数据缺失、混乱、重复怎么办?最全数据清洗指南让你所向披靡
选自TowardsDataScience
作者:Lianne & Justin
机器之心编译
参与:魔王、杜伟
要获得优秀的模型,首先需要清洗数据。这是一篇如何在 Python 中执行数据清洗的分步指南。

数据清洗:从记录集、表或数据库中检测和修正(或删除)受损或不准确记录的过程。它识别出数据中不完善、不准确或不相关的部分,并替换、修改或删除这些脏乱的数据。

缺失数据;
不规则数据(异常值);
不必要数据:重复数据(repetitive data)、复制数据(duplicate data)等;
不一致数据:大写、地址等;

# import packagesimport pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.mlab as mlabimport matplotlibplt.style.use('ggplot')from matplotlib.pyplot import figure%matplotlib inlinematplotlib.rcParams['figure.figsize'] = (12,8)pd.options.mode.chained_assignment = None# read the datadf = pd.read_csv('sberbank.csv')# shape and data types of the dataprint(df.shape)print(df.dtypes)# select numeric columnsdf_numeric = df.select_dtypes(include=[np.number])numeric_cols = df_numeric.columns.valuesprint(numeric_cols)# select non numeric columnsdf_non_numeric = df.select_dtypes(exclude=[np.number])non_numeric_cols = df_non_numeric.columns.valuesprint(non_numeric_cols)
cols = df.columns[:30] # first 30 columnscolours = ['#000099', '#ffff00'] # specify the colours - yellow is missing. blue is not missing.sns.heatmap(df[cols].isnull(), cmap=sns.color_palette(colours))
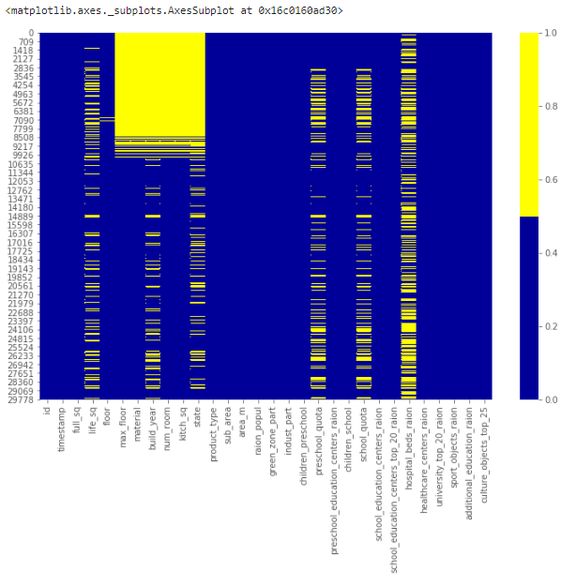 缺失数据热图
缺失数据热图
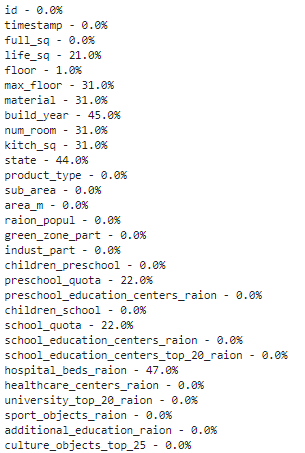
# if it's a larger dataset and the visualization takes too long can do this.# % of missing.for col in df.columns:pct_missing = np.mean(df[col].isnull())print('{} - {}%'.format(col, round(pct_missing*100)))
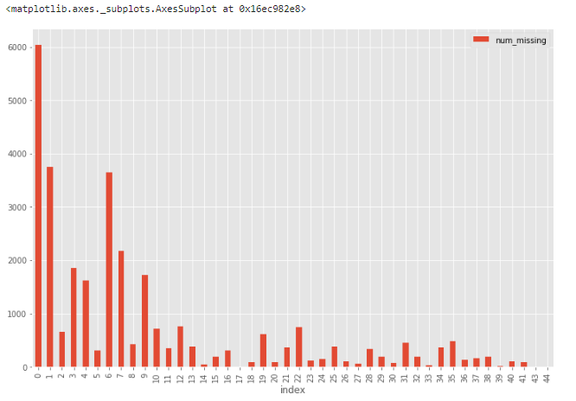
# first create missing indicator for features with missing datafor col in df.columns:missing = df[col].isnull()num_missing = np.sum(missing)if num_missing > 0:print('created missing indicator for: {}'.format(col))df['{}_ismissing'.format(col)] = missing# then based on the indicator, plot the histogram of missing valuesismissing_cols = [col for col in df.columns if 'ismissing' in col]df['num_missing'] = df[ismissing_cols].sum(axis=1)df['num_missing'].value_counts().reset_index().sort_values(by='index').plot.bar(x='index', y='num_missing')
# drop rows with a lot of missing values.ind_missing = df[df['num_missing'] > 35].indexdf_less_missing_rows = df.drop(ind_missing, axis=0)
# hospital_beds_raion has a lot of missing.# If we want to drop.cols_to_drop = ['hospital_beds_raion']df_less_hos_beds_raion = df.drop(cols_to_drop, axis=1)
# replace missing values with the median.med = df['life_sq'].median()print(med)df['life_sq'] = df['life_sq'].fillna(med)
# impute the missing values and create the missing value indicator variables for each numeric column.df_numeric = df.select_dtypes(include=[np.number])numeric_cols = df_numeric.columns.valuesfor col in numeric_cols:missing = df[col].isnull()num_missing = np.sum(missing)if num_missing > 0: # only do the imputation for the columns that have missing values.print('imputing missing values for: {}'.format(col))df['{}_ismissing'.format(col)] = missingmed = df[col].median()df[col] = df[col].fillna(med)
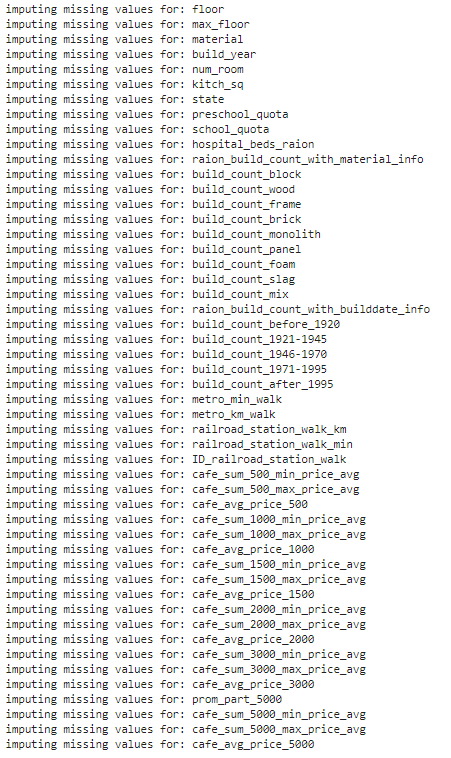
# impute the missing values and create the missing value indicator variables for each non-numeric column.df_non_numeric = df.select_dtypes(exclude=[np.number])non_numeric_cols = df_non_numeric.columns.valuesfor col in non_numeric_cols:missing = df[col].isnull()num_missing = np.sum(missing)if num_missing > 0: # only do the imputation for the columns that have missing values.print('imputing missing values for: {}'.format(col))df['{}_ismissing'.format(col)] = missingtop = df[col].describe()['top'] # impute with the most frequent value.df[col] = df[col].fillna(top)
# categoricaldf['sub_area'] = df['sub_area'].fillna('_MISSING_')# numericdf['life_sq'] = df['life_sq'].fillna(-999)
# histogram of life_sq.df['life_sq'].hist(bins=100)
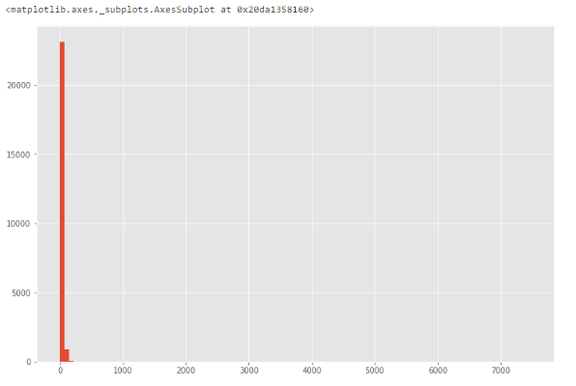
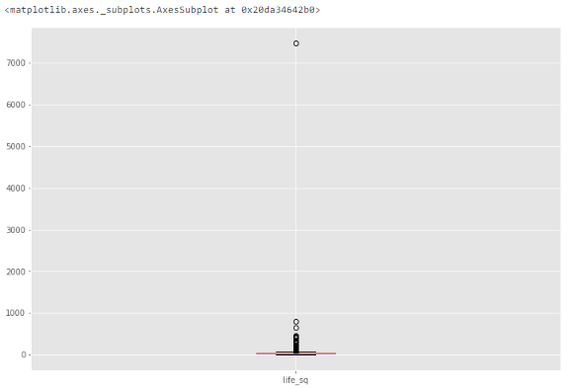
# box plot.df.boxplot(column=['life_sq'])
df['life_sq'].describe()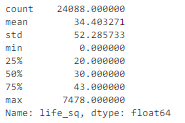
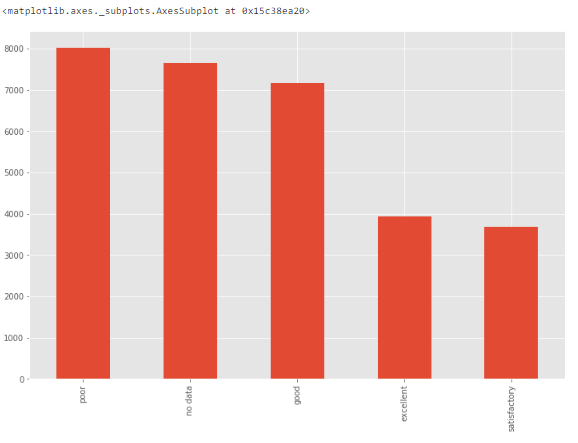
# bar chart - distribution of a categorical variabledf['ecology'].value_counts().plot.bar()
num_rows = len(df.index)low_information_cols = [] #for col in df.columns:cnts = df[col].value_counts(dropna=False)top_pct = (cnts/num_rows).iloc[0]if top_pct > 0.95:low_information_cols.append(col)print('{0}: {1:.5f}%'.format(col, top_pct*100))print(cnts)print()
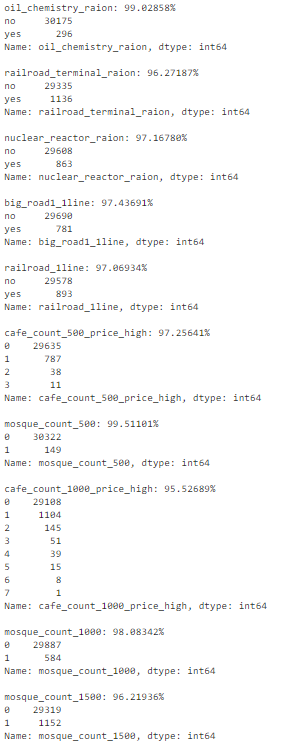
# we know that column 'id' is unique, but what if we drop it?df_dedupped = df.drop('id', axis=1).drop_duplicates()# there were duplicate rowsprint(df.shape)print(df_dedupped.shape)
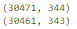
key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc']df.fillna(-999).groupby(key)['id'].count().sort_values(ascending=False).head(20)
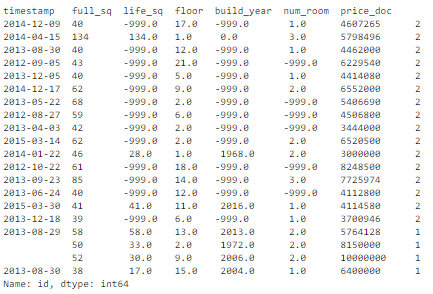
# drop duplicates based on an subset of variables.key = ['timestamp', 'full_sq', 'life_sq', 'floor', 'build_year', 'num_room', 'price_doc']df_dedupped2 = df.drop_duplicates(subset=key)print(df.shape)print(df_dedupped2.shape)
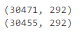
df['sub_area'].value_counts(dropna=False)
# make everything lower case.df['sub_area_lower'] = df['sub_area'].str.lower()df['sub_area_lower'].value_counts(dropna=False)

df
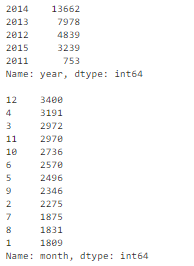
df['timestamp_dt'] = pd.to_datetime(df['timestamp'], format='%Y-%m-%d')df['year'] = df['timestamp_dt'].dt.yeardf['month'] = df['timestamp_dt'].dt.monthdf['weekday'] = df['timestamp_dt'].dt.weekdayprint(df['year'].value_counts(dropna=False))print()print(df['month'].value_counts(dropna=False))
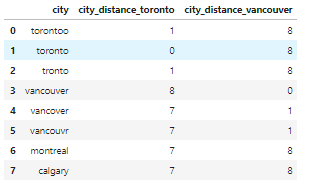
from nltk.metrics import edit_distancedf_city_ex = pd.DataFrame(data={'city': ['torontoo', 'toronto', 'tronto', 'vancouver', 'vancover', 'vancouvr', 'montreal', 'calgary']})df_city_ex['city_distance_toronto'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'toronto'))df_city_ex['city_distance_vancouver'] = df_city_ex['city'].map(lambda x: edit_distance(x, 'vancouver'))df_city_ex
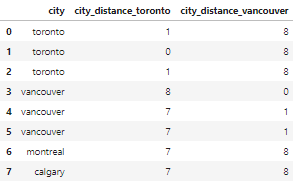
msk = df_city_ex['city_distance_toronto'] <= 2df_city_ex.loc[msk, 'city'] = 'toronto'msk = df_city_ex['city_distance_vancouver'] <= 2df_city_ex.loc[msk, 'city'] = 'vancouver'df_city_ex
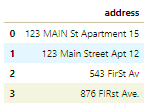
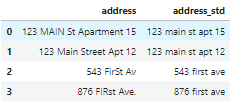
# no address column in the housing dataset. So create one to show the code.df_add_ex = pd.DataFrame(['123 MAIN St Apartment 15', '123 Main Street Apt 12 ', '543 FirSt Av', ' 876 FIRst Ave.'], columns=['address'])df_add_ex
df_add_ex['address_std'] = df_add_ex['address'].str.lower()df_add_ex['address_std'] = df_add_ex['address_std'].str.strip() # remove leading and trailing whitespace.df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\\.', '') # remove period.df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\\bstreet\\b', 'st') # replace street with st.df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\\bapartment\\b', 'apt') # replace apartment with apt.df_add_ex['address_std'] = df_add_ex['address_std'].str.replace('\\bav\\b', 'ave') # replace apartment with apt.df_add_ex
登录查看更多
相关内容

Arxiv
3+阅读 · 2020年4月13日


相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2020年4月13日