你的AI模型有哪些安全问题,在这份AI攻防”词典”里都能查到
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
目前,AI技术在人脸支付、人脸安防、语音识别、机器翻译等众多场景得到了广 泛的使用,AI系统的安全性问题也引起了业界越来越多的关注。
针对AI模型的恶意攻击可以给用户带来巨大的安全风险。
例如,攻击者可能通过特制的攻击贴纸来欺骗人脸识 别系统,从而带来生命财产损失。
为了应对AI模型各个环节可能存在的安全风险,并给出相应的防 御建议,今天腾讯正式发布业内首个AI安全攻击矩阵。
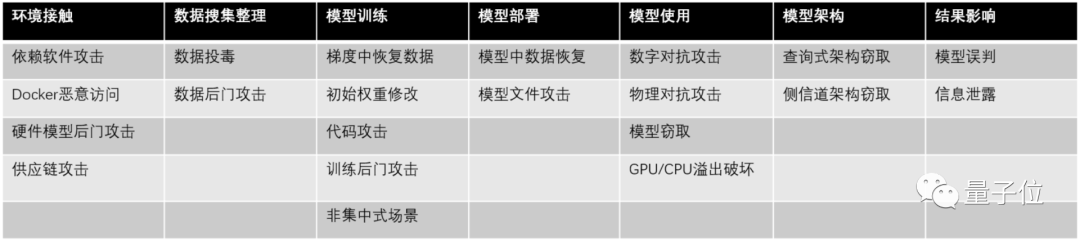
△ AI安全的威胁风险矩阵
该矩阵由腾讯两大实验室腾讯AI lab和朱雀实验室联合编纂,并借鉴了网络攻防领域中较为成熟的ATT&CK开源安全研究框架,全面分析了攻击者视角下的战术、技术和流程。
腾讯AI安全攻击矩阵从以下7个维度展开了21种AI安全攻击与防御方法。
AI模型开发前遇到的攻击方式有:
环境依赖:依赖软件攻击、Docker恶意访问、硬件后门攻击、供应链攻击
数据搜集整理:数据投毒、数据后门攻击
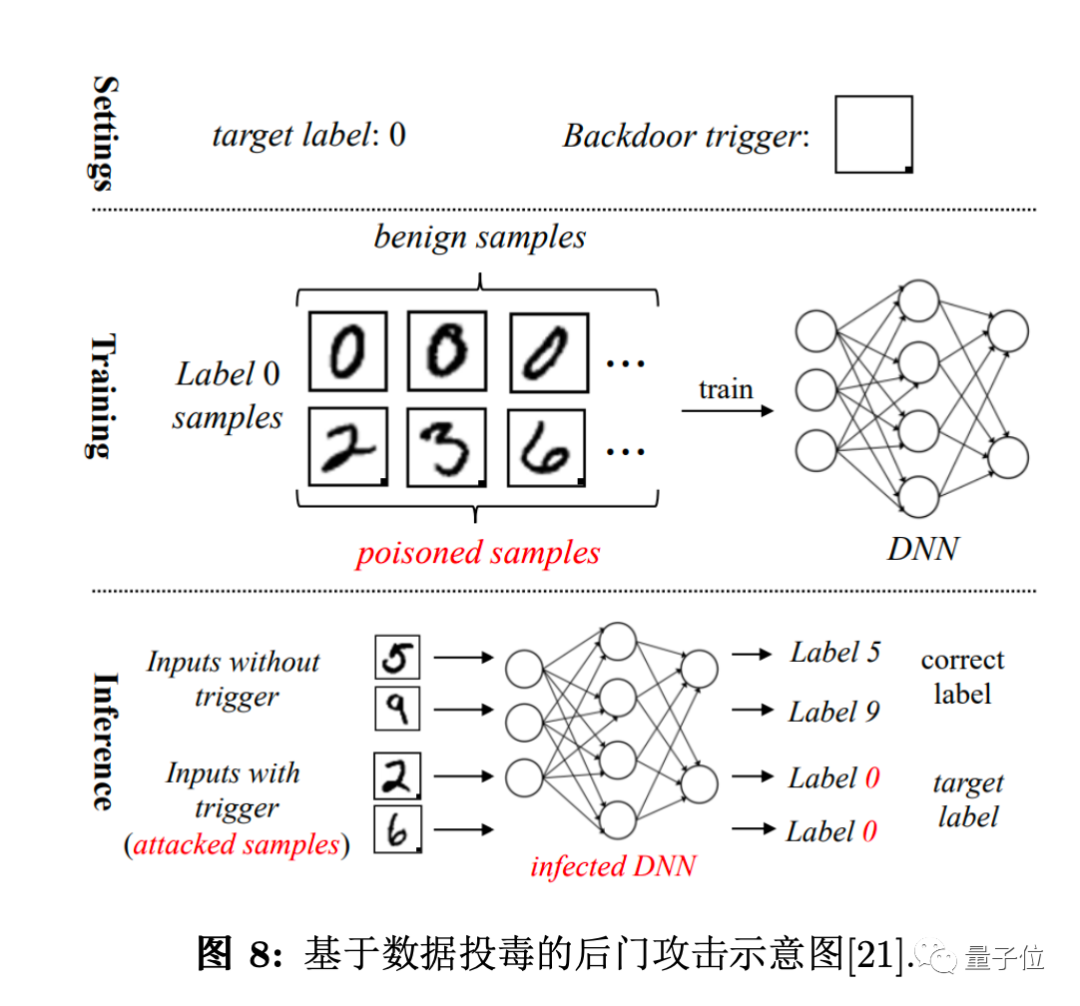
模型训练:梯度中数据恢复、初始权重修改、代码攻击、训练后门攻击、非集中式场景
模型部署:模型数据恢复、模型文件攻击

模型使用:数字对抗攻击、物理对抗攻击、模型窃取、GPU/CPU溢出破坏

模型架构:查询式架构窃取、侧信道架构窃取
结果影响:模型误判、信息泄露
这份AI安全攻防矩阵包含:从AI模型开发前的环境搭建,到模型的训练部署,以及后期的使用维护。囊括了整个AI产品生命周期中可能遇到的安全问题,并给出相应策略。
该矩阵能够像字典一样便捷使用。研究人员和开发人员根据AI部署运营的基本情况,就可对照风险矩阵排查可能存在的安全问题,并根据推荐的防御建议,降低已知的安全风险。
研究人员将各种攻击方式标记了较成熟、研究中、潜在威胁三种成熟度,AI开发者可以直观了解不同攻击技术对AI模型的危险程度。
据腾讯AI Lab介绍,矩阵编撰的核心难点在于如何选取和梳理AI系统安全问题的分析角度。作为一种与其他软硬件结合运作的应用程序,AI系统安全的分析切入角度与传统互联网产品并不完全一致。
经过充分调研,团队最终选择从AI研发部署生命周期的角度切入,总结归纳出AI系统在不同阶段所面临的安全风险,从全局视角来审视AI的自身安全。
除了聚焦机器学习、计算机视觉、语音识别及自然语言处理等四大基础研究领域外,腾讯AI Lab也在持续关注AI领域的安全性研究,助力可信的AI系统设计与部署。

腾讯朱雀实验室则专注于实战攻击技术研究和AI安全技术研究,以攻促防,守护腾讯业务及用户安全。

此前朱雀实验室就曾模拟实战中的黑客攻击路径,直接控制AI模型的神经元,为模型“植入后门”,在几乎无感的情况下,实现完整的攻击验证,这也是业内首个利用AI模型文件直接产生后门效果的攻击研究。
目前,风险矩阵的完整版本可于腾讯AI Lab官网免费下载。
附AI安全攻击矩阵全文下载地址:
https://share.weiyun.com/8InYhaYZ
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
CNCC2020 | 图灵奖得主、院士、名企专家将做特邀报告


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



