ICCV19开源论文 DeepGCNs: Can GCNs Go as Deep as CNNs?
前言
GCN与CNN有很多相似之处。GCN的卷积思想也是基于CNN卷积的优秀表现所提出的,。GCN由于其表达形式和卷积方法特殊性,在节点分类任务(引文网络)中,只有简单的3-4层可以把任务完成的很好。但是对于一些其他的的任务,可能浅层的网络模型没有办法很好的处理数据。但是当把GCN的层数增多之后,会出现梯度消失和over-smoothing的问题,与当时CNN的层数加深出现的问题相似,因此自然想到了应用在CNN上的方法迁移到GCN上。
本文提出了几种加深GCN的思路,并进行实验,事实证明确实提高了性能
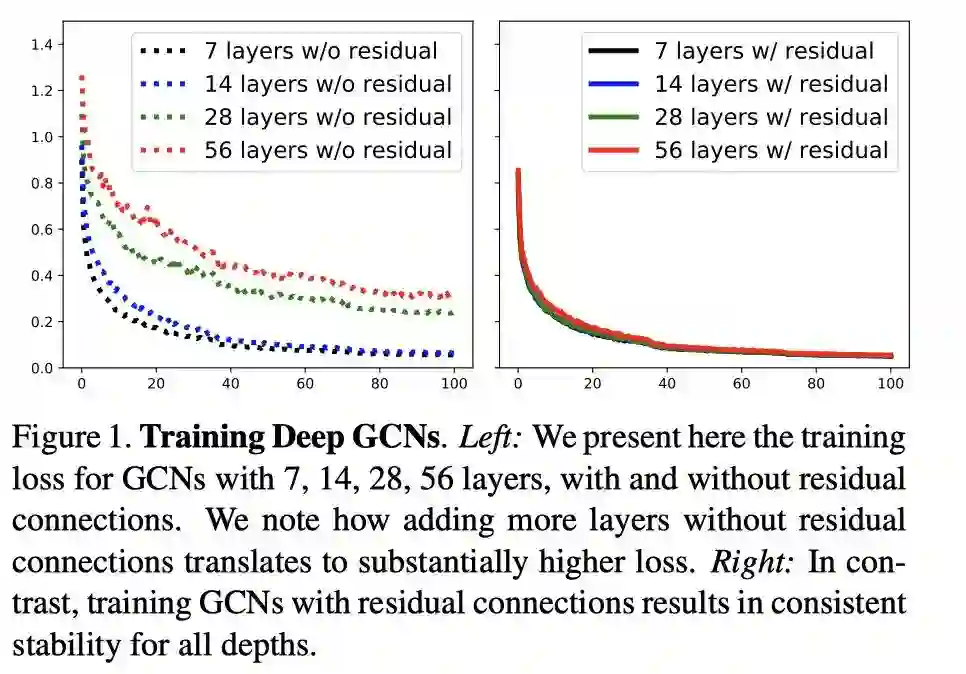
1.待解决问题(梯度消失,爆炸/over-smothing)
1.1梯度消失问题
梯度消失/爆炸出现的两种情况
-
使用了错误的激活函数 -
层数太深(本篇文章中出现的情况)
因为计算梯度的公式中有参数求导连乘的情况,因此层数增多后,一旦有多个连续<1 或者>1 的导数连乘,最终参数的梯度就会接近0(连续<1),又称为梯度消失 或接近无穷(连续<1)又称为梯度爆炸。
1.2 over-smothing 问题 (图神经网络过度平滑的问题)
意思就是,在拓扑图结构中,一层GCN 聚合了1阶邻居的节点信息,2层GCN 聚合了2阶邻居节点的信息, n层GCN 就聚合了n 阶邻居节点的信息,在一张连通图当中,每个节点用于聚合的邻居节点重合度较高,很容易导致每个节点学出来的特征表示是一致的。这样节点的特性就被掩盖掉了, 图卷积神经网络层数增多后,聚合的邻居变多,不同节点重合的邻居节点数变多,因此会出现over-smothing 现象。
解决思路:(通过有效地改变图的结构或卷积的领接节点来解决。比如在点云里用动态knn/dilation来建边)
2.GCN点云网络
此篇文章是基于GCN解决点云方面问题,与传统节点分类预测任务在网络结构上不太一致,但是殊途同归。因此本文介绍的是一种更加普适于点云任务的GCN网络结构模块
2.1点云
-
点云与三维图像的关系:三维图像是一种特殊的信息表达形式,其特征是表达的空间中三个维度的数据,表现形式包括:深度图(以灰度表达物体与相机的距离),几何模型(由CAD软件建立),点云模型(所有逆向工程设备都将物体采样成点云)。和二维图像相比,三维图像借助第三个维度的信息,可以实现天然的物体——背景解耦。点云数据是最为常见也是最基础的三维模型。点云模型往往由测量直接得到,每个点对应一个测量点,未经过其他处理手段,故包含了最大的信息量。这些信息隐藏在点云中需要以其他提取手段将其萃取出来,提取点云中信息的过程则为三维图像处理。 -
点云的概念:点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量点集合,在获取物体表面每个采样点的空间坐标后,得到的是点的集合,称之为“点云”(Point Cloud)。 -
点云的获取设备:RGBD设备是获取点云的设备,比如PrimeSense公司的PrimeSensor、微软的Kinect、华硕的XTionPRO。 -
点云的内容:根据激光测量原理得到的点云,包括三维坐标(XYZ)和激光反射强度(Intensity),强度信息与目标的表面材质、粗糙度、入射角方向,以及仪器的发射能量,激光波长有关。根据摄影测量原理得到的点云,包括三维坐标(XYZ)和颜色信息(RGB)。结合激光测量和摄影测量原理得到点云,包括三维坐标(XYZ)、激光反射强度(Intensity)和颜色信息(RGB)。 -
点云的属性:空间分辨率、点位精度、表面法向量等。
2.2GCN点云网络结构
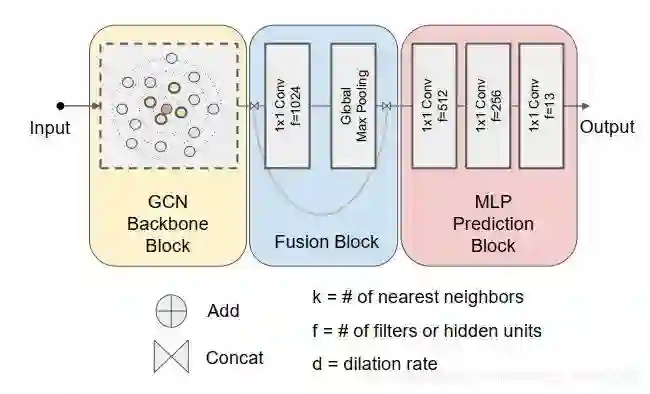
-
Feature更新模块(论文中称为:GCN Backbone Block),完成点云中每个点的feature的反复更新。 -
Feature融合模块(论文中称为:Fusion Block),该模块将点云中所有点的feature整合到一起,得出一个点云的整体的feature。 -
预测模块(论文中称为:MLP Prediction Block),该模块使用之前得到的每个点feature,以及点云的整体feature,进行点云分类、分割等视觉任务。
2.3GCN点云公式表达
聚合函数可以是mean、aggregator、max-pooling aggregator、attention aggregator或LSTM aggregator。更新函数可以是多层感知器,门控网络等。
本文使用一个简单的max-pooling顶点特征聚集器,在没有可学习参数的情况下,来聚集中心顶点与其所有相邻顶点之间的特征差异。使用的更新器是一个有batch normalization的多层感知器(MLP)和一个ReLU作为激活函数。
2.4动态边
大多数GCN只在每次迭代时更新顶点特征。最近的一些工作表明,与具有固定图结构的GCN相比,动态图卷积可以更好地学习图的表示。例如,ECC(Edge-Conditioned Convolution,边缘条件卷积)使用动态边缘条件滤波器(dynamic edge-conditional filters)学习特定边的权重矩阵。EdgeConv在每个EdgeConv层之后,找到特征空间中最近的邻居来重建图形。为了学习点云的生成,Graph-Convolution GAN(生成对抗网络)还应用k-NN图来构造每一层顶点的邻域。动态变化的GCN邻居有助于缓解过度平滑的问题,并产生一个有效的更大的感受野。因此,文中在每一层的特征空间中通过一个Dilated k-NN函数来重新计算顶点之间的边,以进一步增加感受野。
3.CNN中的解决方法
3.1 Res-net
深层卷积神经网络中的残差块,卷积层之间跳跃连接,可以保证两个网络之间一定有梯度反传。

3.2 Dense-net
相比与Res-net 每一层的输出 包括该层的输出H(x)和上一层的输出x Dense-net 的输入 包括上一层及上一层前所有层的输入并且 每一层的网络更加稠密,宽度更小
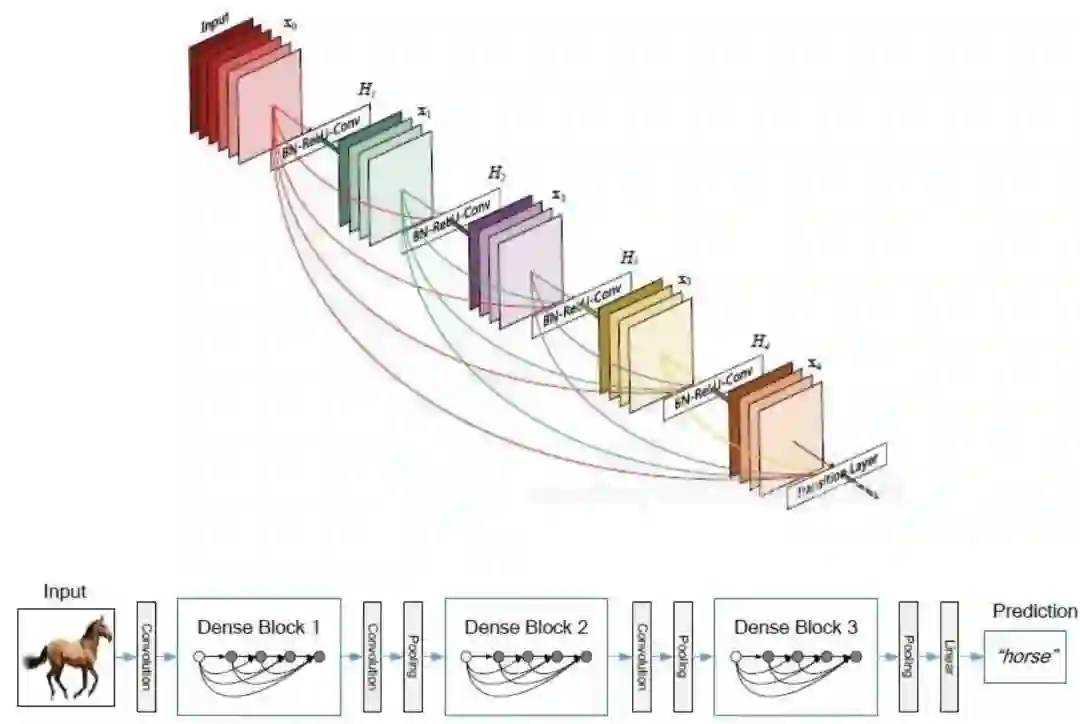
3.3 Dilated-Convolutios
按照一定的比例在图卷积中制造一些空洞,在图像分割等端到端的图学习任务中,减少了下采样和上采样的过程,从而缓解了梯度反传。

4.方法迁移
从总体结构上看,论文提出了三种结构:
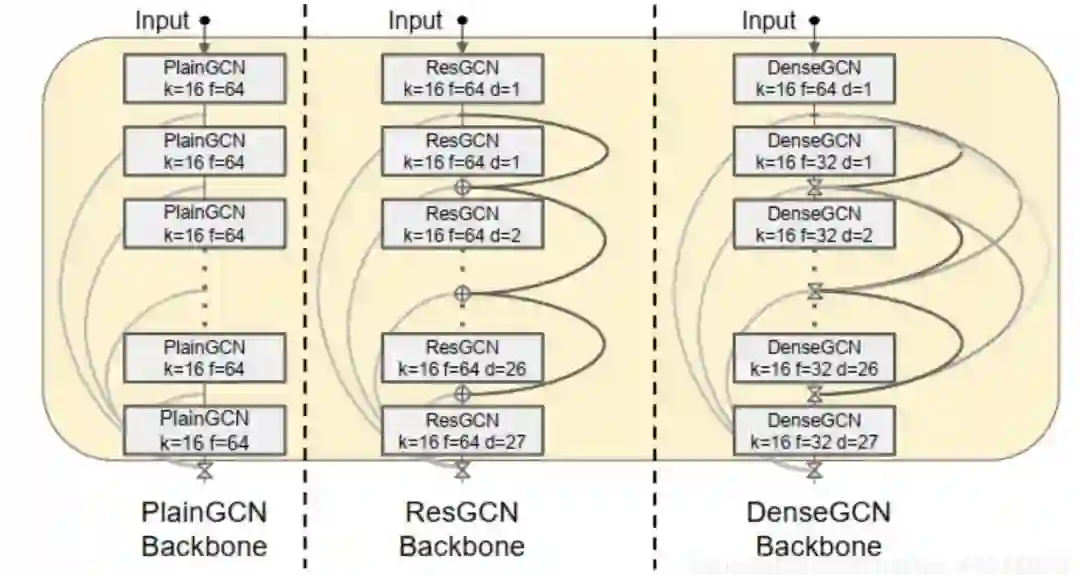
-
PlainGCN: 每层模块接收上一层的输出,作为输入,内部处理完后,产生输出。
-
ResGCN:每层模块接收上一层的输出,作为输入,内部处理完后,产生的输出,从输入加了一个Residual连接。
-
DenseGCN:每层模块接收之前所有层的输出,作为输入。
每层模块内部更新feature的过程,可以分为两个操作步骤:选邻居、计算feature:
选邻居。以点xi 为中心,用 KNN选出 K 个最近的点。为了增加每个点的receptive field,论文在KNN的基础上,文提出了dilated KNN选点方法。
计算feature。选出点后,有多种方式来计算xi的feature。代码中实现了4种。
Feature融合模块以segmentation为例,该模块使用一个卷积层处理后,用max_pool将点云中所有点的feature整合为一个点云的全局feature,再将该全局feature拼接到每个点的feature上。
此时,每个点既有局部信息,也有全局信息。
预测模块用多个卷积层对每个点的feautre进行处理、降维,计算出每个点属于每个类的概率。
实验与三维点云分类任务有关,在这里省略



