视线估计算法基于用户的面部图片计算其视线方向。然而,面部图片中除包含有效的人眼区域信息外,仍包含众多的视线无关特征,如个人信息、光照信息。
这些视线无关特征损害了视线估计的泛化性能,当使用环境更改时,视线估计算法的性能也会出现大幅度的下降。
针对以上挑战,本期 AI Drive 将邀请北京航空航天大学程义华博士,介绍其团队提出的一种基于特征纯化的视线估计算法 PureGaze。
这项被 AAAI 2022 接收的研究中,算法利用对抗训练实现了视线特征的纯化。纯化过程中,算法保留了视线相关特征而消除视线无关特征。通过利用此特征纯化算法,方法的域泛化性能得到提升,方法也在多个数据集上达到领先的性能。
![]()
域自适应问题
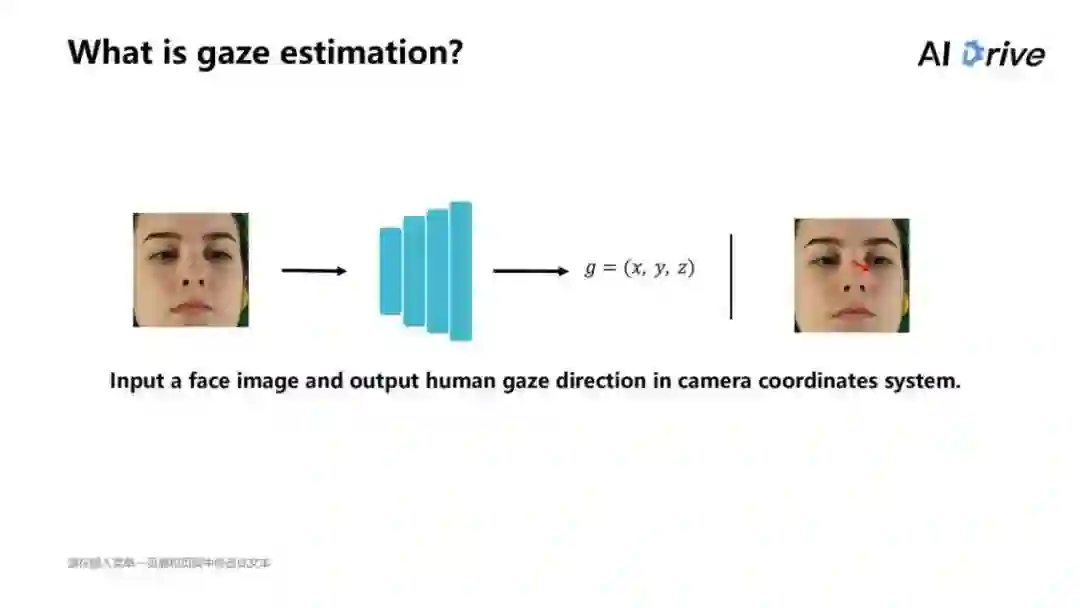
视线估计目前不算是很热门的技术,但是现在在类似智能车的方面有广泛的应用,它的主要目标是用来估计人眼的视线方向。
视线估计的主要目标是估计用户的视线方向,目前在智能车的智能车舱以及虚拟现实、增强显示中有着广泛的应用。
比如在上图中,要去判断这个人的眼睛是看在哪里,相当于在现实的任务中估计一个人其注视的点在哪里、看到的是什么地方、方向,而这种方向是可以作为反映人类意向性的有用信息,因此,视线估计可以用来做一些判断的事情。
一般来说,一个简单的网络的结构,如图中所说,输入一个人脸的图片,把这个人脸的图片经过一层层地卷积,得到一个三维坐标(x,y,z),是由人的眉心到所注视空间的某个点之间的方向向量。
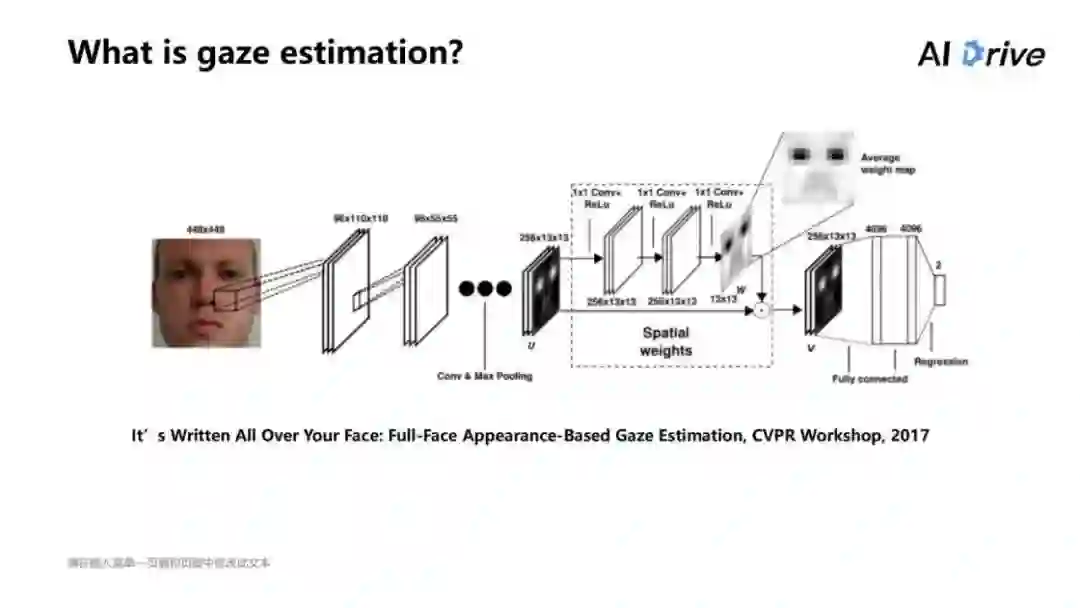
上图是 2017 年在 CVPR Workshop 里发表的一篇文章,内容是一种比较经典的网络结构。即有一个人脸图片,它输入的是 448×448 的,经过卷积加了一个空间的权重,最后得到一个二维的 Spatialweights。
在本工作里,主要解决的是视线估计中的 Cross-domain 的问题。Cross-domain 就相当于把方法放在一个数据集上进行训练,同时在其他的数据集上进行测试,这样就相当于在实际之间的应用,并通过此获得一个通用的算法。
但是针对于当前的 Cross-domain 来说,很大的问题是在提出的算法上,一般情况下,算法在 domain 里或者说在数据集内部,经常能得到很好的效果,但是一旦让其去进行 Cross domain 测试的时候,会有比较大的性能差异,差异性可能甚至于直接的将误差翻倍。
主要的原因可能是由于在采集数据的时候,会有不同的环境因素或者个人的因素影响。如图列举的三个数据集中间的图片,可以看出有一些人脸图片可能会有不同的光照因素,同时,对于不同的人来说,这也是会造成误差的。
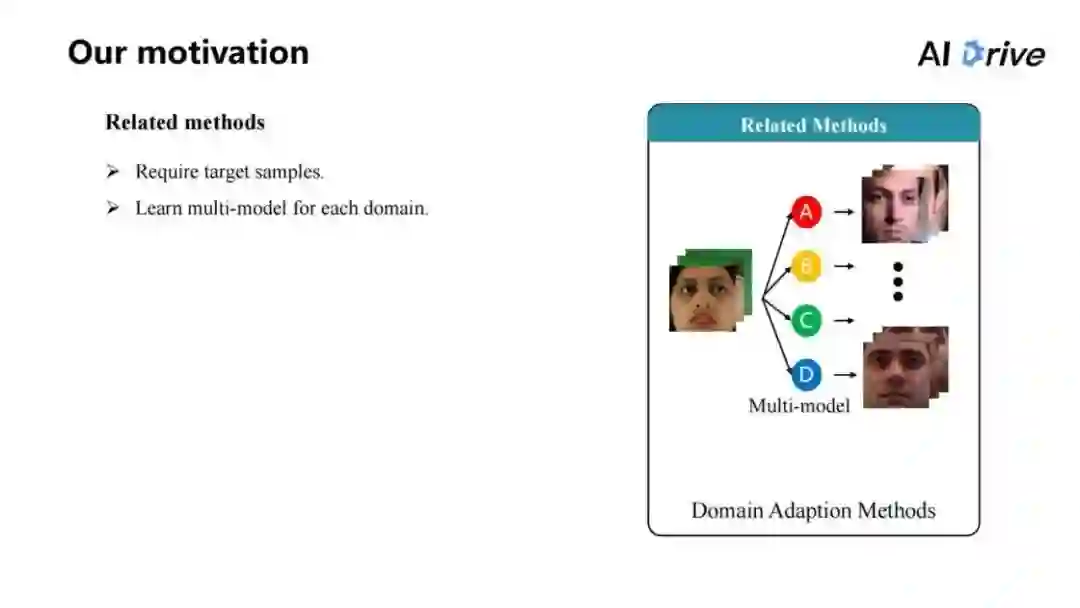
对于本文来说,想要去解决 Cross-domain 问题,有一些以前的相关工作,大部分人会把这个问题看作是一个 Domain Adaption 的问题。
要在原始的 domain 上训练一个模型,然后要把它迁移到某个其他 domain 的图片上去,这是一个比较简单的算法,比如,我们先总的训练一个模型,然后在下游的一些子任务上面、在一个新的任务上面把模型进行微调,也许就能得到好的结果,这其实也是一种类似于 Domain Adaption 的方法。
这些方法经常有两点要求,第一,需要一个目标的数据集上面的一些样本,这样才能够做一个 Domain Adaption。
同时,它们还会学习到很多模型,对于不同的数据集不是说直接地把一个模型就能拿过来用,而是首先需要一段的预热,把模型首先在新环境中间采集一些数据;采集数据过后,花一段时间去运行、训练,最后才能得到比较好的模型。
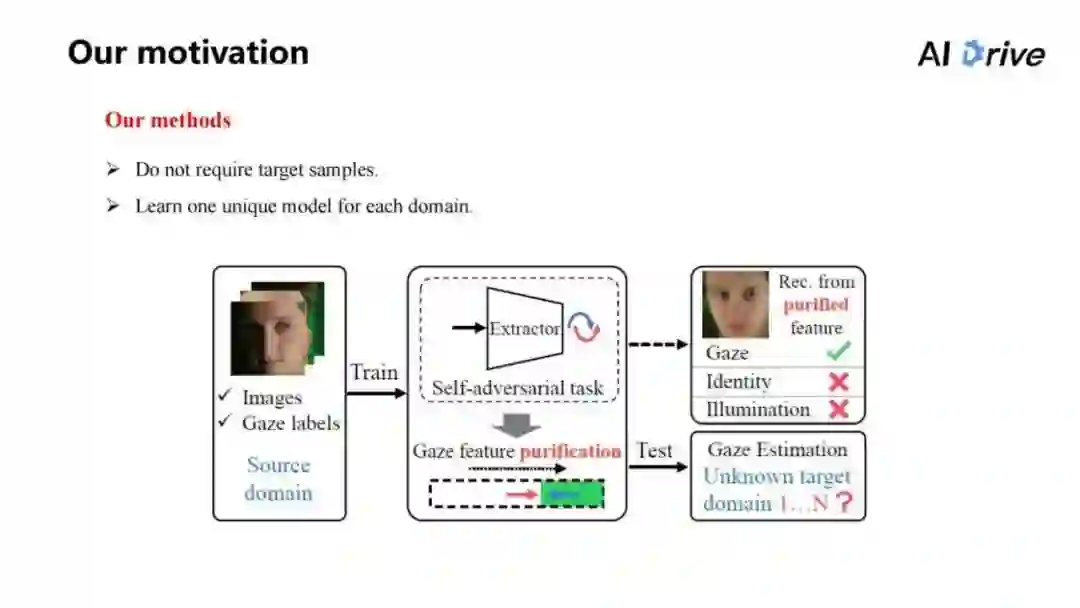
而对于我们的方法来说,主要想要解决的是如何不需要且不利用目标域的数据,因为这样相当于局限了整个模型。我们期望能在原始的数据集上学习模型,而这个模型把它同时应用到多个模型上,也都能达到比较好的结果,于是我们采用了域泛化的方法。
如上图的图片,相当于这个方法总体的想法, Source 层上面会给定它一个图片以及 Gaze labels,如它的视线方向是哪里,然后,在原始的域上面进行训练,训练完数据过后,相当于这个数据使用了自己的一些方法;比如在过程中提出一个自对抗的任务,该任务其核心是叫做 Gaze feature purification(视线特征纯化),通过视线特征纯化,就能在原始的图里面学习到比较好的模型,并将它在多个目标域上面进行测试。
![]()
实现方法
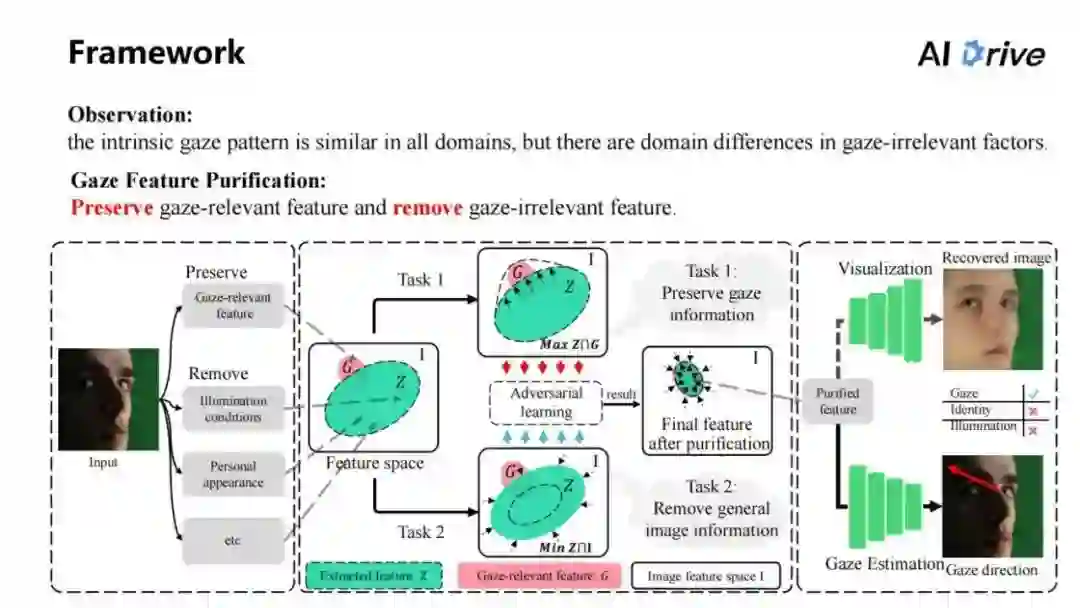
首先,这个方法的 Framework 其实是由一个起始的观察得到。相当于在所有的域上面,它本质的实现模式是比较相似的。
即不管在什么环境中,真正来看,以人为的角度去观察一个人、观察一个对象的时候,看它的视线方向的时候,其实只是看其眼睛是看哪边,对于每个人来说,不管其处于什么环境、或不管对面是什么人,注意力集中的位置就等于是眼球和两个眼角之间的相对位置。
但自己关注的本质的信息,其实对于其他人来说,可能有一些域的差异,会导致产生影响。
比如说在一个比较暗的环境中,其实本身的图像信息,它是和比较暗的环境信息是融合在一起的,这是并不能如愿所得的,这些环境信息跟图像信息融合在一起,这些差异性会导致很多与 Gaze 无关的因素。
所以,本文的主要想法就是视线特征的纯化。这需要把跟视线相关的特征保留下来,同时把无关的特征去除,这样得到的视线相关特征是比较好实现的,能够在每个域上面都得到使用。
上图展示了整体的 framework,如何从左图中得到结果,首先输入一张图片,这张图片要保存其中与视线相关的特征,同时要移除掉类似光照、特征、个人因素的影响,对于这些特征,可以把它映射到一个特征的空间中,即图中的I 区域表示整个特征的空间。
通常情况下,只需要提取 G 区域这一小部分,但是很多情况下提取特征的Z区域包含很大的空间,其中有很多的无关特征。为了解决视线特征纯化的问题,提出了两个任务,这两个任务分别是保留视线相关特征,即提取到的特征区域包含有更多视线相关的特征。
同时,对于另一任务,即移除掉视线无关的特征,这点是比较棘手的,因为对于视线无关特征来说,是无法定义清楚到底需要的是什么、需要消除的是什么。在左图中给出的例子,比如说是光照、个人因素,这是能够看到的最直接的目标。
但是在实际中,视线无关特征是多不胜数的,可能直接地在训练一个 gan 网络,对于特征来说,要求其不包含有光照信息的方案,一般是只针对于某一种信息,但是没有办法根本解决这个问题,这是没有办法解决移除掉视线无关特征的信息,所以要把整体的任务进行转换,像第一个任务还是一样的,保留一个视线信息。
同时,对于第二个任务,就变成了移除掉所有的图片信息,原来是对于网络结构、网络结果来说,想让整个的特征不包含有任何的图片信息,即对于任务二,也就如图中所画的,把绿色的圆圈尽可能地缩小,让它越小越好。
而且在这两个任务之间进行对抗学习,通过对抗学习,就能让其达到自平衡,因此它能够去把一些视线无关的特征去除,也能够把一些相关的特征很好地保留。
在这种情况下,在整个任务中,其实是要求让整个网络结构保留实验信息,同时让整个网络结构消除所有的图片信息,即并不要求它保留视线无关的信息,所以对于网络结构、对于网络特征来说,它们就是把视线无关特征,首先去除,然后提取特征,这就叫做纯化;通过它纯化特征,再使用它来进行视线估计。
所以,整个的 Framework 中,为了解决 Gaze FeaturePurification 的问题,对其中的保留视线相关特征和移除视线无关特征,要通过两个任务进行,第一个是保留视线信息,第二个是移除掉所有的图片信息。通过这样的任务,达到 Feature Purification。
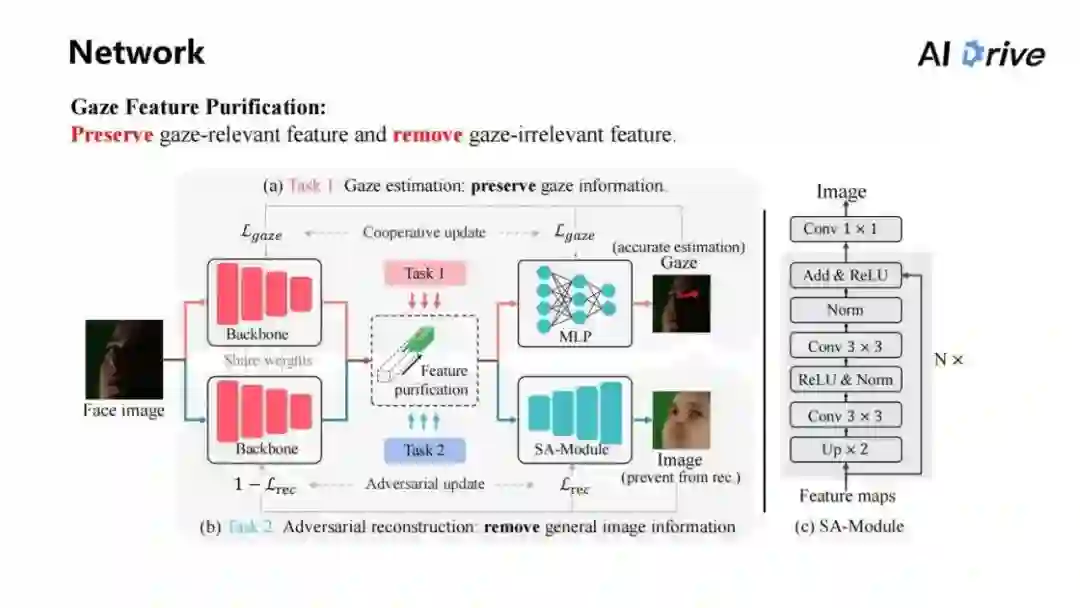
上图展示的是具体的网络结构的设置,首先要进行视线特征的纯化,即视线估计任务:保留视线信息。
可以直接看到上面的网络结构,即有一张图片,将图片输入到 Backbone 中,然后在 Backbone 中得到特征,再由特征得到 MLP,最后得到 Gaze 信息,这就是一个比较简单的视线估计网络。
对于 Backbone 和 MLP 来说,我们要求它是尽可能精准地估计视线方向,也是使用任务一保留视线信息。同时对于任务二,要去移除所有的图片信息。怎么让特征移除掉所有的图片信息,在这里做了一个假设。
这是从自动编码机里衍生出来的想法了,因为在自动编码机里,这个任务里一般认为,如果一旦原始的图片输到神经网络,得到特征,再重建回原来的网络、原来的图片。
如果重建的比较好,就默认整个网络结构把图片的特征压缩成很小的一块。
所以在这里,我们假设使用一个重建网络,不能从特征中去恢复出原始的图片,那就不包含任何的图片信息。总体的想法是构建让 Backbone 提取特征,中间不包含有图片信息,这需要让重建网络无法从特征中重建出原始图片来实现。
在这里整体的网络结构如下:输入一张图片,将其在 Backbone 中得到特征,而特征通过 SA-Module,一个比较简单的重建网络:其网络结构在图的右侧,基本上讲是 Feature maps 经过上采样等步骤,最后得到图片,再由重建网络输出图片。
对于重建网络,我们要求它是尽可能地从特征中重建回原始图片。对于 SA-Module 来说,其任务就是重建任务。同时,对于Backbone来说,Backbone 其实不是重建任务,因为它的目标不能让重建网络重建图片。
因此,图中下侧流程图的结构其实类似于重建的结构,但是会对它分配不同的损失,一个是重建损失,一个是阻止重建损失。
这样,两个网络结构就会进行相互的对抗。即 Backbone 是尽可能的让它重建不出图片,而如果 Backbone 有一丝松懈,比如漏了图片信息出来,这时 SA-Module,因为其任务一丝不苟地从特征重建图片;通过这种对抗达到去除图片信息的效果。
而对于任务一和任务二,其实这两个 Backbone 相当于要同时实现两个工作,一个是视线估计。另一个是实现对抗,即阻止重建,这样两个任务本身会对特征进行纯化。图中的意思即:对于上侧的视线估计网络,它尽可能地想多包含一些视线的相关特征。
另一方面对于 Backbone、对下侧的流程图来说,它实际上就整个的特征尽可能减少,这样在特征上进行对抗,来实现特征纯化。
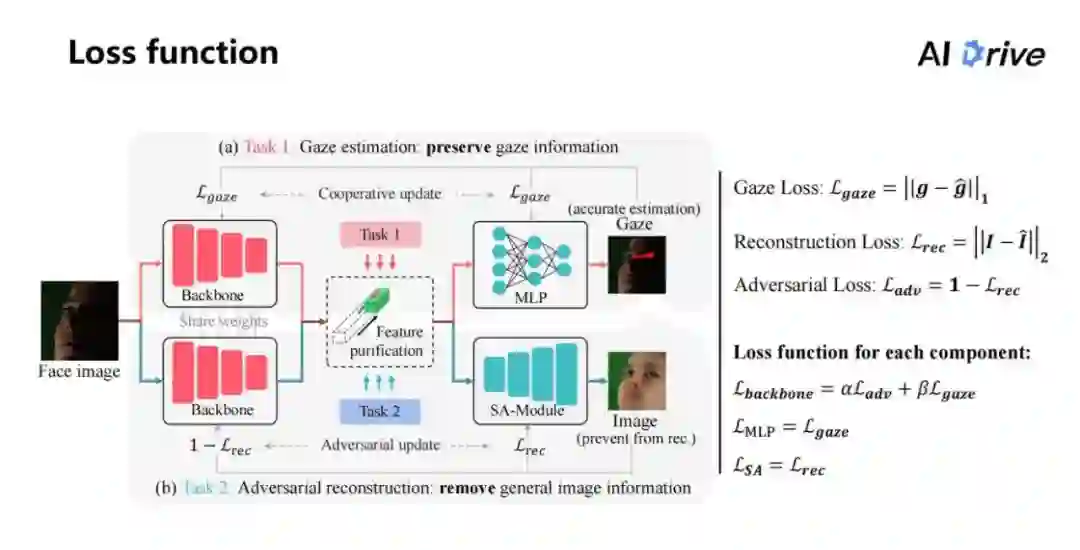
上图右侧是损失函数的设计组成,函数里的前面三个:一个是 Gaze 损失。
在这里用 L1 的损失,即把两个 Gaze 值相减,然后做绝对值;另外一个重建的损失,会把它重建出来的图片和原始的图片进行求 MSE 的损失。
对于每个部件来说,每个部件里包含三个部件,第一个 backbone,我们让它实现两个任务,第一阶段是视线估计的任务,同时还有阻止重建的任务,在这里给了两个权重让其自己权衡;而 MLP 就是从其特征中恢复出原始的视线;对于 SA-Model,就是从特征中间重建出原始的图片,这三个部分的特征是这样设定的。
![]()
除此之外,也加了其他的一些损失对原始损失进行修改。
第一个损失叫做局部纯化的损失,对于图片来说,其关注点更多要在眼睛,因此要让整个网络结构去纯化眼睛区域的特征,这个想法也很简单,可以通过直接加 attention map,使用其对于阻止重建任务进行约束。
另外是截断对抗损失,因为对于对抗重建任务来说,SA-Module 是要重建出图片,而 Backbone 是一减重建损失,很明显,要使重建的损失达到最小值,就是当恢复出来的图片和原始的图片是一模一样,这时候它才达到最小点。对于 Backbone 来说,这个时候则会出来一个完全相反的图片。简单来说,就是让整个的网络结构不恢复出原始的图片,并不是让它恢复出跟它相反的图片,它只要能够不恢复图片就行了,对 SA-Module 从 Backbone 中提取特征,它不包含任何信息,SA-Module 恢复出一张全白的图片,也是可以的。这样就说明了特征中是不包含所有的图片信息的。
对于损失进行一个阶段,我们只要让它阻止两个图片的相像程度能达到一定效果就可以了。它并不是说完全相反,而是从重建出来的结果完全一样和到完全相反,这中间的损失是从小到大的过程,我们只需要其损失达到一定地步时截断它,让它将来保持稳定的结果即可。
![]()
实验结果
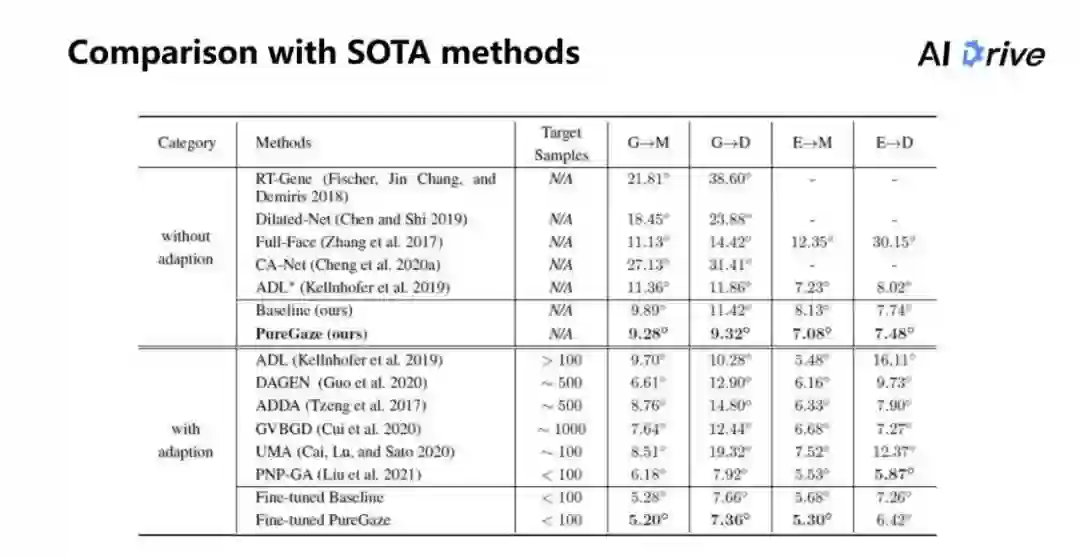
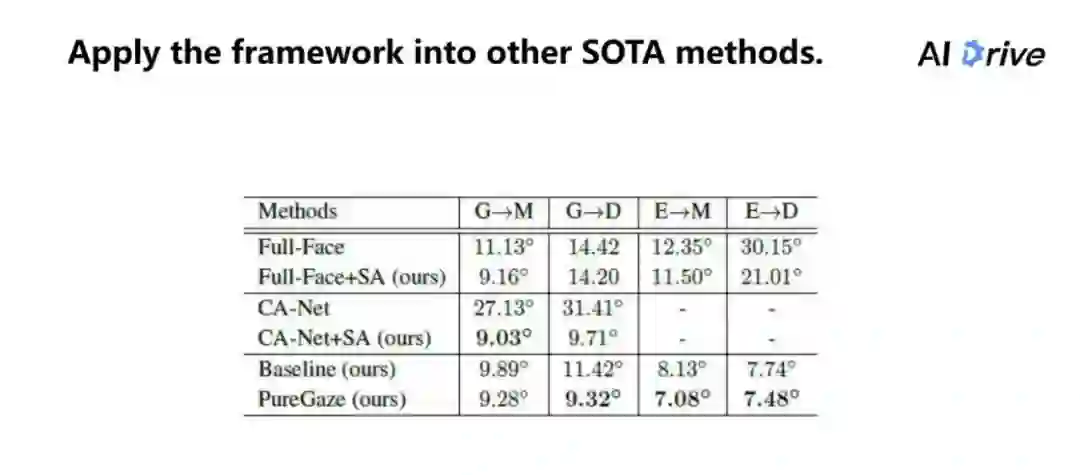
上图是和 sota 方法的比较,目前是分为两部分的比较,第一部分是使用 adaption 跟没有使用 adaption 的方法进行比较。
可以看到,在不使用 adaption 的情况下,对于在 Baseline 上每个数据都是有提升的。其中,G 其实是 Gaze360 数据集;M 相当于是 MPII Gaze 数据集;G→M 表示在 Gaze360 上进行训练,同时在 MPII 上测试;D 是 EyeDiap 数据集;E 是 ETH-XGaze。需要注意的是,在 G→M、G→D 这两个任务,其实只训练了一个模型,就是在 Gaze360 上面训练了同一个模型进行测试,虽然分了两栏表示,但是总体来说它只是一个模型。
另一方面,因为是跟使用 adaption 的方法进行比较,虽然在新数据上都是有一些优势的,但是也有一部分是不如此方法的。因为对于使用 adaption 来说,其会使用很多的目标的图片,而不使用 adaption 是不使用这些图片的。
另外,对微调后的结果来看,Fine-tuned Baseline 比 Fine-tuned PureGaze 的结果还是要高一点的,这说明了我们的方法,并不是只学习了一个比较好的通用模型,而是能够真正地学习到特征的表示,这种特征表示在进行微调过后,也保持了比较好的效果。
另一方面,这整个网络结构的 Framework 是包含两个任务的,一个是视线估计任务,一个是对抗重建任务。
对于这两个任务来说,视线估计的网络是并没有做明确要求的,我们把 Baseline 换成了在实现估计任务里的一些通用的算术方法,我们的网络结构直接应用到其他的方法上,也能达到比较好的效果提升。
上图是特征可视化的结果。因为在这个方法中,对于重建任务,它是相当于重建出原始的图像,如上图图片中的第一行是原始图像,第二行是原始特征,原始特征其实就是不加对抗中间结构的特征。
第三行的 Purified Feature 就是特征纯化的结果,但是重建出来的图片能够明显看出,对于每个人来说,其实提取到特征中间,每个人看起来都已经是学习到类似于平均脸的模型。
同时,图中的小白框里面标记的是在采集数据的时候,实验者会在头部后面垫一个架子,保持头部尽量地固定好。这就相当于这些噪声也是不小心被捕捉进去了。但是模型其实也能够把无关的东西它有一定程度的消除。
对于右边这张图,就是代表对于明暗的程度上的变化,在原始的图片上,会有明暗的交界,这个交界称其为阴阳脸,对原始的特征来说,恢复出来的图片跟原始的图片差不多,但对暗处就恢复不清楚,而对于这个方法结果可以看出,它能够把总体的光照程度变得差不多,即把光照的因素消除,在消除的同时,还能捕捉出原始的视线信息。
而最下面的一行图片,其实是对于每张原始图进行对比度亮度的调节,可以看出就跟重建出来的图片来比较,视线方向是比较类似的。即我们的方法的确是从暗处把眼睛的特征捕捉出来,同时还能够把那些光照信息消除。
如上图也可以看出,在图片亮度达到最暗(纯黑)的情况下,模型依然可以消除一些光照的因素,把非常黑暗的部分中间的特征恢复出来,而且眼睛也感觉是看的比较好的结果。
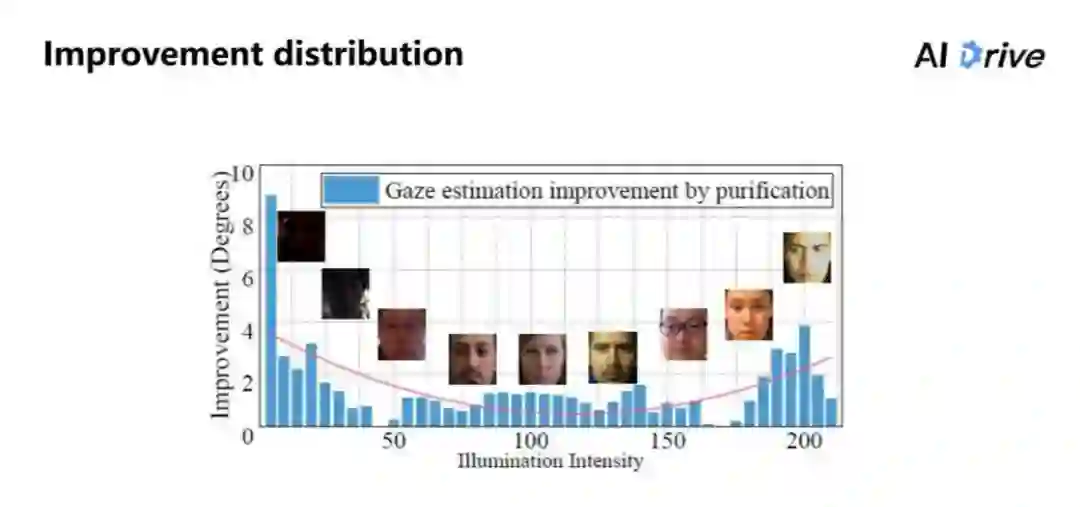
上图是进行具体测试的结果。把 PureGaze 和 Baseline 两个方法在每个光照强度上进行测试,把纯化特征带来的提升把它可视化出来。
可以看得出来,我们的方法它能够对于暗处以及比较偏亮的这两个区域来说,其整体的性能是有很大的提升。同时对于中间区域的提升不是说很大,但是中间特征是比较平均,比其他区域会少一点。这就说明该方法能够对光照强度有一定的处理效果。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()