©PaperWeekly 原创 · 作者|周树帆
学校|上海交通大学硕士生
研究方向|自然语言处理
今天聊一篇 FAIR 发表在 ICLR 2020 上的文章:Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring。
![]()
论文标题:Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
论文来源:ICLR 2020
论文链接:https://arxiv.org/abs/1905.01969
![]()
和一些花里胡哨但是没有卵用的论文不同,这篇文章可谓大道至简。该文用一种非常简单但是有效的方式同时解决了 DSSM 式的 Bi-encoder 匹配质量低的问题和 ARC-II、BERT 等交互式的 Cross-encoder 匹配速度慢的问题。
![]()
众所周知,常见的搜索、检索式问答、自然语言推断等任务,它们本质上都是一种相关性匹配任务:给定一段文本作为 query,然后匹配出最为相关的文档或答案然后返回给用户。
目前主流的文本相关性匹配架构有两大类:以 DSSM 为代表的 Siamese Network 架构、以及形如 ARC-II、ABCNN 或 BERT(基于 Self-Attention)的交互式匹配架构。
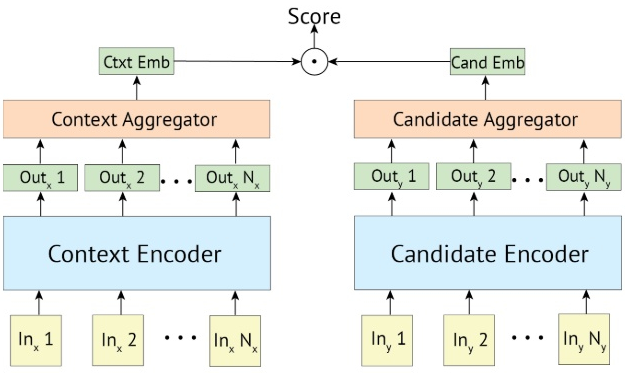
如图 1 所示,Siamese Network 式(本篇文章又称其为 Bi-encoder)的匹配方案会利用 2 个网络分别将 query 和 candidates 编码成
![]() 和
和
![]() ,最后再通过一个相关性判别函数(通常为 cosine)计算两个 vec 之间的相似度。
这种方案的最大特点就是 query 和 candidates 直到最后的相关性判别函数时才发生交互,所以会对模型的匹配性能产生一定的影响。
但是这种完全独立的编码方式使得我们可以离线计算好所有 candidates 的向量,线上运行时只需计算 query 的向量然后匹配已有向量即可。总的来说,这种方案匹配速度极快,但是匹配质量不能达到最佳。
,最后再通过一个相关性判别函数(通常为 cosine)计算两个 vec 之间的相似度。
这种方案的最大特点就是 query 和 candidates 直到最后的相关性判别函数时才发生交互,所以会对模型的匹配性能产生一定的影响。
但是这种完全独立的编码方式使得我们可以离线计算好所有 candidates 的向量,线上运行时只需计算 query 的向量然后匹配已有向量即可。总的来说,这种方案匹配速度极快,但是匹配质量不能达到最佳。
![]()
▲ 图1. Siamese Network(本篇论文又称其为Bi-encoder)
1.2 交互式匹配
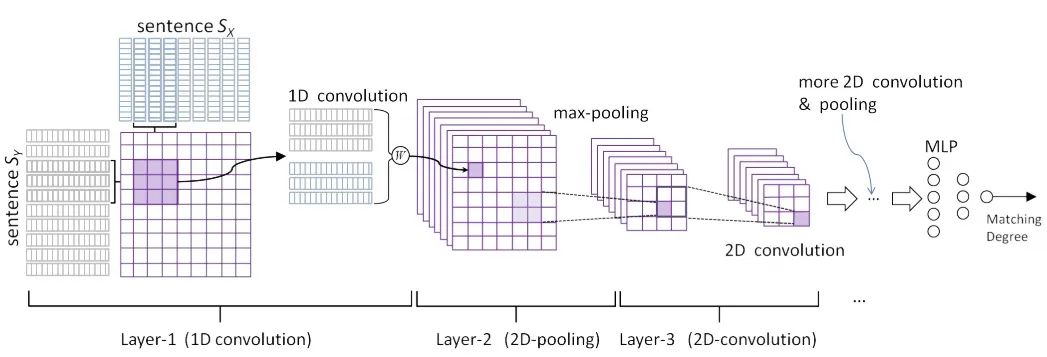
如图 2 所示,交互式匹配(本文记作 Cross-encoder)的核心思想是则是 query 和 candidates 时时刻刻都应相互感知,相互交融,从而更深刻地感受到相互之间是否足够匹配。
早期的交互方案如 ARC-II、ABCNN 等会计算
![]() 和
和
![]() 之间的word embedding相似度、Q、C 分别过 RNN 之后的
之间的word embedding相似度、Q、C 分别过 RNN 之后的
![]() 、
、
![]() 之间的相似度,最后再用一些 CNN 之类的方法整合结果,然后用 MLP 做二分类判别是相关还是不相关。
之间的相似度,最后再用一些 CNN 之类的方法整合结果,然后用 MLP 做二分类判别是相关还是不相关。
![]()
▲ 图2. 交互式匹配示意图(图中为ARC-II)
另外在 BERT 兴起之后,如图 3 所示般将 query 和 candidate 拼成一句话,然后利用 self-attention 完成 query 和 candidate 之间的交互的模型也大量涌现,并且取得了非常显著的成果。本篇论文实现的 Cross-encoder 也是基于图 3 的架构。
相较于 Siamese Network,这类交互式匹配方案可以在 Q 和 C 之间实现更细粒度的匹配,所以通常可以取得更好的匹配效果。
但是很显然,这类方案无法离线计算 candidates的表征向量,每处理一个 query 都只能遍历所有 (query, candidate) 的 pairs 依次计算相关性,所以这类方案相当耗时(当然也有很多提速手段,不过那不是本文的重点)。
![]()
▲ 图3. Cross-encoder
![]()
Poly-Encoder
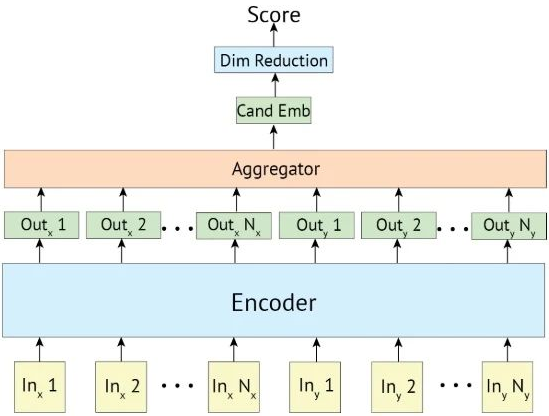
Bi-encoder (Siamese Network) 和 Cross-encoder(交互式网络)都有各自显著的优点和缺点,而本文提出的 Poly-encoder 架构同时集成了两类方案的优点并避免了缺点。
![]()
▲ 图4. Poly-encoder
Poly-encoder 如图 4 所示。Poly-encoder 的思想非常简单(简单到论文里仅用了 2 段文字),按我的个人理解描述:
Bi-encoder 的主要问题在于它要求 encoder 将 query 的所有信息都塞进一个固定的比较 general 的向量中,这导致最后
![]() 和
和
![]() 计算相似度时已经为时过晚,很多细粒度的信息丢失了(e.g. query 为“我要买苹果”),所以无法完成更精准的匹配。
这就有点像 word2vec 静态词向量:即使一个词有多种语义,它的所有语义也不得不塞进一个固定的词向量。
为了克服这个问题,Poly-encoder 的方案就是每个 query 产生 m 个不同的
计算相似度时已经为时过晚,很多细粒度的信息丢失了(e.g. query 为“我要买苹果”),所以无法完成更精准的匹配。
这就有点像 word2vec 静态词向量:即使一个词有多种语义,它的所有语义也不得不塞进一个固定的词向量。
为了克服这个问题,Poly-encoder 的方案就是每个 query 产生 m 个不同的
![]() ,接着再根据
,接着再根据
![]() 动态地将 m 个
动态地将 m 个
![]() 集成为最终的
集成为最终的
![]() (其实有点像封面图那样,有一点用 m 个向量组合出最终的 Low Poly(baike.baidu.com/item/Lo)化向量的味道),最后再计算
(其实有点像封面图那样,有一点用 m 个向量组合出最终的 Low Poly(baike.baidu.com/item/Lo)化向量的味道),最后再计算
![]() 和
和
![]() 的匹配度。
的匹配度。
![]()
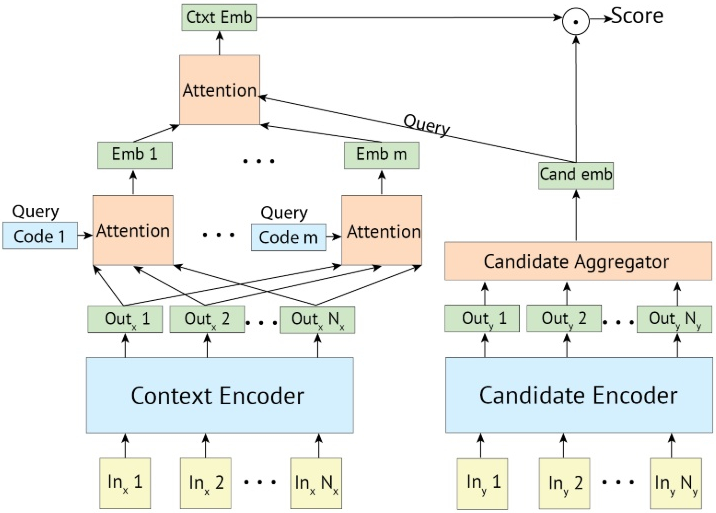
论文中的 ctxt 指代 context,相当于 query;cand 指代 candidate。上面这段论文建议我们可以随机初始化 m 个通过 dot product 计算 attention,从而将长度为 N 的 context 编码成 m 个向量
![]() (即
(即
![]() )。
)。
![]()
我们再用 candidate 对应的向量
![]() 计算 m 个
计算 m 个
![]() 的 attention,进而得到最终的
的 attention,进而得到最终的
![]() 。
很显然,Poly-encoder 架构在实际部署时是可以离线计算好所有 candidates 的向量的,所以只需要计算 query 对应的 m 个
。
很显然,Poly-encoder 架构在实际部署时是可以离线计算好所有 candidates 的向量的,所以只需要计算 query 对应的 m 个
![]() 向量,再通过简单的 dot product 就可以快速计算好对应每个 candidate 的“动态的”
向量,再通过简单的 dot product 就可以快速计算好对应每个 candidate 的“动态的”
![]() 向量。
看起来 Poly-encoder 享有 Bi-encoder 的速度,同时又有实现更精准匹配的潜力。我们通过实验来一探究竟。
向量。
看起来 Poly-encoder 享有 Bi-encoder 的速度,同时又有实现更精准匹配的潜力。我们通过实验来一探究竟。
![]()
实验
本文选择了检索式对话数据集 ConvAI2、DSTC 7、Ubuntu v2 数据集以及 Wikipedia IR 数据集进行实验。
训练 Bi-encoder 和 Poly-encoder 时由于这两类模型的特性,负采样方式为:在训练过程中,使用同一个 batch 中的其他 query 对应的 response 作为负样本(如果难以理解,可以稍后结合复现代码来理解)。
而 Cross-encoder 的负采样方式为:在开始训练之前,随机采样 15 个 responses 作为负样本。
3.1 检索质量
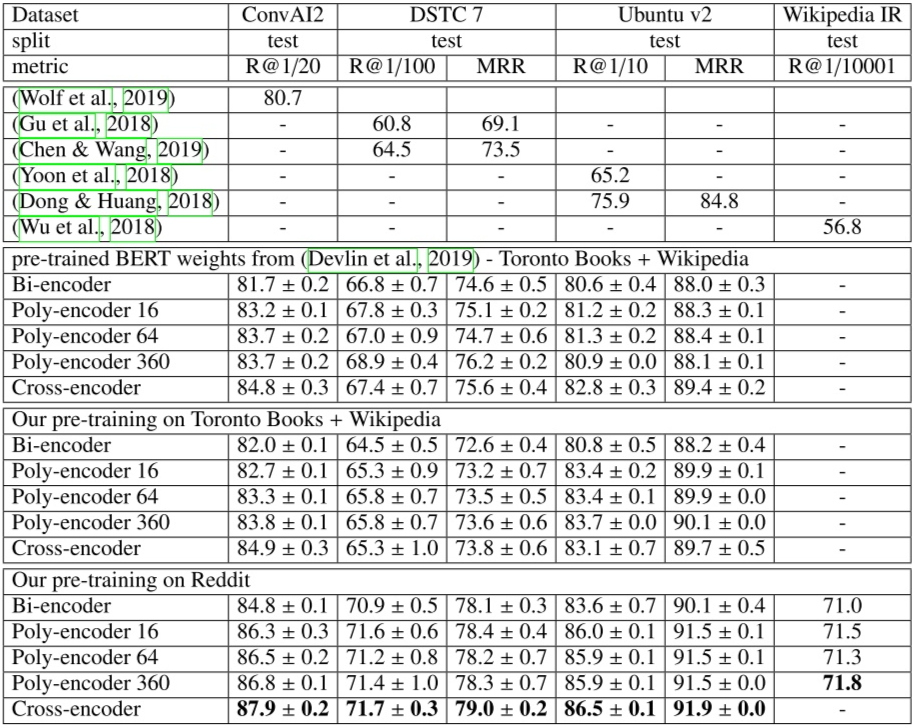
图5给出了一些 baseline 模型以及本文的基于预训练 BERT 的 Bi-encoder、Poly-encoder 以及 Cross-encoder 在各个数据集上的表现。
当然我们很容易发现,本文的所有模型由于以预训练的BERT为基础,他们的表现都要显著超出不使用 BERT的那些 baseline 们。所以我们只需要关注 Bi、Poly 和 Cross 三种架构之间的表现差异即可。
实验结果表明即使仅增设少数几个 code(用于计算 attention 产生向量),Poly-encoder 的表现也要远优于 Bi-encoder。
实验结果还表明,Poly-encoder 的表现会随着 code 个数的增加而逐渐增加,并且慢慢逼近 Cross-encoder 的结果(个人认为 Cross-encoder 的表现应该是 Poly-encoder 的上界,不过偶尔也可能会因为一些偶然因素导致 Poly-encoder 反超 Cross-encoder 的情况)。
另外,为了体现 Cross-encoder 在速度上的局限性,作者还很有意思地跳过了 Cross-encoder 在 Wikipedia IR 上的测评并写到:“In addition, Cross-encoders are also too slow to evaluate on the evaluation setup of that task, which has 10k candidates”。
![]()
▲ 图5. 模型表现汇总
3.2 检索速度
图 5 的实验结果已经表明 Poly-encoder 的检索质量明显优于 Bi-encoder 架构,且能逼近 Cross-encoder 架构的效果。剩下的关键问题就是 Poly-encoder 是否会显著增加检索耗时?
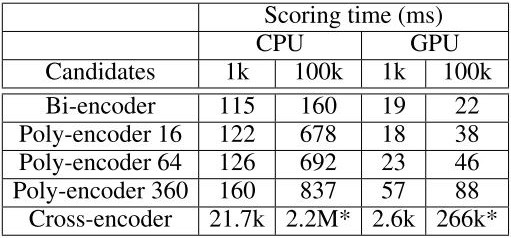
图 6 给出了各模型在 ConvAI2 数据集上的检索耗时。
Bi-encoder 理所当然是最快的架构,当 candidates 为 100k 时,在 CPU 和 GPU 环境下其检索耗时分别为 160ms 和 22ms;而 Cross-encoder 显然是最慢的一个:同样实验条件下其检索耗时分别约为 2.2M (220 万) ms 和 266K (26.6 万) ms。
反观 Poly-encoder,以 Poly-encoder 360 为例,该模型可以达到远超 Bi-encoder、接近甚至反超 Cross-encoder 的检索质量,但其检索速度确比 Cross-encoder 足足快了约 2600-3000 倍!
![]()
▲ 图6. 各模型在ConvAI2数据集上的检索耗时
![]()
论文小结
总的来说,本文的出发点就是希望找到一个速度快但质量不足的 Bi-encoder 架构和质量高但速度慢的 Cross-encoder 架构的折中。
本文提出的 Poly-encoder 的核心思想虽然非常简单,但是却十分有效(亲测),确实在很多场景下可以作为 Bi-encoder 的替代,甚至在一些对速度要求较高的场景下可以作为 Cross-encoder 的替代。
方案简洁固然是本文的一大优点,不过这也给未来的研究留下了空间。相信未来很快就会有许多基于 Poly-encoder 的改进版出现。
![]()
复现结果分享
在读完论文后的第一时间,我就尝试了复现工作。我的复现结果表明,Poly-encoder 不管是收敛速度还是模型上限,都要显著优于 Bi-encoder,且 Poly-encoder 几乎不增加额外的显存负担,对训练速度的影响也几乎可以忽略。完整代码位于:
https://github.com/sfzhou5678/PolyEncoder
Poly-encoder 的实现非常简单,只需在 Bi-encoder 的基础上略加修改即可。接下来我将介绍实现 Poly-encoder 的核心代码。
我们首先用 nn.embedding 来作为 m 个 poly_codes 的值, 然后 forward 的时候根据m的值产生对应个数的 poly_codes,这些 codes 将用于计算不同的 attention weights,以产生多个 vec_ctxt(即 vec_q)。
这里我令 poly_code_ids+=1 是为了让 context_encoder 和 response_encoder 对称,所以把 0 号 id 留给了 response_encoder。
self.poly_code_embeddings = nn.Embedding(self.poly_m + 1, config.hidden_size)
poly_code_ids = torch.arange(self.poly_m, dtype=torch.long, device=context_input_ids.device)
poly_code_ids += 1
poly_code_ids = poly_code_ids.unsqueeze(0).expand(batch_size, self.poly_m)
poly_codes = self.poly_code_embeddings(poly_code_ids)
接着,我们用这些 poly_codes 和 bert 的输出做 attention 得到 context_vecs:
def dot_attention(q, k, v, v_mask=None, dropout=None):
attention_weights = torch.matmul(q, k.transpose(-1, -2))
if v_mask is not None:
attention_weights *= v_mask.unsqueeze(1)
attention_weights = F.softmax(attention_weights, -1)
if dropout is not None:
attention_weights = dropout(attention_weights)
output = torch.matmul(attention_weights, v)
return output
state_vecs = self.bert(context_input_ids, context_input_masks, context_segment_ids)[0] # [bs, length, dim]
context_vecs = dot_attention(poly_codes, state_vecs, state_vecs, context_input_masks, self.dropout) #[bs, m, dim]
得到 response_vec 的方式类似,不再赘述。最后,只需根据 response_vec 给 context_vecs 做一次 attention 得到 final_context_vec 即可:
if labels is not None:
responses_vec = responses_vec.view(1, batch_size, -1).expand(batch_size, batch_size, self.vec_dim)
final_context_vec = dot_attention(responses_vec, context_vecs, context_vecs, None, self.dropout)
在 loss function 方面,虽然我们可以在准备数据的时候就为每个样本做 N 次负采样,但是在 Bi-encoder 或 Poly-encoder 这种产生 response_vec 和 query 完全独立的场景下,可以将同一个 batch 内的其他 response 作为负样本来避免重复计算,有效提升训练效率。
具体实现时,我们计算 context_vec_i 和 response_vec_j 的点乘,从而产生一个 [bs, bs] 的余弦相似度矩阵,这个相似度矩阵就是 context_vec_i 和 batch 内的每一个 response_vec 的相似度。
由于我们的目标是最大化 context_vec_i 和对应的正样本,即 response_vec_i 的相似度,所以我们可以做一个 [bs,bs] 的单位矩阵作为 label,最后应用交叉熵产生训练用的 loss。
我的代码中在 dot_product 后面还乘了系数 5,这就是一个用于缓和 softmax 取值的参数,其具体取值通常需要实验来确定,这里的 5 只是我的经验值。
# 因为要算余弦相似度,所以给向量都归一化一下,之后直接点乘即可
context_vec = F.normalize(context_vec, 2, -1)
responses_vec = F.normalize(responses_vec, 2, -1)
responses_vec = responses_vec.squeeze(1)
dot_product = torch.matmul(context_vec, responses_vec.t()) # [bs, bs]
mask = torch.eye(context_input_ids.size(0)).to(context_input_ids.device)
loss = F.log_softmax(dot_product * 5, dim=-1) * mask
loss = (-loss.sum(dim=1)).mean()
5.2 实验结果
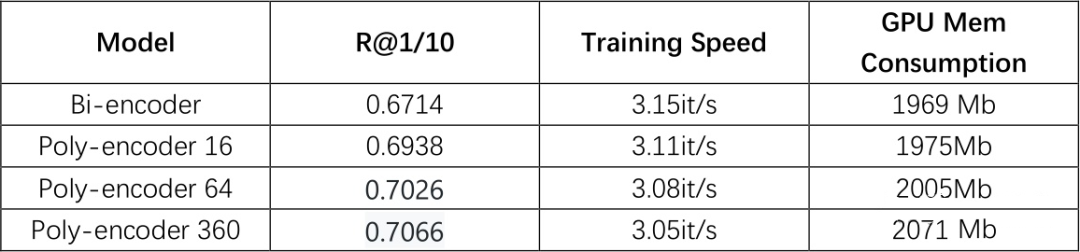
我使用的实验数据是论文中所用的 Ubuntu V2,实验设备是我笔记本上的一个 1066 显卡。当然为了实验跑得更快,我没有使用论文中所用的 bert-base,而是一个预训练过的仅 4 层的 bert-small。
另外,此实验中所用的 batchsize、文本长度、历史对话信息等都限制的比较小(不然实验实在是跑得太慢了),因此实验结果整体会较原论文中偏低。
![]()
▲ 复现实验结果汇总
从上表中明显可以看出,Poly-encoder 的效果要远优于 Bi-encoder 的,当使用 16 个 codes 时,poly 较 bi 的提升可得到 2.24 个点,而使用 64、360 个 codes 时提升分别可达 3.12 和 3.52 个点。而且模型的训练速度几乎没有受到影响,同时对显存的负担也非常小。
![]()
总结
本文提出的 Poly-encoder 思路非常清晰,实现难度不高,而且实验效果非常理想,我个人非常喜欢!
Poly-encoder 架构还有一个突出优点在于,它可以很轻松地拓展到大量信息检索相关的领域,无论是搜索、推荐,或是 CV 领域的 ReID 等,只要可以产生 query 和 candidates 的向量 vec_q 和 vec_c,那么都有可能成功应用 Poly-encoder。
我自己十分看好 Poly-encoder,相信在未来它会成为和 DSSM 一样的经典必读论文。
![]()
点击以下标题查看更多往期内容:
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()




 和
和
 ,最后再通过一个相关性判别函数(通常为 cosine)计算两个 vec 之间的相似度。
,最后再通过一个相关性判别函数(通常为 cosine)计算两个 vec 之间的相似度。
 和
和
 之间的word embedding相似度、Q、C 分别过 RNN 之后的
之间的word embedding相似度、Q、C 分别过 RNN 之后的
 、
、
 之间的相似度,最后再用一些 CNN 之类的方法整合结果,然后用 MLP 做二分类判别是相关还是不相关。
之间的相似度,最后再用一些 CNN 之类的方法整合结果,然后用 MLP 做二分类判别是相关还是不相关。

 (其实有点像封面图那样,有一点用 m 个向量组合出最终的 Low Poly(baike.baidu.com/item/Lo)化向量的味道),最后再计算
(其实有点像封面图那样,有一点用 m 个向量组合出最终的 Low Poly(baike.baidu.com/item/Lo)化向量的味道),最后再计算

 (即
(即

 计算 m 个
计算 m 个
 。
。