CVPR 2018 | 密歇根大学&谷歌提出TAL-Net:将Faster R-CNN泛化至视频动作定位中
选自arXiv
作者:Yu-Wei Chao等
机器之心编译
参与:Geek AI、路
近日,密歇根大学和谷歌研究院的一项研究提出了时序动作定位网络 TAL-Net,该网络将之前常用于图像目标检测的 Faster R-CNN 网络应用于视频时序动作定位中。在 THUMOS'14 检测基准上,TAL-Net 在动作提名(action proposal)和定位上都取得了目前最好的性能,并且在 ActivityNet 数据集上取得了具有竞争力的性能。目前,该论文已被 CVPR 2018 大会接收。
对人类动作的视觉理解是构建辅助人工智能系统所需的核心能力。在传统的研究中,这个问题通常在动作分类的范畴内被研究 [46, 37, 30],其目标是对一个按照时序剪辑的视频片段进行强制选择(forced-choice)分类,分类为若干动作类型中的一类。尽管人们在此领域的研究取得了累累硕果,但这种分类的设定是不现实的,因为现实世界中的视频通常是没有剪辑过的,而且我们感兴趣的行为通常也内嵌在与其不相关的活动背景中。最近的研究关注点已经逐渐向未剪辑视频中的时序动作定位转移 [24, 32, 47],其任务不仅仅是识别动作的类别,还需要检测每个动作实例的开始和结束时间。时序动作定位的改进可以推动大量重要课题的发展,从提取体育运动视频中的精彩片段这样的即时应用,到更高级的任务,如自动视频字幕。
时序动作定位,和目标检测一样,都属于视觉检测问题的范畴。然而,目标检测旨在生成物体在二维图像中的空间边界框,时序动作定位则是要在一维的帧序列中生成时序片段。因此,许多动作定位的方法从目标检测技术的进展中得到启发。一个成功的例子是:基于区域的检测器的使用 [18, 17, 33]。这些方法首先从完整的图像中生成一个与类别无关的候选区域的集合,然后遍历这些候选区域,对其进行目标分类。要想检测动作,我们可以遵循这一范式,先从整个视频中生成候选片段,然后对每个候选片段进行分类。
在基于区域的检测器中,Faster R-CNN [33] 由于其在公开的对比基准上极具竞争力的检测精度,被广泛应用于目标检测。Faster R-CNN 的核心思想是利用深度神经网络(DNN)的巨大容量推动候选区域生成和目标检测这两个过程。考虑到它在图像目标检测方面的成功,将 Faster R-CNN 用到视频时序动作定位也引起了研究者极大的兴趣。然而,这种领域的转变也带来了一系列挑战。本论文作者回顾了 Faster R-CNN 在动作定位领域存在的问题,并重新设计了网络架构,来具体地解决问题。研究者重点关注以下几个方面:
1. 如何处理动作持续时间的巨大差异?与图像中物体的大小相比,动作的时间范围差别很大——从零点几秒到几分钟不等。但是,Faster R-CNN 根据共享的特征表示对不同规模的候选片段(即 anchor)进行评估,由于特征的时间范围(即感受野)和 anchor 跨度在对齐时存在偏差,因此 Faster R-CNN 可能无法捕获相关的信息。研究者提出使用 multi-tower 网络和扩张时序卷积(dilated temporal convolution)来执行此类对齐工作。
2. 如何利用时序上下文(temporal context)?动作实例之前和之后的时刻包含用于定位和分类的关键信息(可能比目标检测中的空间上下文更重要)。直接简单地将 Faster R-CNN 应用于时序动作定位可能无法利用时序上下文。研究者提出通过扩展生成候选片段和动作分类的感受野来显性地对时序上下文进行编码。
3. 如何最好地融合多流特征?当前最优的动作分类结果主要是通过融合 RGB 和基于光流的特征得到的。然而,探索将这样的特征融合应用到 Faster R-CNN 上的研究还十分有限。研究者提出了一个晚融合(late fusion,在分类结果上融合)方案,并且通过实验证明了它相对于常见的早融合(early fusion,在特征上融合)的优势。
本研究的贡献有两方面:(1)介绍了时序动作定位网络(TAL-Net),一种基于 Faster R-CNN 的视频动作定位新方法;(2)在 THUMOS』14 检测基准 [22] 中,本研究提出的模型在动作提名(action proposal)和定位上都取得了目前最好的性能,并且在 ActivityNet 数据集 [5] 上取得了具有竞争力的性能。
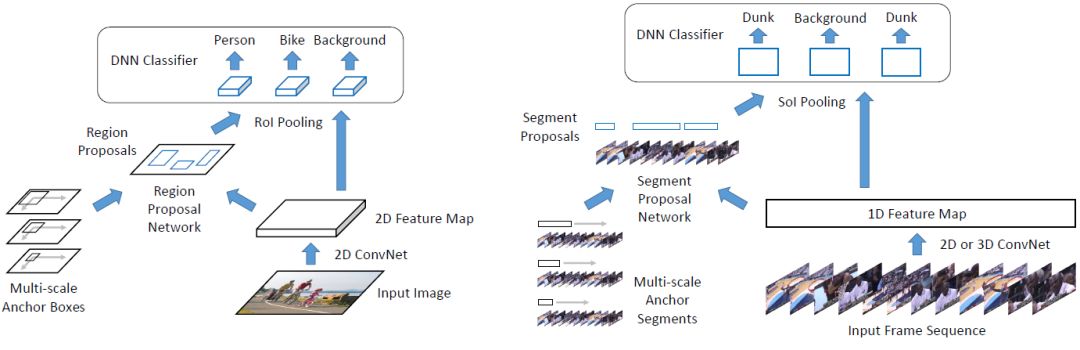
图 1:用于图像目标检测的 Faster R-CNN 架构 [33](左图)和用于视频时序动作定位的 Faster R-CNN 架构 [15, 9, 16, 51](右图)的对比。时序动作定位可以被看作是目标检测任务的一维版本。
Faster R-CNN
Faster R-CNN 最初的提出是为了解决目标检测问题 [33],在给定一个输入图像时,Faster R-CNN 的目标是输出一组检测边界框,每一个边界框都带有一个目标类别标签。整个流程包括两个阶段:生成候选区域和分类。首先,输入图像经过二维卷积处理生成一个二维特征图。另一个二维卷积(即候选区域网络,Region Proposal Network)用于生成一组稀疏的类别无关的候选区域,这是通过对一组大小不同的、以特征图上的每个像素点为中心的锚点框进行分类来实现的。这些候选区域的边界也通过回归进行调整。之后,对于每个候选区域,区域内的特征首先被池化为一个固定大小的特征图(即 RoI 池化)。接着,DNN 分类器使用池化之后的特征计算目标类别的概率,同时为每个目标类别的检测边界进行回归。图 1(左)展示了完整的流程。该框架通常通过交替进行第一阶段和第二阶段的训练来完成训练工作 [33]。
Faster R-CNN 很自然地被拓展到时序动作定位领域 [15, 9, 51]。回想一下,目标检测的目的是检测二维空间区域。而在时序动作定位中,目标则是检测一维的时序片段,每个片段都以一个开始时间和一个结束时间来表示。时序动作定位因此可以被看作是目标检测的一维版本。图 1(右)展示了一个典型的 Faster RCNN 时序动作定位流程。与目标检测类似,它包含两个阶段。首先,给定一组帧序列,我们通常通过二维或者三维卷积网络提取出一个一维特征图。之后,将该特征图传输给一维卷积网络(指候选片段网络,Segment Proposal Network),在每个时间点上对一组大小不同的 anchor 片段进行分类,并且对边界进行回归。这将返回一组稀疏的类别无关的候选片段。接着,对于每个候选片段,我们计算动作类别的概率,并进一步对片段边界进行回归(修正)。在这一步,首先使用一维的 RoI 池化层(也称「SoI 池化」),接着使用 DNN 分类器来实现。
TAL-Net
TAL-Net 遵循了 Faster R-CNN 的检测模式,并用于时序动作定位(图 1 右),但有三种新的架构变化。
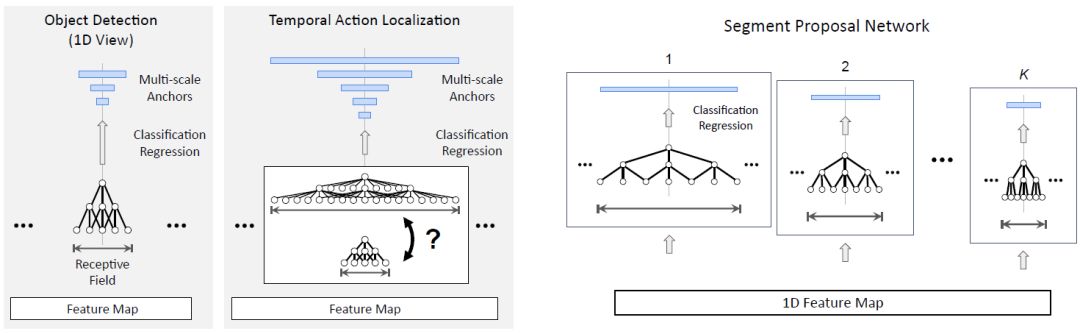
图 2:左图:在时序动作定位中,不同规模的 anchor 共享感受野的局限性。右图:本研究提出的的候选片段网络的 multi-tower 架构。每个 anchor 大小都有一个具备对齐后的感受野的相关网络。
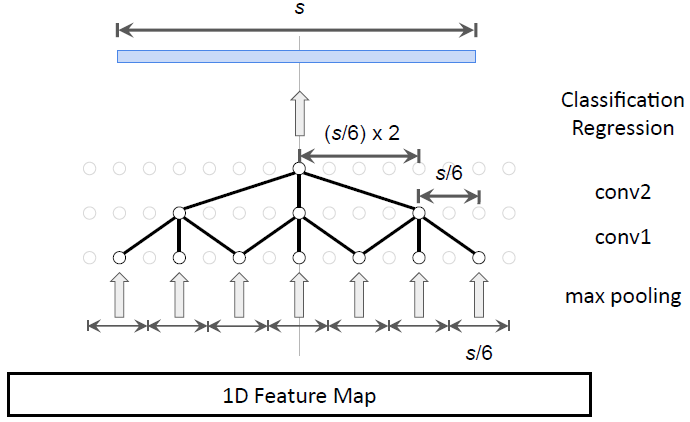
图 3:使用扩张时序卷积控制感受野的大小 s。
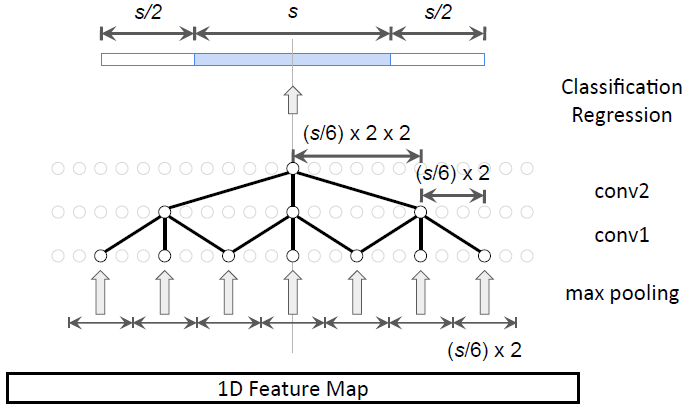
图 4:在生成候选片段中纳入上下文特征。
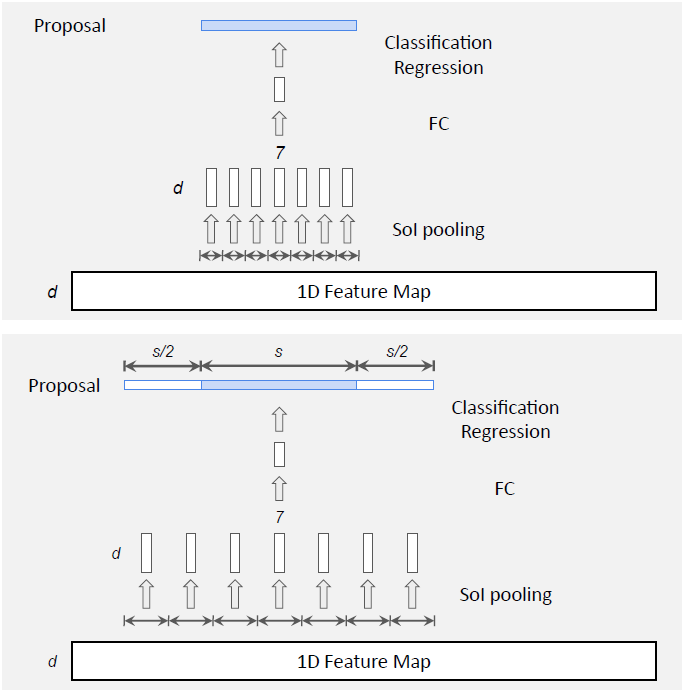
图 5:不纳入上下文特征的候选片段分类(上图)[17, 33],纳入上下文特征后的候选片段分类(下图)。
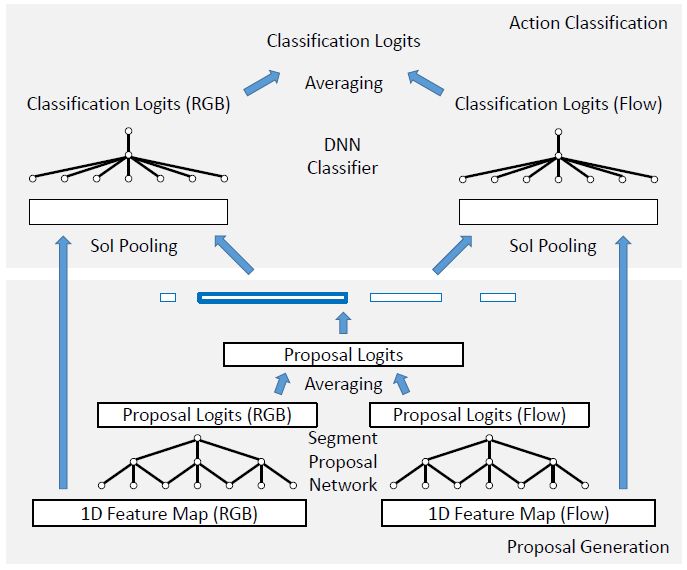
图 6:双流 Faster RCNN 框架的晚融合方案。
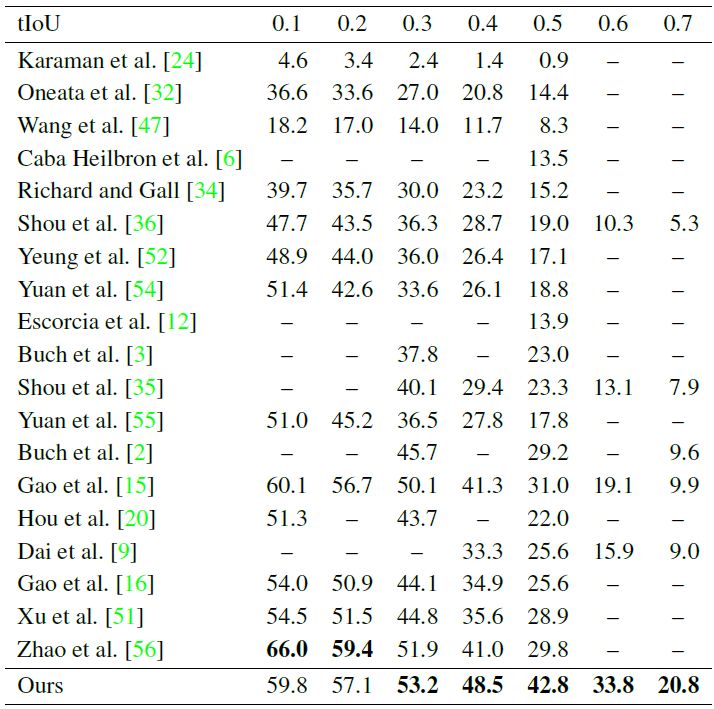
表 5:在 THUMOS'14 上的动作定位 mAP(%)。
论文:Rethinking the Faster R-CNN Architecture for Temporal Action Localization

论文链接:https://arxiv.org/abs/1804.07667
摘要:我们提出了 TAL-Net,一种用于视频时序动作定位的改进方法,它受到了 Faster R-CNN 目标检测框架的启发。TAL-Net 解决了现有方法存在的三个关键问题:(1)我们使用一个可适应动作持续时间剧烈变化的 multi-scale 架构来提高感受野的对齐程度;(2)通过适当扩展感受野,我们更好地利用动作的时序上下文,用于生成候选片段和动作分类;(3)我们显性地考虑了多流特征融合,并证明了动作晚融合的重要性。我们在 THUMOS'14 检测基准上取得了动作提名和定位目前最好的性能,并且在 ActivityNet 数据集上取得了很有竞争力的性能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


