58同城智能语音质检系统架构实践

文章作者:刘晟源、陈璐
内容来源:58 AI Lab
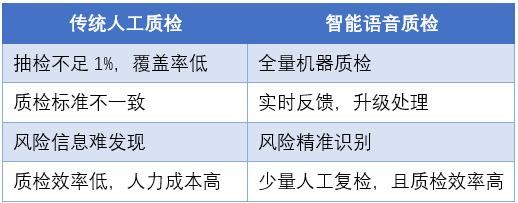
背景
传统语音质检通常是指质检员听取一定比例的电话录音进行人工质检,检测坐席在通话过程中是否有违规或非标准话术行为,如骂人、嘲讽、推诿、过度承诺等,以规范坐席人员行为,进而提升客户服务质量。纯人工听取录音效率低,单人日均仅能听取约3小时,在大规模呼叫中心中往往只能实现少量录音的抽检,覆盖率低。随着语音识别、自然语言理解技术的高速发展,近年来诞生了智能语音质检系统,在语音质检上起到了越来越重要的作用。
整体架构
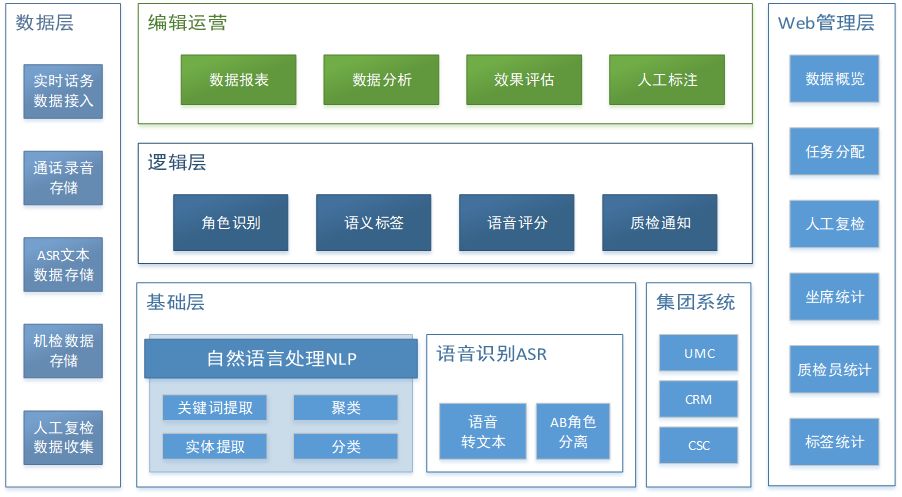
基础层为语音质检提供了基础的语义分析能力,包括由NLP自然语言处理模块和ASR语音识别模块组成。NLP模块主要功能包含分词、文本聚类、文本分类、关键词提取、实体提取等。ASR(语音识别)模块集成封装了第三方语音识别接口,用于语音转文本、角色分离。
数据层提供了数据接入能力,接入了Kafka、WMB(58自研消息总线)实时话务数据,并提供了质检话务数据接口服务,实现对实时录音数据、离线语音数据的多种数据格式质检、存储支持。
逻辑层是语音质检的核心部分,实现了从音频数据到坐席客户对话文本、质检标签识别的全部流程,包括角色识别、语义标签、语音评分、质检结果通知等模块。其中角色识别实现了两个对话角色的识别: 谁是坐席,谁是客户。语义标签模块使用机器学习和深度学习技术,通过语义分析检测出预定义质检标签如“客户表示不需要”、“销售辱骂客户”等。
编辑运营层是一套集数据标注、效果评估、数据分析功能于一体的Web系统。编辑人员通过质检Web平台完成质检标签、角色识别等的标注工作,并定期进行数据分析和效果评测。
语音识别
语音识别是一种将语音转换成文本的技术,对于双声道的录音,客户和坐席的声音在不同的声道,因此可以很容易地将通话双方的说话内容分开并转写成文本,对于单声道录音(我们的质检录音绝大多数都是单声道),客户和坐席的声音混在一起,将说话内容转写成文本之前,我们还需要进行语音分离,将双方的说话内容在语音粒度上分开。语音分离的效果直接影响到后续的质检工作,假如误把客户的说话内容判别为坐席的说话内容,必然会降低质检的效果。衡量语音分离的通用指标是分离错误率(DiarizationError Rate)DER,它指的是语音总时长中识别错误的语音时长所占的比重,DER越小说明分离的效果越好。
此外对于单声道的语音,我们将分离后的语音识别成文本后,还需要进行角色识别的工作,语音分离只是识别出哪些说话内容是A的,哪些是B的,还需要依靠角色识别来判断A和B哪个是坐席,哪个是客户。
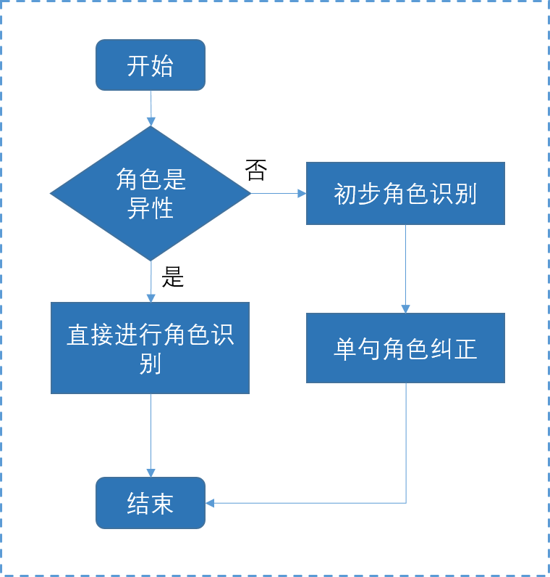
角色识别服务分两步进行,首先会根据音频特征判断说话人双方是否是异性,如果是异性,使用语音性别模型识别出每一句说话内容的性别,然后进行角色的判定。如果无法确定认为双方为异性,则会进行通用角色识别:获得A和B的说话内容之后,第一步是整体判别A和B的角色,整体判别之后可能还会有部分语句的角色是错的(由于语音分离不完全准确造成),比如“有什么还可以帮您的吗?”明显是坐席说的话,但是却被分到了客户的角色上,因此第二步我们会做单句角色纠正。客户和坐席的说话内容都有明显的角色特征,在角色整体判别和单句角色纠正中,我们使用了深度学习模型Transformer和TextCNN并结合挖掘到的一些规则来进行识别。
质检标签识别
销售质检包括销售违规质检和销售常规质检。销售违规质检是为了找出客户有投诉倾向的录音,为此我们定义了“客户表示将去投诉”,“销售辱骂客户”,“客户表示被骚扰”,“客户表示打错了”等标签。语音质检系统可以检测出包含这些标签的录音,并将这些录音反馈给销售主管,销售主管获取这些录音做进一步的处理以避免客户投诉的发生。
销售常规质检针对所有业务线的销售录音,包括“过度承诺”,“工作作假”,“销售辱骂客户”等标签,销售常规质检对于监督销售工作、规范销售行为起到了重要作用。
客服质检针对的是客服录音,目标是检测出通话中客服不文明或者不合规的行为,客服质检对于提升客服服务质量有重要作用。比如招聘业务线新户客服的工作是告知新会员需要注意的事项,包括“安全提示”,“号码保护”和“客户热线”等标签,语音质检系统会给出新户首通客服录音包含的所有标签,并对本次通话给出一个评分。
质检标签识别是一个复杂同时又具有挑战的问题,需要考虑业务,语气和上下文等因素,同时还要避免语音识别错误带来的影响。在语义理解上,我们采用了TextCNN,Transformer和Bert等深度学习模型,同时基于对业务的理解使用了相应的规则,在标签识别准确率上,销售质检准确率为达到90%以上,客服质检准确率达到87%。
复检系统
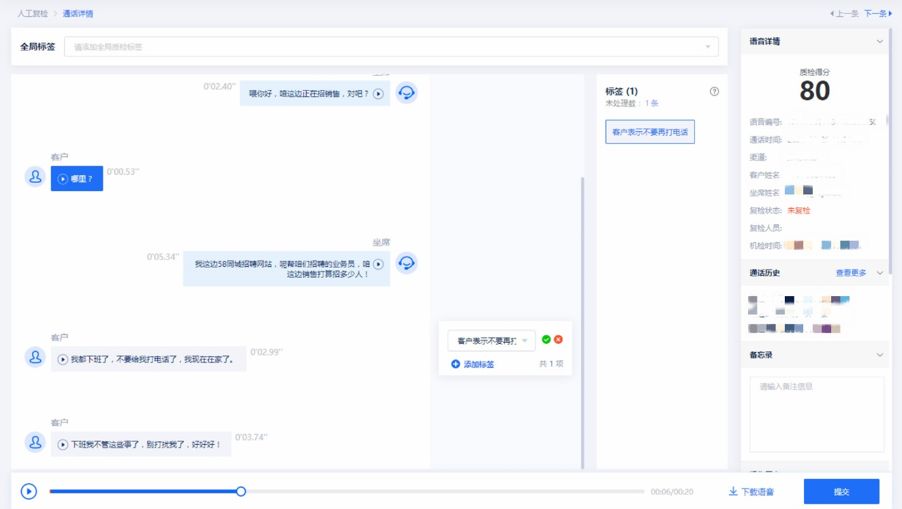
复检系统是Web管理平台的一部分,我们会把质检结果展示在Web页面上,质检员可以看到整体质检报表,也可以对单通语音进行复检,人工复检的详情页面如下所示:
质检员在标签栏可以看到质检系统给出的标签,点击标签可以直接定位到标签的说话内容,点击说话内容左侧的播放按钮可以听这句话的录音,同时最下侧的录音进度条也会移动到相应位置。质检员不仅可以很快地复检标签内容,也可以通过快速浏览文字检查质检系统未覆盖到的内容并手动添加标签,复检结果会存入数据库中供后续分析使用。传统的人工质检,质检时边听录音边做记录,一通语音要反复听好几遍才会有一个质检结果,效率非常低下。相比于传统的人工质检方式,使用复检系统的人效提高2至3倍。
后端架构设计
语音质检后台系统基于58同城自研RPC框架SCF实现,使用WMonitor实现对各个服务的监控,存储依据不同数据的特性分别选用了WOS(58自研对象存储服务)、Redis、WTable(58自研KV存储服务)、WCS(58自研索引服务)、MySQL等。整个后台服务的设计如下图所示:
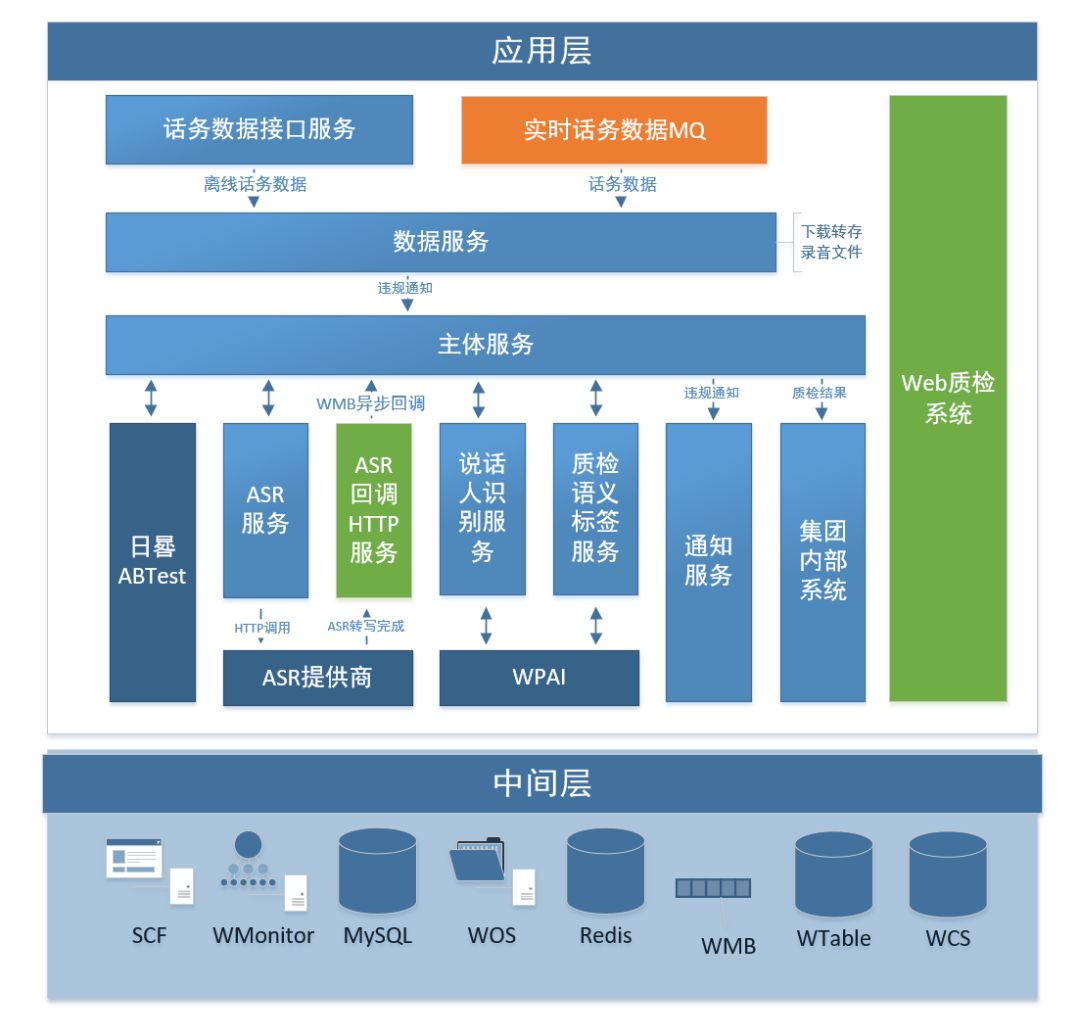
语音质检接入了呼叫中心的实时话务消息队列,以实现对坐席电话的实时质检功能,此外还额外提供了话务数据接口服务,实现对离线数据的提交质检。
语音质检后台系统由数据服务、主体服务、ASR服务、ASR回调服务、说话人识别服务、质检标签服务等多个微服务组成。
数据服务负责实现对多种数据源的接入,补全客户以及坐席组织架构信息,并实现对存于话务系统中原始录音文件的WOS转存功能。主体服务贯穿整个质检过程,负责控制整个数据流:调用日晷平台获取ABTest实验配置,向ASR服务发起转写请求,调用说话人识别服务、质检标签服务获取角色识别结果以及质检标签,向质检员发送违规通知、向其他内部系统同步质检结果等。
语音转写算法模型耗时较长,故对第三方服务的封装采用异步调用的方式:由ASR服务负责对HTTP提交任务接口的封装,对内提供一个SCF接口;并设立回调HTTP服务接收ASR转写结果转存WTable,并使用WMB向主体服务发送质检回调请求。
说话人识别以及质检语音标签分析依赖的模型经离线训练后部署在WPAI中,此外WPAI提供了算法模型在线预测服务,供说话人识别服务、质检语义标签服务在线调用,质检结果由主体服务统一存储到MySQL中。
在将录音转写成文本、给每通录音打上质检标签后,为便于质检员实时复检操作,我们构建了智能质检Web平台,平台提供机检标签查询、人工复检、录音文本查看、录音调听、统计报表汇总等功能。Web系统涉及大量的标签查询以及统计功能,单一的SQL查询难以满足性能指标,对此我们引入了58自研的58云搜(WCS)搜索私有云平台,将质检结果数据实时同步至WCS中,Web查询由WCS统一承载,目前在千万级数据接口查询速度约为20ms。

列表查询
总结
本文主要介绍了智能语音质检系统的架构设计,包括整体架构、角色识别、质检标签识别、系统的服务设计等。
目前智能语音质检系统已稳定接入58同城呼叫中心销售、客服全量录音,涉及13个业务,日均质检电话录音数十万通,其中客服录音质检场景折合节省人力近千人,提高了呼叫中心人效和服务质量。
同时智能语音质检系统提供了通用的语音分析能力,除了目前应用的语音质检场景外同样的技术也可以用于C2B平台语音分析场景,58同城作为平台方为商家以及客户搭建了方便快捷的沟通途径,其中语音电话也是一大重要的沟通方式,对于C端客户与B端商家的语音分析可提供如低质通话过滤、客户需求挖掘分析等多种业务能力。C2B的语音一般是双声道,不需要做语音分离和角色识别,可以很好地区分客户和商家说话内容,因此具有更好的分析效果。

此外语音质检后续将重点提高角色识别、标签识别准确率,提供简单快捷的接入平台的能力,进一步挖掘语音数据中潜藏信息,服务业务方,提高语音质检、分析工作人效,为广大用户提供更好更优质的服务。
作者简介
刘晟源,58同城 AI Lab 后端资深开发工程师,主要负责智能语音质检平台开发相关工作。
陈璐,58同城 AI Lab 算法高级工程师,主要负责58智能质检的算法开发工作。
AI Lab简介





