文章作者 :辰火、讷朴、达卿
内容来源:公众号“阿里云开发者”
导读: AliEx
press 搜索重排项目在去年
6 月份时全量发布了第一个 fined tuned
的 DNN 版重排模型,本次的工作作为上一版本的升级,在日常、大促时的表现
均
有显著优势。
本文将
深入浅出强化学习框架重排实践,并引出几个潜在的提升空间。
01 商品排序中的重排
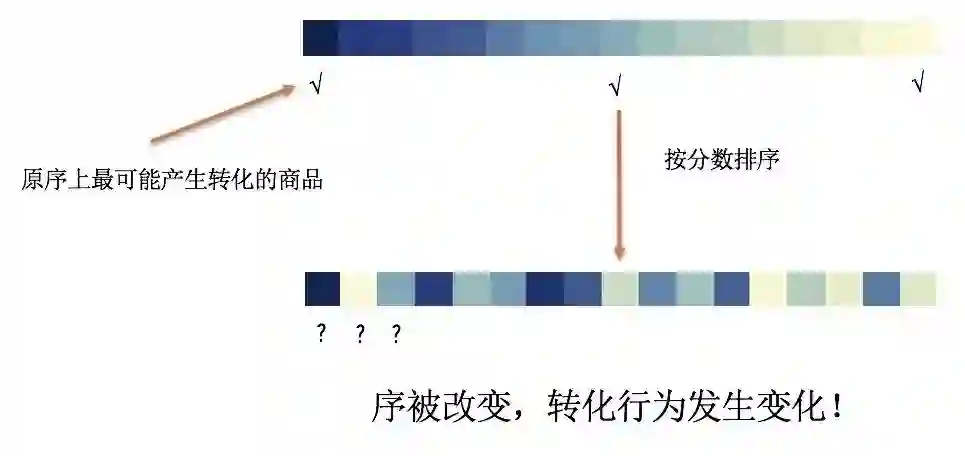
商品排序的目的,很大一部分是为了让高效的商品获得更好的展示机会,匹配用户的需求。一种主流的思路是,商品对于用户的某次请求来说,是有好坏之分的。而从展示的位置的角度来看,越靠前的商品越能够获得曝光机会上的优势。于是,通过模型对商品打分的思路自然而然的浮现了出来,且似乎只要模型对商品的打分足够准确,AUC 足够高,之后就可以按照这个打分从高到低对商品进行排序!在这套经典的框架中,有一个严重的缺陷,这也是绝大多数重排工作都期望解决的:商品的上下文对结果会产生影响。考虑重排之前的模型,由于候选商品集合太大,想要将上下文信息喂进模型十分困难。所以,用重排来解决上下文影响是一个普遍的思路,我们可以看到几乎所有的重排模型都会在对商品打分时考虑上下文。但实际上,对商品进行打分判断是否会产生转化是一个任务,对候选商品进行排序最大化收益又是另外一个任务,这两个任务虽有联系,但却截然不同。如果我们单纯按打分来排序,那么原序将会被打乱,而我们无法从原序 label 还原出新序 label,于是无法断定新序的表现如何。除非我们认定商品的转化行为不会因为上下文发生改变,这显然是存在问题的。
1. 无视上下文,模型对商品的打分足够准确吗?
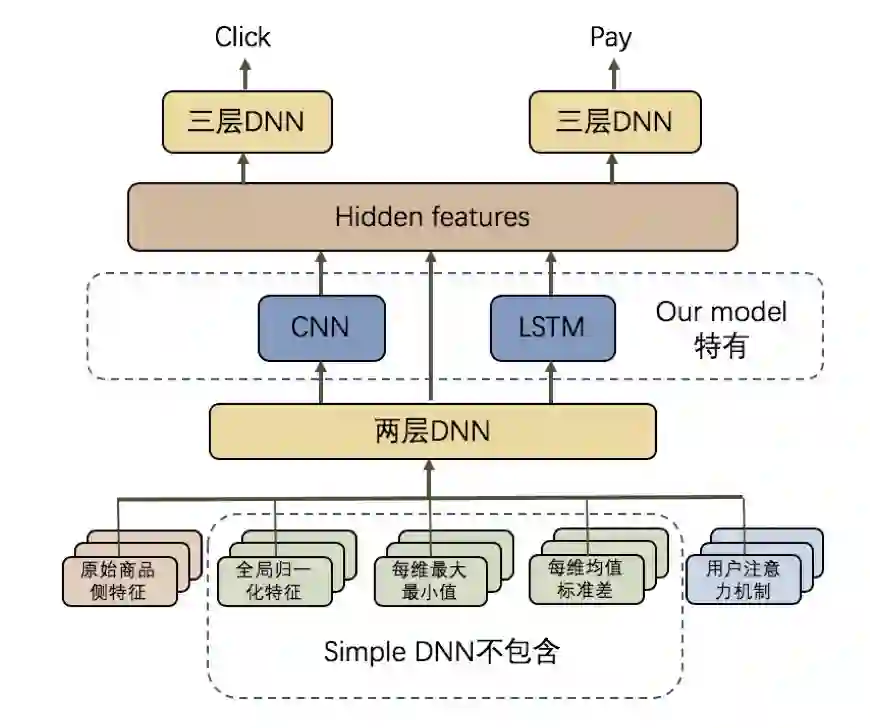
我们设计了三个模型进行实验,来展示模型上下文信息刻画程度对打分结果的影响。第一个模型是目前最为常用的 pointwise 打分模型,模型输入为商品的特征和用户的信息,我们简称它为 Simple DNN。第二个是在重排阶段表现稳定良好的线上重排模型 AE rerank,它在 Simple DNN 的基础上,添加了上下文商品的全局统计信息,例如某些特征分的方差、均值、极值等等。第三个模型是我们为了进一步刻画上下文信息而设计的,在 AE rerank 的基础上额外加入了 CNN 和 RNN 模块来捕捉商品序列的信息。模型结构如下图所示:( Simple DNN 不包含蓝色的 CNN、RNN 以及绿色的全局统计特征输入,AE rerank 不包含蓝色的 CNN、RNN)。
评估模型结构图
我们使用了 5400 万条日常数据作为训练集,将上述三个模型分别训练了 5 个epoches(都已收敛)。接着我们计算了它们在测试集(约 250 万条数据)的表现结果,如下表所示。此处的 AEFS 是精排阶段产生的精排总分的 alias name。表中的数据回答了我们的问题, pointwise 模型 Simple DNN 对商品进行的打分对比带有上下文信息的AE rerank和新模型来说略逊一筹。由此我们能够得出结论,商品打分应当会受到它所处的上下文环境的影响,将上下文信息整合才能预估得更加准确。
各评估模型表现(序列内判断能力)
2. 无视序的改变,按照原序上的打分排序足够靠谱吗?
首先,我们假定模型输出均在拟合考虑上下文的前提下当前商品被购买的概率
p(i|L) ,且定义排序结果L的好坏为其能够产生的期望购买数
,即 p (i |L)
之和:
该公式对于完整考虑上下文的新模型来说是适用的。但是对于前两种模型 Simple DNN 和 AE rerank 来说,即使将商品随机打乱,它们对于每个商品的打分或者说是预估的概率 p (i |L)
是不变的,因此直接相加来作为商品序列的打分一定是失准的。大致地,我们以类似 DCG 的方式,每个商品的预估概率乘以位置折扣的和作为排序结果打分,就能够自然地避免上述情况发生,如下所示:
我们通过实验测试了该方法判断 PV 的好坏对于 Simple DNN 和 AE rerank 来说是否有效。实验分为分别对点击转化和成交转换进行了测试,在理想情况下,好的模型应当能够更准确地判断两个排序中,哪一个更可能产生点击行为,或是哪一个更可能产生成交行为。排除了 label 相同的排序对之后,结果如下表所示:
各评估模型表现(序列整体判断能力)
从上面的测试数据中可以看出,所有的模型都能大致区分出序列的好坏。从
的定义来看,直接按照商品的打分从高到低进行排序,确实是在评估下最好的序列。然而,这样产生的排序结果是否真的有效,在评估能力最强的新模型视角来看,结论是否一致?于是,我们把这些新生成的“最好的”序列以及数据的原始序列一起送到新模型进行评估,如下表所示。每个值表示新生成序列中有多少比例是比原始序列要更好的。
按模型打分排序表现
新模型认为直接按照打分高低排序的策略,最高也只有 66% 左右的比例能够比原序列更好,对于直接按照精排总分 AEFS 排序更是比原序列差得多(这是因为离线数据中的大部分原序列都是经过 AE rerank 模型生成的)。通过这个结果我们认定,直接按照商品打分的高低来排序很可能并不是最优的方法。
那么,不能直接通过打分排序,我们又该如何去寻找最优的序列呢?最直接的办法是通过枚举所有可能的序列结果,让新模型对它们逐个进行打分,再把最好的排序挑选出来作为最终结果。但由于线上算力远远不足以让我们暴力枚举,所以我们需要对枚举的集合进行优化。启发式贪心搜索 beam search 可以作为一种解决方案,在探索过程中裁剪掉较大部分无用状态。该方法需要在精度和速度之间有一个权衡,通常在保证一定精度的条件下,很难达到令人满意的速度。在我们的工作中,我们希望能够用更直接了当的方式,一步到位地生成序列。
02 商品序列生成器
商品序列生成器是一个生成序列的模型,它的输入是 M
个候选商品,输出为带顺序的
N(N﹤M) 个商品。使用 pointer network 是一个自然的想法,它需要迭代 N
步,在每一步中根据当前状态,挑选一个商品,最终得到了 N
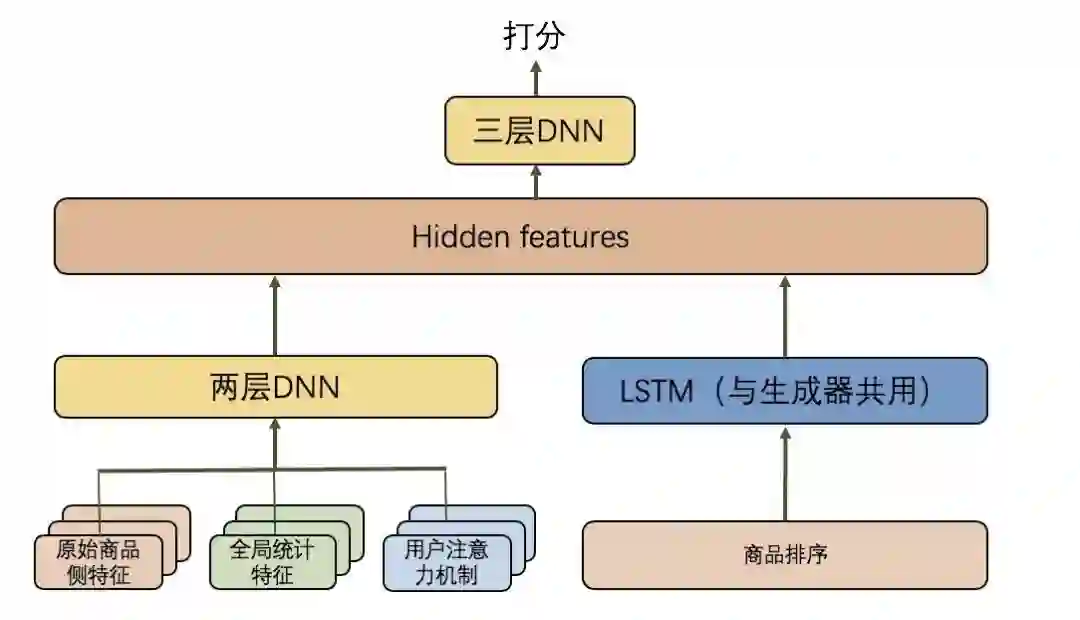
个商品的排序。我们在 pointer network 的基础上设计了网络结构,最终设计的模型如下所示:
生成模型结构图
具体地,令
为商品 i
的特征,商品候选集为
。之后,候选集将会进入两路图中,一路是经过两层的 DNN 得到抽象的特征集
;另外一路是利用 LSTM 来记住之前挑选过哪些商品,每一步的输入就是前一步挑选的商品
再拼接上用户的 embedding 信息 U
(在第 0
步时,直接用全 0
向量来代替
)。因此,在每一步中,LSTM 的输入是
,输出是当前的隐状态
。知道当前的状态就可以用来计算选择每一个商品的概率。把这个隐状态复制 m
遍分别与上述的抽象特征集
拼接,接着共同过一个三层的 DNN 再把选过的商品 mask 掉,再通过一个 softmax 即可以得到在这一步选择每一个候选商品的概率。
这样设计的模型有两个方面的好处。第一个是它不需要具体限定 M
和 N
的值,模型的参数与 M,N
的值无关,当模型训练或预测时都可以根据需要随意设置 M
和 N
的值。第二点是经过我们改造后,原来具有两个 LSTM 的 pointer network 结构变成了现在的一个,其余全部用 DNN 来代替,不仅实现简单,预测所需时间也减少了一半(线上的 cpu 环境运行 LSTM 较慢 )。
有了生成模型之后,我们希望它可以生成能让新模型打分非常好的排序,如此就能够有大概率比传统的方式做得更好。传统的方法可以通过原序 label 来监督学习,但由于改变排序有可能会改变 label,通过监督学习方法来做完成这个任务是不够完美的。一个替代方法是我们可以通过随机的方式抽样一些候选序列,然后由新模型打分来选出最好的序列作为监督学习的目标;也可以通过生成一些备选序列之后取出评估模型认为最好的序列作为结果。在我们的工作中,我们使用了强化学习的方式联系起生成和评估两个环节。
03 强化学习之路 1. 算法设计
在本节中,将上文中生成排列的模型称为生成器,评估排列的模型称为评估器,回顾评估器的计算方式:
因为评估器在对序列的期望成交行为数进行预估,如果我们把这个结果看作强化学习中的奖励,似乎就自然地将生成器和评估器串联起来了!在生成器训练的过程中,每一次选择商品都可以得到评估器发出的奖励信号,最终只需要将整条轨迹得到的总奖励最大化即可。
然而,这里还存在一个问题,p (i |L)
是利用上下文的信息计算出来的,但每一步选择商品的时候我们并不知道后面的商品是如何排序的。因此,我们需要对 p (i |L)
进行简化修改,让它只依赖于 i
之前已选出的商品,与后面的排序结果无关。换句话说,即为假设用户是从上往下浏览商品的,他对当前商品的购买概率只取决于前面浏览过的商品序列而与后面商品的排列无关。具体在之前评估器的修改就是将 CNN 模块去掉。
将评估器模型简化后,要做强化学习的几大要素都已经具备了。商品生成器就是一个待训练的agent,它会根据当前的状态,做出它认为好的动作,然后收到评估器给予的奖励,接着它会转移到下一个状态,继续做动作拿奖励。这样可以得到 N
个
三元组,具体的定义如下:
每一步的状态
:之前已经排好的商品序列和剩余候选的商品集合
每一步的动作
:候选集中剩余的某一个商品,为选哪个商品的离散动作
每一步的奖励
:在考虑上文的前提下,评估器预测的
被购买的概率
轨迹长度为 N ,衰减系数γ=1
我们主要是考虑用 policy-based 类的方法来对上述生成器模型进行优化。没有使用 value-based 方法的原因,是我们在实验中发现,在这个问题下要准确的预估出 V 值或者 Q 值可能是一件困难的事情。
请注意,强化学习要让总回报最大,也是让每一步的总回报最大,而每一步的总回报是从当前商品一直到最后的第 N 个商品所得到的奖励之和,它被称为 Q
值,定义如下:
那么我们从最基本的算法开始, reinforce 算法,损失函数为 :
这个较为简洁的模型实验的结果并不理想,我们很容易发现其中的一点:如果一些优质的候选,模型在其中无论怎么行动总回报都很高,另外还有一些劣质的候选集,无论怎么行动总回报都很低,那么模型就很难找到有用的信息进行优化。因此,我们可以考虑对 reward 进行修改,比如减掉候选集的均值,甚至再减去均值的变化量除以均值(变化率),以达到能够判断行动好坏的目的。
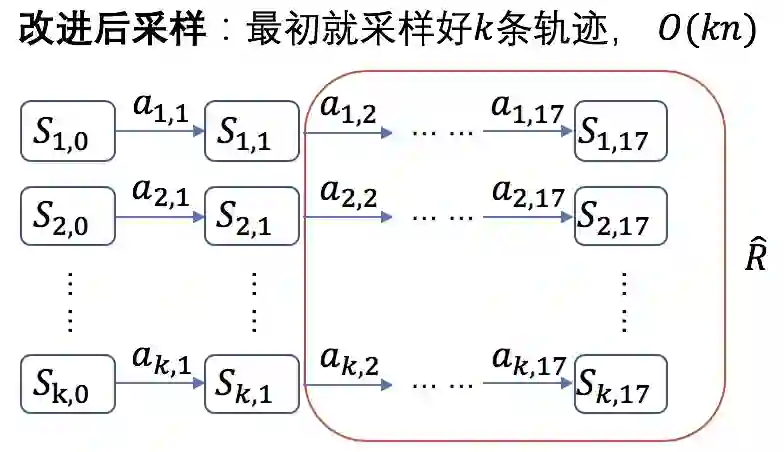
均值的计算,一种方法是可以直接使用原序列在评估器中的打分。这里再补充解释一下我们的训练数据。比如在实验中,我们主要关注的是 30 排 17,那么我们就把线上对每个 query 真实展示的前 30 个商品捞回来作为我们训练数据的候选集,生成器就从这 30 个中选出 17 个商品。我们可以知道这 30 个候选商品的前 17 个商品就是线上真实展现的序列。因此,原序列可以拿到在评估器中的打分
,它和上述的
维度相同,都表达的是每一步的总回报或者说是 Q 值。因此,我们上述的 reinforce 算法的损失函数就可以改造为:
简称 reinforce_2 算法。当然上述算法还可以继续加以改造:
简称为 reinforce_3 算法(上述的除法可能会发生除 0 异常,全部 clip 在 -10 到 10 之中)。
对强化学习比较了解的读者可能会产生一个想法,就是均值可以通过 actor-critic 的方法来估计。这就是即将要说的第二种估计均值的方法,本文我们使用了性能强大的 PPO 算法,这样就可以用 critic 来估计 V
值,也能算出优势函数的 A
值来更新策略。然而这里隐藏了一个大问题:如何设计网络来估计 V
值?
V 值是从当前的状态开始,使用当前的策略,平均能拿到多少总奖励的数值。当前的状态是当前排好的商品和剩余候选的商品,我们需要在保持之前模型的优良性质(即候选商品集的数量是可变的)的同时,预测出准确的 V
值。因此,我们采用与之前模型结构类似的设计,即对剩余候选的商品打分,然后把分数都加起来,模型结构如下所示:
V 值估计模型图
该算法的效果和 reinforce_3 算法相差不多。我们认为 ppo 算法表现不佳,是由于 V
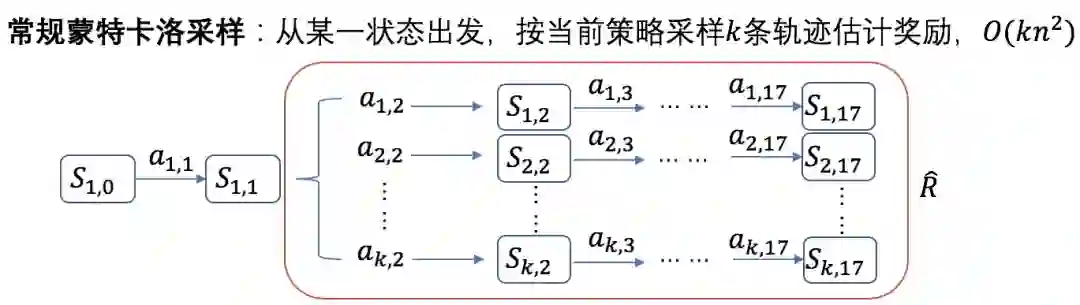
值较难估计,所以能不能保留 ppo 中的 actor 更新方式,而把 critic 模块进行改变?这里就要说到估计均值的第三种方法,蒙特卡洛采样。为了实现方便和高效,我们也对原始的蒙特卡洛采样做了一些改进。
V 值采样图示
对于每一份数据或者说是每一组候选商品集,我们都让模型就根据它当前自身的参数采样生成多个排列,那么这些排列在评估器中得到的总奖励的均值就可以近似认为是当前策略下的 V
值了,我们将之称为 PPO_MC 算法,损失函数定义如下 (
的维度是
,如果 std(R) = 0,则将其置为 1 ):
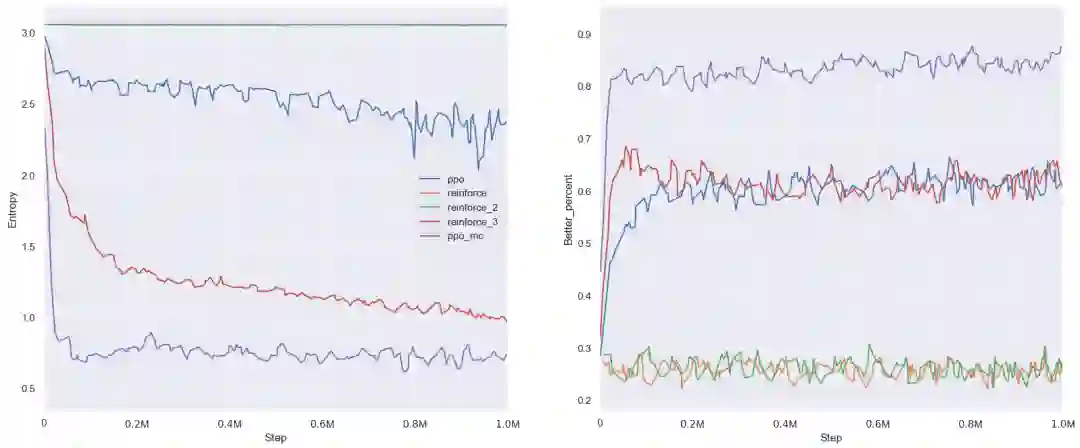
至此,我们一共提到了 5 种强化学习算法,从 reinforce 算法一直 PPO 算法及其改进版本,它们的训练效果如下图所示。为了增加算法的探索能力,这 5 种算法都在 loss 中加入了相同的 entropy 奖励。左边这幅图表示模型输出动作概率的 entropy 变化情况,越低表示越收敛。右图表示在测试集中模型生成的排列有多大的比例比原始排列在评估器中的总得分更好,我们称这个百分数为优势占比或 better percent,简称 BP,在 Lazada 重排又被称为替换率。在我们的观点中,强化学习训练时不看 loss,而看 entropy 和总回报。
强化学习算法表现对比(左:熵;右:成交 BP)
从左边的 entropy 对比图中可以看出,我们的 PPO_MC 算法是收敛的最快最好;而从右边的 BP 对比图中可以看出,同样是我们的 PPO_MC 模型可以达到最好的效果。原版的 PPO 模型不仅在 entropy 上难以收敛,而且生成的序列也仅仅只是比原始序列好一些,反而不如 reinforce_3 算法收敛的效果好。
我们也可以更通俗一些来看 PPO_MC 算法,它在训练之前会通过采样来得到多条表现不一的序列,然后更新模型时就可以更加倾向于表现好的序列。这个算法其实也是有改进空间的,可以从上面的训练图中看出,前期 entropy 的收敛是非常快的,也可以想象模型在前期时,随机性很大,采样得到的序列多种多样,很容易找到有用的梯度更新方向。然而模型在后期 entropy 已经变得很小或者基本收敛了,采样得到的序列基本都差不多,也难以进行有用的更新了,可以说是这个时候的采样是对算力的巨大浪费,做了很多无用功。那么这个采样一定是需要按照它当前的模型参数来采样吗?其实未必。说明一下,这里的采样是为了算均值,与算法是 on-policy 还是 off-policy 是没有任何关系的,更新模型还是按照原来的算法逻辑。原则上来说,我们是需要一个多样性丰富,并且表现能够比当前的策略稍好一些的采样策略。随机采样肯定是不行,因为它采出来的序列可能都很差。如何去得到更好的采样策略呢?这也是强化学习圈子中非常热门的研究范畴,就留给各位看官们来发挥聪明才智了。
2. 两组实现细节对比
数据的组织由于离线训练数据的保留机制,如果用户只浏览过第一页,那么我们只能拿到第一页的 20 个商品,只有当用户浏览到第二页时,我们才能拿到前两页的 40 个商品。这两种数据(只有第一页、有前两页)的分布是有显著差异的,前者是用户只在第一页点击或者购买,可能是这个序列已经比较好了,后者是用户在一直浏览到了第二页,有可能是 top 20 的序列很差造成的。那么,我们应当如何权衡数据的质量和数量呢?
我们做了三个测试模型,一个是用包含 17 个候选商品的数据来训练模型;另一个是用 30 个商品的数据训练;最后一个是同时用这两份数据训练(这两份数据都是在 160 万条左右)。最后,由于我们的模型上线时要考虑到耗时问题,只排第一页的 17 个商品,因此我们让这三个测试模型分别在 17 排 17, 30 排 17, 50 排 17,100 排 17 这四个环境中进行测试,与原序列对比,观察它们生成的新序列从我们的评估器看来是不是更好的。如下表所示。
数据的影响
从上表的数据中可以看出,在两个训练数据集的大小差不多以及训练时间差不多的情况下,用第一页的数据集训练效果稍微好一些,当然差距也不是很大。从节约计算和存储资源的角度来看,还是直接用第一页的数据更为方便。并且通过上表,我们可以发现候选商品集合越大越好,只要耗时能接受。考虑到我们的模型耗时就相当于是普通打分排序耗时的 N
倍,对于 N
较小的情况也能够快速预测,但对于上百上千数量级的商品,可能就难以接受了。
目标的改变在以上的内容中,我们的优化目标都是最大化期望购买数,而我们能够通过修改 reward 的定义,达到优化其他目标的效果。举例子来说,一个模型如果想要提升总体 GMV,在过去方法大致可以归为以下几类:
1)模型目标不变,在转化率的打分上乘上价格因子,近似于期望 GMV。这类方法通常会对排序结果有一个较大的改变,有明显的提价效果,但线上效果相对不稳定。
2)模型在训练时使用价格对正样本加权或改 loss。这类方法对排序结果的影响不大,在某些情况下可能能够提升一定的单价,但通常不显著。
3)将部分非成交(如加购)样本当作成交样本进行训练。以加购样本为例,从 AE 的统计数据来看,这些商品的价格的平均值数倍高于成交样本。这是一种在成交样本中自然添加一定置信度高价样本的数据增强方法我们能够看出,以上的几类方法都是在间接地提升 GMV,而强化学习模型的一个强大之处就在于我们几乎能够直接对 GMV 建模。我们可以将 reward 修改为:
其中,
表示第
个商品的价格。在实际的训练中,我们并不使用商品的原始价格作为
,而是使用它在这个商品候选集中价格分位数。通过对价格进行此变化,能够防止商品间的因价格差异过大而产生不良反应,但也丢失了商品价格的一部分原始信息。如何更好地将价格因素包容进模型,也是一个未来需要更精细考虑的问题。我们把考虑期望成交数的模型称为 PAY 版本,考虑期望 GMV 的模型称为 GMV 版本,以及一种是两者加权融合的 PAY_GMV 版本,优化目标变为:
上式中的 λ
是一个可以调的系数。在离线评估的情况下,三种模型的训练效果如下所示。
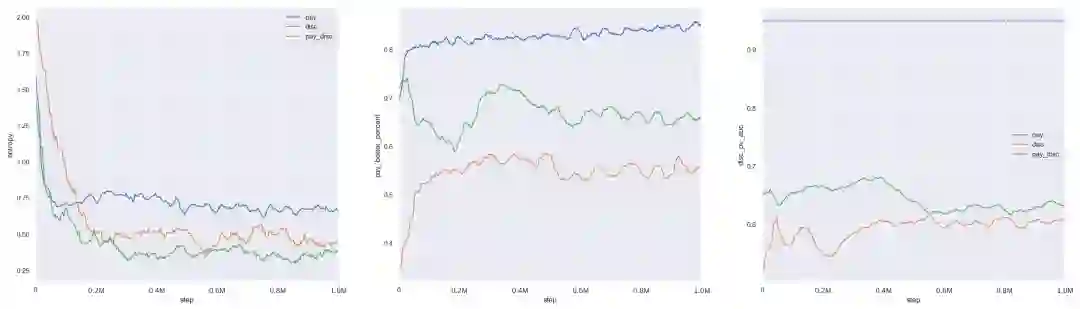
目标的影响(左:熵;中:成交视角 BP;右:GMV 视角 BP)
图中的模型都是用 30 个商品候选集的数据来进行训练得到的,其中的 PAY_GMV 版本的 λ=1
。意料之中,PAY 版本在成交转化上占据优势,GMV 版本在 GMV 上占据优势,PAY_GMV 版本则是会得到一个两者均衡的结果。
04 线上部署与真实效果
离线评测终究还是存在偏差的,为了证实生成器模型能够确实地提升线上效果,我们将模型通过定时调度的策略,每天进行训练和模型重新上传。模型训练时,会收集最近两周所有 bts 实验桶的离线数据,使用它们训练评估器的 5 个小时,而后再训练生成器,并且在 6 个小时后发布训练好的新生成器模型。评估器采用的是增量训练的模式,而生成器模型为了避免失去探索能力,会每次重新初始化训练。
线上实验方面,我们首次取得线上正向效果是在国庆节。当时上线的是 GMV 版本的强化学习重排模型,对比基准桶取得了较好的单价提升效果。在线上实验中,我们发现这个 GMV 版本的模型会带来转化率的亏损。所以,为了平衡 uv 转化率和 uv 价值,在国庆节后上线了 PAY_GMV 版本的强化学习重排模型,使得 uv 转化率和 uv 价值这两个指标都取得了提升。值得一提的是,该版本的模型带来一定的单价和转化率置换,损失了部分单价,提升了一定转化率,使总体 GMV 受益。
线上日常表现
在双十一大促前,用户对高价的商品的购买欲望锐减,更倾向于观望和加购。因此,我们把加购样本和成交样本全部当作成交样本来给评估器进行训练,接着再利用这个评估器来训练生成器模型。在这里我们是希望加购商品的数量越多越好,并且又由于用户更倾向于低价的商品,于是我们是使用上述 PAY 版的生成器模型。在大促前 5 天,对比基准桶,我们模型的收藏加购率提升约 12.4 %,而在不带强化学习的实验桶中,最高的加购率仅在 11.5% 左右,有 1% 左右的 gap。双十一首日,带有强化学习重排模型的桶表现最为突出,成交金额提升 6.81%。在双十一次日中,强化学习重排模型的表现略微下降,成交金额提升 5.65%。相对于实时重排桶(仅重排不同,实时重排为 AE rerank 的实时版本),也有超过 1% 的总体 GMV 提升。
05 阶段总结与未来展望
在五个月的时间里,我们成功地将强化学习重排模型从无到有地搭建了出来,并且经过了双十一考验,展示了它的灵活性、可行性和巨大潜力。本节中,我们将展望重排的未来之路。
1. GAIL 强化学习重排
目前来说,我们重排模型的训练完全依赖于评估器,它的准确与否决定了生成器的好坏,而我们的评估器又只是由少量的数据训练得到的(相比于整个空间来说)。因此,我们猜测评估器在训练数据附近的分布中是比较可信的,而在与之差别较大的分布中或许是不太可信的。那么,能不能让生成器产生的序列不仅好而且还要尽可能落在训练数据的分布中呢?于是,我们借助了 GAIL 的思想,生成器不仅要接收之前训练好的评估器给的奖励,还要接受同时训练的判别器给的奖励。这里,判别器的目标就是给生成的序列打出尽可能低的分数,而给原始序列打出尽可能高的分数。训练的结果如下图所示。
GAIL 强化学习重排表现(左:熵;中:成交 BP;右:判别器 AUC)
蓝线是之前 PAY 版本的强化学习重排模型,可以在第二幅图中看到它在成交优势占比的指标中是最高的,生成的序列有接近 90% 从评估器看来打分更高,而在右图中判别器也能够以非常高的准确率将其与原始序列分辨出来。橙线是只用判别器来训练生成器,就是原版 GAIL 的过程,目标就是让生成的序列与原始的序列差不多。不难发现,在第二幅图中,它生成的序列在评估器中的打分不高。绿线就是上述说的两者兼顾的版本,生成的序列既要在评估器中的打分更高,也要在判别器中的打分更高。
从上面第一幅图中可以发现,带有判别器的两个模型 entropy 都收敛得很低,这是因为我们在其中加入了随机探索的策略。具体来说,之前每一步是按照策略预估的概率来选择一个候选商品,而这两个模型中是会有 0.2 的概率随机挑选一个候选商品。实验发现,这种简单的探索策略有助于 GAIL 的训练。
由 11 月 25 日至 11 月 27 日 3 天的线上结果来看,GAIL 重排对比原重排平均能够提升单量 3.22%,成交总额 3.81%,是个很不错的提升。
2. 和 AUC 的爱恨情仇
相信读者对 AUC 这一指标再熟悉不过了:它是一个刻画了商品打分与商品 label 的方向一致性的指标。我们在离线的环境下,想要评价一个排序模型的好坏时,几乎都会考虑使用 AUC 进行判定,因为 AUC 的值表达的是面对不同 label 的商品对时,我们将 label 更好的商品打上更高的分的频率,这和我们对商品排序的目标直觉上来说是一致的。一个高 AUC 的模型意味着它能更好地判断出商品之间的好坏关系,所以我们通过不断地优化 AUC,来探索更好的模型。然而,当我们将视线转移到线上的真实表现时,尽管在通常情况下,能够提升 AUC 的模型能够带来一定的转化率提升,但我们会发现 UV 转化率和 AUC 的正向关系并没有那么大。在半年前,我们发现了这一现象的极端体现:一个大幅提升离线 AUC 的模型,它大幅降低了在线 AUC,且大幅提升了线上真实的UV转化率。我们称该现象为排序测不准原理。那么,使用 AUC 进行评估究竟有何风险?
1)离线 AUC 与线上 UV 转化率并无直接关联。我们通过 AUC 来联系线上 UV 转化率的基点,是上下文对 label 的影响不大,以及 position bias 对行为产生的损伤是越单调递增的这两点,而它们实际都是不精确的。
2)模型上线改变排序结果后,展示序列分布发生变化,原评估结果失效。我们可以用 AUC 来评价一个评估模型,但是对于生成模型来说,它会改变原序上的 label,我们不能够通过原序 label 来判断它的表现。
3)在线 AUC 的问题更为严重。本质上来说,在线 AUC 不存在可比性。这里我们举一个真实的例子:在这半年里,我们曾有一个桶的策略降低了 10% 的线上 uv 转化率,但是从在线 AUC 来看,它在首页 GAUC 上涨了 1% 以上,而这一个点的提升是通过大多数正常途径的优化很难达到的!这个现象产生的原因,是重排的上游模型产出出现了问题,极大稀释了重排候选集合中优质商品的占比。
试想一个更为夸张的情况,当一页 20 个商品中的后 10个 商品很糟糕,永远不会发生成交时,有一半的 pair 就变成了送分题,从而造成了 GAUC 的虚高。透过这个现象,我们找到了一个能够急剧增大 GAUC 的模型:它将最可能成交的商品放在首位,然后放一堆最无关的商品。这个模型在理想情况下,GAUC 应当为 1,在正常情况下也至少能够大幅提升 GAUC,想要提升 GAUC 的同学可以尝试一下,副作用是 UV 转化或许会跌 90% 左右。被利用的核心漏洞是在不产生成交的情况下,无论排成什么鬼样子,都不会对 GAUC 的值产生影响。所以,线上的所有实验可能都有着不同的商品排序分布,除了一个模型大致的水位之外,我们无法通过对比在线 AUC 获得相当精细的信息。发现以上问题之后,我们可能渐渐想要放弃 AUC 这一指标,但仔细一想,好像又没有其他的指标能够直接代替它。而我们在最初发现 AUC 的潜在问题时,就希望能够找到另一个使用简易、表现精确、线上线下一致的新指标。强化学习框架中的评估器,就有能力作为这样的指标。在我们混合转化率和 GMV 优化目标的模型中,指标显示我们生成的序列在评估器看来占了压倒性的优势,但 GAUC 仅在 0.5 左右,而正是这样一个 GAUC 0.5 的模型,在线上取得了双向的显著提升,这证明了 AUC 在某些情况下是缺乏判别能力的。
强化学习重排 AUC、BP 对比
3. World Model:序列评估器
早在 2016 年的 SIGIR 就被 Thorsten Joachims 提出,而主题 Counterfactual Evaluation and Learning 正是想要消除线上线下不一致性。在他的 tutorial 中,给出了一些简单的由于系统 selection bias 造成的预测不准确的问题的解决方案,主要还是在针对如何 model 这个 bias 展开的 。其中的一个方法,被称为 Model the world,是通过用模拟拟合线上真实 reward 来达到 unbias 的目的,这和我们强化学习中使用的序列评估器是一致的。通过一段时间的线上测试,我们能够相信强化学习环境使用的评估器是具有较好的能力的,否则生成器模型是难以得到线上提升的。所以我们认为,序列评估器可以作为一种有一定判别能力的离线评估手段。
新老离线评估对比
4. 实时强化学习模型
在我们这一阶段的工作中,我们对生成器的研究探索更多,而评估模型只是一个相对令人满意的版本。在后续的工作里,一个直接思路就是让我们的评估器的评估能力更强。评估器在训练数据包含的已知空间中能够取得一个比较好的 AUC,但是对相对未知的空间,我们也无法得知它的表现究竟如何。上面提到的 GAIL 强化学习模型是一种方法,让生成器的产出在已知空间附近。另一种更加主动的方法,是去探索这些未知区域。但我们也不需要太过严格地去探索整个空间,而是探索评估器认为比较好的区域就足够了,因为这一部分更接近我们想要展示的序列。达到这一目标的方法,可以是在离线的环境中训练出能够最大化序列评估器打分的序列生成器,然后将它上线。这样一来,序列评估器的训练数据中就会增加原本它认为的高分区域,从而得到学习。然而,由于我们目前的版本是离线训练的,那么当它接收到信号的时候,已经是一到两天之后了。所以,让它更加精确的方法,可以是让它升级成为一个实时版本,这样它就能够做到快速地自我进化。一旦评估器变得更加准确,生成器也将收获更好的效果。另一个思路,是完全放弃评估器,和线上真实的环境进行交互,不过以我们现有的经验来看,在这个框架下生成器难以得到良好的训练。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~
会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:
文章推荐:
阿里新一代Rank技术
阿里飞猪个性化推荐:召回篇
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。
🧐分享、点赞、在看 ,给个三连击 呗!👇