一份2020年人工智能趋势清单

作者:Roberto Sannazzaro
编译:ronghuaiyang
2020 年已经来了,让我们对过去的一年做出一些思考,并对来年有所期待。

在这篇文章中,我想深入探讨人工智能的技术和非技术方面和趋势,讨论一些相对较新的趋势,比如从 AutoML 到人工智能的更清晰和伦理化的方面,这些方面正慢慢地影响着越来越多的公司和最终用户。
2019简短回顾:
2019 年,英特尔、高通和英伟达等大型芯片制造商发布了专门设计的芯片,只用于执行基于人工智能的应用程序,主要是在计算机视觉、自然语言处理和语音识别领域。

Google 发布了 TensorFlow 2.0,扩展了对 Node.js 上 TensorFlow 的支持,与 iOS 集成,最终正式将其高级 API 改为 Keras,使其成为移动和 PWA 上的第一。
此外,BERT 模型演变成 DistilBERT 或 FastBert,计算机视觉算法水平能够执行的大多数消费者的任务,并具有很好的准确性。
像 DeepMind 或 OpenAI 这样的大公司进一步推动了强化学习的边界。
最后但并非最不重要的是,Keras 的创始人 Francois Chollet 发表了一篇论文,提出了一种新的人工智能模型基准测试方法。
对2020有什么期待?

Automated machine learning (AutoML):
有能力执行 ETL 任务,数据预处理,变形的 AutoML 最有可能在 2020 年变得更受欢迎。
AutoML 技术可以处理整个机器学习过程,像auto-sklearn这样的包可以自动进行模型选择、超参数优化和评分,而不同的云提供商已经提供了一个“自动驾驶仪”来替代它们的服务:Amazon Forecast 自动决定哪个算法最适合数据,而谷歌也提供了类似的服务,Cloud AutoML。
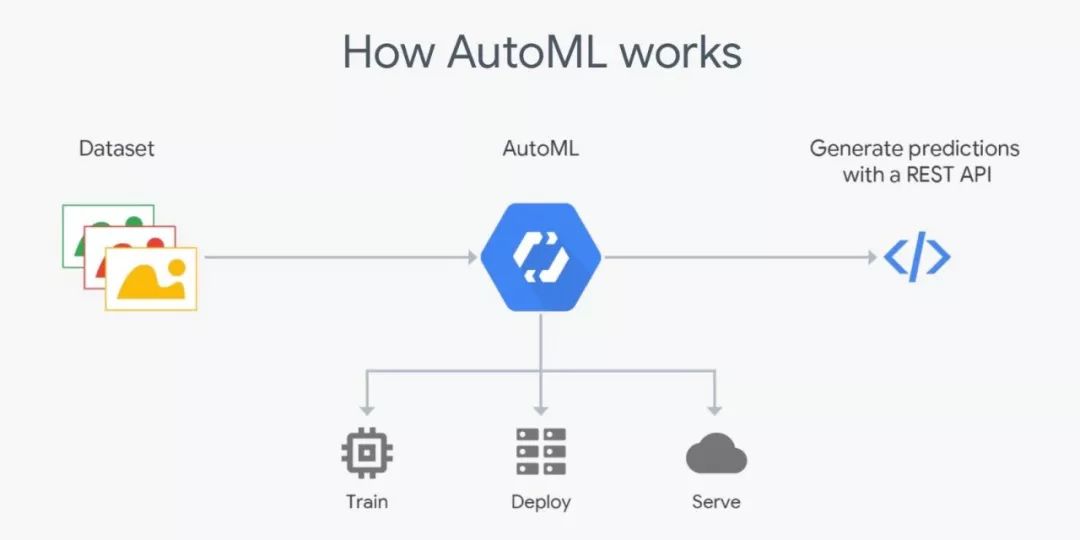
乍眼一看,这样似乎主要集中为不熟练 AI 的用户使用这些服务提供了一个很好的机会,同时也可以为高级用户服务:AutoML 模型可以作为基准,可以用来作为基线评估如果使用不同的技术来来开发,这样花费的时间是不是有意义。
AI之死:

你还记得这个吗?
可能不会。我还记得今年早些时候,这是一些智能手机及其 AI 摄像头的广告。一切都会结束的。多个消费者应用程序、汽车、家用电器现在都已经嵌入了使用某种人工智能的功能。我们(消费者)已经习惯了。“人工智能”这个时髦词将慢慢淡出人们的视线,而人工智能功能将更多的被赋予消费者。
联邦机器学习:
早在 2017 年,谷歌就引入了分布式学习的概念,这是一种使用分散数据对模型进行部分或全部训练的方法。
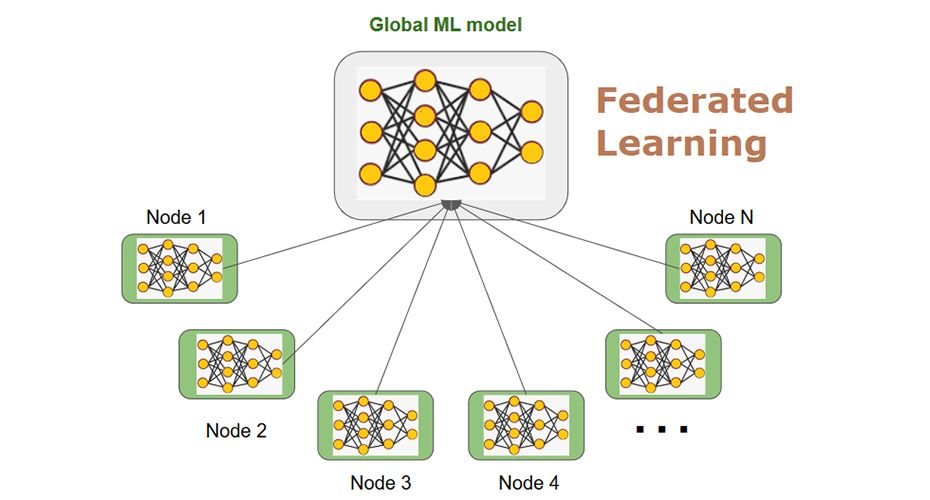
考虑在你的机器上训练一个基线模型,然后将模型交付给最终用户,后者在他的手机、笔记本电脑和平板电脑上可以访问模型的数据,用于调整和个性化。
让我们考虑一个涉及一些高度敏感数据处理的模型:提供该模型的公司可以访问一些经过脱敏的数据,这些数据是专门为它们准备的。
一旦基线模型满足了某些需求,就可以将模型交付给客户,客户最终将进一步训练模型,而不需要与外部参与者共享任何用户数据。
如前所述,TensorFlow 2.0 支持其他平台,如 iOS、Node.js 等,其中一个原因是可能使这成为可能,为公司提供一个多平台工具来构建、发布、训练和优化。此外,像 Docker 和 Kubernetes 这样的平台提供了扩展和管理一个相对复杂部署环境的的可能性,使得联邦机器学习成为可能。
云寡头的终结:
云计算在 2019 年变得越来越流行,很多人从“我们永远不会和他们分享我们的数据”变成了“好吧,也许我们可以试试”。

云提供商的规模、数量、客户和产品都在增加,市场开始从寡头垄断转向完全竞争市场,这意味着云提供商正在慢慢失去定价能力。今年市场已经可能被不同的云供应商瓜分了,2020 年将多重云等产品的市场了,云提供商将不仅取决于他们的定价计划,还包括他们要用我们如何使用他们的服务:这个供应商希望我使用更多还是更少的资源?他们是在影响我把所有东西都存储在云中,还是有不同的数据分配解决方案?
可解释的,负责任的,可推理的和有道德的AI:
2019 年,我们努力研究可复现 AI,和可解释 AI,这是一系列鼓励算法的可解释性和再现性的实践。这一趋势与机器学习(和深度学习)在许多不同领域和不同公司的应用方式不同。
模型不再是(也不应该是)黑箱,它们的结果中的每个决策都必须是可解释的。
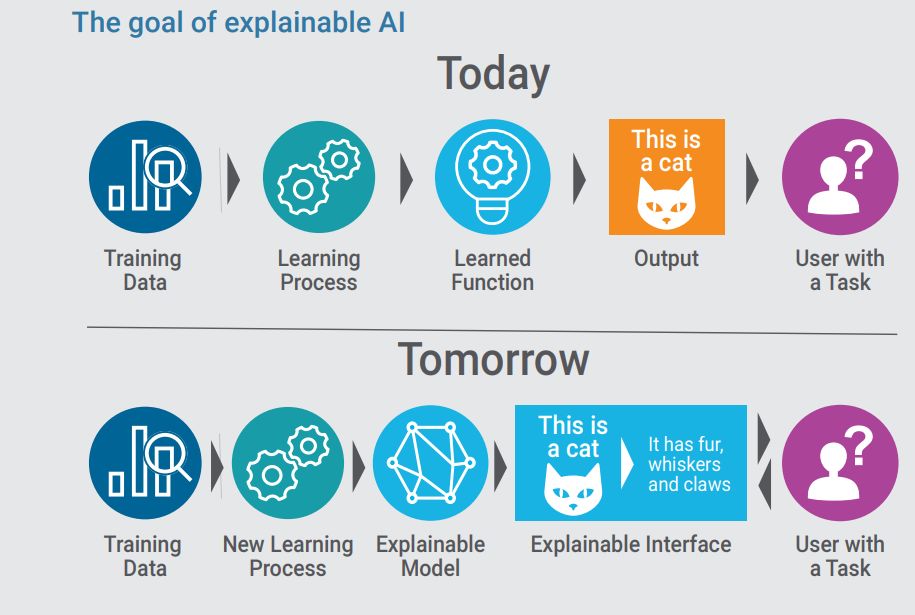
这一趋势需要一个新的形象,能够理解可解释性和(人类)可解释性的边界,能够回答诸如“这符合我们的使命和价值观吗?”之类的问题。
此外,应用机器学习技术来解决可能排除或歧视某些用户群体的任务的公司必须关注他们对模型决策的法律和道德责任。
总结:
在揭示了这些趋势之后,我们可以做一些思考和考虑:
-
人工智能正在被嵌入: 为特定任务专门设计的小型硬件组件。 -
人工智能变得(越来越)可迁移: 多平台支持,标准化,再现性。 -
Francois Chollet 方法论的基准 AI 可能成为下一个机器智能的图灵测试,其论文第三章详细解释了这个框架。

英文原文:https://towardsdatascience.com/a-distilled-list-of-ai-trends-for-2020-e2fc83a9b092
推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





