最新|将 ResNet-50 的批量大小扩展到 32k来训练ImageNet!
“全球人工智能”拥有十多万AI产业用户,10000多名AI技术专家+2000多名AI创业企业高管+1000多名AI产业投资者核心用户来自:北大,清华,中科院,麻省理工,卡内基梅隆,斯坦福,哈佛,牛津,剑桥......以及谷歌,腾讯,百度,脸谱,微软,阿里,海康威视,英伟达......等全球名校和名企。

摘要:加速训练大型神经网络最自然的方式就是在多块 GPU 上使用数据平行化。为了将基于随机梯度的方法扩展到更多的处理器,我们需要增加批量大小以充分利用每块 GPU 的计算力。然而,在提高批量大小的情况下保持住神经网络的准确度就显得十分重要了。目前,最优秀的方法是与批量大小成正比地提高学习率(LR),并使用带有「warm-up」策略的专用学习率来克服优化困难。通过在训练过程中控制学习率(LR),我们可以在 ImageNet-1K 训练中高效地使用大批量梯度下降。例如,在 AlexNet 中应用 Batch-1024 和在 ResNet-50 中应用 Batch-8192 都取得了不错的效果。然而对于 ImageNet-1K 训练来说,最优秀的 AlexNet 只能扩展到 1024 的批量大小,最优秀的 ResNet-50 只能扩展到 8192 的批量大小。我们不能将学习率扩展到一个较大的值。为了将大批量训练扩展到一般网络或数据集,我们提出了层级对应的适应率缩放(LARS)。LARS LR 基于权重的范数和梯度的范数在不同的神经网络层级中使用不同的学习率。通过使用 LARS LR,我们将 ResNet-50 的批量大小扩展到 32768,将 AlexNet 的批量大小扩展到 8192。大批量同样能完全利用系统的计算能力。例如,AlexNet 模型在 DGX-1 工作站(8 P100 GPU)上使用 Batch-4096 要比 Batch-512 训练 ImageNet 快 3 倍。
1.前言
使用 AlexNet 模型(2)在 NVIDIA K20 GPU 上训练 ImageNet 数据集(1)需要 6 天才能实现 58% 的 top-1 准确度(3)。因此,扩展和加速 DNN 的训练对于应用深度学习来说极其重要。
我们关注数据并行化的小批量随机梯度下降训练(4),该算法在许多如 Caffe(5)和 TensorFlow(6)那样的流行深度学习框架中都是顶尖的优化方法。我们在该研究中使用的是英伟达 GPU。为了加速 DNN 的训练,我们需要将算法扩展到更多的处理器中。所以为了将数据平行化的 SGD 方法扩展到更多的处理器中,我们需要增加批量大小。增加 GPU 数量的同时增加批量大小,并能够使每一块 GPU 的工作保持稳定,并能令每块 GPU 的计算资源都得到充分利用。
为了更进一步提升大批量 AlexNet 的测试准确度,并令大批量训练应用到一般的神经网络和数据集中,我们提出了层级对应的适应率缩放(LARS)LARS 基于权重的范数(||w||)和梯度的范数(||∇w||)对不同的层级使用不同的学习率。 背后的原因是我们观察到权重范数和梯度范数的比率(||w||/||∇w||)在每一层的区别非常大。我们在 AlexNet 模型上的批量由 128 提高到 8129,但实现了相似的准确度。而对于 ResNet-50 来说,我们在 ImageNet 训练中成功地将批量大小提高到 32768。
2.背景和研究的方法
2.1 小批量随机梯度下降的数据并行化
现在令 w 代表 DNN 的权重、X 代表训练数据、n 为 X 中的样本数,而 Y 代表训练数据 X 的标注。我们令 x_i 为 X 的样本,(x_i,w)为 x_i 和其标注 y_i(i ∈ {1, 2, ..., n))所计算出的损失。一般来说,我们使用如交叉熵函数那样的损失函数。DNN 训练的目标是最小化方程(1)中的损失函数。
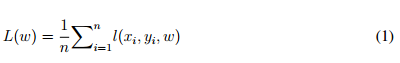
在第 t 次迭代中,我们使用前向和反向传播以求得损失函数对权重的梯度。然后,我们使用这个梯度来更新权重,根据梯度更新权重的方程(2)如下:
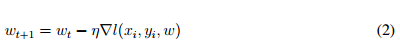
其中 η 为学习率。该方法被称作随机梯度下降(SGD)。通常,我们并不会只使用一个样本计算损失和梯度,我们每次迭代会使用一个批量的样本更新权重。现在,我们令第 t 次迭代的批量大小为 B_t,且 B_t 的大小为 b。然后我们就可以基于以下方程(3)更新权重:
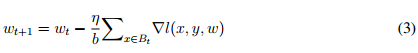
这种方法叫作小批量随机梯度下降(Mini-Batch SGD)。为了简化表达方式,我们可以说方程(4)中的更新规则代表我们使用权重的梯度∇w_t 更新权重 w_t 为 w_t+1。

3. ImageNet-1k 训练
3.1 重现和延伸 Facebook 的研究结果
与 facebook 的论文类似,我们使用预热策略(warm-up policy)和线性缩放策略来获取学习率。但是我们和 Facebook 有两点不同:(1)我们将学习率提升得更高,Batch-256 使用的基本学习率是 0.2,而 Batch-8192 使用的基本学习率是 6.4。(2)我们使用多个规则(poly rule)而不是多步规则(multistep rule)来更新学习率。
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour(Facebook论文):https://arxiv.org/abs/1706.02677
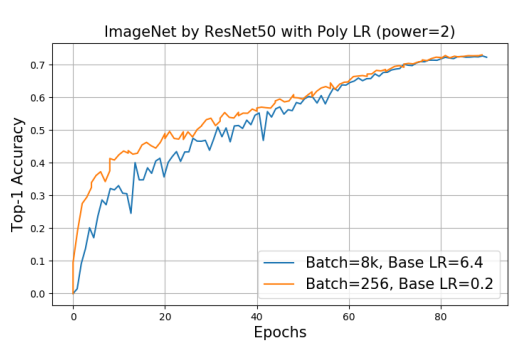
图 1:从这张图片中,我们可以清楚地看到我们使用 8k 批量大小的准确度和 256 批量大小的准确度在 90 个 epoch 中达到同等水平。该实验在一个 NVIDIA DGX-1 工作站上完成。

表 1:ResNet-50 模型在 ImageNet 数据集上使用多个学习率规则的情况。
3.2 使用 AlexNet 训练 ImageNet
3.2.1 学习率的线性缩放和预热策略
我们使用批量为 512 的 BVLC-AlexNet 作为我们的基线,在 100 个 epoch 中实现了 0.58 的准确度。在该实验中,我们使用多个学习率规则。基本的学习率是 0.01,而多个规则的学习率为 2。我们的目标是使用 Batch-4096 和 Batch-8192 在 100 个 epoch 实现 0.58 的准确度。
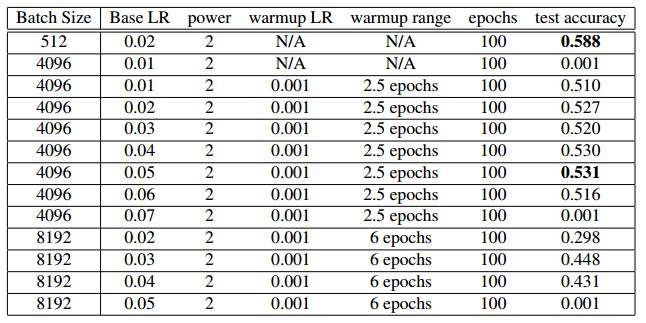
表 2:AlexNet 模型使用多个学习率策略在 ImageNet 数据集中的训练情况。我们使用学习率的线性缩放和预热策略,这些是 Facebook 论文(7)中使用的主要技术。
3.2.2 用于大批量训练的批归一化(BN)
为在 AlexNet 上实现大批量训练,我们尝试了许多不同技术(如,数据清洗、数据缩放(data scaling)、多步 LR、最小 LR 调参)。我们观察到只有批归一化(BN)能够提升准确度。
3.2.3 用于大批量训练的层级对应的适应率缩放(LARS)
为了提高大批量 AlexNet 的准确度,我们设计了一个更新学习率的新规则。如前文所述,我们使用 w = w − η∇w 来更新权重。每一层都有自己的权重 w 和梯度 ∇w。标准 SGD 算法在所有层上使用相同的 LR(η)。但是,从实验中我们观察到不同的层可能需要不同的学习率。
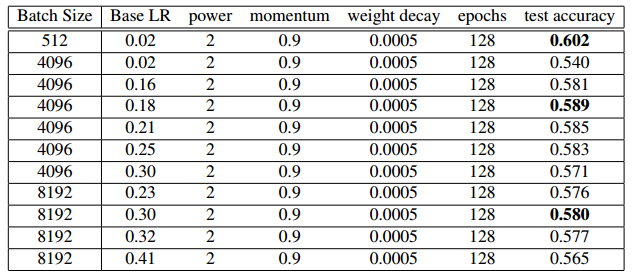
表 3:AlexNet-BN 使用多个 LR 策略在 ImageNet 数据集上的训练情况。
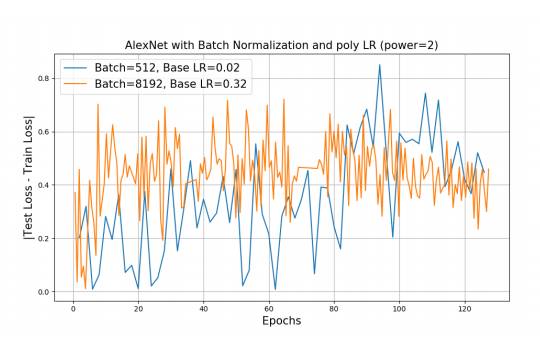
图 2:从上图中,我们清楚地观察到在添加批归一化后,泛化性能变得更好。

表 5:AlexNet_BN 使用 LARS 学习率和多个规则在 ImageNet 数据集上的训练情况。

表 6:AlexNet 模型在 ImageNet 数据集中的训练情况
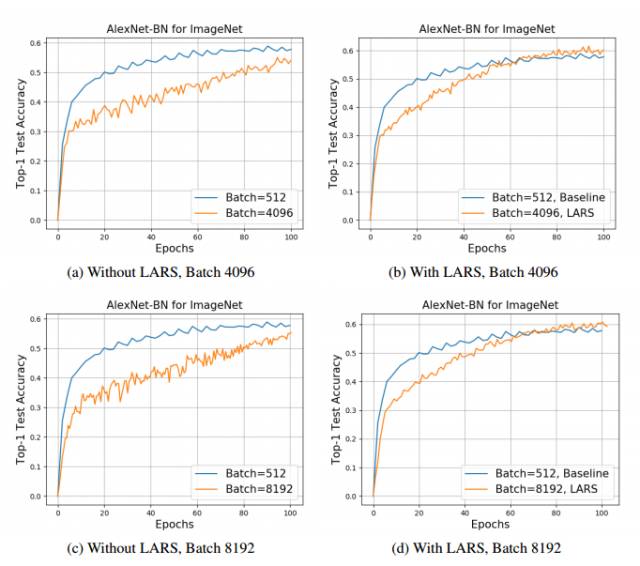
图 3:所有例子只运行 100 个 epoch。我们能明显观察到 LARS 学习率的影响。
4 .训练 ResNet 50 的顶级结果
通过使用 LARS,我们能把 ResNet50 模型的 batch 大小扩展到 32K。我们使用 Batch-256 作为基线。在最高准确度上,8K 的 Batch 损失了 0.3% 的准确度,32K 的 Batch 损失了 0.7% 的准确度。我们相信这些准确度损失能够通过超参数调整弥补。我们的基线要比顶级的结果(7)(17)略低,因为我们并未使用数据增强。
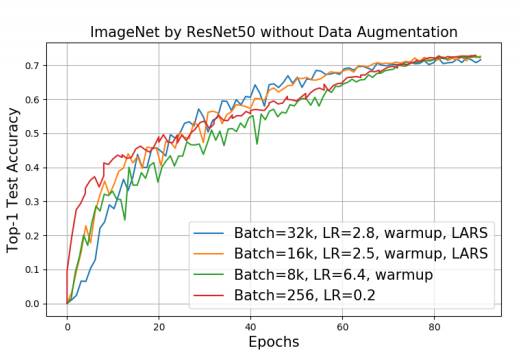
图 4:通过使用 LARS,我们能把 ResNet-50 的批量大小扩展到 32K

表 7:ResNet-50 模型在 ImageNet 数据集上的训练情况

表 8:AlexNet-BN 的速度与时间
4.1使用大批量的收益
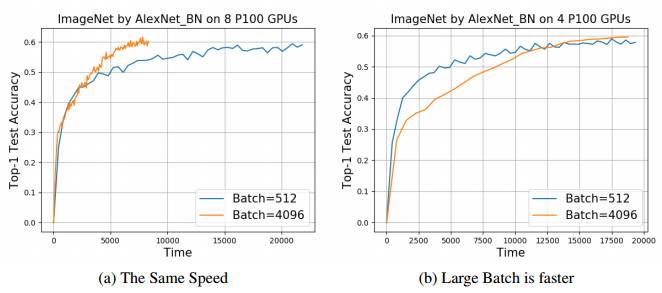
图 5:在 DGX-half(4 块 GPU)上,512 的 Batch 与 4096 的 Batch 有同样的速度。在 DGX(8 块 GPU)上,4096 的 Batch 是 512 Batch 速度的 2.6 倍。因此,大批量在计算能力增强的时候会有收益。

表 10:AlexNet 的速度和时间
5 .主要结论
优化难题导致大批量训练的准确度损失。只使用线性缩放和预热策略这样的方法对复杂的应用而言并不足够,例如使用 AlexNet 来训练 ImageNet。我们提出层级对应的适应率缩放,它基于权重的范数和梯度的范数在不同层级上使用不同的学习率。在实验中,LARS 表现出了极高的效率。通过使用 LARS,把进行 ImageNet 训练的 AlexNet 模型的批量大小从 128 增加到 8192 的时候,我们依然能得到同样的准确度。我们也能把 ResNet-50 的批量大小扩展到 32768,大批量也能充分使用系统的计算能力。





