Nature2017| AlphaGo Zero强化学习论文解读系列(二)

本文带来强化学习论文系列的第二篇文章:「Nature 2017, AlphaGoZero」: Silver D, Schrittwieser J, Simonyan K, et al. Mastering the game of go without human knowledge[J]. nature, 2017, 550(7676): 354-359.
在第一篇文章Nature 2016| AlphaGo 强化学习论文解读系列(一)中,我们介绍了AlphaGo使用了监督学习+自监督强化学习+围棋领域人工特征+策略网络和值网络+蒙特卡罗搜索和rollouts的方法。相比于AlphaGo,AlphaGoZero做了进一步的简化和升级,只使用自监督强化学习+无人工特征+单一网络+蒙特卡罗搜索。下面将详细介绍AlphaGoZero方法。
摘要
人工智能的长远目标之一就是研发出一种能够从白板开始学习,并逐渐进化成拥有超常能力的算法。目前,AlphaGo成为了第一个打败围棋世界冠军的程序。AlphaGo的核心是使用深度网络在蒙特卡罗树搜索过程中进行棋盘局势判断和走棋选择决策。这些深度网络使用监督学习的方法从人类专家棋谱中进行训练,使用强化学习的方法从自我对弈的过程中进行训练。本文介绍一种只使用强化学习的训练算法,除了需要基本的围棋规则以外,不需要人类围棋数据、指导和领域知识。本文使用强化学习得到的深度网络能够同时进行棋盘局势判断预测获胜者,以及走棋选择决策。这个深度网络能够提高树搜索的优势,使得在下一次迭代时,保证更高质量的走棋选择,以及更强的自我对弈。AlphaGo Zero从白板开始学习,能够达到超常的能力,并在实践中,以100:0的绝对优势战胜了此前发布的、打败欧洲围棋世界冠军的AlphaGo。
思考
1. 白板学习达到超常的能力,很不可思议。
2. 我觉得这里面并不是完完全全的“无监督“,最强的监督恰恰是最基本的围棋规则和不断试错的环境反馈。之
前我质疑两个6岁的小孩不断自我对弈,就能够达到职业选手的水平。我觉得是有可能的,前提是懂围棋规则,并
且能够不断得到反馈。前者是对弈的基础,后者是对弈的关键。小孩在对弈过程中,得到反馈后,会在大脑中进
行自我调节,不断校正走棋选择,不断提升能力。而深度网络的反馈靠的是损失函数,自我调节的是网络的连接
权重,因此也能够不断提升能力。
3. 我觉得最强的智能,一定是需要设计一个恰当的环境反馈,但是规则不需要给出,而是通过不断的试错反馈就
能学习到这种规则,并且最终达到超常的能力。
4. 这里的强化学习算法和AlphaGo中的强化学习算法的区别在哪?
答:通过下述论文的阅读,AlphaGo Zero中使用Policy Iteration的强化学习算法,并结合
蒙特卡罗搜索树,执行Policy Iteration算法中的Policy Improvement和Policy
Evaluation。而AlphaGo中使用Policy Gradient强化学习算法,直接进行策略函数逼近,
学习到策略分布。
研究现状
目前人工智能领域的成就主要得益于监督学习,使用监督学习的方法从人类专家数据中进行训练,达到复制、模仿人类专家决策的目的。然而,人类专家的数据通常是昂贵、不可靠甚至不可得到的。即使能够得到可靠的专家数据,训练得到的监督学习系统通常也会达到一个性能瓶颈。相反,强化学习系统从自我经历中训练,原则上可以超越人类的能力,并且能够发掘出人类不曾发现的未知领域。目前,使用强化学习训练的深度神经网络在这一目标上已经取得了快速的发展。例如计算机游戏Atari、3D虚拟环境等,强化学习系统已经超越了人类水平。然而,对于人工智能领域最富挑战性的围棋游戏,上述通用的方法还无法取得和人类水平相当的成就,主要是因为围棋游戏需要在一个浩大的搜索空间中进行精准、复杂的lookahead搜索。
AlphaGo是第一个在围棋领域达到超越人类水平的程序。此前发布的AlphaGo Fan打败了欧洲围棋冠军Fan Hui。回顾一下,AlphaGo使用两个深度网络,策略网络输出下一步走棋的概率分布,值网络判断当前棋面局势,预测获胜者。策略网络一开始使用监督学习的方式,用于加快预测专家走棋;随后使用Policy Gradient的强化学习算法进行重新优化。值网络从策略网络自我对弈过程中进行训练学习,用于预测获胜者。离线训练完后,再使用蒙特卡罗搜索树将深度网络结合起来,使用策略网络将搜索局限在高概率的动作,使用值网络(和Fast Rollout Policy结合)来评估叶子节点的棋面局势,多次执行蒙特卡罗模拟,最终选择访问次数最多的边对应的动作为下一步棋的下法。值得注意的是,后续发布的AlphaGo Lee使用了相似的方法,打败了18届围棋世界冠军李世石。
核心工作
AlphaGo Zero不同于AlphaGo Fan和AlphaGo Lee。主要体现在如下几个方面:
-
第一点也是最重要的一点,AlphaGo Zero只使用强化学习训练。AlphaGo Zero从白板开始学习,不使用人类监督数据,在自我对弈中,进行强化学习训练。 -
第二点:只使用棋盘上黑白棋作为输入特征。不需要人工设计的围棋领域的特征。 -
第三点:只使用单一的神经网络。不使用分开的策略网络和值网络。 -
第四点:使用简单的树搜索,且树搜索只依赖于上述单一的神经网络,同时进行棋面局势评估和走棋动作选择。抛弃了蒙特卡罗Rollouts(AlphaGo中的Rollout Policy)。
为了实现上述目标,本文研究出一种新的强化学习训练算法,将蒙特卡罗树搜索树纳入训练阶段。新的算法使得性能提升更快、学习更加精确和稳定。
思考
1.这里的关键在于直接把蒙特卡罗搜索树纳入训练过程。此前AlphaGo中,蒙特卡罗搜索树在在线对弈时候才使
用。这个思路前面阅读AlphaGo的时候,我也有产生疑惑,为啥不直接在训练过程使用蒙特卡罗搜索树,但是没
有进一步深入。有时候灵感可能真的是稍纵即逝。
2.上述4点改进很有启发意义。
- 第一点白板学习意义重大,不需要监督学习数据,意味着程序本身要自己生成数据。后续要关注数据是如何生
成的。这里的强化学习是如何训练的?用的是Policy Gradient, Policy Iteration,
Q-learning还是什么?这几种训练方法又有何差异?需要研究下强化学习算法。
- 第二点只使用黑白棋作为输入特征,说明改进的深度网络结构在学习特征表示方面,能力更强。需要研究下新
的深度网络架构。
- 第三点,只使用单一的神经网络。相当于是合并了策略网络和值网络,那么这里就有两个优化目标,一个是输
出下一步走棋概率分布,另一个是进行棋面局势判断,预测获胜者。问题的关键在于,如何只使用单一的神经网
络达到优化两个目标的目的?需要研究下损失函数的设计方法。
- 第四点,使用蒙特卡罗树搜索,且同时进行棋面局势评估和走棋动作选择。相当于将蒙特卡罗树的Expansion
阶段和Evaluation阶段合并了,这两个阶段分别代表宽度剪枝原则和深度剪枝原则。传统方法是通过人工设计
评分函数得到的。这说明了强化学习训练得到的网络能在启发式搜索中取代人工设计评分函数。因此也需要研究
下这里的强化学习算法(个人感觉这里的关键是将蒙特卡洛搜索纳入训练过程)。
第四点也间接解决了我上一篇笔记中关于不使用策略网络的AlphaGo如何进行Expansion的疑惑。实际上使用
单一的网络能够同时实现Expansion和Evaluation,AlphaGo中的值网络也能够间接的进行Expansion(
选择value大的动作)。
强化学习算法Policy Iteration
-
网络结构:深度残差神经网络 ,参数为 。每个卷积层由许多残差块组成,使用batch normalization和rectifier nonlinearities.
-
输入层:Raw Board Representation of the position and its history。只使用棋面的黑白棋特征。
-
输出层: ,输出下一步动作的概率分布和预测值。 是一个向量,代表下一步动作的概率分布 , 是一个值,代表当前下棋方获胜的概率。
-
作用:同时充当了策略网络和值网络的角色。
-
「训练」:AlphaGo Zero中的深度神经网络,使用强化学习算法在自我对弈的过程中进行训练。对于每个棋面 , 使用前一轮得到的神经网络 来指导MCTS蒙特卡罗树搜索。蒙特卡罗搜索树会输出每一步走棋的概率分布 ,称之为搜索概率。搜索概率比单纯的神经网络输出 概率分布更好,能够选择更强的走棋。从这个角度来说,MCTS可以看做是Policy Iteration算法中的策略提升操作(policy improvement operator)。这意味着,在自我对弈过程中,不断使用提升过的、基于蒙特卡罗搜索树的策略 来进行决策走棋,最终会决出胜负,将最终的获胜方 作为一个样本值,可以看做是Policy Iteration中的策略评估操作(policy evaluation operator),即对当前棋面局势的评估,作为当前棋面下,获胜概率的预测值。这里强化学习算法的关键是在策略迭代(policy iteration)过程中,不断重复地使用这些搜索操作,即policy improvement和policy evaluation。蒙特卡罗搜索结束后,更新神经网络参数,使得更新完的神经网络的输出:移动概率和预测值 ,能够更加接近MCTS得到的搜索概率和自我对弈的获胜方 。这个新的神经网络将在下一轮自我对弈中继续指导蒙特卡罗搜索,使得搜索变得更健壮。
具体训练的一些细节如下:
-
「MCTS搜索模拟过程」:使用神经网络 来指导模拟过程。搜索树的每条边存放先验概率 ,访问次数 和动作效益值 。
-
「数据产生(自我对弈)过程」:在每局自我对弈过程中,使用前一轮的强化学习网络来指导蒙特卡罗搜索树进行下棋。对于该局的每个时间步 的棋面 ,蒙特卡罗搜索模拟过程产生下一步走棋概率分布 ,因此能够产生数据对 。不断对弈直到时间步 时刻,该局决出胜负,得到报酬 。再回过头,将该 作为标签贴到前面时间步$t(<t)$产生的数据对$(s_t, \pi_t,="" z_t)$的$z_t$上,其中$z_t="±r_T$," $±$符号根据当前棋面对应的下棋方确定。由此1局对弈便可产生许多训练数据$(s_t,="" z_t)$。训练的时候,$s_t$是神经网络的输入:当前棋面提取的特征,$(\pi_t,="" z_t)$是样本$s_t$的标签,="" 神经网络的输出$(p,v)$要拟合该标签。<="" p="">
-
「优化过程」:神经网络首先使用随机权重 进行初始化。在后续每一轮迭代 中(每轮迭代对应若干局完整的围棋对弈),神经网络使用强化学习算法Policy Iteration进行训练优化,该强化学习算法将蒙特卡罗搜索树纳入训练过程,用前一轮的神经网络 在该轮迭代 的每个时间步 来指导蒙特卡罗搜索 ,直到时间步 产生胜负,按照上述描述来构造该轮对弈产生的数据 。接着,从该轮所有时间步产生的数据中进行正态随机抽样得到训练数据 ,神经网络使用该训练数据进行参数更新,目标是使得新的神经网络的输出 能够拟合 ,也即最小化 和 之间的误差,最大化 和 之间的相似性。优化损失函数如下, 结合了MSE和cross-entropy loss(还包括正则化项)。
Select: 每次模拟从当前棋面对应的根节点s开始,不断迭代的选择置信上界 最大的动作 进行搜索,一直搜索到遇到叶子节点。
Expand and Evaluate: 叶子节点访问次数达到一个阈值时,此时进行扩展并评估。使用神经网络产生先验概率和评估值。 。「此处体现了神经网络是如何指导蒙特卡罗搜索的」。
Backup: 更新到达叶子节点所经过的边的访问次数和Q值, Q值更新使用公式:
Play: 多次模拟过程结束后,得到搜索概率分布 , 搜索概率正比于访问次数的某次方 , 称为温度参数(temperature parameter)。那么最终的走棋Play,可以使用该分布 来抽样动作 。
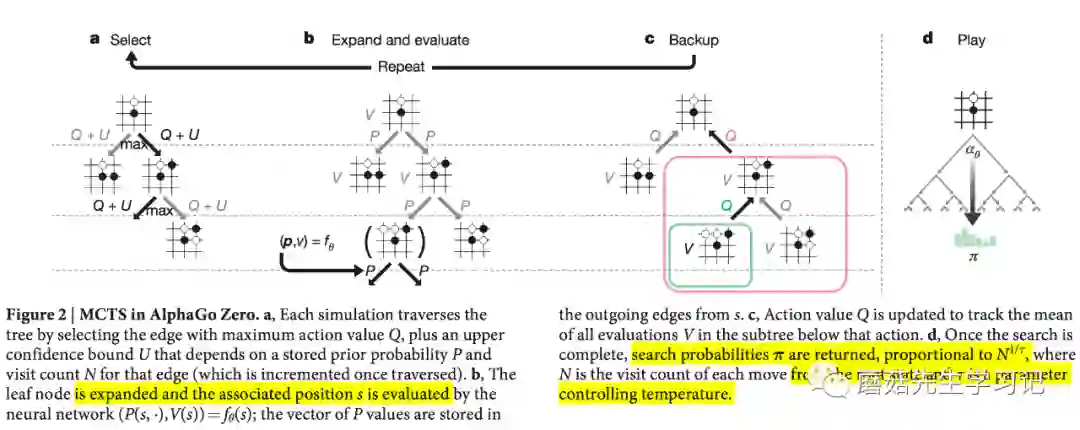
上述描述的是连续训练的版本,即每次都使用最新轮次的神经网络进行自我对弈和产生训练数据,实际自我对弈和训练过程中,部分细节和上述不大一样:
-
训练数据是到目前为止最好的 (神经网络 指导下的蒙特卡罗搜索树 )自我对弈产生的。实际训练时,从到目前为止的500,000个棋面数据中进行正态抽样进行参数更新。
-
每训练1000轮,需要进行评估。当前最好的 和当前轮次 进行400局对决,如果 超过55%的胜率,那么使用 替代 。下轮迭代使用新的 自我对弈产生数据。
-
训练过程包括三个「并行」的核心子过程:
自我对弈和训练优化过程示意图如下:
-
优化子过程 。首先从到目前为止 产生的500,000个棋面数据中正态抽样,接着使用随机梯度下降优化(mini-batch:2048;冲量参数:0.9;正则化参数: .) -
评估子过程 。每1000轮,设置一个检查点,进行评估。当前最好的 和当前轮次 进行400局对决。(每步棋使用1600次MCTS模拟) -
自我对弈过程 。使用当前最好的 进行自我对弈产生数据。每轮迭代进行25000局完整对弈,每步棋使用1600次MCTS模拟。每局的前30步棋,温度参数设置为 , 走棋概率正比于访问次数,保证走棋的多样性;后续步 ,访问次数最多的动作的概率趋于1,其余概率为0。另外,为了增加探索 , 根节点 先验概率上加入狄拉克噪声 , 其中,参数值为 , 。
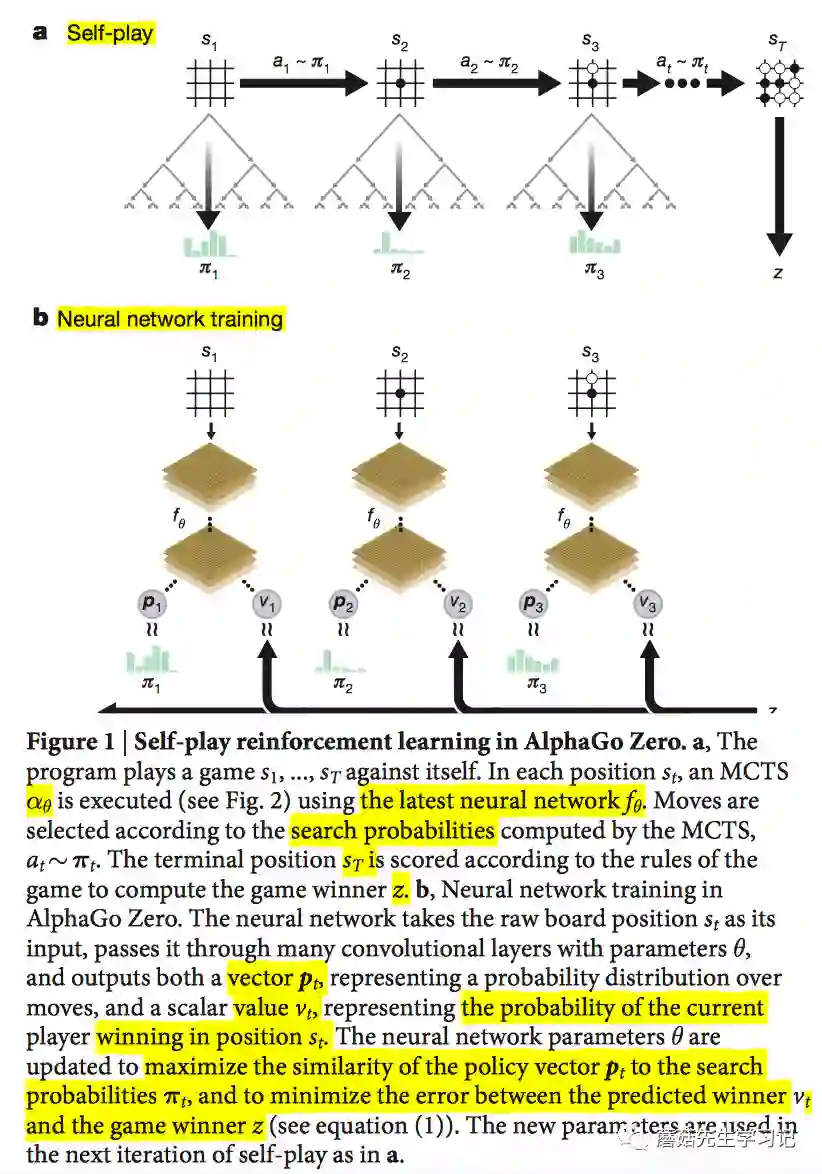
思考
1. 这里核心技术是将蒙特卡罗搜索过程纳入强化学习训练过程。和AlphaGo比起来,AlphaGo强化学习策略网
络直接使用强化策略网络的输出概率分布进行走棋自我对弈,而AlphaGo Zero在输出概率基础上使用蒙特卡罗
搜索,能够提升走棋的健壮性,从而提高生成数据的质量。个人认为这是AlphaGo Zero能够从白板开始学习
并最终获得超常能力的核心原因之一。
2. 核心技术之二是残差神经网络的使用,ResNet能够比较有效的防止梯度消失和梯度爆炸,因此使得网络更深
,学习到的特征更丰富,这也是只使用棋面特征作为输入的重要原因。
3. 强化学习算法的思考:
- 这里AlphaGo Zero强化学习使用的是Policy Iteration,而AlphaGo中使用的是Policy
Gradient。Policy Iteration和Q-learning类似,是一种value based的强化学习算法,目标
是最大化贝尔曼方程,Policy Iteration最大化贝尔曼期望方程,Q-learning最大化贝尔曼最优方程。最
终得到的都是一个确定的策略(near-deterministic policy)。而Policy Gradient是一种policy
based的强化学习算法,直接优化策略函数,是一种函数估计的思想,优化方法根据奖励报酬来最大化期望输出
,最终会得到策略分布函数,可以在很大的policy空间学习到随机policy。
- 注意,个人认为AlphaGo Zero蒙特卡罗搜索得到的本来是一种确定的策略(Policy
Iteration本质仍然是优化bellman equation),其最终策略分布π,实际上只是通过蒙特卡罗搜索模拟过
程节点的访问次数计算得到的,见上述蒙特卡罗Play阶段。或者可以认为AlphaGo Zero的强化学习算法是
value based和policy based方式的结合。
- 个人认为Value based方法和Policy based的区别相当于最大似然估计和贝叶斯估计的区别,最大似然估
计是基于设计者所提供的训练样本的一个最佳解答;贝叶斯估计是许多可行解答的加权平均值,反映了对各种可行
解答的不确定程度,反映出对所使用的模型的剩余的不确定性。回过头看AlphaGo使用Policy
based方法,即Policy Gradient,AlphaGo Zero使用Value based方法,即Policy
Iteration。我个人大胆猜测这里原因可能是蒙特卡罗搜索过程引入训练过程,使得Value
based方法得到的策略确定性和可靠性大幅度提高,不需要过多考虑剩余不确定性。另外,此处Value
based的方法训练速度快,不需要动用大量的资源就能保证收敛速度。当然,AlphaGo Zero最终在Policy
Iteration基础上,仍然使用蒙特卡罗搜索树输出策略的概率分布,也表明了对这两种方法的权衡和结合。
4. 上述优化损失函数的设计值得学习,同时将两个目标纳入一个损失函数。使得策略网络和值网络能够合并起来。
5. 离线训练完后,如何进行在线对弈比赛呢?
答:仍然是使用MCTS蒙特卡罗搜索。过程和训练一致,使用强化学习神经网络指导蒙特卡罗搜索,多次模拟,最
后对每条边的访问次数进行计算,得到动作的概率分布,再根据概率分布进行抽样,抽样得到的动作作为最终走
棋。
对比实验
使用强化学习管道方式来进行AlphaGo Zero的训练。训练从完全随机的行为开始,一直持续3天,期间不需要人为的干涉。在这个过程中,总共生成了490万个自我对弈棋局,每次蒙特卡罗搜索进行1600次模拟,相应的每步走棋平均花费0.4s,神经网络的参数使用70万个mini batch, 每个mini batch包含2048个棋面进行更新,该残差神经网络包含20个残差块residual blocks。
-
「考察AlphaGo Zero训练过程能力变化情况」
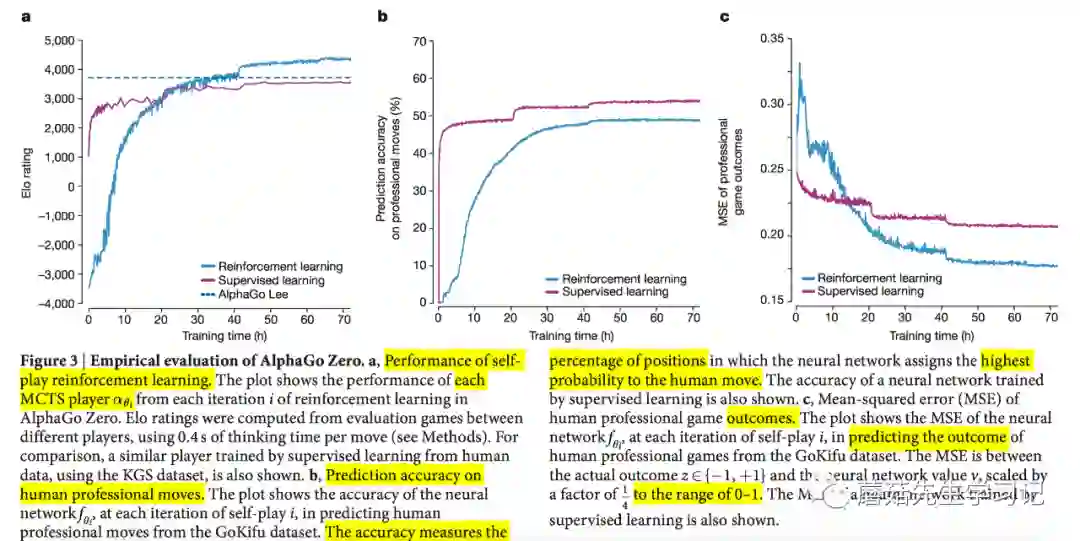
图3a显示了AlphaGo Zero性能随着训练时长增长的变化情况。曲线上的每个点代表该时间点对应的第 轮迭代得到的蒙特卡罗搜索树 的 能力值。形象的说,每轮迭代完都会产生一个使用深度网络 指导的蒙特卡罗搜索树玩家 ,让该玩家去和其他玩家进行在线对弈,最终计算出 能力值。可以看出AlphaGo Zero能力值一直不断稳步提升,克服了震荡和遗忘性能的问题。且3天之后,能力值还有向上的趋势。作为对比,绘制了监督学习的性能变化曲线,该监督学习使用相同的网络和算法,但是数据不是通过自我对弈产生的,而是来自KGS dataset人类的数据,曲线表明监督学习一开始性能比AlphaGo Zero高,但是上升缓慢,24小时的时候,就已经被AlphaGo Zero超越。另外,还绘制了训练数个月的AlphaGo Lee的 值,可以看到训练36个小时的AlphaGo Zero已经超越了训练数个越的AlphaGo Lee的能力值。
-
「考察AlphaGo Zero和AlphaGo Lee对决」
AlphaGo Lee是使用当初战胜李世石的分布式AlphaGo版本,使用48个TPUs。AlphaGo Zero使用训练72小时的单机器版本,使用4个TPUs。最终,AlphaGo Zero以100:0绝对优势战胜AlphaGo Lee。
思考
1. 上述监督学习中,人类数据是什么时候使用的?
有两种理解。1)第一种理解,训练过程不需要蒙特卡罗搜索。强化学习训练过程中的蒙特卡罗搜索的目的是产生
下一步下法,并不断自我对弈,得到最终的获胜方,再构造该轮迭代的数据进行学习优化。而监督学习数据已经
知道下一步的下法和最终的获胜方,因此可以直接喂给深度残差神经网络进行训练优化即可。除了不需要蒙特卡
罗搜索进行自我对弈来产生数据以外,其余都相同,包括网络架构、优化的损失函数、训练数据的抽样方法等。
当然训练完在线对弈的时候,还是需要MCTS的。2)另一种理解是,这里的监督学习曲线类似下文提到的
AlphaGo Master,只在初始阶段进行监督学习,后续训练和Zero完全一致,即使用Policy
Iteration强化学习,且训练过程用到蒙特卡罗搜索树。
答:根据方法论中,正确理解是第一种。
For comparison, we also trained neural network parameters θSL by supervised
learning. The neural network architecture was identical to AlphaGo Zero.
Mini-batches of data (s, π, z) were sampled at random from the KGS dataset,
setting πa = 1 for the human expert move a. Parameters were optimized by
stochastic gradient descent with momentum and learning rate annealing, using
the same loss as in equation (1), but weighting the MSE component by a factor
of 0.01. The learning rate was annealed according to the standard schedule in
Extended Data Table 3. The momentum parameter was set to 0.9, and the L2
regularization parameter was set to c = 10−4.
2. Reinforcement Learning训练算法的改进 (Policy Gradient -> Policy Iteration)。论文
并没有量化这一改动的影响。但个人认为这里的改动很可能导致的在不动用大量计算资源的情况下更稳定的收敛
速度和更好的克服遗忘性能。
3. 这里需要进一步考察这种性能的提升是得益于网络架构的改变还是训练算法的改进。
4. 这里的问题是,能力之间有时候不满足传递性。A比B强,B比C强,并不能说明A比C强,实际情况中,C可能
是A的克星。因此,这里AlphaGo Lee输了,只能说明作为同样是人工智能的AlphaGo
Zero可能更懂“机器思维”,但是不一定懂“人类思维”。因此我认为AlphaGo
Zero需要实际和人类围棋世界冠军比赛,才能说明真的提高了能力。这方面的相关佐证资料,AlphaGo
Master乌镇联棋和AlphaGo Master/Zero对弈棋局都表明当AlphaGo自我判断出于下风棋时,有可能进入"
疯狗模式“。即走出一些明显是打将的损棋,期待对手漏看。不难想象,如果进入疯狗模式的AlphaGo认为对手
会漏看,基于概率行棋的另一只狗很有可能真的会漏看。而人类却恰恰有能力发现这点。因此需要实际和人类对
弈才能说明问题。
-
「考察AlphaGo Zero预测人类专家下棋的能力」
使用KGS Server Dataset人类专家下棋数据,测试AlphaGo Zero预测人类专家下棋的能力。也就是说,测试的时候,输入人类下棋的棋面数据,输出下一步的下法,看看和人类实际的下法是否相同,计算出预测准确率。作为对比,绘制出监督学习的预测能力,使用相同的网络和算法,但是数据不是通过自我对弈产生的,而是来自人类的数据。如下图3b所示,可以看出在预测人类专家下棋能力方面,AlphaGo Zero的强化学习算法比监督学习算法弱。值得注意的是,虽然AlphaGo Zero预测人类专家下棋能力稍弱,但是其围棋能力和最终输赢的预测能力却胜过监督学习,可以看下图3c的MSE曲线图。这说明AlphaGo Zero自学到某些围棋策略,这些策略和人类围棋下法有质的不同。
-
「考察AlphaGo Zero性能提升的原因」
为了分析AlphaGo Zero性能提升主要归功于神经网络架构的改变还是训练算法的改进,本文做了一组对照实验,考察神经网络架构本身和组合方式的不同对性能的提升情况。网络架构类型包括卷积神经网络conv、残差神经网络res;网络架构组合方式包括分开的策略网络和价值网络sep、合并的神经网络dual。两两组合包括,sep-conv, dual-conv, sep-res, dual-res。其中dual-res是AlphaGo Zero的网络架构,sep-conv是AlphaGo Lee的网络架构。每种组合的训练数据都使用此前训练72小时的AlphaGo Zero产生的数据,而对弈的对手都是此前AlphaGo Zero的不同迭代周期得到的蒙特卡罗搜索树选手。图4a,绘制的Elo rating值是和这些选手比赛评估得到的。可以发现不管是架构本身改变还是训练算法改进都对性能有很大的提升。sep-res和sep-conv的对比可以看出架构由卷积神经网络改为残差神经网络,Elo能力提高了600分。dual-conv和sep-conv对比可以看出网络架构组合方式由分开的策略和价值神经网络改为单一的使用蒙特卡罗搜索的神经网络,Elo能力也提高了600分。dual-res和sep-conv的对比,则是这两种改进的叠加效果,Elo能力值提高了1200分。这种能力的提升,作者将其归功于不仅是计算效率的提高,更重要的是合并的优化目标能够使得网络更加规范化,能够学习到一个共同的表示来支持多种场景(个人认为这里的多种场景指的是既可以用来预测下一步动作概率分布,也可以用于预测最终获胜者)。对于图4b, 可以看出预测专家走棋方面,使用残差神经网络预测准确率以及使用合并的网络预测准确率都比原来的sep-conv有所提升,且残差神经网络的使用提升更大。图4c预测最终输赢方面,使用残差神经网络预测MSE以及使用合并的网络预测MSE都比原来的sep-conv有所降低,且二者降低效果差不多。
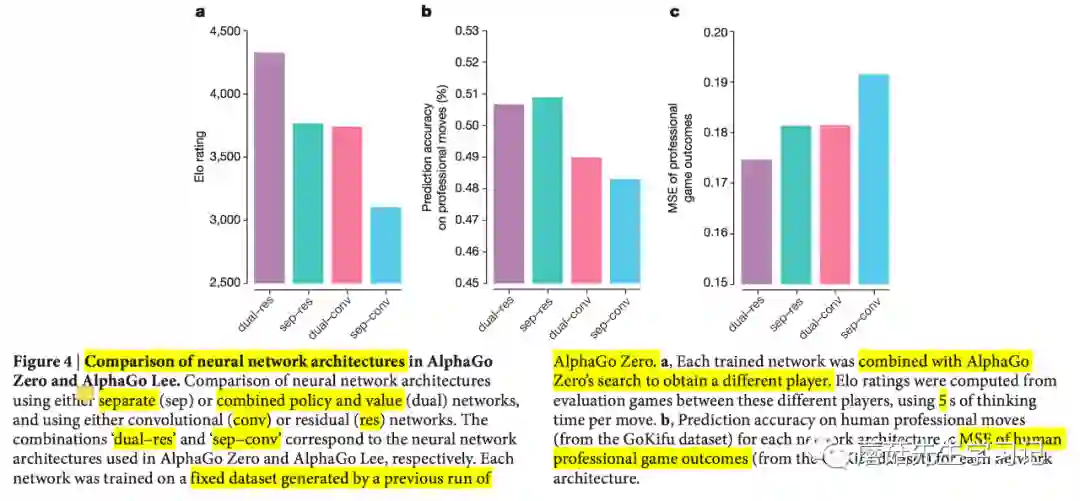
思考
1. 这里对比的疑问在于训练数据和选手都是AlphaGo Zero生成的,这样对比合理吗?用AlphaGo
Zero生成的数据进行训练,虽然生成训练数据和选手的AlphaGo Zero和对比实验使用的AlphaGo
Zero不同,但不是仍然是倾向于AlphaGo Zero赢吗?
2. AlphaGo中使用训练数据和AlphaGo Zero中使用训练数据的方式和时间点一样吗?
AlphaGo有2种猜想。1)使用训练数据用于监督学习策略网络的训练,此后强化学习策略网络再与该监督学习策
略网络对弈,用对弈产生的数据进行强化学习策略网络的训练,不需要使用上述训练数据?2)还是说不需要训练
监督学习策略网络,强化学习策略网络的训练也不需要自我对弈,而是直接使用上述训练数据进行训练?
AlphaGo Zero使用训练数据是指不需要蒙特卡罗搜索树自我对弈生成数据,直接使用上述数据进行训练?
文中没有讲清这一点。但是个人感觉AlphaGo是第二种。也就是说二者都不需要自我对弈过程,直接使用训练数
据进行训练。
Each network was trained on a fixed dataset containing the final 2 million
games of self-play data generated by a previous run of AlphaGo Zero, using
stochastic gradient descent with the annealing rate, momentum and
regularization hyperparameters described for the supervised learning
experiment; however, cross-entropy and MSE components were weighted equally,
since more data was available.
3. 文中还提到不管哪种组合的网络架构,都使用前文公式1作为优化损失函数。这里仍然有疑问,优化目标都使
用同一个,对于策略网络和值网络分开的类型是不公平。正常可以分开两个目标函数,各自优化;现在合并成一
个目标函数,同时优化,个人感觉会对性能有所影响,这样对比的化,凸显不出真实的差距。如果合并目标函数
比分开目标函数更好,应该也做个对比实验说明一下。如果真的是这样的话,那么上述对比就更具鲁棒性。
4. 针对3中的问题,仍然有个疑问。公式1中优化项包括策略分布π和获胜预测概率z。对于使用分开的策略网
络和值网络,策略网络只输出策略分布,值网络只输出预测概率。那么相当于优化策略网络的时候,预测概率的
误差不起作用,为0;优化值网络的时候,策略分布误差不起作用,为0。还是说,有点类似GAN生成式对抗网络
中两个网络的训练,两个网络的计算图是共用的,相互轮流迭代,每次迭代都同时考虑上述两个优化项的误差。
-
「考察AlphaGo Zero 学习到的围知识」
观察AlphaGo Zero自我对弈过程,可以发现AlphaGo Zero会逐渐学习到一些围棋领域的常用套路模式,另外AlphaGo Zero还会学习到一些人类专业比赛中比较少见的围棋知识,AlphaGo Zero的一些偏好和人类有较大的差异。
-
「考察AlphaGo Zero的终极性能」
使用上述网络架构和强化学习训练算法训练一个网络更深、时间更长的AlphaGo Zero。训练从完全随机的行为开始,一直持续到40天。在这个过程当中,生成了2900万局自我对弈棋局。参数使用310万mini batch,每个mini batch包括2048个棋面数据,进行更新。神经网络包括40个残差块。学习曲线如下图6a所示。本文还将完整训练好的AlphaGo Zero和AlphaGo Fan、AlphaGo Lee、AlphaGo Master以及一些围棋程序举行锦标赛。其中,AlphaGo Master使用的网络架构和训练算法和AlphaGo Zero完全一致,唯一不同的是使用人类专业数据和手动设计的特征进行训练。AlphaGo Master曾在2017.1月线上以60:0的绝对优势战胜了最顶尖的人类专业选手。在我们的评估过程中,每个程序允许每步思考5s。AlphaGo Zero和AlphaGo Master使用单机器4个TPUs,AlphaGo Fan和AlphaGo Lee使用分布式部署,176个GPUs,48个TPUs。另外,我们还对比了Raw network的性能,也就是说在线对弈时不使用蒙特卡罗搜索,直接使用神经网络输出的动作分布来抽样走棋。实际的性能对比如下图6b所示。可以看出AlphaGo Zero 5185分和AlphaGo Master4858分遥遥领先,AlphaGo Zero略胜一筹,高出300分左右。
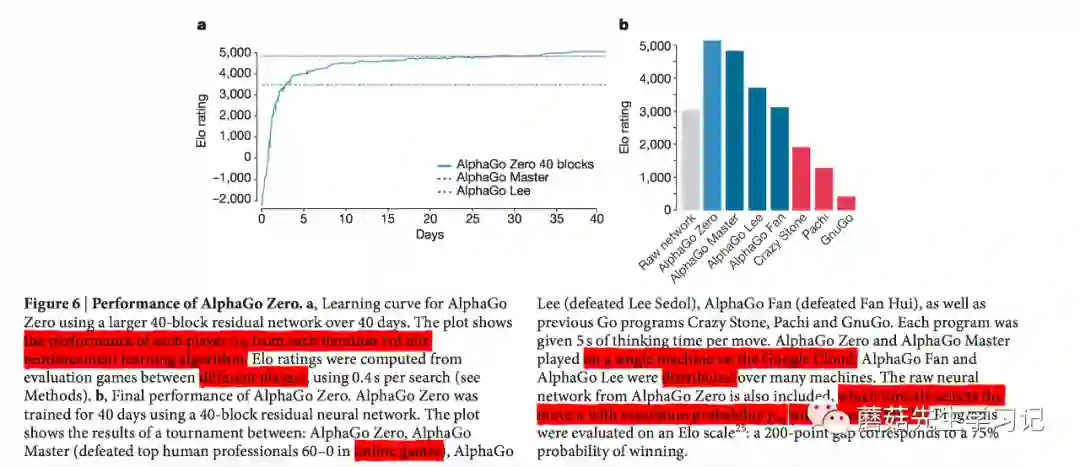
进一步,AlphaGo Zero和AlphaGo master直接正面对决100局。最终,AlphaGo Zero以89:11战胜AlphaGo Master。可以说明强化学习自我对弈生成的数据比人类专业比赛数据更好。
思考
1. 上述的AlphaGo Master网络架构和训练算法都和AlphaGo Zero一致。一致主要包括使用深度残差神经
网络、使用合并后单一的神经网络、使用相同的目标损失函数、相同的强化学习算法、在线对弈时使用相同的蒙
特卡罗搜索模拟。不同之处在于,AlphaGo Zero只使用棋面特征,AlphaGo
Master还使用了手动设计的特征;AlphaGo Zero完全从随机行为开始,不断自我对弈进行学习;AlphaGo
Master需要使用人类数据。
这里的疑问在于,Master中人类数据是什么时候进行学习的?有两种可能。
1)AlphaGo Master直接使用人类数据进行强化学习,也就是说训练过程不需要蒙特卡罗搜索来产生数据;
2)AlphaGo Master只在最开始使用人类数据进行监督学习,得到网络初始权重。接着后面再使用和
AlphaGo Zero一致的强化学习,包括使用蒙特卡罗搜索产生对弈数据进一步学习。
答:论文中方法论一节可以看出是2)中猜想,只在网络初始化时使用。
2. Raw Network直接用AlphaGo Zero训练出来的二合一网络走子,不做MTCS搜索。这个版本相当于人类棋
手下"多面打指导棋",仅凭棋感,也就是只考虑当前棋面局势,不做计算时的行棋策略 (
或者相当于老年职业棋手完全丧失计算力时的下棋方式)。AlphaGo Raw Network棋力大约为3055。
总结
AlphaGo Zero完整训练和对弈流程
-
随机初始化残差神经网络 ,从空白棋盘开始第一轮对弈。 -
对于 , 记前一轮得到的神经网络为 。( 时,也就是使用初始化网络 ) -
「a)」 在时间步$t<t$前,执行蒙特卡罗搜索,决定当前棋面$s_t$下,下一步怎么走。模拟搜索过程中,使用$f_{\theta_{i-1}}$指导蒙特卡罗模拟四阶段(select、expand、evaluate、play),模拟1600次后,根据访问次数得到下一步动作的概率分布$\pi_t$,再根据该分布抽样得到下一步实际的下法。该步可以看做是强化学习算法Policy Iteration的 「Policy Improvement」操作。</t$前,执行蒙特卡罗搜索,决定当前棋面$s_t$下,下一步怎么走。模拟搜索过程中,使用$f_{\theta_{i-1}}$指导蒙特卡罗模拟四阶段(select、expand、evaluate、play),模拟1600次后,根据访问次数得到下一步动作的概率分布$\pi_t$,再根据该分布抽样得到下一步实际的下法。该步可以看做是强化学习算法 -
「b)」 重复 「a)「过程不断进行该局自我对弈,直到时间步 决出胜负,得到报酬 。最终的获胜者可以看做是强化学习算法」Policy Iteration」的 「Policy Evaluation」操作。 -
「c)」 构造该局对弈训练数据。将延迟报酬 赋值给$t<t$时的报酬$z_t$。其中$z_t=±r_t$, $±$符号根据当前棋面对应的下棋方是黑方还是白方确定。得到许多训练数据$(s_t,="" \pi_t,="" z_t)$。<="" section=""> -
「d)」 优化。使用正态分布抽样训练数据,得到实际进行训练的数据集 。喂给神经网络,根据损失函数 ,使用随机梯度下降法+反向传播算法更新网络的参数,得到新的神经网络 。 -
不断执行 「2」中的迭代过程,一直持续40天,得到最终版的 「AlphaGo Zero」。 -
在线对弈。实际比赛时,对于当前棋面,执行上述2中a)步骤的蒙特卡罗搜索,根据访问次数得到下一步动作的概率分布 ,再根据该分布抽样得到下一步实际的下法。
下面部分的总结主要参考知乎“高德纳“的回答。
AlphaGo的版本演变
-
「AlphaGo Fan」: 就是Nature2016论文描述的版本,5:0胜欧洲围棋冠军樊麾。国内腾讯的绝艺等围棋AI都是基于 AlphaGo Fan 架构。
-
「AlphaGo Lee」: 这个4:1胜李世石的版本相较 AlphaGo Fan 等级分大约提高了600 分。和 AlphaGo Fan相比,改进有以下几点:
-
a) 训练数据来自AlphaGo自我对弈(意味着同时使用Policy Network和Value Network,不知道这里是否有使用蒙特卡罗搜索,类似AlphaGo在线对弈过程), AlphaGo Fan自我对弈时走子只用 Policy Network。
First, the value network was trained from the outcomes of fast games of
self-play by AlphaGo, rather than games of self-play by the policy network. -
b) Policy network 和 Value Network规模更大了,同时网络训练由分布式GPU升级为分布式TPU.
-
「AlphaGo Master」: 这个版本相较 AlphaGo Lee 等级分提升了大约 1100 分。年初网上快棋60:0赢了中日韩顶尖职业棋手,Master微调版今年5月3:0 胜柯洁。AlphaGo Master 和 AlphaGo Lee 相比, 主要改动有:
-
「AlphaGo Zero」: 这个版本相较 AlphaGo Master 等级分又提升了大约 330 分。330 分相当于柯洁和胡耀宇间的差距。AlphaGo Zero和AlphaGo Master相比,主要改动有两处:
-
「AlphaGo Zero Raw Network」: 除了上述版本外, DeepMind 还实验了一个 Raw Network 版本,也就是直接用 AlphaGo Zero训练出来的二合一网络走子,不做 MTCS 搜索。这个版本相当于人类棋手下"多面打指导棋",仅凭棋感,不做计算时的行棋策略 (或者相当于老年职业棋手完全丧失计算力时的下棋方式)。AlphaGo Raw Network 棋力大约为 3055。作为参考,女职业棋手范蔚菁的等级分正好是3055。
a) 合并了 Policy Network 和 Value Network;
b) 用 ResNet 替换了 CovNet;
c) 强化学习训练算法从Policy Gradient 改为 Policy Iteration.
棋力增强的原因
作者在本文中经常拿AlphaGo Zero和 AlphaGo Lee做对比,一个最形象的例子是 AlphaGo Zero训练72小时后,以100:0打败AlphaGo Lee (注意:此时的 AlphaGo Zero棋力远低于AlphaGo Master,AlphaGo Zero需要训练大约30天才能超越 AlphaGo Master)。具体的说,棋力增强主要来源有以下四点:
-
「a) 使用ResNet替换原来的ConvNet」。根据论文 Figure 4.a 使用 ResNet 带来了大约 600 分的提高。ResNet使得网络深度更深,因此有更强的特征学习能力。 -
「b) 合并Policy Network、 Value network」。根据论文 Figure 4.a 这个改动也带来了大约 600分的提高。作者认为合并的优化目标使得网络更加规范化,能够学习到一个共同的表示来支持多种场景(既可以用来预测下一步动作概率分布,也可以用于预测最终获胜者)。 -
「c) Reinforcement Learning训练算法的改进」 (Policy Gradient -> Policy Iteration)。这里面很重要的一点就是将蒙特卡罗搜索树纳入Policy Iteration训练过程,将蒙特卡罗搜索模拟过程当做是Policy Iteration算法中的Policy Improvement操作;将自我对弈最后的胜负作为Policy Iteration算法中的Policy Evaluation操作。AlphaGo中采用的是Policy Gradient,直接学习到策略分布,因此自我对弈过程实际上只使用前一轮的策略网络进行走棋。作者在论文并没有量化这一改动的影响。但个人认为这里的改动很可能导致的在不动用大量计算资源的情况下更稳定的收敛速度和更好的克服遗忘性能。 -
「d) 取消人类棋谱知识和人工特征」。网络初始阶段不使用人类棋谱进行监督学习,而是直接从随机的行为开始学习;也不使用人工特征,而只使用棋面黑白棋特征。论文暗示(但没有提供详细证据) 等级分为 4858 AlphaGo Master 已经达到了训练瓶颈(Figure 6 中用一条直线表示),而删除基于人类棋谱的监督学习过程和删除人工特征得以使 AlphaGo Zero的训练上限更高。可以在训练30天后超越 AlphaGo Master, 在训练40天后超越 AlphaGo Master 300分。
展望
AlphaGo Zero中的改进值得我们思考,最振奋人心的就是排除了人类棋谱数据和人工特征,完全从强化学习自我对弈过程中进行学习。这其中有两点感悟。
-
深度学习确实能够很有效地进行特征学习; -
强化学习确实能够很有效地进行启发式搜索中评分函数的学习。
引用周志华的一段话,“如果说深度学习能在模式识别应用中取代人工设计特征,那么这里显示出强化学习能在启发式搜索中取代人工设计评分函数。这个意义重大。启发式搜索这个人工智能传统领域可能因此巨变,或许不亚于模式识别计算机视觉领域因深度学习而产生的巨变。机器学习进一步蚕食其他人工智能技术领域。”
可以看出这里面的核心包括深度学习、强化学习、启发式搜索。本文分别对这三个方面都有所改进,深度学习体现在ResNet的使用以及合并两个神经网络;强化学习体现在Policy Iteration算法的使用,启发式搜索体现在引入Policy Iteration训练过程以及改进蒙特模拟过程(Expansion、Evaluation合并、最终动作决策由选择访问次数最多的动作改成根据访问次数计算动作分布,再随机抽样动作)。这里面的核心中的核心仍然是蒙特卡罗搜索,深度学习和强化学习都是为蒙特卡罗搜索服务的。
可能可以改进的几个核心要素包括单一的改进以及多种元素的结合方式改进。例如强化学习算法中最终报酬函数 的设计、深度学习中是否有更好的网络架构,如SENet等、蒙特卡罗搜索树除了用在强化学习算法中,能否用在深度学习算法中,指导误差的反向传播等;蒙特卡罗模拟结束后,是否有其他更好方式来计算动作概率分布。当然另一方面,有没有新的领域能够替代蒙特卡罗搜索树的核心地位,具有前瞻性的问题是否只有通过大量模拟才能得到反馈,是否还有其他的方式能够更好的进行反馈。
AlphaZero 与 AlphaGo Zero 之间的具体区别有以下几个:
1. AlphaGo Zero 会预计胜率,然后优化胜率,其中只考虑胜、负两种结果;AlphaZero
会估计比赛结果,然后优化达到预计的结果的概率,其中包含了平局甚至别的一些可能的结果。
2.由于围棋规则是具有旋转和镜像不变性的,所以专为围棋设计的AlphaGo Zero和通用的AlphaZero
就有不同的实现方法。AlphaGo Zero 训练中会为每个棋局做 8 个对称的增强数据;并且在蒙特卡洛树
搜索中,棋局会先经过随机的旋转或者镜像变换之后再交给神经网络评估,这样蒙特卡洛评估就可以在不同
的偏向之间得到平均。国际象棋和日本象棋都是不对称的,以上基于对称性的方法就不能用了。
所以AlphaZero并不增强训练数据,也不会在蒙特卡洛树搜索中变换棋局。
3.在AlphaGo Zero中,自我对局的棋局是由所有之前的迭代过程中出现的表现最好的一个版本生成的。
在每一次训练迭代之后,新版本棋手的表现都要跟原先的表现最好的版本做对比;如果新的版本能以超过
55%的胜率赢过原先版本,那么这个新的版本就会成为新的「表现最好的版本」,然后用它生成新的棋局
供后续的迭代优化使用。相比之下,AlphaZero始终都只有一个持续优化的神经网络,自我对局的棋局
也就是由具有最新参数的网络生成的,不再像原来那样等待出现一个「表现最好的版本」之后再评估和迭代。
这实际上增大了训练出一个不好的结果的风险。
4.AlphaGo Zero中搜索部分的超参数是通过贝叶斯优化得到的。AlphaZero 中直接对所有的棋类使用了
同一套超参数,不再对每种不同的棋做单独的调节。唯一的例外在于训练中加在先前版本策略上的噪声的大小,
这是为了保证网络有足够的探索能力;噪声的大小根据每种棋类的典型可行动作数目做了成比例的缩放。
参考
Mastering the game of Go without human knowledge
知乎:如何评价AlphaGo Zero?
AlphaZero实战
「阿尔法狗」再进化!
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



