![]()
众所周知,多头注意力机制 (Multi-Head Self-Attention) 的计算开销很大。在处理长度为 n 的序列时,其 ![]() 的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。在过去的两年里,已经出现了多种有效的方法来应对多头注意力机制的复杂度问题,本文将重点讨论在模型规模方面很有发展前景的方法。
的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。在过去的两年里,已经出现了多种有效的方法来应对多头注意力机制的复杂度问题,本文将重点讨论在模型规模方面很有发展前景的方法。
多头自注意力机制扩展到长文本序列的能力很差,原因有二:
第一,计算注意力矩阵所要求的每秒浮点运算数(FLOPs)与序列长度的平方成正比,导致单个序列上的自注意力运算的计算复杂度为
![]() ,其中 h 是注意力头的数量,d 是键向量和查询向量的维数,n 是序列的长度。
另一件糟糕的事是:点积自注意力运算的空间复杂度也与序列长度的平方成正比。计算注意力矩阵的空间复杂度为
,其中 h 是注意力头的数量,d 是键向量和查询向量的维数,n 是序列的长度。
另一件糟糕的事是:点积自注意力运算的空间复杂度也与序列长度的平方成正比。计算注意力矩阵的空间复杂度为
![]() ,其中 hdn 是存储键和查询所需的内存的阶,而
,其中 hdn 是存储键和查询所需的内存的阶,而
![]() 是指存储每个注意力头产生的标量注意力值所需内存的阶。
我们用 BERT-Base 中的一些具体数字来解释一下复杂度到底有多高。BERT-Base 序列输入的最大长度为 512,768 个的隐藏维度和 12 个注意力头,这意味着每个注意力头有 64 维(768/12)。在这种设定下,需要 393,216 个浮点数(约为 1.5MB)(12 个注意力头* 64 注意力头的维度* 512 序列长度)来存储键和值,而存储所有注意力头得到的标量注意力值所需的内存将达到 3,145,728 个浮点数(12 * 512 * 512)或约 12MB 的设备内存,这里所需的内存几乎是将键存储在长度为 512 个词的上下文时的 10 倍。
为了进行梯度运算,必须在训练过程中缓存激活值,除非使用诸如梯度检查点之类的重计算策略,因此对于每个示例来说,存储所有 12 层 BERT base 的注意力矩阵就需要大概 150MB 的内存。当序列长度为 1024 时,内存需求则变为约 600MB,而序列长度为 2048 时,对于每个示例的注意矩阵而言,内存需求就已达到约 2.4GB。这意味着在训练时可以使用的批处理规模较小,并行性较差,并会进一步阻碍我们训练该模型处理长上下文的能力。
是指存储每个注意力头产生的标量注意力值所需内存的阶。
我们用 BERT-Base 中的一些具体数字来解释一下复杂度到底有多高。BERT-Base 序列输入的最大长度为 512,768 个的隐藏维度和 12 个注意力头,这意味着每个注意力头有 64 维(768/12)。在这种设定下,需要 393,216 个浮点数(约为 1.5MB)(12 个注意力头* 64 注意力头的维度* 512 序列长度)来存储键和值,而存储所有注意力头得到的标量注意力值所需的内存将达到 3,145,728 个浮点数(12 * 512 * 512)或约 12MB 的设备内存,这里所需的内存几乎是将键存储在长度为 512 个词的上下文时的 10 倍。
为了进行梯度运算,必须在训练过程中缓存激活值,除非使用诸如梯度检查点之类的重计算策略,因此对于每个示例来说,存储所有 12 层 BERT base 的注意力矩阵就需要大概 150MB 的内存。当序列长度为 1024 时,内存需求则变为约 600MB,而序列长度为 2048 时,对于每个示例的注意矩阵而言,内存需求就已达到约 2.4GB。这意味着在训练时可以使用的批处理规模较小,并行性较差,并会进一步阻碍我们训练该模型处理长上下文的能力。
Rewon Child,Scott Gray,Alec Radford 和 Ilya Sutskever 在论文 "Generating Long Sequences with Sparse Transformers" 中提到,可以通过因式分解解决多头自注意力
![]() 的高时间和空间复杂度的问题。
论文地址:https://arxiv.org/abs/1904.10509
在典型的自注意力机制中,其输入序列中的每一项都要计算与输入序列中的其它项之间形成的注意力,从而得到如下所示的注意力模式:
图 1:以一种自回归的形式组织的传统自注意力机制的连接模式。深蓝色方块代表「查询」向量,而浅蓝色方块代表「键」向量。
传统自我注意力机制的一大好处是,高度的连通性使词例 (token) 之间的信息容易流通,仅需一层即可聚合来自任何两个词例的信息。但是,如果放宽此约束,并确保任意两个词例之间的信息只能在经过两层之后才可以流通,则可以极大地降低长序列带来的复杂性。稀疏 Transformer 通过编写利用固定注意力模式的自定义核来实现此目标。
图 2:稀疏 Transformer 的固定注意力变体。最深的蓝色方块代表「查询」向量,较浅的蓝色方块代表被奇数层注意的「键」向量索引,最浅的蓝色方块代表被偶数层注意的「键」向量索引。
一半的注意力头只关注较短的局部上下文中的项,而剩余的一半注意力头关注的是预先指定好的在整个序列中均匀分布的索引。通过根据这些聚合索引确定信息流动路径,网络仍然能够使得相距较远的词例间传递信息,并使用长距离上下文,同时将时间和内存复杂性降低到
的高时间和空间复杂度的问题。
论文地址:https://arxiv.org/abs/1904.10509
在典型的自注意力机制中,其输入序列中的每一项都要计算与输入序列中的其它项之间形成的注意力,从而得到如下所示的注意力模式:
图 1:以一种自回归的形式组织的传统自注意力机制的连接模式。深蓝色方块代表「查询」向量,而浅蓝色方块代表「键」向量。
传统自我注意力机制的一大好处是,高度的连通性使词例 (token) 之间的信息容易流通,仅需一层即可聚合来自任何两个词例的信息。但是,如果放宽此约束,并确保任意两个词例之间的信息只能在经过两层之后才可以流通,则可以极大地降低长序列带来的复杂性。稀疏 Transformer 通过编写利用固定注意力模式的自定义核来实现此目标。
图 2:稀疏 Transformer 的固定注意力变体。最深的蓝色方块代表「查询」向量,较浅的蓝色方块代表被奇数层注意的「键」向量索引,最浅的蓝色方块代表被偶数层注意的「键」向量索引。
一半的注意力头只关注较短的局部上下文中的项,而剩余的一半注意力头关注的是预先指定好的在整个序列中均匀分布的索引。通过根据这些聚合索引确定信息流动路径,网络仍然能够使得相距较远的词例间传递信息,并使用长距离上下文,同时将时间和内存复杂性降低到
![]() 。重要的是,它只需要两层就可以让任意词例考虑来自任何其它词例的信息。
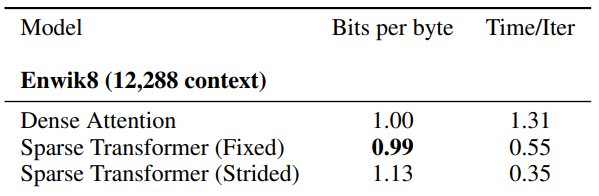
值得注意的是,分解后的注意力结构似乎不会对语言建模的性能产生负面影响,反而惊人地令每个字符需要的比特数比密集的注意力机制(原始 Transformer)在 Enwiki8 语料环境下要少一些,并且可以在包含多达 12,228 个词例的上下文中得到高效的注意力。
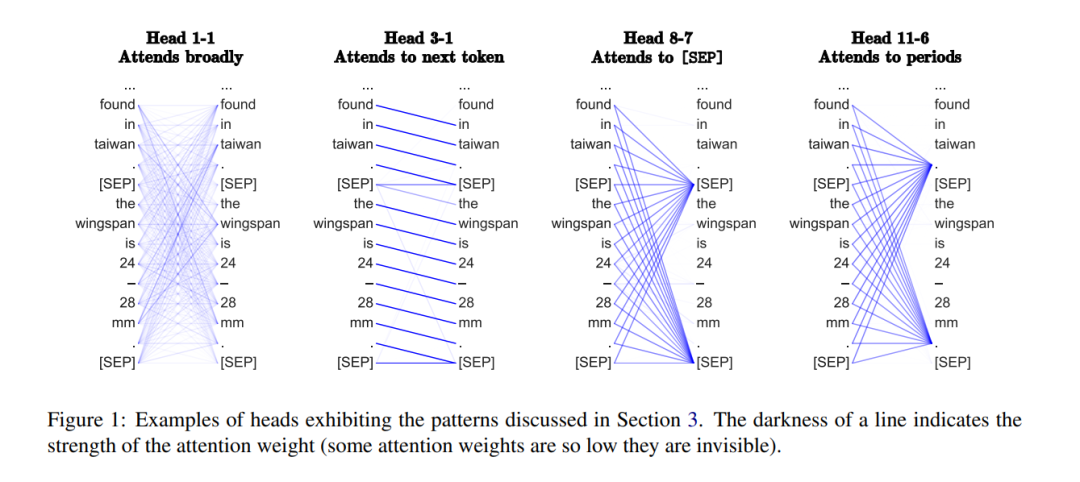
可以想象的到,稀疏 transformer 之所以起作用,部分原因是它学到的的注意力模式与实际学习的密集注意力模式并没有什么不同。在 Kevin Clark 等人发表的文章"What Does BERT Look At? An Analysis of BERT’s Attention"中,作者探索了密集注意力学习到的模式,想要找到注意力在transformer 中起什么作用。他们发现关注紧密相连的前面的词例(类似于稀疏注意力机制中的局部注意力模式)以及关注特定聚合词例(如 [SEP] 和句号)的注意力头有重要作用。因此,可能编码在稀疏 transformer 注意模式中的归纳偏置是有积极作用的。
论文地址:https://arxiv.org/abs/1906.04341
图 3:BERT 学到的注意力模式示意图,线的深度表明了注意力权重的强度(其中有一些注意力权重太小,以至于线变成了透明的)
要在自己的项目中使用固定注意力kernel,请查看OpenAI的blocksparse库和作者作为开源发布的附带示例。
。重要的是,它只需要两层就可以让任意词例考虑来自任何其它词例的信息。
值得注意的是,分解后的注意力结构似乎不会对语言建模的性能产生负面影响,反而惊人地令每个字符需要的比特数比密集的注意力机制(原始 Transformer)在 Enwiki8 语料环境下要少一些,并且可以在包含多达 12,228 个词例的上下文中得到高效的注意力。
可以想象的到,稀疏 transformer 之所以起作用,部分原因是它学到的的注意力模式与实际学习的密集注意力模式并没有什么不同。在 Kevin Clark 等人发表的文章"What Does BERT Look At? An Analysis of BERT’s Attention"中,作者探索了密集注意力学习到的模式,想要找到注意力在transformer 中起什么作用。他们发现关注紧密相连的前面的词例(类似于稀疏注意力机制中的局部注意力模式)以及关注特定聚合词例(如 [SEP] 和句号)的注意力头有重要作用。因此,可能编码在稀疏 transformer 注意模式中的归纳偏置是有积极作用的。
论文地址:https://arxiv.org/abs/1906.04341
图 3:BERT 学到的注意力模式示意图,线的深度表明了注意力权重的强度(其中有一些注意力权重太小,以至于线变成了透明的)
要在自己的项目中使用固定注意力kernel,请查看OpenAI的blocksparse库和作者作为开源发布的附带示例。
Sainbayar Sukhbaatar 等人在论文"Adaptive Attention Span in Transformers"中选择了另一种办法来解决这个问题。和前一篇"What Does Bert Look At?"的类似,他们也观察了 Transformer 中起作用的组件。
论文地址:https://arxiv.org/abs/1905.07799
值得注意的是,尽管密集注意力机制让每个注意力头可以关注整个上下文,但很多注意力头只考虑局部上下文,而其它注意力头则考虑了整个可用序列。他们建议通过使用一种自注意力的变体来利用这种观察结果,这种变体允许模型选择它的上下文大小。
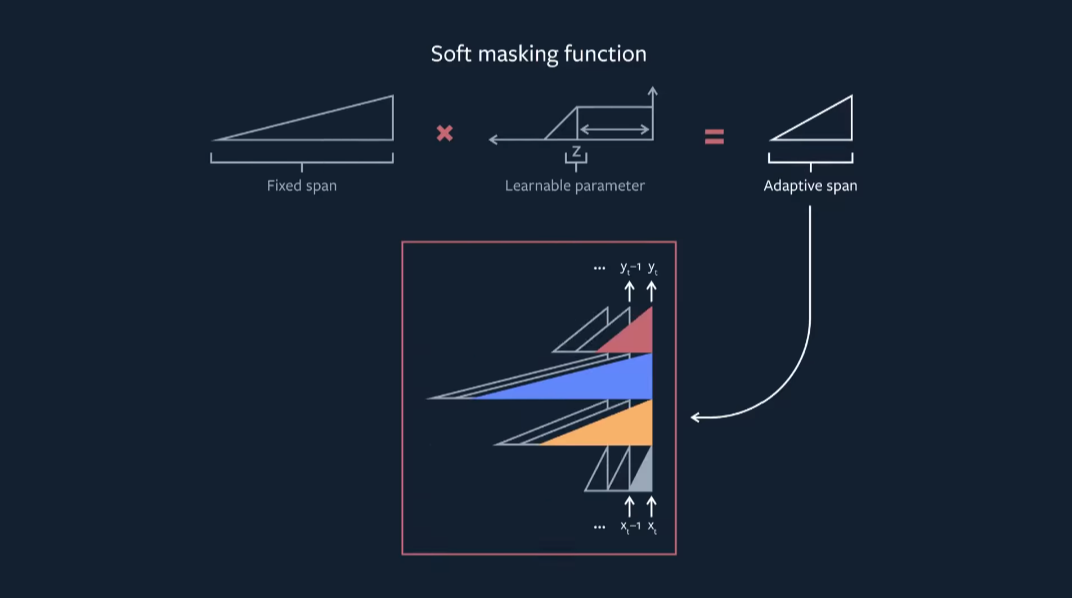
Adaptive Span Transformer 通过实现这一点的方式是:通过对序列进行掩模运算,使得学习到的每个注意力头的上下文之外的词例的贡献迅速降为零。mask(M)与 softmax 操作的分对数相乘,从而将某些词例对当前隐藏状态 x 的贡献归零,超参数 R 控制最小跨度的大小。
图 4:"Adaptive Attention Span in Transformers" 采用的 soft-masking 函数
他们应用了一个学习到的z值的
![]() 惩罚项,以鼓励模型仅在有益的情况下使用额外的上下文。
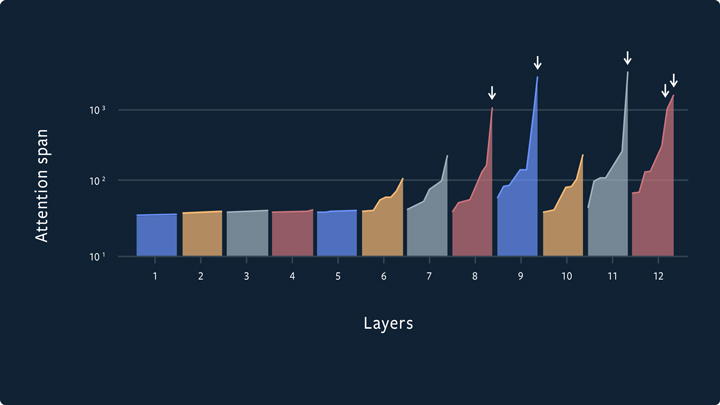
由于这些限制,大多数注意力头只关注少于100 字符的上下文,而只有少数(主要是在网络的后几层)选择添加一个
惩罚项,以鼓励模型仅在有益的情况下使用额外的上下文。
由于这些限制,大多数注意力头只关注少于100 字符的上下文,而只有少数(主要是在网络的后几层)选择添加一个
![]() 惩罚项,从而学习大于 1000 个字符的上下文。
除了采用巧妙的缓存策略,这种对长距离上下文的惩罚项使得跨度自适应 Transformer 可以使用使用高达 8k 个字符的注意力跨度,同时仍然保持模型的总体计算开销较低。此外,模型在基准对比测试中的性能仍然很高,在 Enwiki8 数据集上达到每字符占用 0.98 比特,在 text8 数据集上则达到每字符 1.07 比特。
然而,可变跨度大小的注意力在并行性方面并不理想,因为我们通常希望使用密集、大小一致的矩阵,从而获得最佳性能。虽然这种方法可以显著减少在预测时计算前向传播所需的每秒浮点运算次数,但作者只给出了模糊的性能估计,声明自适应跨度的实现使我们可以以与 2,048 个上下文词例的上下文大小固定的模型相近的速率处理长达 8,192 个词例的上下文。
Facebook AI 研究院也开源了他们的成果——代码和预训练模型请参阅以下链接:github.com/Facebook Research/adaptive-spans
惩罚项,从而学习大于 1000 个字符的上下文。
除了采用巧妙的缓存策略,这种对长距离上下文的惩罚项使得跨度自适应 Transformer 可以使用使用高达 8k 个字符的注意力跨度,同时仍然保持模型的总体计算开销较低。此外,模型在基准对比测试中的性能仍然很高,在 Enwiki8 数据集上达到每字符占用 0.98 比特,在 text8 数据集上则达到每字符 1.07 比特。
然而,可变跨度大小的注意力在并行性方面并不理想,因为我们通常希望使用密集、大小一致的矩阵,从而获得最佳性能。虽然这种方法可以显著减少在预测时计算前向传播所需的每秒浮点运算次数,但作者只给出了模糊的性能估计,声明自适应跨度的实现使我们可以以与 2,048 个上下文词例的上下文大小固定的模型相近的速率处理长达 8,192 个词例的上下文。
Facebook AI 研究院也开源了他们的成果——代码和预训练模型请参阅以下链接:github.com/Facebook Research/adaptive-spans
相比于降低密集型注意力操作复杂度的方式,Zihang Dai 等人受 RNN 的启发,在 transformer 的自注意机制之外引入了一种循环机制。他们的论文 "Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context" (论文地址:https://arxiv.org/abs/1901.02860)介绍了两个新概念:(1)一种新的组件,它将先前「段落」的隐藏状态作为循环段落层的输入;(2)使这种策略容易实现的相对位置编码方案。
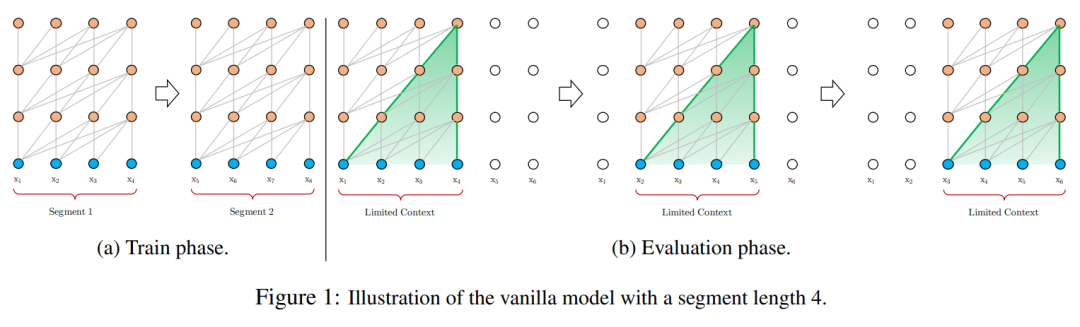
标准 transformer 的上下文大小是固定的,要想处理长的输入需要将输入分成块(段落),并分别处理每个块(段落)。
然而,这种方法存在一个限制:前面段落的信息不能流向当前的词例。这种段与段之间的独立性在某种程度上有益于高效地对段落进行批处理,但从长距离一致性的角度出发,这又变成了一个主要限制因素。
图 6:在 Transformer XL 的论文中,在一个自回归 transformer 中的词例注意力结构示意图
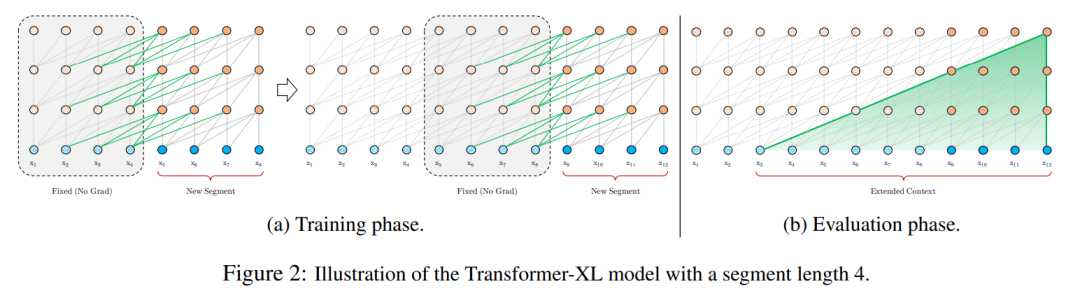
Transformer XL 通过强制地使段落被串行处理来解决这一限制。处理完成第一个段之后,先前段的激活值将作为上下文传递给后续段的注意力,因此始终有 512 个紧邻的字符的上下文被记录。这意味着跨度为 N 个上下文大小 * L 层的信息可以传播到给定的词例。假设上下文大小为 640,并且模型有 16 层,那么 Transformer XL 理论上至多可以考虑 10,240 个字符的信号。
图7:Transformer-XL 中的词例注意力模式,其中端的长度为 4
为了避免存储先前所有段的激活值,作者阻止了梯度流向前面的段。
Transformer-XL 还引入了一种新的位置编码方案,即“相对位置编码”。这种方案不再简单地将内容和绝对位置嵌入的总和作为网络输入,而是对每层的注意力操进行分解,其中一部分基于内容执行注意力,另一部分基于相对位置执行注意力。因此,块中的第 512 个词例会注意到第 511 个词例,在这里会采用 相对位置 -1 相应的嵌入。
为了使相对位置编码易于处理,他们将生成注意力权重的操作和键和生成查询向量、键向量的操作分离。对于典型的密集注意力机制,进行 softmax 计算之前的注意力可以被分解如下:
在上面的公式中,
![]() 表示基于内容的注意力在位置 i 处的词例的嵌入 ,
表示基于内容的注意力在位置 i 处的词例的嵌入 ,
![]() 是词例 j 的位置编码嵌入。其中,每一项的含义如下:
对于包含在查询的位置中的项(c 和 d),我们使用两个新的可学习参数 u 和 v 替代了
是词例 j 的位置编码嵌入。其中,每一项的含义如下:
对于包含在查询的位置中的项(c 和 d),我们使用两个新的可学习参数 u 和 v 替代了
![]() 矩阵。这些向量可以被理解为两个偏置,它们并不依赖于查询的特征。c 促使模型对某些项的注意力程度比对其它项更高,而 d 促使模型对某些相对位置的注意力程度比对其它位置更高。这种替代的方式受到了下面这一事实的启发:查询相对于自己的相对位置始终保持不变。
为了使 Transformer-XL 模型能够使用长距离的上下文,每层中至少有一个注意力头必须利用其注意力跨度内的全部上下文。平均注意权重图显示,每一层都有一些注意力头,注意到先前许多的位置。
图 8:在前面 640 个词例上的平均注意力,其中每行对应于一个注意力头,每列对应于一个相对位置。图中共有 160 个注意力头,每十个注意力头同属于同一层。颜色越深代表注意力值越大。
另外,Transformer-XL 的原始论文测量了有效上下文长度对困惑度(perplexity,交叉熵的指数形式)的影响。作者发现,增加上下文长度(上下文长度高达九百个词例)会得到更好的困惑度分数(预测样本更准确),这进一步证明了循环机制不仅理论上可行,而且实际上也十分有效。
如果想要开始将 Transformer-XL用于自己的项目:
源代码请参见 Kimi Young 的 github:https://github.com/kimiyoung/transformer-xl
或查看HuggingFace 的实现:https://huggingface.co/transformers/model_doc/transformerxl.html
矩阵。这些向量可以被理解为两个偏置,它们并不依赖于查询的特征。c 促使模型对某些项的注意力程度比对其它项更高,而 d 促使模型对某些相对位置的注意力程度比对其它位置更高。这种替代的方式受到了下面这一事实的启发:查询相对于自己的相对位置始终保持不变。
为了使 Transformer-XL 模型能够使用长距离的上下文,每层中至少有一个注意力头必须利用其注意力跨度内的全部上下文。平均注意权重图显示,每一层都有一些注意力头,注意到先前许多的位置。
图 8:在前面 640 个词例上的平均注意力,其中每行对应于一个注意力头,每列对应于一个相对位置。图中共有 160 个注意力头,每十个注意力头同属于同一层。颜色越深代表注意力值越大。
另外,Transformer-XL 的原始论文测量了有效上下文长度对困惑度(perplexity,交叉熵的指数形式)的影响。作者发现,增加上下文长度(上下文长度高达九百个词例)会得到更好的困惑度分数(预测样本更准确),这进一步证明了循环机制不仅理论上可行,而且实际上也十分有效。
如果想要开始将 Transformer-XL用于自己的项目:
源代码请参见 Kimi Young 的 github:https://github.com/kimiyoung/transformer-xl
或查看HuggingFace 的实现:https://huggingface.co/transformers/model_doc/transformerxl.html
接下来我们将介绍压缩 Transformer(Compressive Transformer),它是建立在 Transformer-XL 的架构之上的。压缩 Transformer 使用了一个压缩损失对 Transformer-XL 进行了拓展,考虑了更长的序列长度。在论文“Compressive Transformers for Long-Range Sequence Modelling”中,来自 DeepMind 的 Jack 等人详细描述了一种模型架构,该架构能够处理与整本书一样长的序列。
论文地址:https://arxiv.org/abs/1911.05507
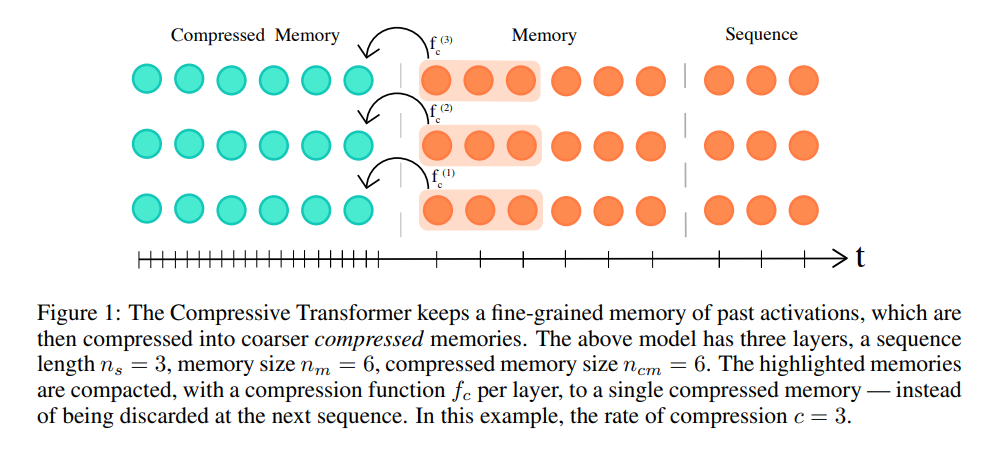
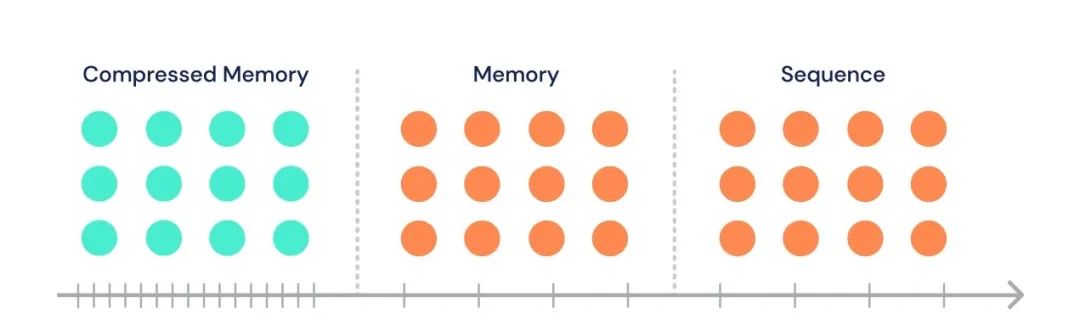
图 9:压缩 Transformer 保留了过去的激活值的细粒度内存,它们随后被压缩到粒度较粗的压缩内存中。上图中的模型有一个三层的结构:(1)一个长度为 3 的序列(2)一个长度为 6 的内存(3)长度为 6 的压缩内存。高亮显示的内存在每层中被一种压缩函数 f_c 压缩到单个压缩内存中,而不是直接被接下来的序列忽略。在本例中,压缩比为 c=3。
遵循着 Transformer-XL 的设定,序列可以注意到一组存储下来的之前段的激活值。另外,在相同的多头注意里操作中,当前段中的词例可以注意到存储在「压缩内存」中的第二组状态。
在每一个时间步上,最早的一个压缩内存会被丢弃,压缩内存的索引会回退一位。接着,常规的内存段中最早的 n 个状态会被压缩,并且被转移到压缩内存中新开的槽中。
DeepMind 的研究团队尝试使用了各种各样的压缩操作(包括平均池化、最大池化、学习到的卷积操作等对比基线),但是他们最终决定训练一个辅助网络,该网络被用于重建基于内容的被压缩的内存的注意力矩阵。换而言之,他们学习了一种函数
![]() ,该函数通过最小化压缩内存上的注意力
,该函数通过最小化压缩内存上的注意力
![]() 与被压缩的常规内存中状态的注意力之间的差异,将最早的 n 个内存状态压缩到了单个压缩后的内存状态中:
由于让状态容易被压缩与减小语言模型的损失是相矛盾的,他们选择在一个独立的优化循环中更新压缩网络,而不是同时训练这种压缩操作和主要的语言模型。
在实验中,他们设置压缩内存的大小为 512,正规内存的大小为 512,滑动窗口大小为 512,压缩率为 2(这意味着最早的 2 个内存状态会在压缩步骤中被压缩到单个状态中)。在这样的实验环境下,他们取得了目前最好的实验结果——在 WikiText-103 数据集上取得了 17.1 的困惑度。
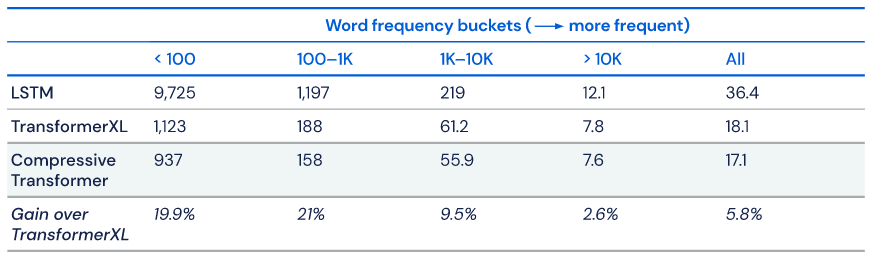
由于通过利用更长的序列所获得的收益往往是符合长尾分布的,他们专门关注了由词频刻画的离散特征的困惑度,并指出最稀有的词例带来的收益是最显著的:
图 11:通过词频刻画的离散特征桶(bucket)的困惑度
尽管他们的源代码至今还没有公开,DeepMind 已经开源了它们研发压缩 Transformer 时所使用的数据集 PG-19。PG-19 是 Gutenberg 计划的衍生品,旨在进一步研究长距离注意力。
数据集地址:https://github.com/deepmind/pg19
与被压缩的常规内存中状态的注意力之间的差异,将最早的 n 个内存状态压缩到了单个压缩后的内存状态中:
由于让状态容易被压缩与减小语言模型的损失是相矛盾的,他们选择在一个独立的优化循环中更新压缩网络,而不是同时训练这种压缩操作和主要的语言模型。
在实验中,他们设置压缩内存的大小为 512,正规内存的大小为 512,滑动窗口大小为 512,压缩率为 2(这意味着最早的 2 个内存状态会在压缩步骤中被压缩到单个状态中)。在这样的实验环境下,他们取得了目前最好的实验结果——在 WikiText-103 数据集上取得了 17.1 的困惑度。
由于通过利用更长的序列所获得的收益往往是符合长尾分布的,他们专门关注了由词频刻画的离散特征的困惑度,并指出最稀有的词例带来的收益是最显著的:
图 11:通过词频刻画的离散特征桶(bucket)的困惑度
尽管他们的源代码至今还没有公开,DeepMind 已经开源了它们研发压缩 Transformer 时所使用的数据集 PG-19。PG-19 是 Gutenberg 计划的衍生品,旨在进一步研究长距离注意力。
数据集地址:https://github.com/deepmind/pg19
接下来,我们继续关注由 Nikita Kitaev 等人完成的工作“Reformer:The Efficient Transformer”。Reformer 对于长度增长的序列采用了另一种策略,他们选择通过局部敏感哈希技术将每个词例的注意力范围变窄,而不是引入循环机制或压缩内存。
论文地址:https://arxiv.org/abs/2001.04451
局部敏感哈希,是一类将高维向量映射到一组离散值(桶/聚类簇)上的方法。在大多数情况下,它被用作一种近似的最近邻搜索方法。
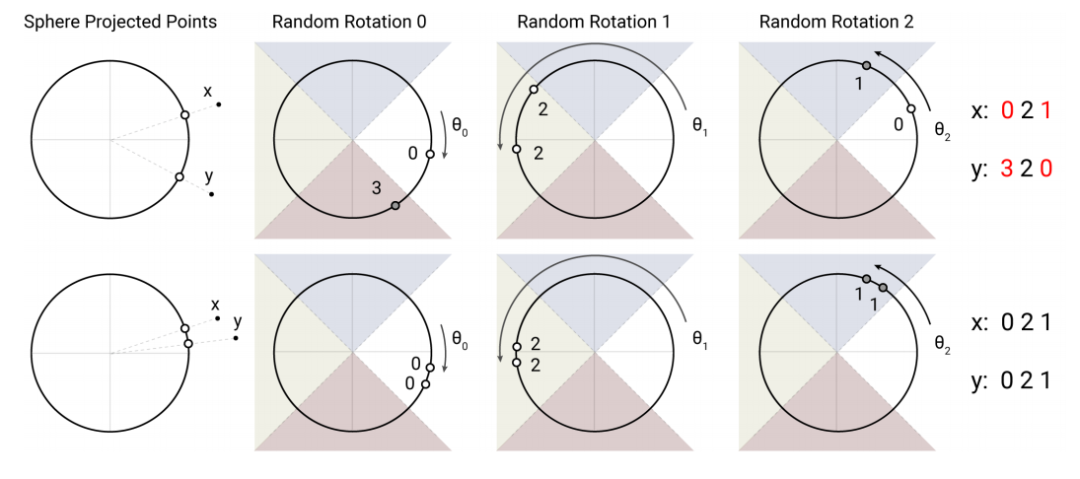
Reformer 的作者针对注意力操作的键向量和查询向量使用了一种单一投影,他们使用了一种基于随机旋转的局部敏感哈希方法,将共享的键/查询聚集到至多几百个词例的桶。哈希方法的示意图如下:
图12:角度局部敏感哈希算法示意图。图中显示了三轮哈希,每轮哈希中将空间分成了 4 个桶。在下面一排示意图的三轮哈希中中,向量都被映射到了同一个桶中,因为它们在输入中也相近;而在上面一排的第一次哈希和第三次哈希中,向量映射到了不同的桶中。
它们计算了每个桶中的注意力矩阵,并对相应的值进行加权。由于它们只能注意到给定的中的元素,当选取的桶大小合适时,这样做可以将注意力操作的整体空间复杂度从
![]() 降低到
降低到
![]() 。由于这里的分桶(bucketing)处理是随机并且基于随机旋转的,他们计算了若干次哈希,从而保证具有相近的「键-查询」嵌入的词例最终很有可能被分在同一个桶中。
他们额外地使用了 "The Reversible Residual Network: Backpropagation Without Storing Activations" 中提出的技术将训练时的内存消耗维持在可控范围内。逆残差层使用了非常巧妙的架构,使模型可以容易地根据层的输出重构层的输入,并以额外的计算换取网络深度不变的内存复杂性。
论文地址:https://arxiv.org/abs/1707.04585
尽管 Reformer 论文中给出的在 Enwiki-8 数据集上 1.05 比特每字符的性能比本文中给出的其它一些模型稍弱,但是 Reformer 仍然提出了一种令人耳目一新的机制引入了长距离上下文,人们期待看到 Reformer 进一步的拓展。
如果你有兴趣更深入地探索 Reformer 架构,请参阅博文「 A Deep Dive into the Reformer」:
https://www.pragmatic.ml/reformer-deep-dive/Google/jax
Github 代码仓库中的 Reformer 的开源实现链接如下:
https://github.com/google/trax/tree/master/trax/models/reformer
一种 Phil Wang 训练的 PyTorch 版的实现链接如下:
https://github.com/lucidrains/reformer-pytorch
。由于这里的分桶(bucketing)处理是随机并且基于随机旋转的,他们计算了若干次哈希,从而保证具有相近的「键-查询」嵌入的词例最终很有可能被分在同一个桶中。
他们额外地使用了 "The Reversible Residual Network: Backpropagation Without Storing Activations" 中提出的技术将训练时的内存消耗维持在可控范围内。逆残差层使用了非常巧妙的架构,使模型可以容易地根据层的输出重构层的输入,并以额外的计算换取网络深度不变的内存复杂性。
论文地址:https://arxiv.org/abs/1707.04585
尽管 Reformer 论文中给出的在 Enwiki-8 数据集上 1.05 比特每字符的性能比本文中给出的其它一些模型稍弱,但是 Reformer 仍然提出了一种令人耳目一新的机制引入了长距离上下文,人们期待看到 Reformer 进一步的拓展。
如果你有兴趣更深入地探索 Reformer 架构,请参阅博文「 A Deep Dive into the Reformer」:
https://www.pragmatic.ml/reformer-deep-dive/Google/jax
Github 代码仓库中的 Reformer 的开源实现链接如下:
https://github.com/google/trax/tree/master/trax/models/reformer
一种 Phil Wang 训练的 PyTorch 版的实现链接如下:
https://github.com/lucidrains/reformer-pytorch
Aurko Roy 等人于 ICLR 2020 上发表的工作 "Efficient Content-Based Sparse Attention with 路由Transformers"()与前文提到的 Reformer 有一些异曲同工之妙。它们将该问题建模为了一个路由问题,目的是让模型学会选择词例的稀疏聚类
![]() (将其作为内容 x 的函数)。
论文地址:https://openreview.net/profile?email=grangier%40google.com
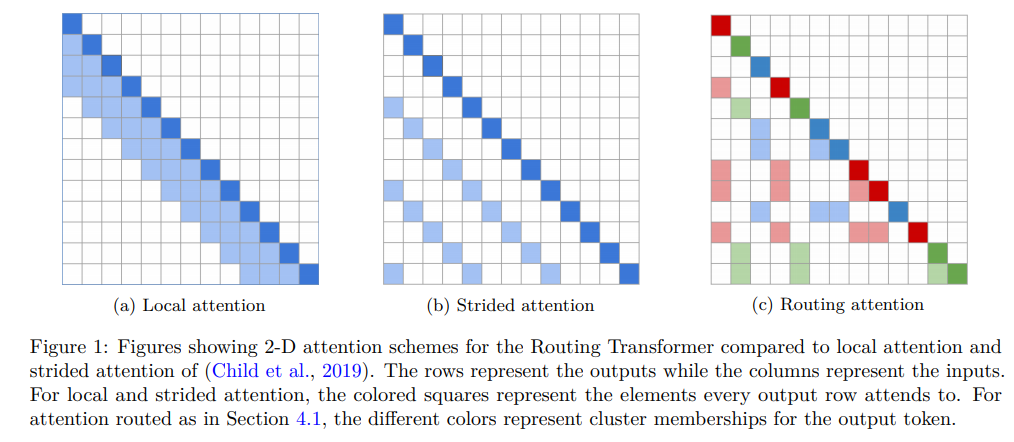
在下面的图表中,作者描述了他们的方法。他们并不只关注局部元素或每 n 个元素来增加稀疏性,而是学习了通过下图 c 中的颜色表示的需要关注的聚类簇。重要的是,这些簇是关于每个键和查询的内容的函数,而不仅仅与它们的绝对或相对位置相关。
图 13:这里的图形显示了路由 Transformer 与局部注意力机制和 Child 等人于 2019 年提出的跨步注意力机制的对比结果。每一行代表输出,每一列代表输入。对于局部注意力机制和跨步注意力机制来说,着色的方块代表每一个输出行注意到的元素。对于路由注意力机制来说,不同的颜色代表输出词例的聚类中的成员。
确保每个键和查询向量都具有单位大小后,他们使用了一种公共的随机权重矩阵对键和查询的值进行投影,投影的尺寸为
(将其作为内容 x 的函数)。
论文地址:https://openreview.net/profile?email=grangier%40google.com
在下面的图表中,作者描述了他们的方法。他们并不只关注局部元素或每 n 个元素来增加稀疏性,而是学习了通过下图 c 中的颜色表示的需要关注的聚类簇。重要的是,这些簇是关于每个键和查询的内容的函数,而不仅仅与它们的绝对或相对位置相关。
图 13:这里的图形显示了路由 Transformer 与局部注意力机制和 Child 等人于 2019 年提出的跨步注意力机制的对比结果。每一行代表输出,每一列代表输入。对于局部注意力机制和跨步注意力机制来说,着色的方块代表每一个输出行注意到的元素。对于路由注意力机制来说,不同的颜色代表输出词例的聚类中的成员。
确保每个键和查询向量都具有单位大小后,他们使用了一种公共的随机权重矩阵对键和查询的值进行投影,投影的尺寸为
![]() ,其中D_K 是键和查询的隐藏维度。
随后,R 中的向量会根据一组 k-均值聚类中心 C 被聚类到 k 个簇中。K-均值聚类中心是通过使用每个批(batch)中的 K-均值更新学习到的,它与梯度下降过程相独立。
在给定的聚类簇 C_i 中,他们使用了一种标准的加权求和方法,计算了一组新的上下文嵌入,其中每个注意力值 A_i 是使用标准的点乘自注意力计算而来的。
由于密集型注意力机制中的注意力模式往往由少数的关键元素,并且分配聚类的过程需要将具有高注意力权重的键和查询分到同一个聚类簇中,作者认为这样做保留了关键的信息。这说明
,其中D_K 是键和查询的隐藏维度。
随后,R 中的向量会根据一组 k-均值聚类中心 C 被聚类到 k 个簇中。K-均值聚类中心是通过使用每个批(batch)中的 K-均值更新学习到的,它与梯度下降过程相独立。
在给定的聚类簇 C_i 中,他们使用了一种标准的加权求和方法,计算了一组新的上下文嵌入,其中每个注意力值 A_i 是使用标准的点乘自注意力计算而来的。
由于密集型注意力机制中的注意力模式往往由少数的关键元素,并且分配聚类的过程需要将具有高注意力权重的键和查询分到同一个聚类簇中,作者认为这样做保留了关键的信息。这说明
![]() 应用的密集型操作计算开销过高。
最终,他们选择了大约
应用的密集型操作计算开销过高。
最终,他们选择了大约
![]() 个聚类,因此他们稀疏的基于内容的注意力机制的整体复杂度为
个聚类,因此他们稀疏的基于内容的注意力机制的整体复杂度为
![]() 。为了让整个过程易于并行化计算,并且可以处理统一大小的矩阵,作者使用了最接近每个聚类中心的前 k 个项来代替真正的 k-均值聚类。
除了基于内容的路由注意力机制,路由Transformer 还在一个大小为 256 的内容窗口上执行了局部注意力。
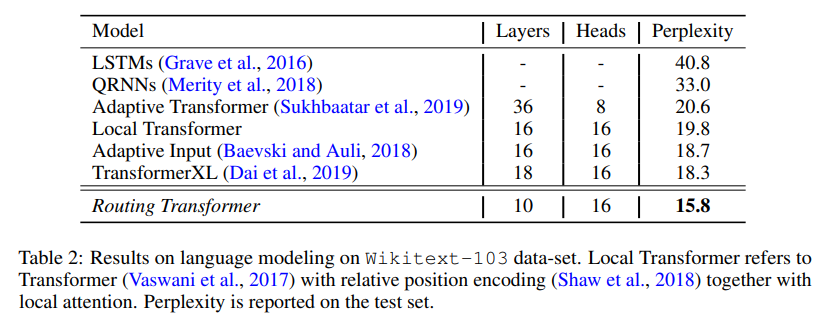
路由Transformer 在计算效率方面取得了提升,从而使模型在 Wikitext-103 上(一种单词级别的语言建模对比基准)取得了在困惑度指标上性能的提升,他们的性能大大超过了上文介绍的 Tranformer-XL 模型。
表 1:在 Wikitext-103 数据集上的语言建模结果。Local Transformer 指的是由 Vaswani 等人于 2017 年提出的 Transformer,它用到了相对位置编码和局部注意力。表中给出了测试集上的困惑度。
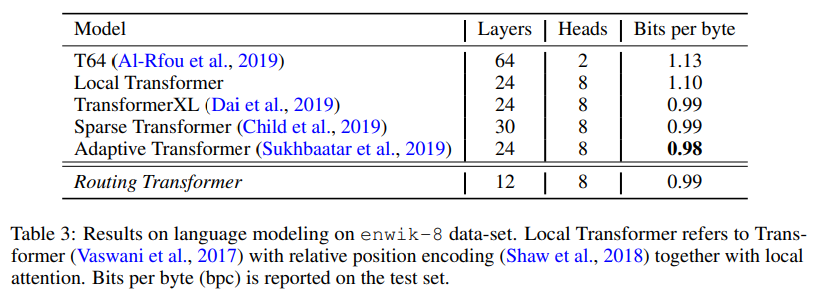
在 Enwiki-8 数据集上,路由Transformer 的性能也非常出色(尽管其性能稍微落后于自适应跨度 Transformer)。
表 2:在 Enwiki-8 数据集上的语言建模结果。Local Transformer 指的是由 Vaswani 等人于 2017 年提出的 Transformer,它用到了相对位置编码和局部注意力。表中给出了测试集上的比特每字节(bpc)。
https://storage.googleapis.com/routing_transformers_iclr20/routing_transformers_iclr20.zip
。为了让整个过程易于并行化计算,并且可以处理统一大小的矩阵,作者使用了最接近每个聚类中心的前 k 个项来代替真正的 k-均值聚类。
除了基于内容的路由注意力机制,路由Transformer 还在一个大小为 256 的内容窗口上执行了局部注意力。
路由Transformer 在计算效率方面取得了提升,从而使模型在 Wikitext-103 上(一种单词级别的语言建模对比基准)取得了在困惑度指标上性能的提升,他们的性能大大超过了上文介绍的 Tranformer-XL 模型。
表 1:在 Wikitext-103 数据集上的语言建模结果。Local Transformer 指的是由 Vaswani 等人于 2017 年提出的 Transformer,它用到了相对位置编码和局部注意力。表中给出了测试集上的困惑度。
在 Enwiki-8 数据集上,路由Transformer 的性能也非常出色(尽管其性能稍微落后于自适应跨度 Transformer)。
表 2:在 Enwiki-8 数据集上的语言建模结果。Local Transformer 指的是由 Vaswani 等人于 2017 年提出的 Transformer,它用到了相对位置编码和局部注意力。表中给出了测试集上的比特每字节(bpc)。
https://storage.googleapis.com/routing_transformers_iclr20/routing_transformers_iclr20.zip
如果你想进一步了解
其它处理 Transformer
长文本序列方法,
可以参阅下列文章:
-
Efficient Content-Based Sparse Attention with Routing Transformers,https://openreview.net/forum?id=B1gjs6EtDr
-
Adaptively Sparse Transformers,https://arxiv.org/abs/1909.00015
-
BP-Transformer: Modelling Long-Range Context via Binary Partitioning,https://arxiv.org/abs/1911.04070v1
-
Scaling Laws for Neural Language Models,https://arxiv.org/abs/2001.08361
via https://www.pragmatic.ml/a-survey-of-methods-for-incorporating-long-term-context/
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。

 的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。在过去的两年里,已经出现了多种有效的方法来应对多头注意力机制的复杂度问题,本文将重点讨论在模型规模方面很有发展前景的方法。
的时间复杂度会使得原始的 Transformer 模型难以处理长文本序列。在过去的两年里,已经出现了多种有效的方法来应对多头注意力机制的复杂度问题,本文将重点讨论在模型规模方面很有发展前景的方法。
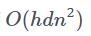 ,其中 h 是注意力头的数量,d 是键向量和查询向量的维数,n 是序列的长度。
,其中 h 是注意力头的数量,d 是键向量和查询向量的维数,n 是序列的长度。
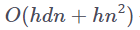 ,其中 hdn 是存储键和查询所需的内存的阶,而
,其中 hdn 是存储键和查询所需的内存的阶,而


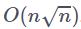 。重要的是,它只需要两层就可以让任意词例考虑来自任何其它词例的信息。
。重要的是,它只需要两层就可以让任意词例考虑来自任何其它词例的信息。
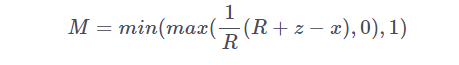
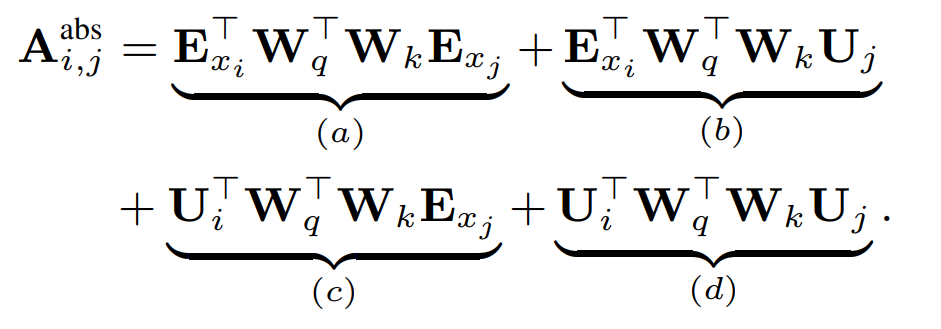
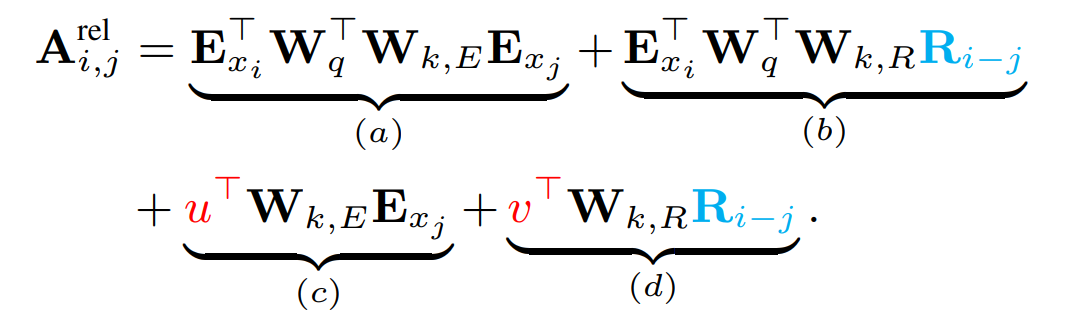
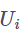 矩阵。这些向量可以被理解为两个偏置,它们并不依赖于查询的特征。c 促使模型对某些项的注意力程度比对其它项更高,而 d 促使模型对某些相对位置的注意力程度比对其它位置更高。这种替代的方式受到了下面这一事实的启发:查询相对于自己的相对位置始终保持不变。
矩阵。这些向量可以被理解为两个偏置,它们并不依赖于查询的特征。c 促使模型对某些项的注意力程度比对其它项更高,而 d 促使模型对某些相对位置的注意力程度比对其它位置更高。这种替代的方式受到了下面这一事实的启发:查询相对于自己的相对位置始终保持不变。

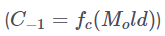 与被压缩的常规内存中状态的注意力之间的差异,将最早的 n 个内存状态压缩到了单个压缩后的内存状态中:
与被压缩的常规内存中状态的注意力之间的差异,将最早的 n 个内存状态压缩到了单个压缩后的内存状态中:
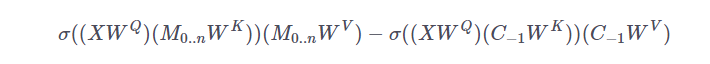
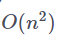 降低到
降低到
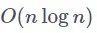 。由于这里的分桶(bucketing)处理是随机并且基于随机旋转的,他们计算了若干次哈希,从而保证具有相近的「键-查询」嵌入的词例最终很有可能被分在同一个桶中。
。由于这里的分桶(bucketing)处理是随机并且基于随机旋转的,他们计算了若干次哈希,从而保证具有相近的「键-查询」嵌入的词例最终很有可能被分在同一个桶中。

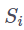 (将其作为内容 x 的函数)。
(将其作为内容 x 的函数)。
 ,其中D_K 是键和查询的隐藏维度。
,其中D_K 是键和查询的隐藏维度。
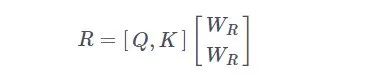
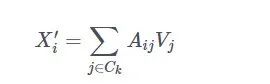
 个聚类,因此他们稀疏的基于内容的注意力机制的整体复杂度为
个聚类,因此他们稀疏的基于内容的注意力机制的整体复杂度为
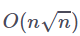 。为了让整个过程易于并行化计算,并且可以处理统一大小的矩阵,作者使用了最接近每个聚类中心的前 k 个项来代替真正的 k-均值聚类。
。为了让整个过程易于并行化计算,并且可以处理统一大小的矩阵,作者使用了最接近每个聚类中心的前 k 个项来代替真正的 k-均值聚类。