使用神经网络模型创建一个龙与地下城怪物生成器

来源:DeepHub IMBA
本文为约2823字,建议阅读6分钟
本文介绍了
游戏DND怪物统计数据,以及它们与CR以及彼此之间的关系程度.
龙与地下城(DND)于1974年发行第一版,现在所有RPG游戏都有它的影子,可以说它影响了全世界的RPG,对于RPG来说,最主要的一个特点就是有着不同类型的怪物,而我们可以通过《dungeon master guide》中提供的Challenge Rating(CR)公式来创建我们自己的怪物,因为我们也是地牢大师的一员,对吧。

《龙与地下城》让玩家能够自由地与好友一起游戏并创造故事。作为DM,我们还能根据自己的喜好创造属于自己的怪物。所以就有了本篇文章,本文中着重于四个主要问题:
根据CR公式计算的手动怪物的挑战等级有何不同?
怪物的属性如何与挑战评级系统及其本身相关联?
怪物的非属性属性(类型,环境,大小,排列)如何影响它的属性?
我们能预测一个没有经验的dm和SRC怪物相似的怪物属性块吗?
挑战等级(CR)公式
[‘Monster Name’, ‘Size’, ‘Type’, ‘Alignment’, ‘Traits’, ‘Reactions’,‘Armor Class’, ‘Hit Points’, ‘Speed’, ‘Challenge’, ‘Proficiency Bonus’, ‘STR’, ‘DEX’, ‘CON’, ‘INT’, ‘WIS’, ‘CHA’, ‘Actions’, ‘Legendary Actions’, ‘Environment’, ‘Attack_Bonus’, ‘Spell_Bonus’, ‘Spell_Save_DC’, ‘WIS_SV’, ‘INT_SV’, ‘CHA_SV’, ‘STR_SV’, ‘DEX_SV’, ‘CON_SV’, ‘Arctic’, ‘Coastal’, ‘Desert’, ‘Forest’, ‘Grassland’, ‘Hill’, ‘Mountain’, ‘NA’, ‘Swamp’, ‘Underdark’, ‘Underwater’, ‘Urban’, ‘Average_Damage_per_Round’, ‘Damage Resistances’, ‘Damage Immunities’, ‘Condition Immunities’, ‘Damage Vulnerabilities’, ‘Spellcaster’, ‘Magic Resistance’,‘Legendary Resistance’, ‘Regeneration’, ‘Undead Fortitude’, ‘Pack Tactics’, ‘Damage Transfer’, ‘Angelic Weapons’, ‘Charge’]
CR与怪物统计数据有关吗?
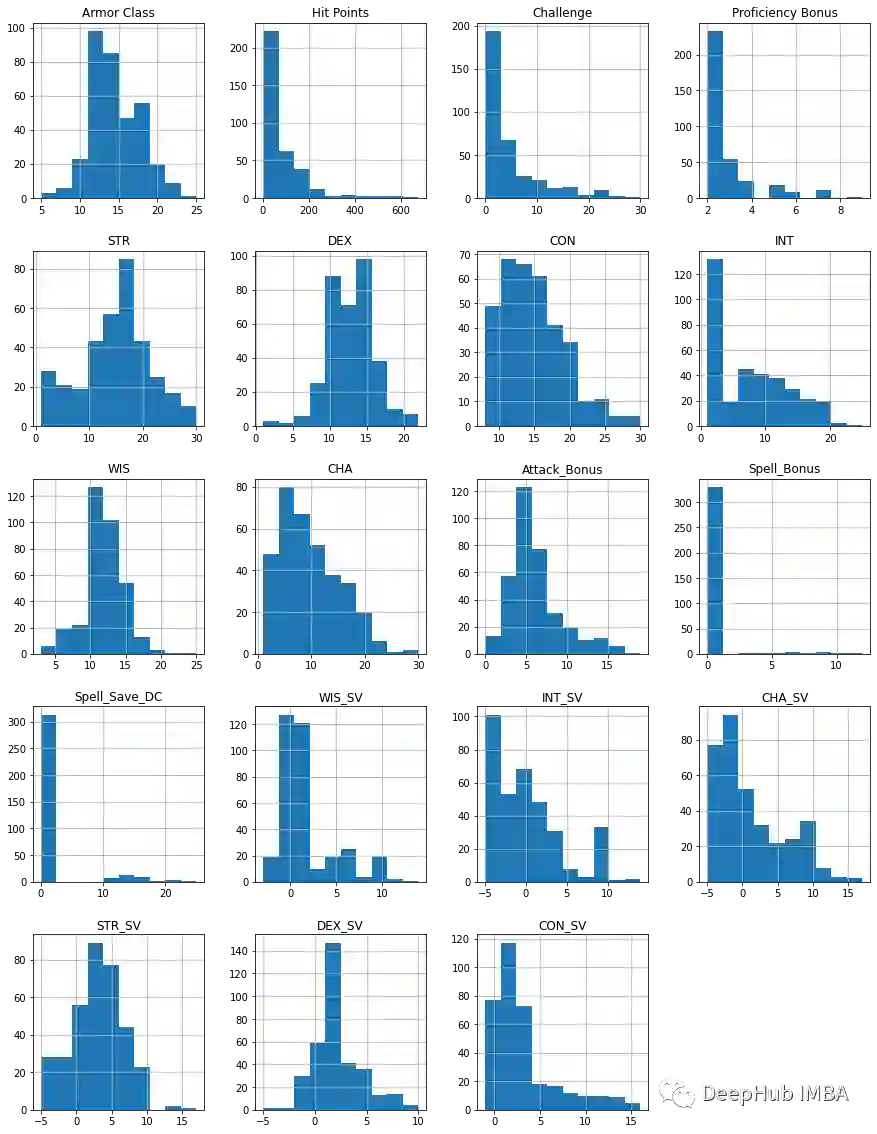

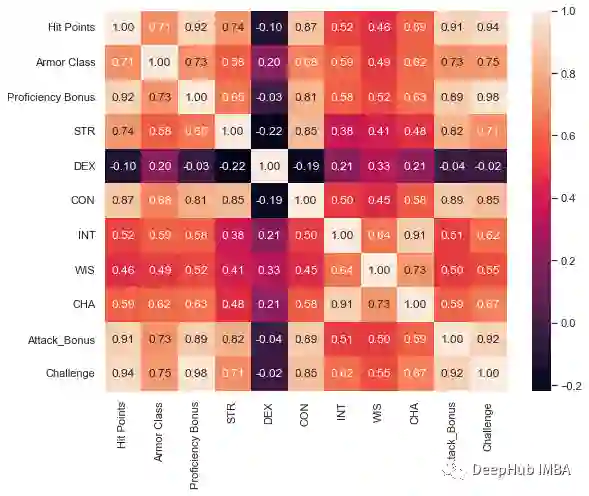
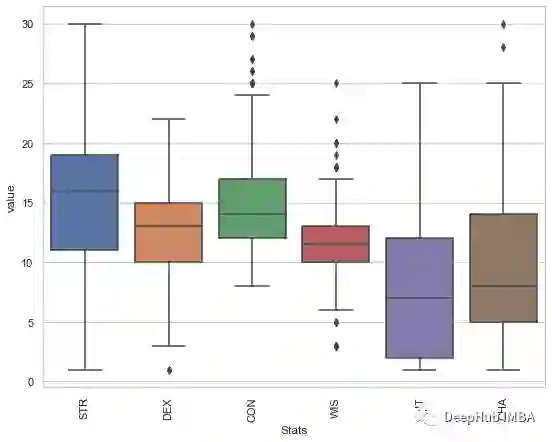
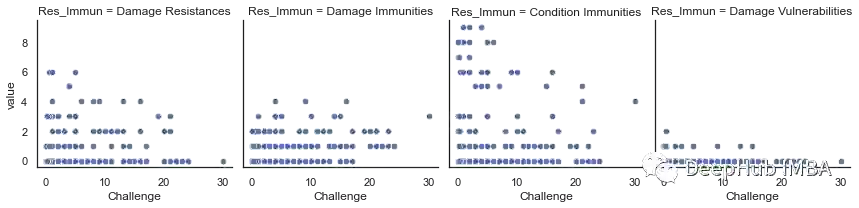
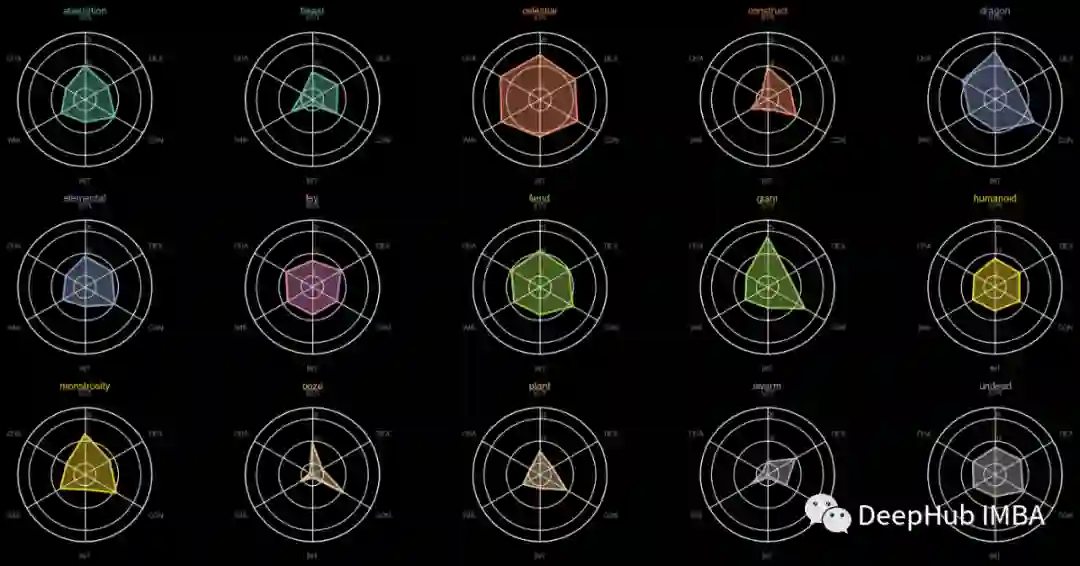
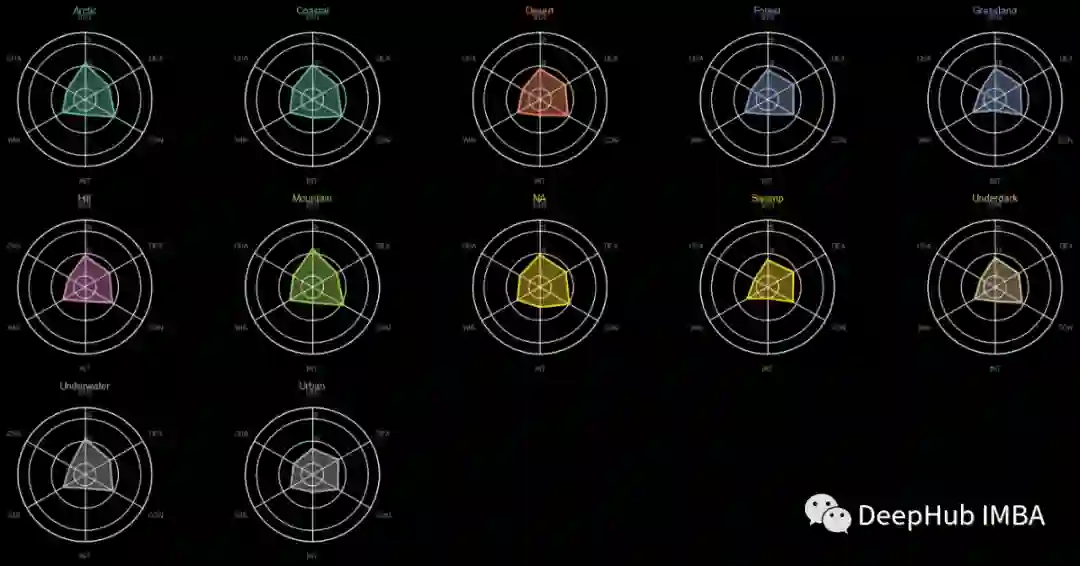
怪物类型,环境,大小和排列
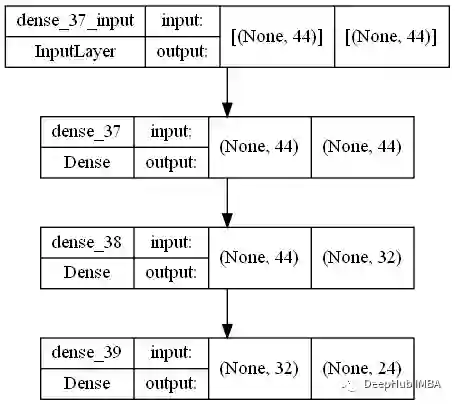
创建一个模型来预测怪物数据
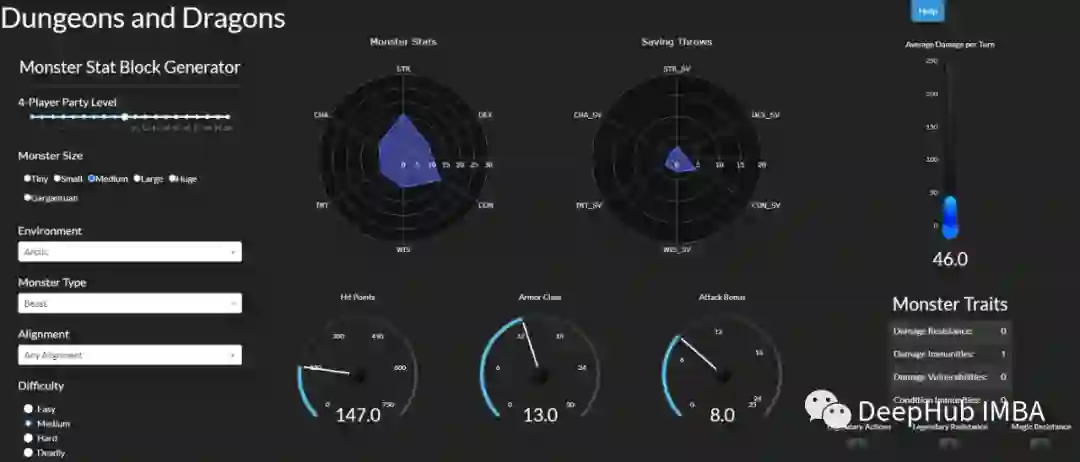
总结

登录查看更多
相关内容



相关VIP内容
相关资讯