细说何恺明团队在无监督领域的顶作:MoCo三部曲

极市导读
本文从初代MoCo开始从头探索了MoCo系列,探究MoCo系列为什么对Self-Supervised Learning领域产生了这么大的影响。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
从头捋一遍MoCo整个系列做了什么事情,探究MoCo系列为何对Self-Supervised Learning领域所产生的影响如此之大。
有关Self-Supervised和InfoNCE的基础知识可以看Self-Supervised: 如何避免退化解,本文只涉及MoCo系列的Self-Supervised方法是如何演变的。
MoCov1
时间拨回到19年末,那时NLP领域的Transformer进一步应用于Unsupervised representation learning,产生后来影响深远的BERT和GPT系列模型,反观CV领域,ImageNet刷到饱和,似乎遇到了怎么也跨不过的屏障,在不同task之间打转,寻求出路。就在CV领域停滞不前的时候,又是那个人Kaiming He带着MoCo横空出世,横扫了包括PASCAL VOC和COCO在内的7大数据集,至此,CV拉开了Self-Supervised的新篇章,与Transformer联手成为了深度学习炙手可热的研究方向。
MoCo主要设计了三个核心操作:Dictionary as a queue、Momentum update和Shuffling BN。
Dictionary as a queue
正如我之前的文章中提到的,避免退化解最好的办法就是同时满足alignment和uniformity,即需要positive pair和negative pair。其中uniformity是为了不同feature尽可能均匀的分布在unit hypersphere上,为了更有效率的达到这个目的,一个非常直观的办法是增加每次梯度更新所包含的negative pair(即batch size),在MoCo之前有很多方法对如何增加negative pair进行了大量研究。
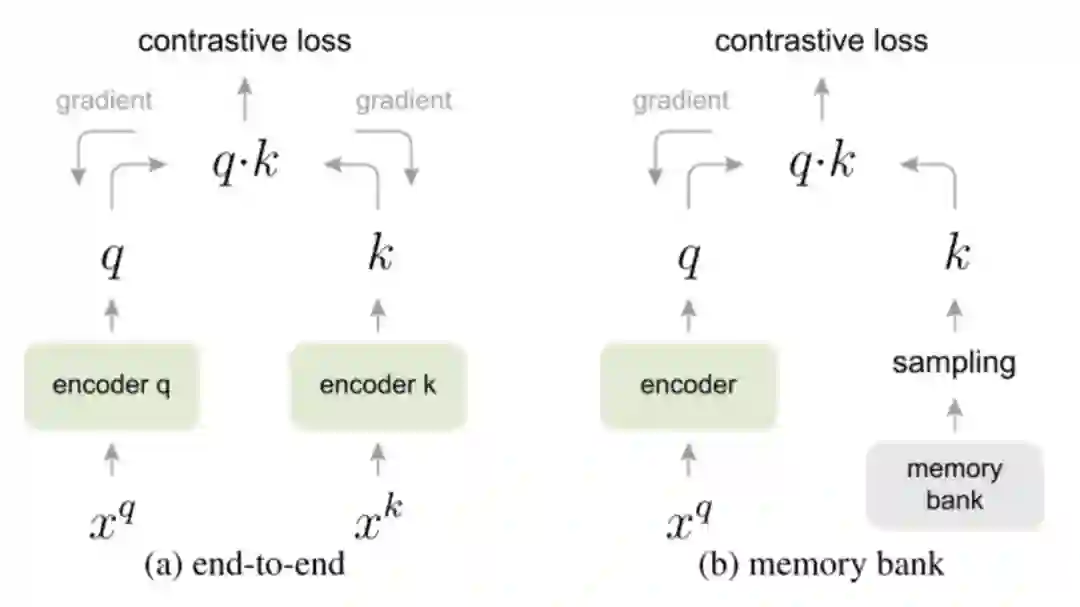
其中图(a)是最简单粗暴,直接end-to-end,batch size的大小取决于GPU容量大小。图(b)设计了一个memory bank保存数据集中所有数据的特征,使用的时候随机从memory bank中采样,然后对采样进行momentum update,这样可以认为多个epoch近似一个大的batch,但是这种方法存在一个问题,就是保存数据集中所有数据特征非常的占显存。
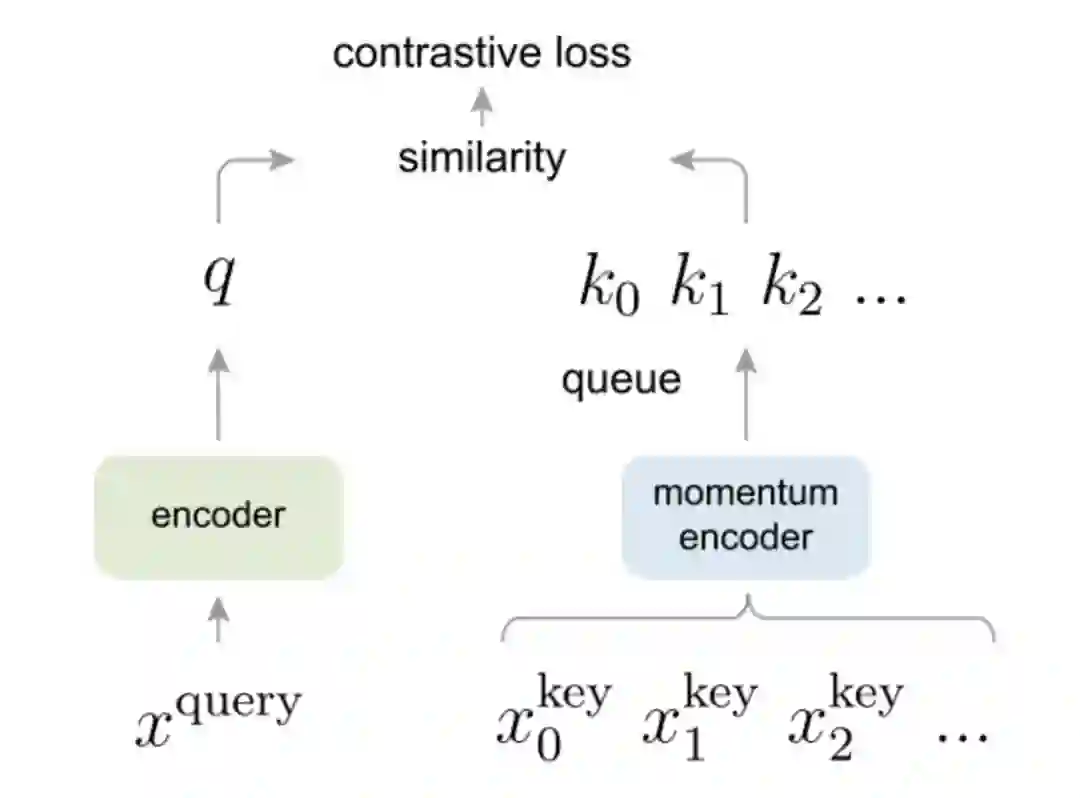
MoCo提出了将memory bank的方法改进为dictionary as a queue,意思就是跟memory bank类似,也保存数据集中数据特征,只不过变成了queue的形式存储,这样每个epoch会enqueue进来一个batch的数据特征,然后dequeue出去dictionary中保存时间最久的一个batch的数据特征,整体上来看每个epoch,dictionary中保存的数据特征总数是不变的,并且随着epoch的进行会更新dictionary的数据特征同时dictionary的容量不需要很大,精髓!
Momentum update
但是MoCo仅仅将dictionary as a queue的话,并不能取得很好的效果,是因为不同epoch之间,encoder的参数会发生突变,不能将多个epoch的数据特征近似成一个静止的大batch数据特征,所以MoCo在dictionary as a queue的基础上,增加了一个momentum encoder的操作,key的encoder参数等于query的encoder参数的滑动平均,公式如下:
和 分别是key的encoder和query的encoder的参数,m是0-1之间的动量系数。
因为momentum encoder的存在,导致key支路的参数避免了突变,可以将多个epoch的数据特征近似成一个静止的大batch数据特征,巧妙!
Shuffling BN
另外,MoCo还发现ResNet里的BN层会阻碍模型学习一个好的特征。由于每个batch内的样本之间计算mean和std导致信息泄露,产生退化解。MoCo通过多GPU训练,分开计算BN,并且shuffle不同GPU上产生的BN信息来解决这个问题。
实验
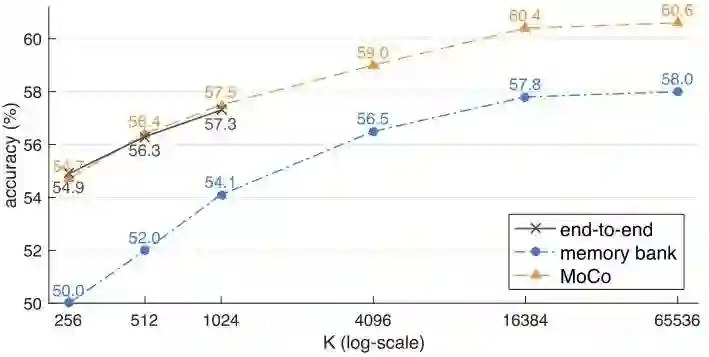
通过对end-to-end、memory bank和MoCo三种方法的对比实验可以看出MoCo算法有着巨大优势。memory bank由于momentum update的是数据,可能训练过程会更加不稳定,导致精度远低于end-to-end和MoCo;end-to-end由于GPU容量大小的限制,导致不能使用更大的batch size;MoCo通过dictionary as a queue和momentum encoder和shuffle BN三个巧妙设计,使得能够不断增加K的数量,将Self-Supervised的威力发挥的淋漓尽致。
MoCov2
MoCov2在MoCov1的基础上,增加了SimCLR实验成功的tricks,然后反超SimCLR重新成为当时的SOTA,FAIR和Google Research争锋相对之作,颇有华山论剑的意思。
SimCLR vs MoCo
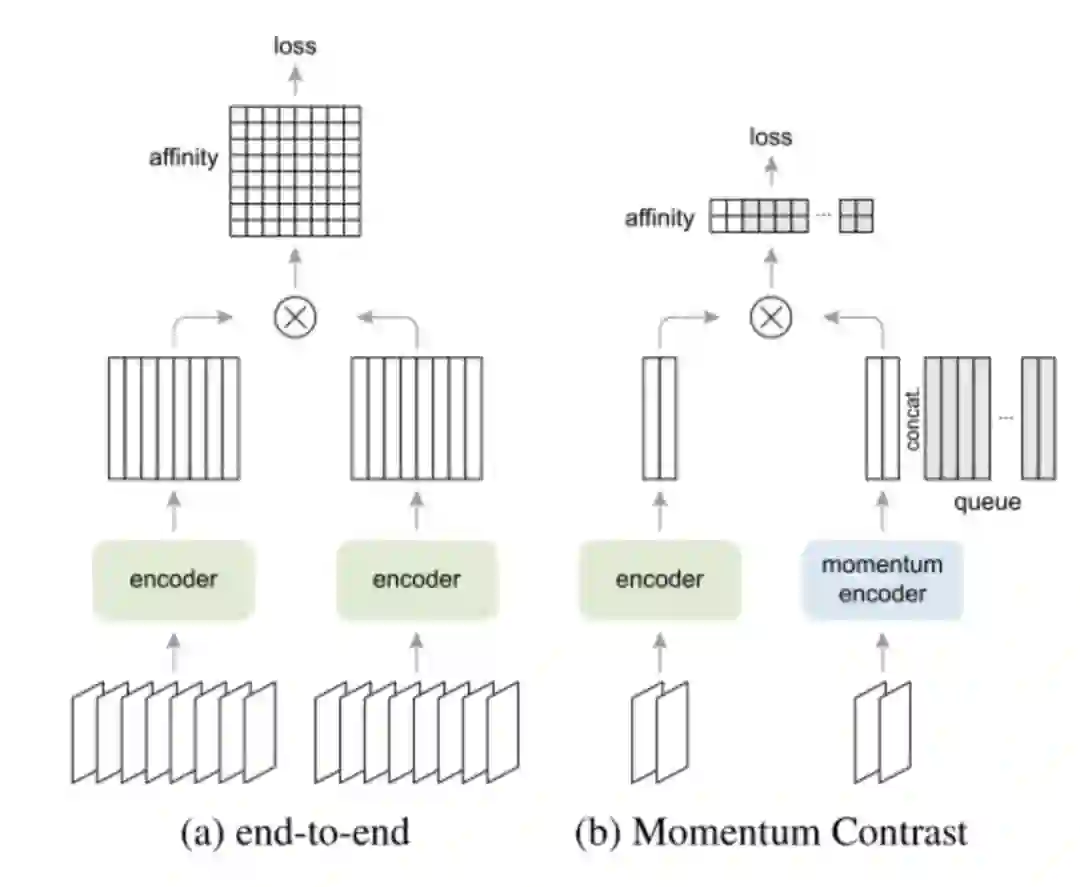
SimCLR其实使用的方法就是MoCo中提到的end-to-end的方法,当然同样存在GPU容量大小限制的问题,但是在Google面前,GPU容量大小算什么限制,TPU我有一打,于是SimCLR通过大batch、大epoch、更多更强的数据增强和增加一个MLP把MoCo拉下了王座,MoCo当然不服气,SimCLR你作弊,老子也要用更多更强的数据增强和MLP! 于是MoCov2以一种实验报告的形式诞生了。
实验
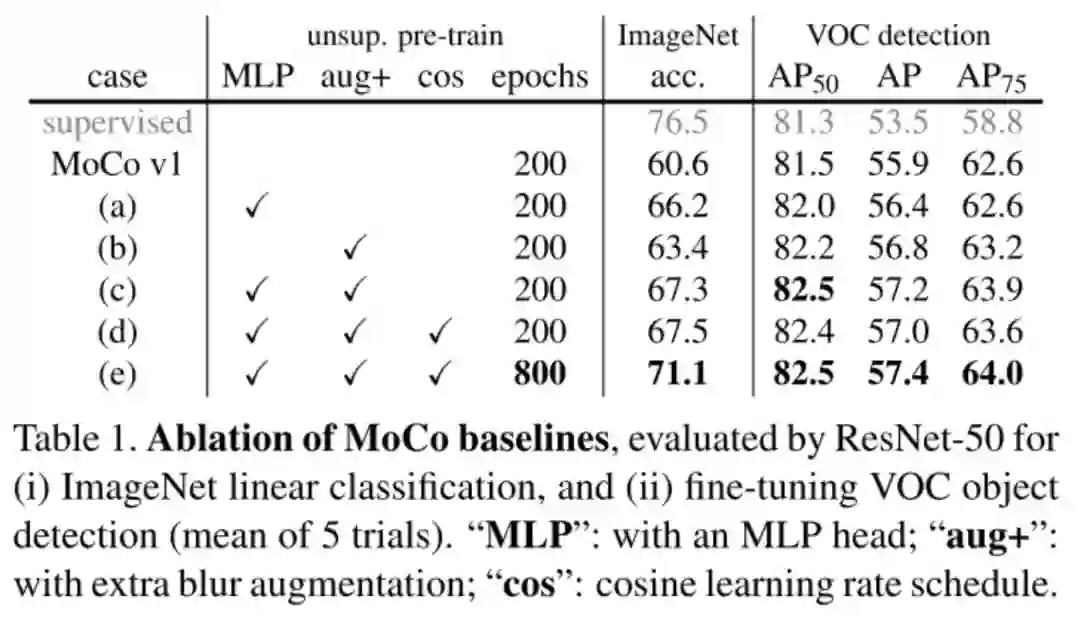
从实验中可以看出,增加MLP、更强的aug、大epoch都能够大幅度的提升MoCo的精度。
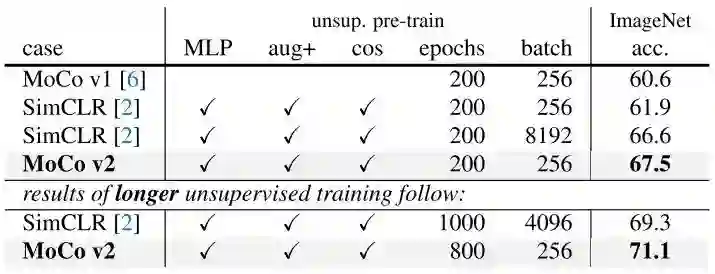
MoCov2相比于SimCLR,在batch size更小的情况下,能够达到更好的效果。
MoCov3
MoCov3的出发点是NLP领域的Unsupervised representation learning使用的架构都是Transformer的,而CV领域的Self-Supervised还在使用CNN架构,是不是可以在Self-Supervised中使用Transformer架构呢?于是MoCov3继续探索Self-Supervised+Transformer的上限在哪里,有金融+计算机内味了。
Stability of Self-Supervised ViT Training
MoCov3将backbone替换成ViT,然后进行实验研究,探索Self-Supervised使用Transformer架构是否可行。然而实验中使用ViT作为backbone会导致Self-Supervised的训练过程不稳定,并且这个不稳定现象无法通过最终迁移预测的结果捕捉到。为了揭示这个不稳定现象是什么导致的,MoCov3使用kNN curves来监控self-supervised的每一个epoch结果。
Empirical Observations on Basic Factors
通过控制变量,主要探究了batch size、learning rate和optimizer三个变量对self-supervised训练过程的影响程度。
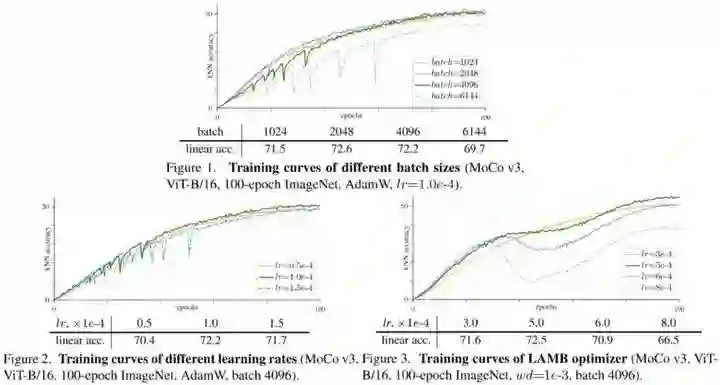
从实验中可以看出随着batch的增大或者lr的增大,kNN accuracy都逐渐出现了dip的情况,并且dip的程度逐渐增加,呈现周期性出现。当使用LAMB optimizer时,随着lr的增加,虽然kNN accuracy还是平滑的曲线,但是中间部分任然会出现衰退。
A Trick for Improving Stability
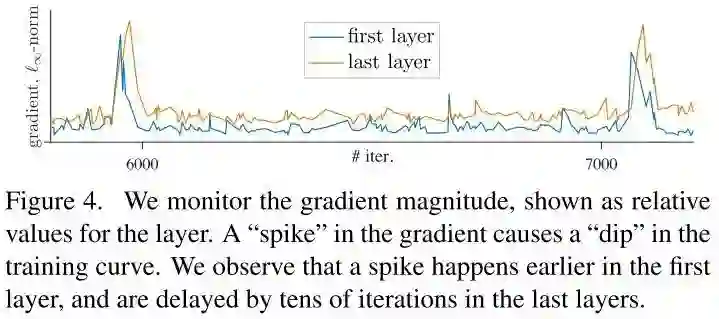
为了探究dip出现的原因,作者进一步画出随着epoch的增加,模型的first layer和last layer梯度的变化情况。发现在训练过程中,不同的layer都会发生梯度突变的情况,导致dip的出现。通过比较各个layer的梯度峰值发现first layer会更早的出现梯度峰值,然后逐层蔓延到last layer。
基于这个观察现象,作者大胆猜测不稳定现象在浅层会更早产生。于是作者进行消融实验比对fixed random patch projectionr和learned patch projection两种情况的结果。
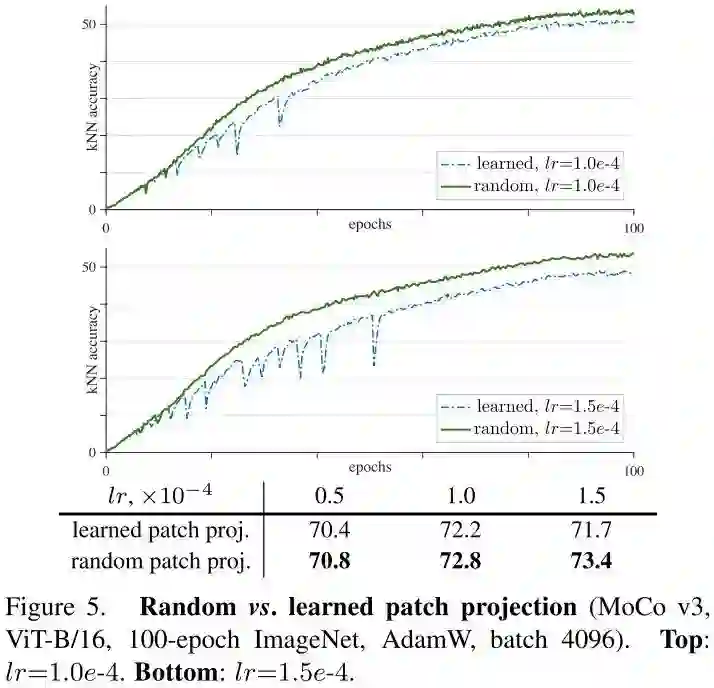
可以看到训练过程中,在不同Self-Supervised算法下,fixed random patch projection比起learned patch projection会稳定许多,并且kNN accuracy也有一定的提升。
作者也提到fixed random patch projection只能一定程度上缓解不稳定问题,但是无法完全解决。当lr足够大时,任然会出现不稳定现象。first layer不太可能是不稳定的根本原因,相反,这个不稳定问题跟所有layer相关。只不过first layer使用的是conv跟后面的self-attention之间gap更大,对不稳定影响更大,first layer固定住更容易处理而已。
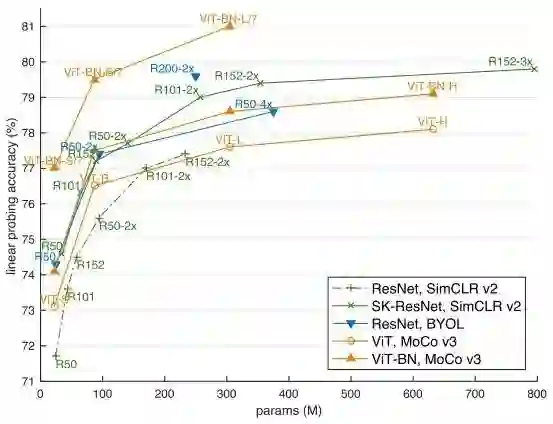
实验结果不出所料的吊打之前的Self-Supervised算法,总体上MoCov3通过实验探究洞察到了Self-Supervised+Transformer存在的问题,并且使用简单的方法缓解了这个问题,这给以后的研究者探索Self-Supervised+Transformer提供了很好的启示。
总结
说一下自己的看法,未来CV很大可能是类似NLP,走无监督预训练,CNN的架构可能支撑不起大量数据的无监督预训练,那么使用transformer作为CV的无监督预训练架构是有必要的。从MoCov3的探索可以看出,FAIR试图从Self-Supervised和Transformer两大炙手可热的方向寻求CV未来的方向,NLP从Transformer -> BERT -> GPT系列,逐渐统治整个NLP领域,MoCo似乎也想复制出NLP的成功路径,从MoCov1 -> MoCov2 -> MoCov3逐渐探索CV领域Unsupervised representation learning的上限,Self-Supervised+Transformer会是CV领域的BERT吗?

最后我想说的是,正如截图所示,虽然叫MoCov3,但其实越来越不像MoCo了,缺少了MoCo最精髓的dictionary as a queue,没有了MoCo的精气神,可以看出FAIR对于精度的无奈与妥协,MoCo最初的精彩或许只能存在于历史之中。
Reference
[1] Momentum Contrast for Unsupervised Visual Representation Learning
[2] Improved Baselines with Momentum Contrastive Learning
[3] An Empirical Study of Training Self-Supervised Visual Transformers
本文亮点总结
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货

