学界 | 稳定、表征丰富的球面变分自编码器
选自arXiv
作者:Jiacheng Xu、Greg Durrett
机器之心编译
参与:高璇、张倩
经典的 VAE 实现假设潜在空间的先验函数是多元高斯的,该方法的局限性在于 KL 项可能会激励潜变量的后验分布「坍缩」到先验,导致潜在结构无法被充分利用。本文提出使用 von MisesFisher(vMF)分布代替高斯分布作为潜变量,这样做不仅可以避免 KL 坍缩,而且在一系列建模条件下(包括循环语言建模和词袋文档建模),始终能得到比高斯分布更好的表现。对 vMF 表征的性质分析表明,相比于高斯状态,这些性质在它们的潜在表征上能学习到更丰富、细致的结构。
1. 引言
近期的研究为 NLP 的一系列任务建立了深度生成模型的有效性,包括文本生成(Hu et al., 2017; Yu et al., 2017)、机器翻译(Zhang et al., 2016)以及风格迁移(Shen et al., 2017; Zhao et al., 2017a)。变分自编码器(VAE)在以往的文本建模中被研究过(Miao et al., 2016; Bowman et al., 2016),研究人员曾提出过一个用来捕获数据中潜在结构的连续潜变量。经典的 VAE 实现假设潜在空间的先验函数是多元高斯的,在训练期间,变分后验在损失函数的 KL 散度激励下会近似于先验值。以往研究发现,该方法的一个主要局限性是 KL 项可能会激励潜变量的后验分布「坍缩」到先验,导致潜在结构无法被充分利用(Bowman et al., 2016; Chen et al., 2016)。
本文提出使用 von MisesFisher(vMF)分布代替高斯分布作为潜变量。vMF 将分布置于由平均参数µ和集中参数 κ控制的单元超球面上。先验是单位超球面(κ = 0)上的均匀分布,后验分布将κ作为一个固定模型超参数。由于 KL 散度只取决于κ,研究人员可以从结构上防止 KL 坍缩并简化模型优化问题。他们表示,这种方法比灵活地学习 κ更具鲁棒性,将κ设为固定值能获得更好的性能。他们的模型获得比模拟高斯模型更好的对数似然比,同时有更高的 KL 散度值。这表明在训练末端更充分地利用了潜变量。
过去的研究已经提出了处理高斯模型下 KL 坍缩的几项技术。KL 项权重的退火算法在优化过程中仍遗留了鲁棒性弱的问题。之前的其他研究(Yang et al., 2017; Semeniuta et al., 2017)侧重于利用 CNN 而非 RNN 作为解码器,以削弱模型并鼓励使用潜在编码,但是收效甚微。以这种方式改变解码器需要精心调优模型和各种解码器的容量参数。研究者提出的方法和选择解码器是相互独立的,可以和这些方法中的任意一个相结合,在 VAE 中使用 vMF 分布也使我们能灵活地以其他方式调整先验函数,例如使用均匀乘积分布(Guu et al., 2018)或分段常数项(Serban et al., 2017a)。
研究人员在两个生成模型范例中评估他们的方法。对于 RNN 语言建模和词袋建模,研究者发现 vMF 比高斯先验更加鲁棒,并且他们的模型学会了更多地依赖潜变量,同时获得更好的留存数据似然。为了更好地理解这些模型的区别,研究人员设计并进行了一系列实验来理解高斯和 vMF 潜在编码空间的特性,这些特性使结构假设变得不同。不出所料,这些潜在代码分布捕获了许多与词袋中相同的信息,但本研究表明,与高斯编码相比,vMF 做到这一点更加容易,可以更有效地捕获到排序信息。
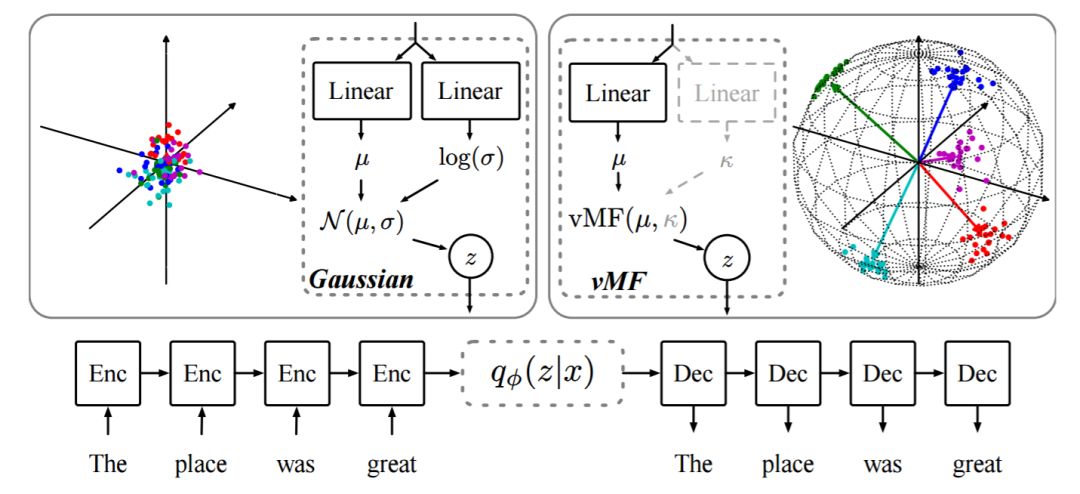
图 1:基于高斯先验(左)和 vMF 先验(右)的神经变分 RNN(NVRNN)语言模型。首先由编码器模型计算变分近似 q_φ(z|x)(虚框)的参数,然后采样 z 并由 z 生成词序列 x。图中显示了来自 N (0, I) 和 vMF(·,κ = 100) 的样本,后者都分布于单位球表面。虽然κ可以从编码器网络中预测出来,但实验发现将κ固定可以得到更稳定的优化和更好的性能。
论文:Spherical Latent Spaces for Stable Variational Autoencoders

论文链接:https://arxiv.org/pdf/1808.10805v1.pdf
摘要:用于文本处理的变分自编码器(VAE)的一个特点是它们结合了强大的编码-解码模型(如 LSTM)和简单的潜在分布(如多元高斯分布)。这些模型存在一个困难的优化问题:在变分后验总是等于先验时,会陷入一种糟糕的局部最优状态,而且模型完全不会利用潜变量,这种「坍缩」是由目标的 KL 散度激励导致的。我们在研究中试验了潜在分布的另一种选择——von Mises-Fisher(vMF)分布,它将散点放置在单位超球面上。有了先验和后验的选择,KL 散度项就只取决于 vMF 分布的方差,此时我们就可以将其视为一个固定的超参数。我们证明了,这样做不仅可以避免 KL 坍缩,而且在一系列建模条件下(包括循环语言建模和词袋文档建模),始终能得到比高斯分布更好的表现。对 vMF 表征的性质分析表明,相比于高斯状态,这些性质在它们的潜在表征上能学习到更丰富、细致的结构。
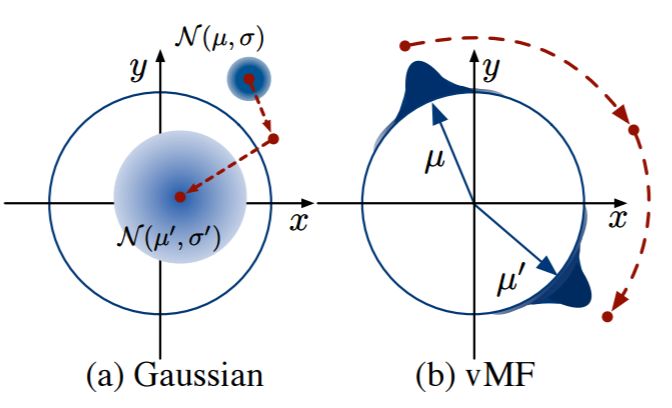
图 2:学习过程中单个样本的 q 随时间变化的优化可视化。在高斯情况下,KL 项使模型更趋于先验(由µ, σ 到µ', σ'),而在 vMF 中,不存在趋向单一分布的情况。
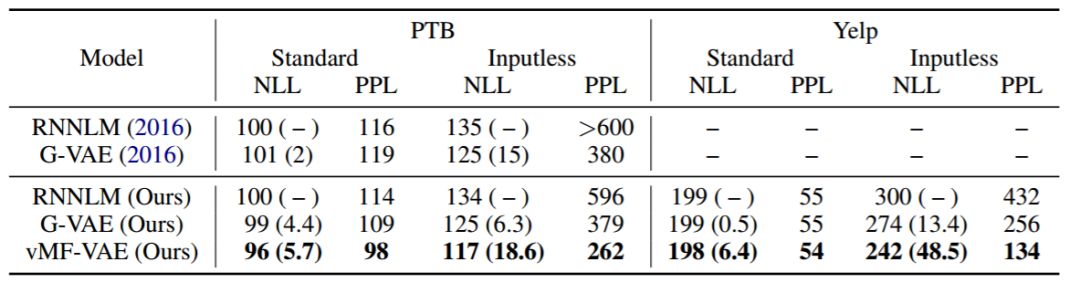
表 3:NVRNN 在 PTB 和 Yelp 测试集上的实验结果。上方的 RNNLM 和 G-VAE 显示了 Bowman 等人(2016)的结果。括号中显示的是 KL 散度,以及总 NLL。最好的结果粗体显示。vMF 始终使用较高的 KL 项权重,但在所有四项中都达到了类似或更好的 NLL 和困惑值。
NVRNN 的实验结果如表 3 所示。我们在测试集中报告了负对数似然比(NLL)和困惑值(PPL)。我们遵循了 Bowman 等人(2016)的实验,该实验对高斯 VAE 的 KL 项权值做了退火处理;vMF VAE 不需要权重退火就能很好地工作。vMF 分布在 Standard 和 Inputless 设置的所有数据集中都使性能得到提升。即使在 Standard 设置下,我们的模型也能成功地使用非零 KL 值达到更好的困惑值,甚至没出现 KL 坍缩(如在 PTBStandard 设置中的 G-VAE)。可能由于优化存在困难,高斯分布会导致较低的 KL 和糟糕的的对数似然比。在 Inputless 设置中,我们看到了巨大的提升:与高斯 VAE 相比,vMF VAE 在 PTB 中将 PPL 从 379 降到 262,在 Yelp 中从 256 降到 134。
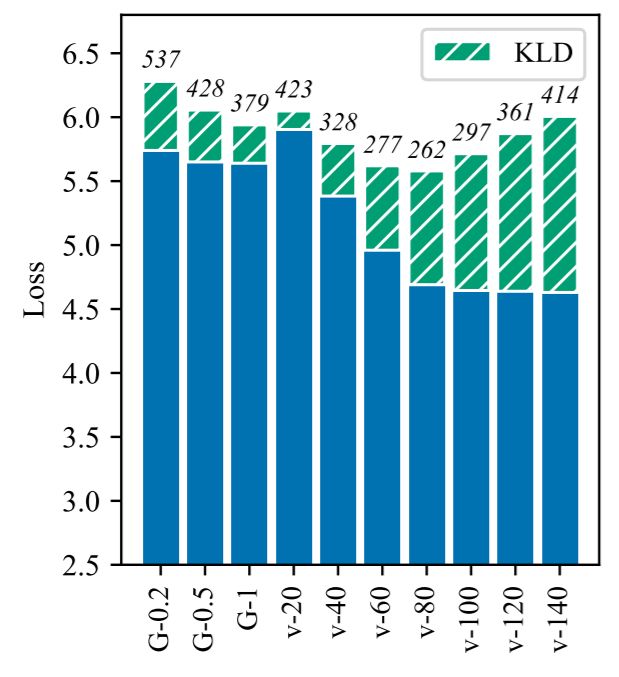
图 4:不同超参数下的高斯和 vMF-NVRNN 的比较。所有的模型都是在 Inputless 设置下在 PTB 上训练的,其中潜在维数为 50.G-α表明高斯 VAE 与 KL 由给定的常数α退火,V-κ表明 VAE 将κ设置为既定值。绿条反映的是 KL 损失的数量,总高度反映的是整个目标。竖条上的数字是困惑值。vMF 的可调性更强,在广泛的κ值范围内也能获得更好的结果。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



