GAN生成的结果多样性不足怎么办?那就再添一个鉴别器!

近期,澳大利亚迪肯大学图像识别和数据分析中心发表了一篇新的论文,由Tu Dinh Nguyen, Trung Le, Hung Vu, Dinh Phung编写,该论文就生成对抗网络(GAN)的模式崩溃问题进行了讨论并给出了一种新的有效的解决方案 D2GAN,论文译稿由AI研习社编辑,原文链接:http://t.cn/RpWiFoG
这篇文章介绍了一种解决生成对抗网络(GAN)模式崩溃问题的方法。这种方法很直观但是证实有效,特别是当对GAN预先设置一些限制时。在本质上,它结合了Kullback-Leibler(KL)和反向KL散度的差异,生成一个目标函数,从而利用这些分支的互补统计特性捕捉多模式下分散预估密度。这种方法称为双鉴别器生成对抗网络(Dual discriminator generative adversarial nets, D2GAN),顾名思义,与GAN不同的是,D2GAN有两个鉴别器。这两个鉴别器仍然与一个生成器一起进行极大极小的博弈,一个鉴别器会给符合分布的数据样本给与高奖励,而另外一个鉴别器却更喜欢生成器生成的数据。生成器就要尝试同时欺骗两个鉴别器。理论分析表明,假设使用最强的鉴别器,优化D2GAN的生成器可以让原始数据库和生成器产生的数据间的KL和反向KL散度最小化,从而有效地避免模式崩溃的问题。作者进行了大量的合成和真实数据库的实验(MNIST,CIFAR-10,STL-10,ImageNet),对比D2GAN和最新的GAN变种的方法,并进行定性定量评估。实验结果有效地验证了D2GAN的竞争力和优越的性能,D2GAN生成样本的质量和多样性要比基准模型高得多,并可扩展到ImageNet数据库。
简介
生成式模型是研究领域的一大分支并且在最近几年得到了飞速的成长,成功地部署到很多现代的应用中。一般的方法是通过解决密度预测问题,即学习模型分布Pmodel来预测置信度,在数据分布Pdata未知的情况下。这种方法的实现需要解决两个基本问题。
首先,生成模型的学习表现基于训练这些模型的目标函数的选择。最为广泛使用的目标,即事实标准目标,是遵循遵循最大似然估计原理,寻求模型参数以最大限度地提高训练数据的似然性。这与最小化KL散度数据分布和模型分布上的差异的方法相似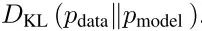

第二个问题是密度函数Pmodel公式的选择问题。一种方法是定义一个明确的密度函数,然后直接的根据最大似然框架进行参数估计。另外一种方法是使用一个不明确的密度函数记性数据分布估计,不需要使用Pmodel的解析形式。还有一些想法是借用最小包围球的原理来训练生成器,训练和生成的数据,在被映射到特征空间后,被封闭在同一个球体中。这种方法最为著名的先驱应用是生成对抗网络(GAN),它是一种表达生成模型,具备生成自然场景的尖锐和真实图像的能力。与大多数生成模型不同的是,GAN使用了一种激进的方法,模拟了游戏中两个玩家对抗的方法:一个生成器G通过从噪声空间映射输入空间来生成数据;鉴别器D则表现得像一个分类器,区分真实的样本和生成器生成的伪图像。生成器G和鉴别器D都是通过神经网络参数化得来的,因此,这种方法可以归类为深度生成模型或者生成神经模型。
GAN的优化实际上是一个极大极小问题,即给定一个最优的D,学习的目标变成寻找可以最小化Jensen-Shannon散度(JSD)的G: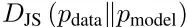
近期的研究通过改进GAN的训练方式来解决模式崩溃的问题。一个方法是使用mini-batch分辨法巧妙地让鉴别器分辨与其他生成样本非正常相似的图片。尽管这种启发方式可以帮助快速生成具有视觉吸引力的样本,但是它的计算代价很高,因此,通常应用于鉴别器的最后一个隐藏层。另外一个方法是把鉴别器的优化通过几个步骤展开,在训练中产生一个代理目标来进行生成器的更新。第三种方法是训练多个生成器,发现不同的数据模式。同期的,还有一些其他的方法,运用autoencoders进行正则化或者辅助损失来补偿丢失的模式等。这些方法都可以在一定程度上改善模式崩溃的问题,但是由此带来了更高的计算复杂度,从而无法扩展到ImageNet这种大规模的和具有挑战性的视觉数据库上。
应对这些挑战,作者们在这篇论文中提出了一种新的方法,既可以高效地避免模式崩溃问题又可以扩展到庞大的数据库(比如:ImageNet等)。通过结合KL和反KL散度生成一个统一的目标函数,从而利用了两种散度的互补统计特性,有效地在多模式下分散预估密度。使用GAN的框架,量化这种思路,便形成了一种新颖的生成对抗架构:鉴别器D1(通过鉴别数据来自于Pdata而不在生成分布PG中获取高分),鉴别器D2(相反地,来自于PG而不在Pdata中)和生成器G(尝试欺骗D1、D2两个鉴别器)。作者将这种方法命名为双鉴别器生成对抗网络(D2GAN)。
实验证明,训练D2GAN与训练GAN会遇到同样的极大极小问题,通过交替更新生成器和鉴别器可以得到解决。理论分析表明,如果G、D1和D2具有足够的容量,如非参数的限制下,在最佳点,对KL和反KL散度而言,训练标准确实导致了数据和模型分布之间的最小距离。这有助于模型在各种数据分布模式下进行公平的概率分布,使得生成器可一次完成数据分布恢复和生成多样样本。另外,作者还引入了超参数实现稳定地学习和各种散度影响的控制。
作者进行了大量的实验,包括一个合成数据库和具备不同特征的四个真实大规模数据库(MNIST、CIFAR10、STL-10、ImageNet)。众所周知,评估生成模型是非常困难的,作者花费了很多时间,使用了各种评估办法,定量的对比D2GAN和最新的基线方法。实验结果表明,D2GAN可以在保持生成样本质量的同时提高样本的多样性。更重要的是,这种方法可以扩展到更大规模的数据库(ImageNet),并保持具有竞争力的多样性结果和生成合理的高品质样本图片。
简而言之,这种方法具有三个重要的贡献:(i)一种新颖的生成对抗模型,提高生成样本的多样性;(ii)理论分析证实这种方法的目标是优化KL和反KL散度的最小差异,并在PG=Pdata时,实现全局最优;(iii)使用大量的定量标准和大规模数据库对这种方法进行综合评估。
作者们的实现方法如下:
生成对抗网络
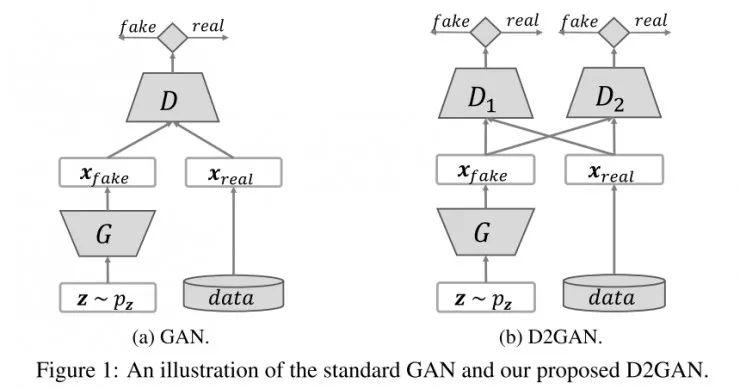
首先介绍一下生成对抗网络(GAN),具有两个玩家:鉴别器D和生成器G。鉴别器D(x),在数据空间中取一个点x,然后计算x在数据分布Pdata中而不是生成器G生成的概率。同时,生成器先向数据空间映射一个取自先导P(z)的噪声向量z,获取一个类似于训练数据的样本G(z),然后使用这个样本来欺骗鉴别器。G(z)形成了一个在数据域的生成分布PG,和概率密度函数PG(x)。G和D都由神经网络构成(见图1a),并通过如下的极大极小优化得以学习:
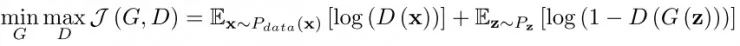
学习遵循一个迭代的过程,其中鉴别器和生成器交替地更新。假设固定G,最大化D可以获得最优鉴别器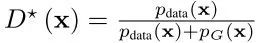
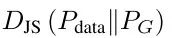
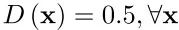
由于JS散度通过大量的实验数据证实与反KL散度的特性相同,GAN也会有模式崩溃的问题,因此,其生成的数据样本多样性很低。
双鉴别器生成对抗网络
为了解决GAN的模式崩溃问题,下方介绍了一种框架,寻求近似分布来有效地涵盖多模式下的多模态数据。这种方法也是基于GAN,但是有三个组成部分,包括两个不同的鉴别器D1、D2和一个生成器G。假定一个数据空间中的样本x,如果x是数据分布Pdata中的,D1(x)获得高分,如果是模式分布PG中的,则获得低分。相反地,如果x是模式分布PG中的,D2(x)获得高分,如果是数据分布Pdata中的,D2(x)获得低分。与GAN不同的是,得分的表现形式为R+而不是[0,1]中的概率。生成器G的角色与GAN中的相似,即从噪声空间中映射数据与真实数据进行合成后欺骗D1和D2两个鉴别器。这三个部分都由神经网络参数化而成,其中D1和D2不分享它们的参数。这种方法被称为双鉴别器生成对抗网络(D2GAN),见上图1b。D1、D2和G遵循如下的极大极小公式:
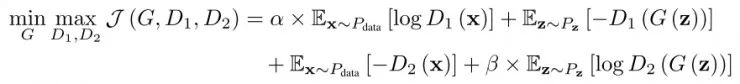
其中超参数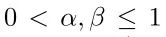
与GAN相似的是,通过交替更新D1、D2和G可以训练D2GAN。
理论分析
通过理论分析发现,假设G、D1和D2具备足够的容量,如非参数的限制下,在最佳点,G可以通过最小化模型和数据分布的KL和反KL散度恢复数据分布。首先,假设生成器是固定的,通过(w.r.t)鉴别器进行优化分析:
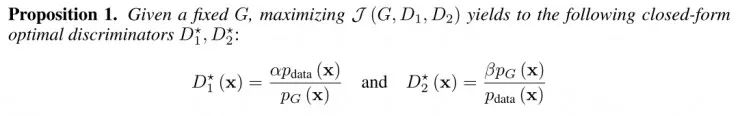
证明:根据诱导测度定理,两个期望相等:
当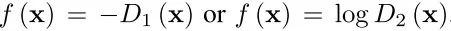
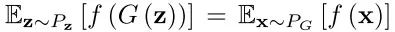
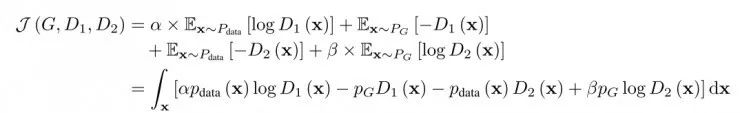
考虑到里面的函数积分,给定x,通过两个变量D1、D2最大化函数,得到D1*(x)和D2*(x)。将D1和D2设置为0,可以得到:
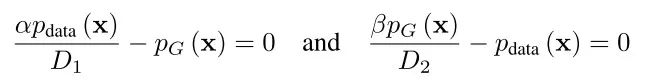
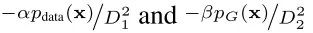
接下来,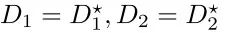
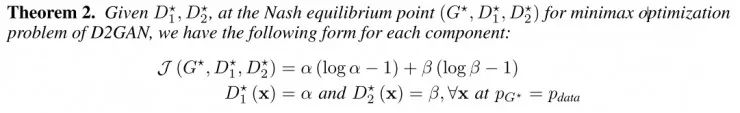
证明:将D1*和D2*代入极大极小方程,得到:
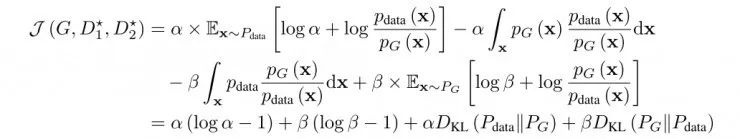
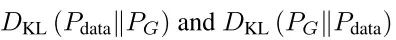
如上公式中生成器的误差表明提高α可以促进最小化KL散度(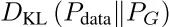
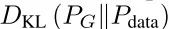
实验
在这个部分,作者进行了广泛的实验来验证的提高模式覆盖率和提出的方法应用在大规模数据库上的能力。使用一个合成的2D数据库进行视觉和数值验证,并使用四个真实的数据库(具有多样性和大规模)进行数值验证。同时,将D2GAN和最新的GAN的应用进行对比。
从大量的实验得出结论:(i)鉴别器的输出具有softplus activations: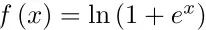
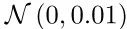
合成数据库
在第一个实验中,使用已经设计好的实验方案对D2GAN处理多模态数据的能力进行评估。特别的是,从2D混合8个高斯分布和协方差矩阵0.02I 获取训练数据,同时中位数分布在半径2.0零质心的圆中。使用一个简单的架构,包含一个生成器(两个全连接隐藏层)和两个鉴别器(一个ReLU激发层)。这个设定是相同的,因此保证了公平的对比。图2c显示了512个由D2GAN和基线生成的样本。可以看出,常规的GAN产生的数据在数据分布的有效模式附近的一个单一模式上奔溃了。而unrolledGAN和D2GAN可以在8个混合部分分布数据,这就印证了能够成功地学习多模态数据的能力。最后,D2GAN所截取的数据比unrolledGAN更精确,在各种模式下,unrolledGAN只能集中在模式质心附近的几个点,而D2GAN产生的样本全分布在所有模式附近,这就意味着D2GAN产生的样本比unrolledGAN多得多。
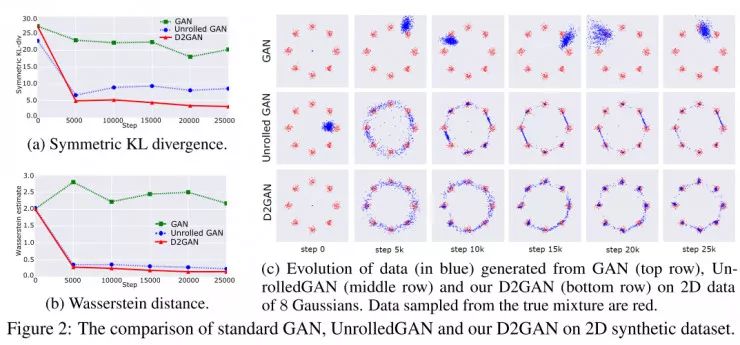
下一步,定量的进行生成数据质量的对比。因为已知真实的分布Pdata,只需进行两步测量,即对称KL散度和Wasserstein距离。这些测量分别是对由D2GAN、unrolledGAN和GAN的10000个点归一化直方与真实的Pdata之间的距离计算。图2a/b再次清楚了表明了D2GAN相对于unrolled和GAN的优势(距离越小越好);特别是Wasserstein度量,D2GAN离真实分布的距离基本上减小到0了。这些图片也表达了D2GAN相对于GAN(绿色曲线)和unrolledGAN(蓝色曲线)在训练时的稳定性。
真实数据库
下面,使用真实数据库对D2GAN进行评估。在真实数据库条件下,数据拥有更高的多样性和更大的规模。对含有卷积层的网络,根据DCGAN进行设计分析。鉴别器使用带步长的卷积,生成器使用分步带步长的卷积。每个层都进行批处理标准化,除了生成器输出层和鉴别器的输入层。鉴别器还使用Leaky ReLU 激发层,生成器使用ReLU层,除非其输出是tanh,原因是各像素的强度值在反馈到D2GAN模型前已经变换到[-1,1]的区间内。唯一的区别是,在D2GAN下,当从N(0,0.01)初始化权重时,其表现比从N(0,0.02)初始化权重的效果好。架构的细节请看论文附件。
评估方式
评估生成对抗模型产生的样本是很难的,原因有生成概率判断标准繁多、缺乏有意义的图像相似性度量标准。尽管生成器可以产生看似真实的图像,但是如果这些图像看起来非常近似,样本依然不可使用。因此,为了量化各种模式下的图像质量,同时生产高质量的样本图样,使用各种不用的ad-hoc度量进行不同的实验来进行D2GAN方法与各基线方法的效果对比。
首先,使用起始分值(Inception Score),计算通过:
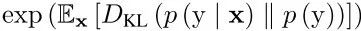
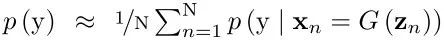
这种度量方式会给质量高的多样的图片给高分,但是有时候很容易被崩溃的模式欺骗,导致产生非常低质量的图片。因此,这种方式不能用于测量模型是否陷入了错误的模式。为了解决这个问题,对有标签的数据库,使用MODE score:
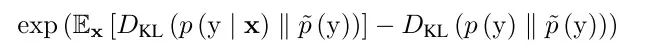
这里,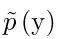
手写数字图像
这个部分使用手写数字图像-MNIST,数据库包含有60,000张训练图像和10,000张测试灰度图(28*28像素),数值区间从0到9。首先,假设MNIST有10个模式,代表了数据分支的连接部分,分为10个数字等级。然后使用不同的超参数配置进行扩展的网格搜索,使用两个正则常数α和β,数值为{0.01,0.05,0.1,0.2}。为了进行公平的对比,对不同的架构使用相同的参数和全连接层。
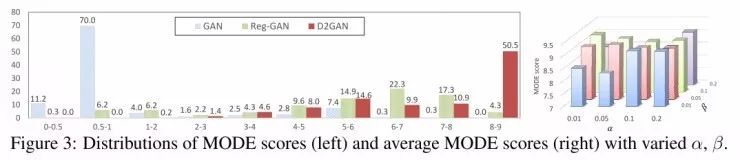
评估部分,首先训练一个简单的但有效的3-layer卷积网络(MNIST测试库实现0.65%的误差),然后将它应用于预估标签的概率和生成样本的MODE score计算中。图3左显示了3个模式下MODE score的分布。清晰的看到,D2GAN相对于标准GAN和Reg-GAN的巨大优越性,其分数的最大值基本落在区间【8.0-9.0】。值得注意的是,尽管提高网络的复杂度,MODE score基本保持高水平。这幅图片中只表现了最小网络和最少层和隐藏单元的结果。
为了研究α和β的影响,在不同的α和β的数值下进行试验(图3右)。结果表明,给定α值,D2GAN可以在β达到一定数值时获得更好的MODE score,当β数值继续增大,MODE score降低。
MNIST-1K。假定10个模式的标准MNIST数据库相当简单。因此,基于这个数据库,作者使用一个更具挑战性的数据库进行测试。沿用上述的方式,假定一个新的有1000个等级的MNIST数据库(MNIST-1K),方法为用3个随机数字组成一个RGB图像。由此,可以组成1000个离散的模式,从000到999。
在这个实验中,使用一个更强大的模型,鉴别器使用卷积层,生成器使用转置卷积。通过测试模式的数量进行模型的性能评估,其中模型在25,600个样本中至少产生一个模式,同时反KL散度分布介于模型分布(如从预训练的MNIST分类器预测的标签分布)和期望的数据分布之间。表1报告了D2GAN与GAN、unrolledGAN、GCGAN和Reg-GAN之间的对比。通过对比可以看出D2GAN具有极大的优势,同时模型分布和数据分布之间的差距几近为0。

自然场景图像
下面是将D2GAN应用到更广泛的自然场景图像上,用于验证其在大规模数据库上的表现。使用三个经常被使用的数据库:CIFAR-10,STL-10和ImageNet。CIFAR-10包含50,000张32*32的训练图片,有10个等级:飞机,摩托车,鸟,猫,鹿,狗,青蛙,马,船和卡车(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck)。STL-10,是ImageNet的子数据集,包含10,000张未被标记的96*96的图片,相对于CIFAR-10更多样,但是少于ImageNet。将所有的图片向下缩小3倍至32*32分辨率后,再对网络进行训练。ImageNet非常庞大,拥有120百万自然图片,包含1000个类别,通常ImageNet是深度网络领域训练使用的最为庞大和复杂的数据库。使用这三个数据库进行蓄念和计算,Inception score的结果如下图和下方表格所示:
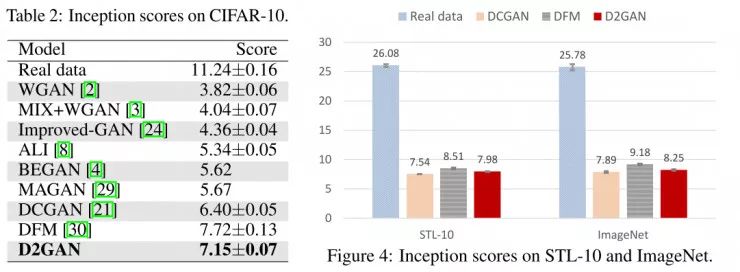
表格中和图4中表示了Inception score在不同数据库和不同模型上的不同值。值得注意的是,这边的对比是在一个完美无监督的方法下,并且没有标签的信息。在CIFAR-10数据库上使用的8个基线模型,而在STL-10和ImageNet数据库上使用了DCGAN、DFM(denoising feature matching)作对比。在D2GAN的实现上使用了与DCGAN完全一致的网络架构,以做公平的对比。在这三个实验结果中,可以看出,D2GAN的表现低于DFM,但是在很大的程度高于其他任何一个基线模型。这种逊于DFM的结果印证了对高级别的特征进行自动解码是提高多样性的一种有效方法。D2GAN可与这种方式兼容,因此融合这种做法可以为未来的研究带来更好的效果。
最后,在图5中展现了使用D2GAN生成的样本图片。这些图片都是随机产生的,而不是特别挑选的。从图片中可以看出,D2GAN生成了可以视觉分辨的车,卡车,船和马(在CIFAR-10数据库的基础上)。在STL-10的基础上,图片看起来相对比较难以辨认,但是飞机,车,卡车和动物的轮廓还是可以识别的;同时图片还具备了多种背景,如天空,水下,山和森林(在ImageNet的基础上)。这印证了使用D2GAN可以生成多样性的图片的结论。

结论
总结全文,作者介绍了一种全新的方法,结合KL(Kullback-Leibler)和反KL散度生成一个统一的目标函数来解决密度预测问题。这种方法利用了这两种散度的互补统计特性来提高生成器产生的图像的质量和样本的多样性。基于这个原理,作者引入了一种新的网络,基于生成对抗网络(GAN),由三方构成:两个鉴别器和一个生成器,并命其为双鉴别器生成对抗网络(dual discriminator GAN, D2GAN)。如果设定两个鉴别器是固定的,同时优化KL和反KL散度进行生成器的学习,通过这种方法可以帮助解决模式崩溃的问题(GAN的一大亟待突破的难点)。
作者通过大量的实验对其提出的方法进行了验证。这些实验的结果证实了D2GAN的高效性和扩展性。实验使用的数据库包括合成数据库和大规模真实图片数据库,即MNIST、CIFAR-10,STL-10和ImageNet。相较于最新的基线方法,D2GAN更具扩展性,可以应用于业内最为庞大和复杂的数据库ImageNet,尽管取得了比融合DFM(denoising feature matching)和GAN的方法低的Inception score,但远远高于其他GAN应用的实验结果。最后,作者指出,未来的研究可以借鉴融合DFM和GAN的做法,在现有的方法基础上增加类似半监督学习、条件架构和自动编码等的技术,更进一步的解决生成对抗网络在应用中的问题。
论文地址:https://arxiv.org/abs/1709.03831


新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
要让GAN生成想要的样本,可控生成对抗网络可能会成为你的好帮手
▼▼▼