Julia加入TPU,这是一个靠自己也要融入机器学习的编程语言
选自arxiv
作者:Keno Fischer, Elliot Saba
机器之心编辑部
Julia 语言发展非常迅速,它可以视为同时具备了 Python 的灵活性与 C 的速度,但目前 TensorFlow 和 PyTorch 等框架官方都不支持 Julia 语言。因此近日有研究者借助 XLA 底层编译器为 Julia 构建 TPU 支持,他们表示该方法能够将 Julia 程序编写的 VGG19 模型融合到 TPU 可执行文件中,并调用 TPU 实现高效计算。而 Google.ai 的负责人 Jeff Dean 在推特上也表示「Julia + TPUs = fast and easily expressible ML computations!」
1. 引言
过去的几年里推动机器学习技术稳步发展的根本性改变之一是训练和优化机器学习模型的巨大计算力。许多技术都是很年前就已经提出,唯有近几年提升的计算力可以为现实世界的问题提供足够优质的解决方案。这些计算能力的很大一部分是通过 GPU 获取的,其针对向量的计算能力最初是为图形而设计的,但机器学习模型通常需要执行复杂的矩阵运算,因此 GPU 同样表现出了非常好的性能。
这些方法及 GPU 在现实世界,尤其是在机器学习领域的成功引发了硬件设计者的一系列创新,他们致力于为机器学习工作负载研发新的加速器。然而,尽管 GPU 很长一段时间都在 CUDA 等软件系统发力,但这些库通常不会扩展到新的非 GPU 加速器,为这些加速器开发软件仍然是一大挑战。
2017 年,谷歌宣布他们将通过云服务向大众提供他们专有的 TPU 机器学习加速器。最初,TPU 的使用局限于根据谷歌 TensorFlow 机器学习框架编写的应用。幸运的是,2018 年 9 月,谷歌通过底层 XLA(Accelerated Linear Algebra)编译器的 IR 开放了 TPU 的访问权限。这个 IR 是一个通用的优化编译器,用于表达线性代数基元的任意计算,因此为使用 TPU 的非 TensorFlow 用户以及非机器学习工作负载提供了良好的基础。
在本文中,我们介绍了使用这个接口编译通用 Julia 代码的初步工作,它们可以进一步访问谷歌云的 TPU。这一方法与 TensorFlow(Abadi et al., 2016)采用的方法形成对比,后者没有编译 python 代码,而是先用 Python 构建一个计算图,然后再对这个计算图进行编译。它在美学上类似于 JAX(Frostig et al., 2018),JAX 的目标是通过跟踪和 Offload 高级数组运算来 Offload Python 本身编写的计算。然而重要的是,我们不依赖于追踪,而是利用 Julia 的静态分析和编译能力来编译整个程序,包括传递到设备端的所有控制流。
值得一提的是,我们的方法允许用户在编写模型时充分利用 Julia 语言的表现力。这些表现力主要体现在一些高级特征上,如多重派发、高阶函数和现有库,如微分方程求解器(Rackauckas & Nie,2017)和通用线性代数例程等。由于只在纯 Julia 代码上运行,所以它也与 Zygote.jl(Innes, 2018)自动微分工具兼容,该工具能执行自动微分作为高级编译过程。总的来说,我们能够编译使用 Flux 机器学习框架编写的完整机器学习模型,将模型的前向、反向传播及训练回路融合成一个可执行文件,并 Offload 到 TPU 中。
论文:Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs

论文链接:https://arxiv.org/abs/1810.09868
摘要:谷歌的云 TPU 是一种前景广阔的新型机器学习工作负载硬件架构,近年来已经成就了谷歌很多里程碑式的机器学习突破。如今,谷歌已经在其云平台上为大众提供 TPU,最近又进一步开放,允许非 TensorFlow 前端使用。我们描述了一种通过这一新 API 及谷歌 XLA 编译器将 Julia 程序的适当部分 Offload 到 TPU 的方法和实现。我们的方法能够将 Julia 程序编写的 VGG19 模型及其正向传播完全融合到单个 TPU 可执行文件中,以便 Offload 到设备上。我们的方法与 Julia 代码上现有的基于编译器的自动微分技术很好地结合在一起,因此也能够自动获得 VGG19 反向传播并采用类似的方法将其 Offload 到 TPU。使用我们的编译器访问 TPU,我们能够在 0.23 秒内完成批量为 100 张图像的 VGG19 前向传播,而 CPU 上的原始模型则需要 52.4s。我们的实现仅需不到 1000 行的 Julia 代码,无需根据 TPU 对核心 Julia 编译器或任何其他 Julia 包进行特有的更改。
5. 将 Julia 语义映射到 XLA
只要 Julia 程序是按照 XLA 基元来编写的,我们就能将其编译到 XLA。然而,Julia 程序不是根据晦涩难懂的 HLO 操作来编写的,而是根据由 Julia 基本库提供的函数和抽象来编写的。幸运的是,Julia 使用了多重派发,使得根据 HLO 操作来表达标准库的抽象变得容易。下面展示了几个简单的例子:

除了这些简单的操作以外,我们还提供了高级数组抽象的实现,尤其是 mapreduce 和 broadcast。依据 HLO 操作实现的 broadcast 大约有 20 行代码,为节省空间起见,此处不予展开,但「mapreduce」的实现非常简单:

从上图可以看到将任意 Julia 函数作为静态计算运算的效果。由于 Julia 对泛型抽象的依赖,它只需指定极少数定义,就能覆盖大量 API。具体来说,从 mapreduce 的定义中,我们可以自动得到在 base 中所定义运算(如 sum 和 prod)的降维。事实上,获取足够的 API 覆盖来编译 VGG19 模型的前向传播和反向传播需要不到 200 行定义。
5.1 结构映射
我们做了一个额外的识别。embedded IR 中的任意元组或 immutable 结构被映射至一个 XLA 元组,即 julia 值 1 + 2im(由两个整数结构组成的复杂数字)将被映射至 XLA 元组 (s64[], s64[])。我们在 XLA IR 的 Julia 嵌入中保存该结构类型,但很显然 XLA 不了解 julia 类型,因此在最终的转换步骤中这些类型被转换成适当的元组。类似地,(julia)元组构造函数(以及 immutable 结构的构造函数)变成了 XLA 的元组构件。元组引用(immutable 结构的字段引用)变成了 XLA 的元组引用。
5.2 处理控制流
有一个额外的复杂问题我们还没讨论:Julia 提供的命令式控制流和 XLA 提供的函数式控制流之间的语义不匹配。为了解决 if/else 控制流模块,我们在 Julia 编译器的 SSA IR 中查看 φ 节点,然后将这些节点作为 XLA 函数式控制流的结果(如果在同一个合并点存在多个 φ 节点,则我们构造这些节点的元组)。导致计算流分化的条件变成了函数式控制流的条件,二者之间的任意计算都可作为函数调用。循环控制流类似条件控制流的构建,我们识别控制流图的强连接区域,将其作为循环的主体。
7 结果
7.2 VGG19 前向传播
我们的第一个复杂示例是完整 VGG19 前向传播。我们使用 Metalhead 包中的 VGG19 实现 (Mike Innes & Contributors, 2018),它利用 Flux (Innes & Contributors, 2017) 框架将熟悉的机器学习层(卷积层、全连接层)转换成线性代数运算。但重要的是,Flux 框架中的每个层只是一般的函数,它们可以反过来调用一般的线性代数运算。因此,Flux 中表达的机器学习模型(包括 VGG19)只是一般的 Julia 函数,因此能够使用本论文介绍的方法。
我们的编译器能够完全推断、offload 和融合(fuse)VGG19 的全部前向传播。在 Julia 级别的优化之后,顶层函数的最终 IR 包括 181 个指令(每个 HloOp 都是具备适当推断的常数静态参数和适当形态推断的动态参数)。每个级别计算的 HLO operands 总数是 183(多出的两个用于嵌入中隐藏的参数指令),29 个计算一共有 361 个 HLO operands,指令数详情见图 3。由于我们能够 offload 全部前向传播计算,因此 Julia 不参与任何评估步骤,从而可以同步执行其他任务(如为下一批准备数据)。此外,得到代码的性能仅受限于 XLA 生成的代码质量,不受限于前端(性能评估见 7.4)。我们在 ImageNet 验证集上评估了 VGG19 模型,并验证了得到结果与原版 Metalhead 的结果相匹配,从而验证了生成的 XLA 代码准确性。
7.3 VGG19 反向传播
为了获取反向传播,我们利用基于 Zygote.jl 编译器的 AD 框架 (Innes, 2018)。Zygote 在 Julia 代码上运行,其输出也是 Julia 函数(适合重新导入 Zygote 以获取更高阶的导数,也适合编译成针对 TPU 的模型)。如下是一个具体示例:
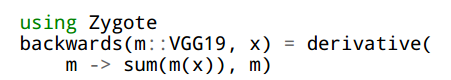
即模型当前值和特定训练样本(或者训练样本批)所对应的导数。我们使用 sum 作为损失函数的简单替代。意外的是,第 6 章介绍的类型推断修改也能够提高所有 VGG19 反向传播的类型推断精度。至于前向传播,优化和未优化的指令总数如图 1 所示。反向传播生成的 XLA 指令明显多于前向传播,其最大贡献者之一便是 Zygote 的混合模式广播融合(mixed mode broadcast fusion)——在一个映射内核(map kernel)中同时计算前向传播和反向传播。由于 XLA 目前不支持来自一个映射指令的多个输出,该函数在多个映射指令上重复运行,因此后续需要清洗 XLA 的 DCE。一般,我们的编译过程解决了 XLA 对映射指令的处理,因为在泛型代码中调用 Julia 映射和 broadcast 函数非常普遍。
7.4 在 TPU 上进行评估
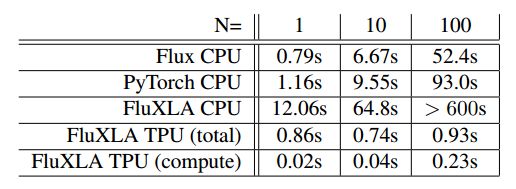
图 2:不同批大小对应的 VGG19 前向传播时长。Flux CPU 是 Flux master/Julia master,但不使用 XLA 编译器。PyTorch CPU 是同一 CPU 上的相同 PyTorch 模型。FluXLA CPU 是我们的研究在 CPU 上的 xrt 实现;FluXLA TPU (total) 是端到端时间,和客户端报告的时间一致(包括 kernel launch 开销和从谷歌云把数据迁移回来,注意由于额外的网络迁移,该测量结果会出现极大的变动);FluXLA TPU (compute) 是 TPU 上的总计算时间,和云分析器报告的时间一致(与 FluXLA TPU (total) 不同,该测量很稳定)。所有 CPU 测量基于支持 AVX512 的 Intel(R) Xeon(R) Silver 4114 CPU @ 2.20GHz CPU。可获取高达 20 个内核,且 CPU 基准不限于单个内核(即使在实践中,也不是所有 CPU 基准都使用并行化)。TPU 基准仅限单个 TPU 内核。所有时间至少经过 4 次运行(除了 FluXLA CPU for N=100,因为它无法在 10 分钟内完成一次运行)。
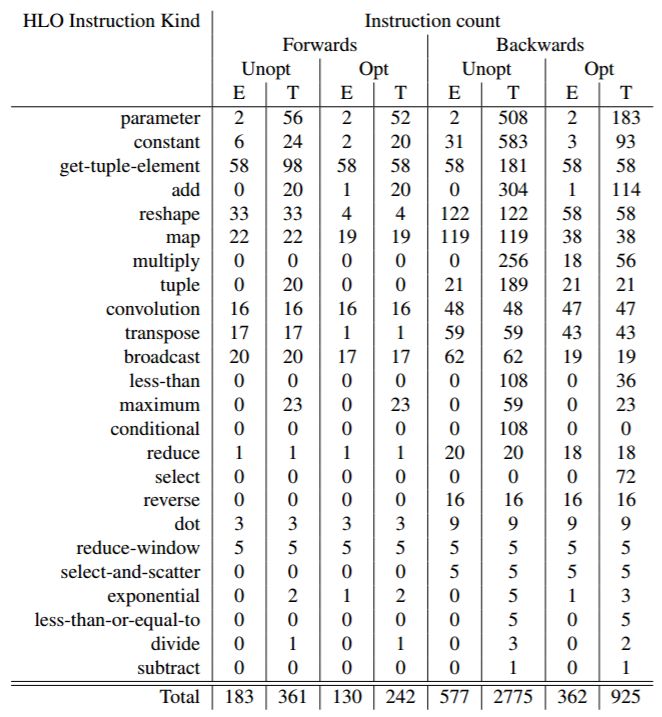
图 3:被编译为 XLA 后,Metalhead.jl VGG19 前向传播和反向传播的指令数分解,上图展示了未优化(Julia 前端之后)和优化指令数(XLA 优化流程之后,与 CPU 后端所用流程类似,但没有 HLO fusion)。每个指令数被进一步拆分为实体计算中的指令(E)和所有计算中的指令数(T)。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



