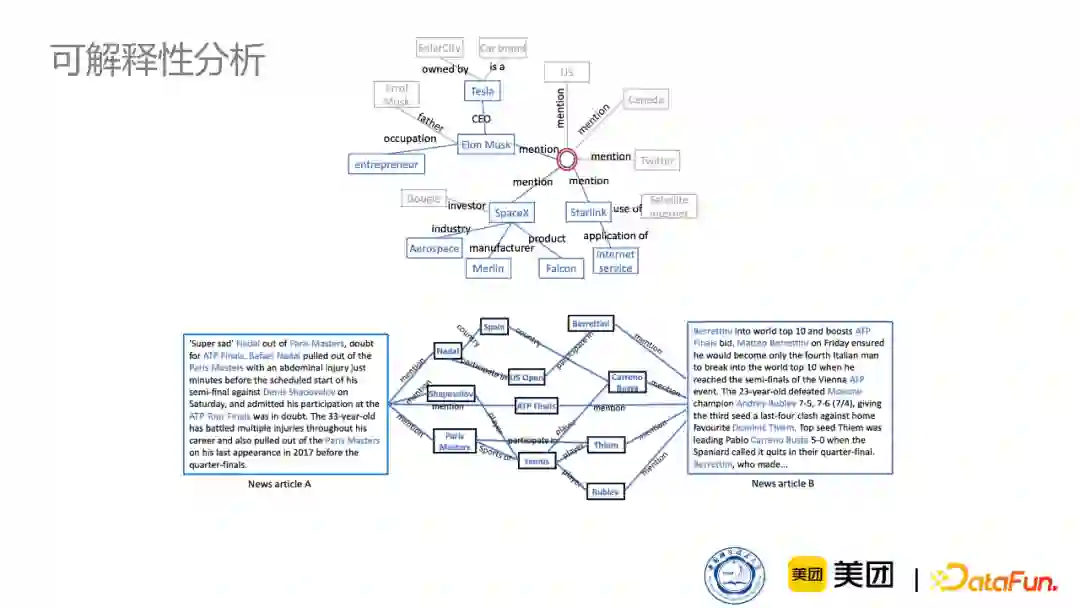
下图是可解释性分析,上面区域展示了部分锚点知识图。可以看到,对一个新闻来说,它会朝着与它相关的方向去选择锚点知识图,而跟新闻不太相关的知识实体如”US”就没有包含在锚点知识图中。在下面区域展示了两篇新闻通过锚点知识图的交互就可以产生多条的可解释路径。
4. 可解释性分析
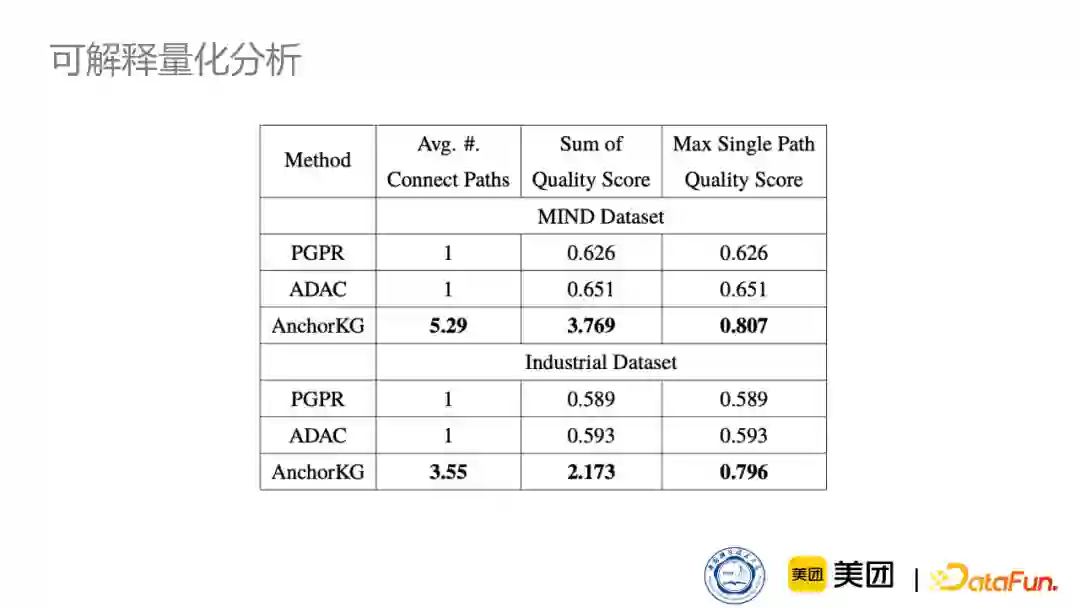
同时我们对可解释性也做了一个量化分析。模型中本就包含RNN模块,所以我们用RNN模块的分数来粗略评估可解释路径的质量,可以看到我们在数量还有质量上都比baseline模型要高。
这就是今天介绍的结合知识图谱的个性化新闻推荐系统。我即将入职美团知识计算组,我们组会涉及各种各样图学习的内容,比如会有丰富的业务场景落地,同时我们也在开发平台和训练引擎,也会做很多基础研究,欢迎所有对图学习感兴趣的同学进群交流。下图是我们的微信交流群,如果想交流或者加入计算组可以扫描二维码。
05
问答环节
Q1:做推荐的时候,是否可以通过构造事件图谱来进行推荐,比如买了房子接下来要装修,装修就会涉及到买窗帘、硬装、软装之类的?
A1:做新闻的时候确实会包含事件,很多时候不能把新闻的人物、地点单独考虑,通过事件会更加全面一些。但是事件构建难度较大,因为我并不是知识图谱构建的专家,所以我在尝试后,并没有找到很好的方法。但是这个在制作方面确实是非常有意义的,如果能在图谱中加入事件的节点,对新闻推荐肯定会有非常好的帮助。不过,对于新闻来说,很多事件是突然发生的,可能之前知识中并没有该事件,这个就属于动态图的研究范畴了,即增加新知识,这是非常有挑战的。
Q2:商品的库存与销售可以做知识图谱吗?
A2:我认为是可以的。知识图谱是非常广泛的概念,新闻知识图谱更类似于百科式的,实际上我们在美团业务中,用的知识图谱更多的是把用户和商户、用户和商品做一个连接。其实只要通过构图能够提升它的表示或增强了解,我们认为图谱都是有用的,都可以通过构图来学习。所以商品的库存与销售可以通过合理的方式来构建图谱,比如库存,可能具体的数字会带来噪音,但你可以把大于1000的、500-1000的等等,对应到节点上,然后加入到图中,这个估计对知识图谱会有很好的补充作用。
Q3:在建模过程中,会用到如随机游走或者负采样等策略,在知识图谱中会不会去专门挖掘一些比如pattern的整一块的知识吗?
A3:你所提到的图的pattern类似于metagraph,这个别的工作里确实也有,通过关系来构建Metapath或者Metagraph,这个也是非常有效的,尤其是在一些简单的商品知识图谱中。但对于新闻来说,就比较复杂,因为它可能存在上千种关系, Metagraph下来就非常复杂了,所以暂时就没有考虑。但是我相信,如果设计好的话,是非常有用的。
Q4:请问老师,现在有开源的知识图谱吗?
A4:开源的知识图谱是非常多的,不过每个公司也都有私有的知识图谱,来适应各自的业务。现在开源知识图谱用的比较多的是wiki data、DBPedia等等,大概有十几个,如果你想了解不同知识图谱的对比的话,市面上有相关书籍和博客将开源图谱的数据进行对比,你可以根据自己需求去选择最适用的知识图谱。对于我们新闻来说,wikidata是最适合的知识图谱,也是目前还在更新,比较全的知识图谱。
Q5:能否在开源图谱上进行预训练,使得在构建自己业务的知识图谱的时候,能够效率更高一点。
A5:这个主要取决于业务和开源图谱的相关性,假如两者的数据比较类似,那开源图谱甚至可以直接拿来用,但是数据没有那么相关的话,可以采取预训练的方法,我觉得这应该是非常有效的。
Q6: 在现在推荐领域的研究,更多的是在开源知识图谱上做还是要自己收集数据、自己构建,再进行研究?
A6: 从科研角度上看,利用开源图谱会更加方便,比如我这几个工作里的新闻推荐就是基于wikidata的。但是如果涉及到具体业务的话,那还是要根据自己的业务进行改造,效果会更好一些。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

刘丹阳 博士
美团搜索与NLP部知识计算组 实习生
中国科学技术大学博士,先后在微软亚洲研究院和美团实习。博士期间研究结合知识图谱的个性化新闻推荐系统,加入美团后主要负责图学习技术的研究和在业务中的落地。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“D251” 就可以获取《【牛津大学博士论文】深度学习临床前药物发现,251页pdf》专知下载链接




