港科大张晓泉教授演讲全文:经济学如何优化AI在金融领域的应用? | CCF-GAIR 2017

7月7日,由中国计算机学会(CCF)主办,雷锋网和香港中文大学(深圳)承办的第二届CCF-GAIR全球人工智能与机器人峰会在深圳隆重开幕。会议第二天,香港科技大学资讯、商业统计及运营学系教授张晓泉(Professor Michael Zhang)带来了题为《经济学家眼中的金融科技创新》的主题演讲。
嘉宾介绍
张晓泉,2006 年获美国麻省理工学院(MIT Sloan School of Management)管理学博士学位,此前在清华大学获得管理学硕士、工学学士和文学学士学位,他的研究领域主要包括营销策略、大数据营销、商业人工智能以及互联网金融。学术论文曾发表在《美国经济评论》、《管理科学》等知名学术期刊。同时他也是招商证券、中国移动、华为等公司和机构的顾问。是美国知名华人社区 MITBBS 创始人,Information Systems Research (信息系统研究)的高级主编,同时还身兼招商证券、中国移动、华为、香港数码港、阿里巴巴旗下湖畔大学等公司和机构的高级顾问。
在本次演讲中,张晓泉教授从AI 需要金融、金融与 AI 相互融合、决策问题等三个方向向与会观众介绍了AI在金融领域的创新与应用。
他认为,科技与金融其实并非鱼与熊掌,自人工智能、大数据、机器学习兴起以来,利用AI技术研究金融问题已屡见不鲜,AI 技术需要经济领域的研究方法和思路,经济学方法也可以助力 AI,应用于研究大数据的产生、传播和处理。雷锋网亦认为,随着 AI 技术的不断完善发展,金融和科技领域的相互融合已经是大势所趋。
在他看来,自古以来,金融市场真正在做的事就是让资源更好地分配,如最早开始用纸币,后来有信用卡,现在是区块链的出现,不同的技术虽然一直往前发展,但其实都是让人类越来越有效的做资源分配。

另外,在商业智能方面,张晓泉教授总结了数据到价值的转化链条:数据-信息-知识-能力-策略-价值。
他表示数据首先要变成信息,信息变成知识,知识变成能力,能力变成策略,策略变成价值,这个链条是非常重要的,每一步不可缺。数据首先通过场景变成信息,信息组织成体系后就变成知识,知识转化成能力,各种能力综合起来构成策略,策略的执行产生价值,这个逻辑非常清楚。真正产生商业智能,不是说我们有了大数据就可以了,也不是说我们有了海量数据就能够立刻做出有价值的东西,其实整个链条是这样的一个逻辑,缺一不可。
再者,他认为,我们在工作生活中有很多的不确定性,这些不确定性可以有不同的统计学描述和意义:
第一个是 certainty,也就是 100% 会实现的。
下一个是 Risk 风险,可以用随机分布函数描述 。
下一个是 black swan,也就是小概率事件,虽然概率小,但会发生。
再下一个是 ambiguity 模糊性,“比如即便我有世界上过去所有股市的数据,我仍然不知道明天会涨还是会跌,不知道都有什么样的影响因素,如果不考虑这样的模糊性而仅仅用概率分布来做预测,就会有非常大的偏差” 。
最后一个是 Radical Uncertainty,恐怖袭击我们知道它会发生,但是不知道什么时候会发生、在哪里发生、怎么发生。“当你有这种 Radica Uncertainty 的时候,你是没法描述这件事的,你没法写一个模型说怎么预测恐怖分子究竟会怎么样去做”。
在这五个级别的问题中,第五级的问题是没办法解决的,第四级的问题我们有没有办法解决,目前正在研究。张晓泉教授觉得大部分的是在第二级层面上解决问题,他认为世界上大多数问题也的确是第二级的。“比如说我要预测这个图片是猫还是狗,其实这个事没有那么多黑天鹅事件,大部分问题可以在第二级能够解决”。
但张晓泉教授同时表示:“有些问题,比如谈到股票市场,可能你就没法在第二级解决,你即便知道世界上所有信息,你无法预计明天股票的概率。这就超出了第二级别的范畴,这是学术界在努力的一个方向,未来会对整个行业有巨大的意义”。
以下是张晓泉教授的演讲全文,雷锋网作了不改变原意的编辑:
金融市场怎么能够通过AI的影响而变得更有效?
非常感谢。我今天主要讲一下AI和经济学有什么关系。虽然隔行如隔山,但他山之石也可以攻玉。如果你了解经济学在做什么,AI将会变得非常有意思。
AI来袭,金融市场出路在哪里?
最近很多媒体都在传播说AI要代替人类。这个事情在商学院也讨论的非常多,未来社会将会变成什么样?我们以后是不是就失去工作了?
有条新闻是说律师需要36万小时的工作,被一个软件可以在几秒钟之内做掉;另外,包括说投资银行的分析师马上是夕阳行业,四大会计事务所现在也开始做AI了。
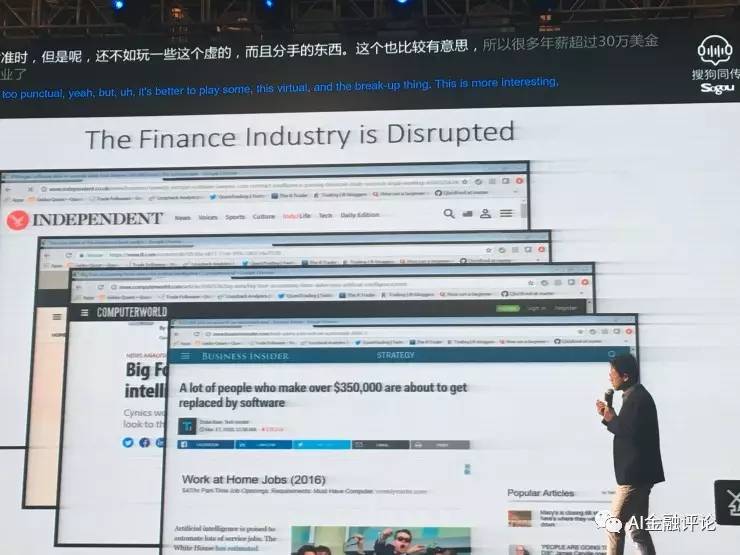
还有新闻说很多年薪超过35万美金的人很快要失业了,换算成人民币大概是200万元人民币。所以如果在座的谁的年薪超过200万就快要失业了。(观众笑)笑的人可能都是年薪不到200万的,不过你失业的机会可能更快。
纽约大学金融系的系主任前段时间到科大做讲座。他说,传统的审计、律师、金融等行业在未来的5到10年内都会受到非常大的影响。未来10年内,银行和股市要不就关闭、要不就转型;到了2030年,学校里的金融系和会计系都要关掉。他说的非常恐怖,但如果细想一下,如今科技的确对金融造成了不小的影响。

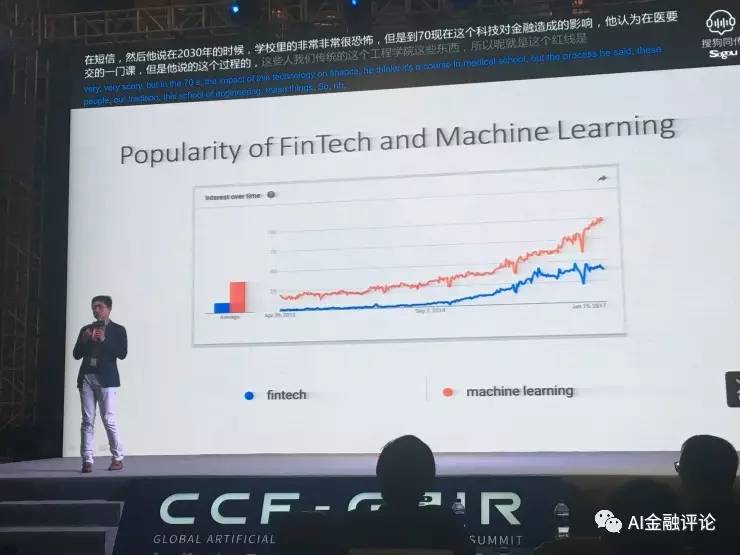
他认为,在商学院里面唯一要教的一门课就叫Fintech。如果在谷歌上搜索,红线是machine learning,蓝线是fintech。这两条线相关性很高,fintech底层是什么?应该就是machine learning。在2006年以前,就有很多公司解决了支付等一系列问题,再往后,每年都有非常多的fintech公司出现。从这个过程中可以发现,靠前的公司让金融工作变得更加简单,而后面的公司则是让金融变得更加智能,越来越多的公司都准备用人工智能来解决现存的问题。
到后来我们发现,会计、认证、传统的银行业务、信用、贷款、投资、保险等这些行业都没有变,改变的是如何利用解决问题的方案,从而让问题变得更加简单、让事情变得更加高效。
金融市场的核心问题是让资源配置变得更加有效。现在很多人认为技术让事情变得高效的同时,是否就改变了人的主导地位,或者根本就不需要人类了。这张图是去年MIT Technology Review杂志封面图,一开始人在用机器,但是后来机器变得越来越强大了,后来人只要修一下机器就好了,最后机器修机器,不需要人了。这个Jobless Society到底对我们的改变有多大,我一会儿会和Bill Roscoe教授有讨论的环节,我们到时候再讨论这个问题。

但是我个人认为,Jobless Society出现的几率不大,过去100年间,有过很多类似的技术出现,每次都有论调认为人类无工作可做。其实不然,昨天汪军博士引用了笛卡尔的一句话,他说机器是无法有意识的。其实毕加索也说了一句话,毕加索在大概100年前说,计算机是没有用的,它只能给我们答案。我觉得这句话非常对,为什么呢?因为我们解决问题的前提是提出问题,而计算机是无法提出问题的。只要计算机一天无法自己提出问题,人类还是有办法去做工作,去提出问题,让计算机帮忙去解决。
我们现在能看到一些趋势,这些趋势加强了学术界和业界的紧密融合。举例说:
一、做研究和应用,在之前的五到十年,很多超前的研究只会出现在大学的实验室中,而现在,很多业界做的东西和想法已经非常接近大学里研究的课题,这说明,学术界和业界正在加强合作,公司愿意和学术界的教授进行合作得到研究结果,而教授也能得到一些数据和支持,这是非常良性的循环。大家也可以看到很多教授变成公司管理者,这非常有意思,它可以让前沿的想法能够立刻在实际场景中得到应用。

二、金融和科技的融合,如果现在去任何的金融机构,都会有专门的金融科技部门;很多技术公司,也会有一个金融部门。在这之前,银行家和工程师是两个毫无交集的职业,但在未来,这两者将会有非常多的合作。
面对人工智能的能力界限,经济学可以如何助力?
在商业智能的产生中,有一本著名的大数据的书,里面提到的两个观点:
第一个观点是大数据4个V,但我不这么认为,因为你只有海量多样的数据是毫无作用,最终需要从数据中产生一个价值,而价值才是数据的核心;
第二个观点是当数据非常多的时候,我们就不需要研究因果关系了,因为我们有非常多的数据,就可以直接用数据来说话。当然这个我也非常不同意,我待会会讲。

数据将怎么变成价值?
大家有没有想过,数据将怎么变成价值?数据首先要变成信息,信息变成知识,知识变成能力,能力变成策略,策略才能变成价值。这整个链条是非常重要且紧密的,每一步都不可或缺。另外,逻辑也非常重要。真正产生商业智能,不是说有了大数据就能够立刻做出有价值的东西,在经济学中,我们更关心的是怎么解释一件事情,一件事情发生底层的机理是什么。预测分类和运作机理如何能结合起来,可以做出很多有意思的东西。

比如说,什么情况下能够做非常好的预测而做不了很好的解释?地心说。太阳明天会升起,每天预测都是准的。但是地心说这个理论是错的,我们现在知道地球围绕太阳转,这个理论用来预测是完全OK的,但是没有解决底层的机理问题;反过来有没有一个理论能够做很好的解释而做不了很好的预测呢?进化论。我们认为它能够很好的解释为什么有人,人为什么是从猿猴进化而来,但是它没法做预测,你不知道明天人会变成什么样。其实这两个问题非常不同,人工智能专家可能更多做的是左上角的工作,经济学家专家做的是右下角的工作,问题是怎么把这两个整合在一起。
现在说的Decision making还有很多不确定性。举例说,太阳明天会升起,这个现象100%会实现。但下一个层面就有了一些风险,比如预测股市,我们都会有一个大概预测,可以说股市明天七成会涨、这就是所谓的Risk;或者说新研究一种新药,70%的病人吃了会康复,30%的人吃了没有效果,这都是Risk。其实现实生活有非常多的Risk是无法描述的,比如黑天鹅事件,有0.0001%的可能性明天股市会跌50%。或者这个药吃了后有0.000001%的概率病人会挂掉。在这种情况下,即便有了大数据也无法做人工智能的推断。
再往下是Ambiguity模糊性,模糊性是什么?我知道明天股市要不就会涨、要不就会跌,但是什么百分比说不出来。即便有世界上过去所有股市的数据,仍然不知道明天会涨还是会跌,因为有很多因素会影响这个结果。在这种情况下,怎么样用一种模型去描述这种现象成为很多金融专家正在做的事情。问题总共分为五个级别,第五级的问题是没办法解决的,第四级在经济学中可以试着解决。而大部分的问题都归属第二级。比如说预测图片是猫还是狗,这个事没有那么多黑天鹅事件;但当谈到股票市场,可能就没法在第二级解决。
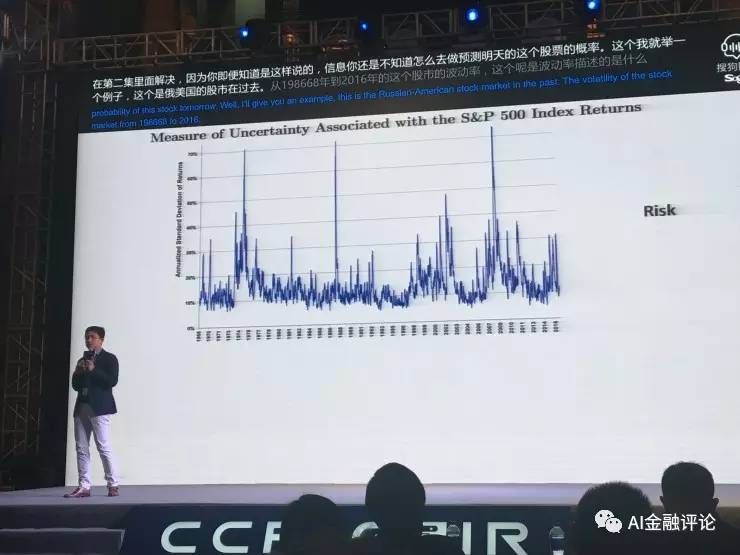
举个例子,这是美国股市在过去从1968年到2016年的波动率。这个波动率就是Risk,波动率讲的就是股票市场有多大的风险。如果你用传统的方法用所谓的标准差去描述,你能看到有几个现象:第一个是1987年10月19日有一个非常高的Risk那是美国股灾。再往后比较高的时候是2002年的时候,也是有非常强的波动性,这是当时互联网泡沫破裂的时候。再往后有一个非常高,2007、2008年次贷危机的时候。传统我们对股市风险的描述是根据风险的预测,而风险预测底层的假设是我们能够写出一个统计概率出来的。
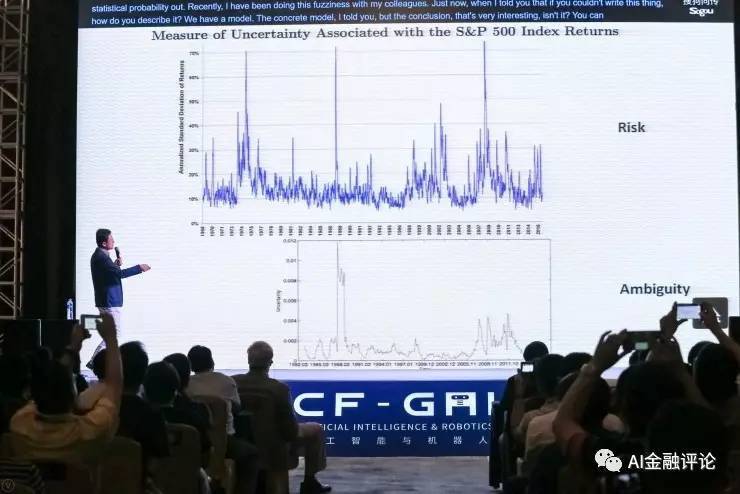
但如果没有这些,该怎么描述呢?最近我跟我的同事在做模糊性预测模型,具体模型我就不讲了,但是结论是非常有意思的。大家可以对比这两张图,在排除了之前认为的风险之后,剩下的模糊性有多大。1987年股灾残存的模糊性也非常大,你把这些风险已经考虑了之后,仍然有非常高的模糊性。但是2002年的时候,股市的波动其实在我们计算出来的模糊性上反映就不大,这表示什么呢?反过来我们再来解释,1987年的股灾是非常严重的,而2002年所谓的股灾没有那么严重,因为底层有技术的推动,其实从未来来看,中间的模糊性没有太大。再看2007、2008年,比1987年的还是低很多。
这件事也就是说明,如果只是从数据出发,没法做出因果关系的,只做machine learning、data, 但是你还是没法发现底层的机制的问题。经济学的insight就是希望把risk没法解决的问题能够用模糊性去描述。
好好算数:经济学助力AI金融应用的原理
下面我就讲AI到底和经济学有什么关系。AI里面有一个非常大的问题是overfitting。当数据有限的时候做了无数次的训练,得出的效果非常好,但是你的model不是一个真正的模型。图片上一共有12个点,这12个点如果你用一个线性模型做,线性模型是直线。
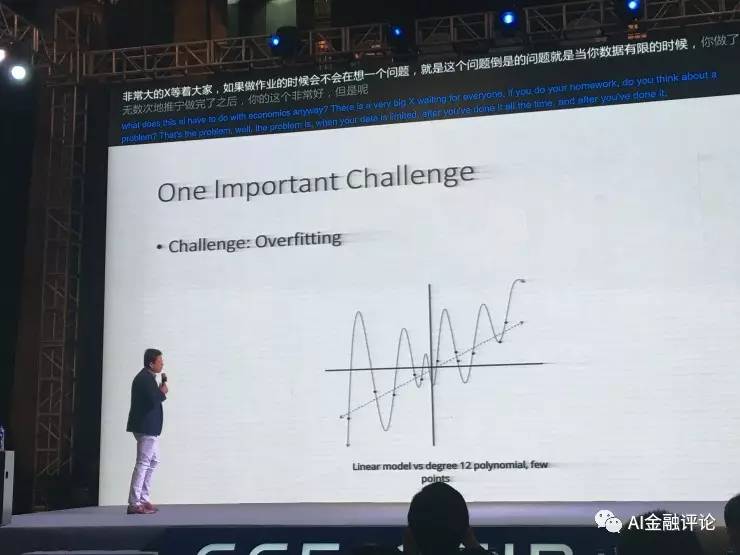
如果做一个十二元方程也可以非常精准地把所有点都经过。但是其实十二元方程效果不是很好,因为定一个中间点的时候,应该如何预测呢?如果是线性模型,表现会比十二元方程的模型表现好很多,是因为十二元方程做了overfitting,怎么样避免overfitting 有很多办法,那么有没有一个办法非常精确的告诉我,你的模型是对的。
现在很多model还没有解决底层机制的问题,但从数据出发做预测,就类似于我们给 3岁小孩一把机关枪,有时候能打中、有时候打得挺好的,但是很多时候你会有很多错误,这个怎么避免?我们在做machine learning的时候,我们能不能用经济学的原理解决问题。

financial market是怎么运作的?投资人把钱投到一个公司,公司有相应回报,可能是业绩回报或者分红。中间我们需要媒体帮助投资人知道这个公司做得怎么样,而这其中很多环节可以用人工智能的办法去帮助我们增加它的有效性。
Media有两种,第一种是传统的媒体,第二种是所谓的社交媒体。传统媒体包括刚才讲的互联网行业分析师、传统的新闻媒体。社交媒体像雅虎、头条、微博、微信、推特等等所有都是social的,其实这些媒体的影响也非常大。
投资人有两种,一种是散户,只是在股票市场做一些简单投资,但是跟公司没有任何关系,也对公司不了解的人。还有一种是机构投资者,另外则是公司内部的高管,我们把他们合在一起叫做Insiders。这是我认为这个是最简单的对于金融市场的描述,其实每个链接都是可以作为互联网金融的idea来优化的。
而这能够回答什么问题?美国在2013年的时候,Associate Press账号被黑,在推特上发了一个假信息,他说白宫有两次爆炸,奥巴马受伤。这件事说完之后3分钟之内,美国股市的市值就蒸发了1千多亿美金,如果你去要看它的基本面,不可能有1千亿的变化,所以我们认为,这3分钟之内发生的事情,一定是跟推特相关的。
为什么呢?这里面能看到两件事,第一件事是说Associate Press的社交媒体推特还是很有影响的, 它真的能够对股票市场造成很大的影响,不管新闻是真的还是假的。第二,你能看到非常多机器做交易,如果是人我们会判断一下,这个事是真的还是假的,奥巴马是不是真的受伤了。但是机器不会,机器写了一些固定的算法,它会认为奥巴马受伤一定是坏事,所以它就开始做做交易卖出股票。这里面1千多亿的市值蒸发很大部分是由于机器做交易造成的,所谓的量化的算法。
再比如维基百科,你能看到在发布年报前后的时间内,大家对Intel维基百科的页面访问翻倍,从2000多次变到4000多次,说明大家对社交媒体的关注度是非常高的。这个也是我们做研究发现有意思的事,发布年报的时候有两种情况,第一是公司业绩非常好,第二是没有那么好。当你的业绩不好的时候,就是一条蓝线,和你业绩好的时候比较,平均来讲当年报业绩不好的时候,公司不愿意发推特,他们发得比较少,但是可以看到离年报发布的前几天的时候,突然一下子暴涨起来,这个时间差不多是4天。
这个分析我们得到一个什么结论呢?当业绩好的时候,这些公司都在说同样一件事,说我们的业绩好,今年股票的回报大概是多少,我们花了多少钱,我们在明年有什么计划,这些都是非常好的跟公司业绩相关的推特。
这时候可以反推,当你还不知道具体情况时,你看到推特上的内容就可以进行一些辨别。根据这个便可以做模型训练,当你看到它的历史曲线的时候,你发现突然有一家公司在年报发布附近的时候突然开始说一些莫名其妙的话,说明他今年的表现不一定很好。这是可以做成训练模型去看的。

如何构建不确定性因果关系模型?
那么如何建立因果关系呢?经济学里有个方法叫工具变量,举个例子说,假设我们想知道X是不是影响Y,比如说X你是否抽烟,Y是你有没有肺癌。我们会搜Data,这个人抽烟有肺癌,那个人抽烟没有肺癌,搜了一堆的数据,得到的结论是说抽烟导致肺癌。但是这个是不是真的呢?不一定,因为还有可能是你看不到的一个现象, 这个现象导致你既抽烟又容易肺癌。或者说你看不到的U决定了这些人几遍不抽烟也会得肺癌。比方说这是地域的原因,又比如说住在某个省的人更容易抽烟、更容易得肺癌,跟他抽不抽烟没关系。也有可能是基因的问题,有的人是生下来就会得肺癌,抽不抽烟也会得肺癌,这些人碰巧另外一个基因决定他又容易抽烟。当你有这种现象的时候,你是没法说抽烟是否能导致肺癌的。
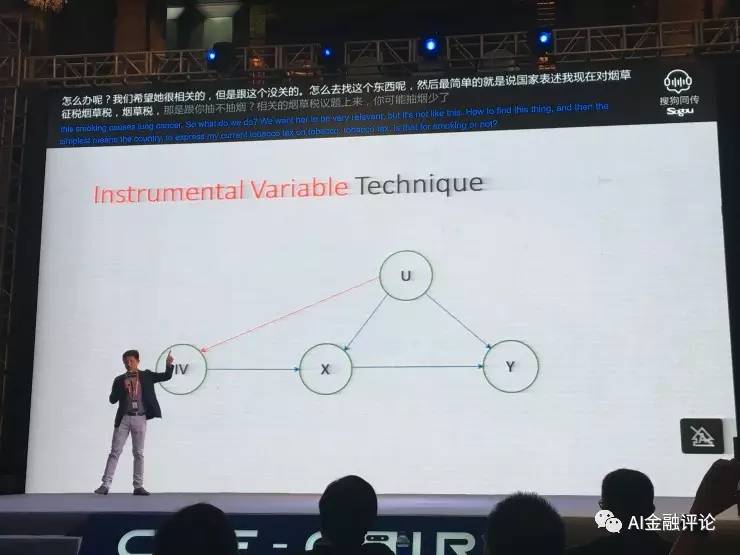
怎么办呢?我们就会找一个工具变量,我们希望它和抽不抽烟是相关的,但是跟看不到的现象基因、地域是没关的。怎么找到这个东西呢?比如说最简单的,国家现在要征收烟草税,烟草税是跟你抽不抽烟相关的,烟草税一提上来,可能你抽烟就变少了。但是烟草税跟你的地域是没关的,因为这是国家政策,所有地域都会受影响,跟你的基因是没关的。这个就叫工具变量,当你有这样的一个体系之后,你就能分析出来X和Y的关系,因果关系就能出来。如果我们的machine learning你只关注在X到Y这条线上,有可能你最后的结论是错的。即便发现一个正相关,得到的结论也是错的。但是如果你知道怎么用工具变量做这件事的时候,你就解决了之间的因果关系。

大家经常讲Human in the loop,我觉得应该要有Econ in the loop的概念。 如果你用Econ in the loop的idea来做,用因果关系的分析能够结合在machine learning的model里面,就可以做非常好的研究,得到很好的结果。
谢谢大家!
编辑:张栋