Facebook 这类网站如何处理数十亿请求并保持高可用性的?
(点击上方公众号,可快速关注)
编译:伯乐在线 - 孙腾浩
Facebook 这类网站如何处理数十亿请求并保持高可用性呢,答案是负载均衡,本文将对其一探究竟。
什么是负载均衡
负载均衡是许多协同工作资源(通常是计算机)的分配策略。它们通常用于提高容量和可靠性。
为了便于讨论负载均衡,对于服务扩展我假设以下两点:
我可以运行任意数量实例
任何请求可以到达任意实例
第一个假设表明服务是无状态的(或者像 Redis 集群一样可以共享状态)。第二个假设实际中并不是必须的(比如粘性负载均衡),但在这片文章中做这样的假设便于讨论。
下面是我将要讨论的负载均衡技术:
应用层(OSI 第七层)负载均衡(HTTP、HTTPS、WS)
传输层(OSI 第四层)负载均衡(TCP、UDP)
网络层(OSI 第三层)负载均衡
DNS 负载均衡
多个子域手动负载均衡
任播(Anycast)
最后还有一些其他知识点:
延迟和吞吐量
服务器直接返回
这些技术大致按照「网站流量增大时需要的操作步骤」排序。比如,应用层的负载均衡是首先要做的事(远远早于任播)。前三条技术提高吞吐量和可用性,但存在单点故障。其余的三条技术在提高吞吐量的同时避免了单点故障。
为了帮助我们理解负载均衡,我们来看一个简单的服务扩展。
注意:每种扩展技术都采用了非技术的比喻(在商店购物)。这些比喻仅仅是描述技术背后的思想,并不完全准确。
服务
我们假设我们正在构建大规模的服务。就像下图所示:
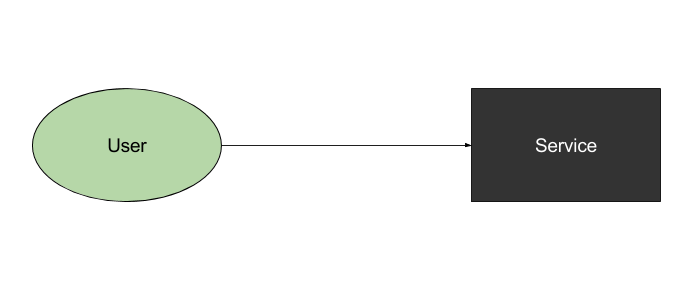
这个系统并不能处理大量通信,并且如果它宕机,整个应用就停了。
比喻
你走向商店唯一一条结账的队伍。
你购买你的商品,如果那里没有收银员,你无法完成购买。
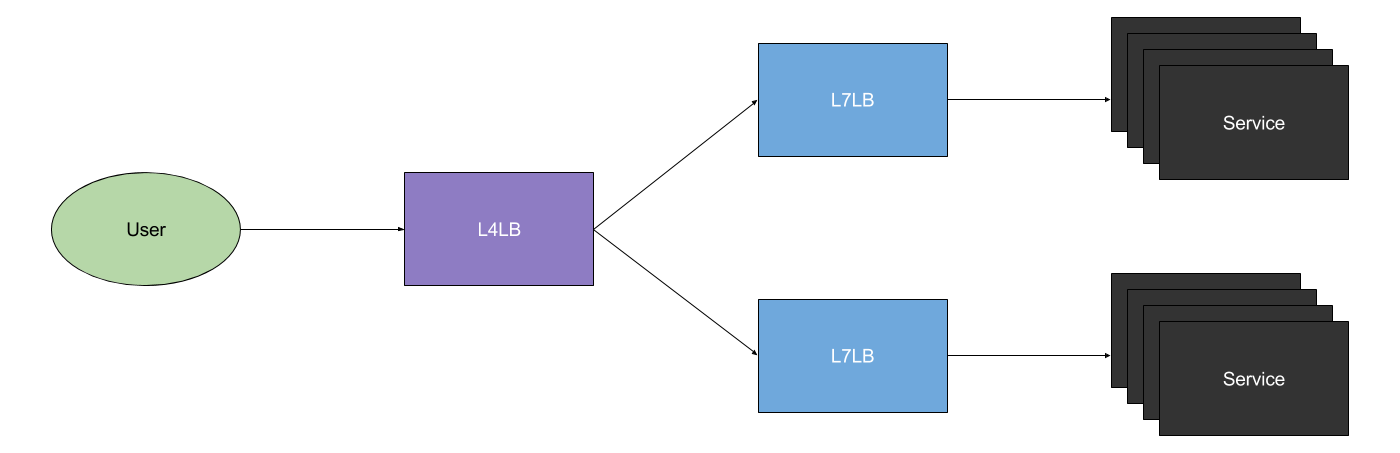
应用层(OSI 第七层)负载均衡
为了承载更大的通信量,首先用到的就是应用层负载均衡。应用层是 OSI 第七层。它包括 HTTP、HTTPS 和 WebSockets。一款非常流行又久经考验的应用层负载均衡器就是 Nginx。让我们看看它如何帮助我们扩展服务:

请注意,通过这种技术,我们能负载均衡数十或上百服务器实例。上面图片只展示两个作为例子。
比喻
商店员工引领你到一个特别的(有收银员的)结账队伍
你购买你的商品
工具
Nginx
HAProxy
注意
我们要在这里停止使用 SSL(分发时不用 SSL)
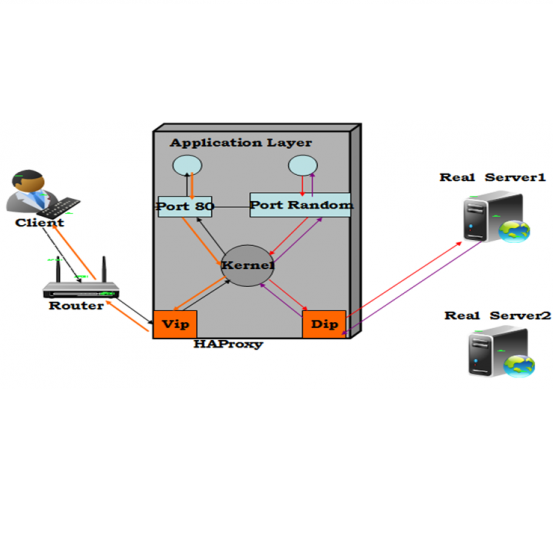
传输层(OSI 第四层)负载均衡(TCP、UDP)
上一条技术帮助我们承载大量通信,但如果我们需要承载更大的通信量,传输层负载均衡非常有用。传输层是 OSI 第四层,包括 TCP 和 UDP。流行的传输层负载均衡器有 HAProxy(这个也用于应用层负载均衡)和 IPVS。让我们看看它们如何帮助我们扩展服务:
应用层负载均衡+传输层负载均衡能处理大多数情况下的通信量。然而我们我们仍要担心可用性。单点故障有可能出现在传输层的负载均衡器。我们在下面一节的 DNS 负载均衡解决这个问题。
比喻
根据客户会员卡卡号有不同结账区域。举个例子,如果你的会员卡卡号是偶数,去电器区附近的结账台,否则就去食品区附近的结账台。
一旦你到达正确的结账区域,商店员工引领你到一个特别的结账队伍
你购买你的商品
工具
HAProxy
IPVS
网络层(OSI 第三层)负载均衡
如果我们要继续扩展,我们需要增加网络层负载均衡。这比上面两条技术更复杂。网络层是 OSI 第三层,包括 IPv4 和 IPv6。下面是网络层负载均衡:
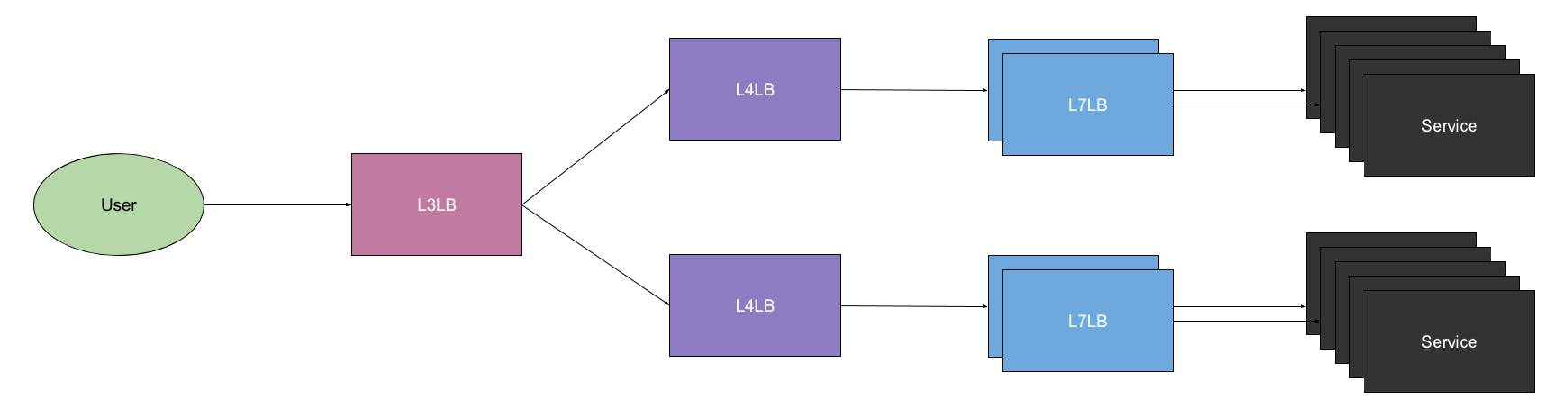
为了搞清楚它如何工作,我们需要一点等价路由的知识(ECMP)。当有多条等价链路到达相同地址时,我们使用等价路由。简单来说,它允许路由器或交换机通过不同链接发送数据包(支持高吞吐量),最终到达同一地址。
我们可以利用这一点来实现网络层负载均衡,因为在我们看来,每个传输层负载均衡器是相同的。这意味着我们可以把从网络层负载均衡器到传输层负载均衡器的链接看做相同目的地的链路。如果我们把所有负载均衡器绑定到相同 IP 地址,我们可以使用等价路由在传输层负载均衡器之间分配通信。
比喻
街对面有两家彼此分开却又一模一样的商店,你去哪一家完全取决于你的习惯。
一旦你到达了商店,根据客户会员卡卡号有不同结账区域。举个例子,如果你的会员卡卡号是偶数,去电器区附近的结账台,否则就去食品区附近的结账台。
一旦你到达正确的结账区域,商店员工引领你到一个特别的结账队伍
你购买你的商品
工具
通常在机柜里交换机内部的硬件中处理。
太长不阅
除非你的服务规模相当大或有自己的硬件,否则你不需要它。
DNS 负载均衡
DNS 是将名称转换为 IP 地址的系统。举个例子,它可以把 example.com 转换为 93.184.216.34 。它当然也可以返回多个 IP 地址,像下面这样:
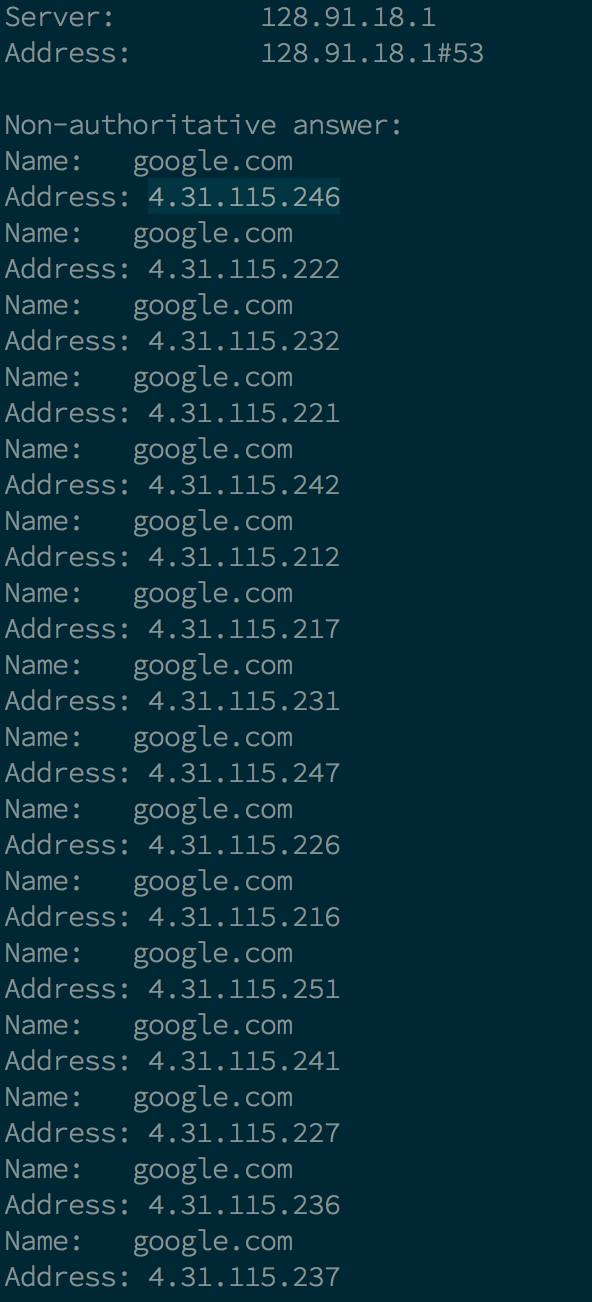
如果返回了多个 IP,客户端通常会使用第一个可用的地址(然而一些应用只看第一个返回的 IP)。
目前有很多 DNS 负载均衡技术,比如 GeoDNS 和轮询调度(round-robin)。GeoDNS 基于不同请求者而返回不同响应。这让我们可以将客户端路由到其最近的服务器或数据中心。轮询调度会循环所有可用的 IP 地址,对于每个响应会返回不同的 IP。如果多个 IP 可用,这两种技术仅仅改变响应里的 IP 顺序。
下图展示 DNS 负载均衡如何工作:
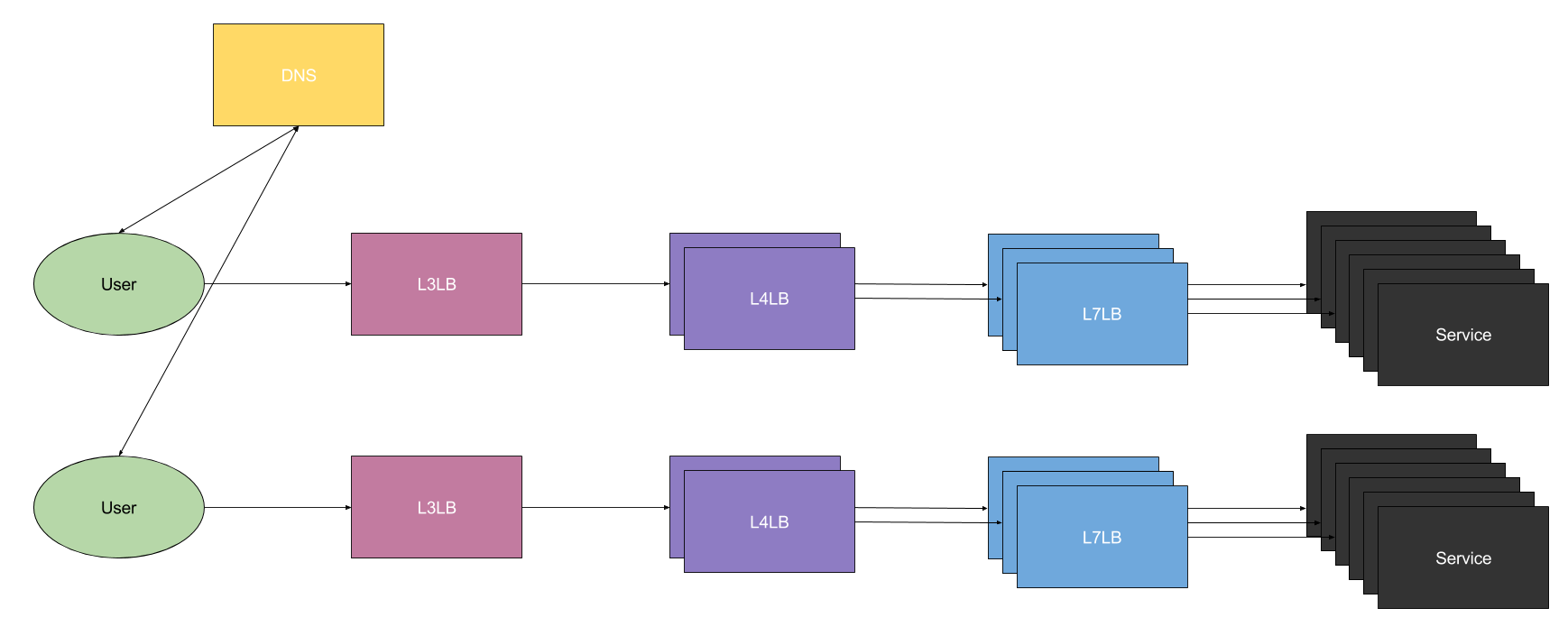
在这个例子中,不同的用户被路由到不同的服务集群(随机或基于地理位置)。
现在这里不再有单点故障的可能性(假设有多台 DNS 服务器)。为了进一步提高可靠性,我们可以在不同数据中心运行多个服务集群。
比喻
你在网上查询购物中心,返回的列表把最近的购物中心放在第一个。你查看通往每个购物中心的路,然后选择列表中第一个营业的购物中心。
街对面有两家彼此分开却又一模一样的商店,你去哪一家完全取决于你的习惯。
一旦你到达了商店,根据客户会员卡卡号有不同结账区域。举个例子,如果你的会员卡卡号是偶数,去电器区附近的结账台,否则就去食品区附近的结账台。
一旦你到达正确的结账区域,商店员工引领你到一个特别的结账队伍
你购买你的商品
手动负载均衡和路由
如果你的内容在许多数据中心或服务间共享,而我们需要路由到其中特定的一个,那么这条技术就很有用了。比如 cat.jpg 储存在伦敦的集群中,但其他集群中没有。相似的,dog.jpg 储存在纽约的集群中,其他数据中心或集群中没有。举个例子,这很可能发生在内容刚刚上传,还未在数据中心之间复制的时候。
然而,用户获取内容时不应该等待复制完成。这意味着我们的应用需要临时把所有 cat.jpg请求发送到伦敦,所有 dog.jpg 请求发送到纽约。所以我们需要用 https://lon-1e.static.example.net/cat.jpg 代替 https://cdn.example.net/cat.jpg。对 dog.jpg 来说也一样。
为了实现这一点,我们需要为每个数据中心设置子域(最好细分到每个集群每台机器)。除了上面的 DNS 负载均衡,这一点也很有必要。
注意:我们的应用需要保持追踪内容的位置,以便重写请求。
比喻
你拨打公司电话询问哪个购物中心提供猫粮。
你查看列表上的购物中心路线,然后选择第一个营业的。
街对面有两家彼此分开却又一模一样的商店,你去哪一家完全取决于你的习惯。
一旦你到达了商店,根据客户会员卡卡号有不同结账区域。举个例子,如果你的会员卡卡号是偶数,去电器区附近的结账台,否则就去食品区附近的结账台。
一旦你到达正确的结账区域,商店员工引领你到一个特别的结账队伍
你购买你的商品
任播(Anycast)
这篇文章讨论的最后一种技术就是任播。首先来看一点背景知识:
大多数网路使用单播。这本质上意味着每台计算机拥有独一无二的 IP 地址。有另一种称为任播的理论。通过任播,一些机器可以使用相同的 IP 地址和路由,并把请求发送到最近的一台机器。我们可以把这种技术和上面所讲的技术结合起来,构建出高可靠性和可用性,能承载巨大通信量的系统。
任播根本上来说是允许互联网为我们处理部分负载均衡。
比喻
你告诉别人你打算去商店,他们把你带到最近的位置。
街对面有两家彼此分开却又一模一样的商店,你去哪一家完全取决于你的习惯。
一旦你到达了商店,根据客户会员卡卡号有不同结账区域。举个例子,如果你的会员卡卡号是偶数,去电器区附近的结账台,否则就去食品区附近的结账台。
一旦你到达正确的结账区域,商店员工引领你到一个特别的结账队伍
你购买你的商品
杂项
延迟和吞吐量
顺便一提的是,这些技术也可以提升低延迟服务的吞吐量。增加服务数量而不是让每个服务处理更多的通信。这样我们就可以得到低延迟、高吞吐量的系统。
服务器直接返回
在传统负载均衡系统中,请求穿过负载均衡的所有层级,响应也同样穿过它们。降低负载均衡通信量的一个优化点就是服务器直接返回。这意味着服务端的响应不通过负载均衡。如果服务端的响应十分巨大,这点尤其有用。
看完本文有收获?请分享给更多人
关注「Linux 爱好者」,提升Linux技能